
作者 | Chuan Li、Corey Lowman、David Hartmann、Jeremy Hummel
译者 | Sambodhi
策划 | 褚杏娟
导读:你是否好奇如何利用尖端技术提升视频生成的质量?你是否想知道,如何通过微调模型,创造出令人惊叹的视觉效果?本篇文章将带你深入探索从硬件配置到数据准备,再到模型微调的全过程。我们揭示了在实际操作中如何克服挑战,不断提升生成视频的分辨率和帧数,并探讨了未来发展方向。
Text2Video 模型为开发者和内容创作者们开启了全新的创作领域。然而,由于专有模型的获取难度或特定需求的适配问题,这些模型可能无法满足所有需求。但好消息是,通过使用自己的数据对开源模型进行微调,你可以大大增强其生成符合项目需求的视频的能力,无论是创造独特的艺术风格,还是提升特定主题的画质。比如,你或许可以以一种别具一格的艺术风格重新诠释经典电影场景。
接下来,本文将详细阐述如何通过微调 Open-Sora 1.1 Stage3 模型来创建定格动画。我们特意发布了两个模型供你选择:
lambdalabs/text2bricks-360p-64f: 该模型经过长达 1000 个 GPU 小时(基于 NVIDIA H100)的训练,能够生成最高达 64 帧的 360p 视频。
lambdalabs/text2bricks-360p-32f: 该模型则经过 170 个 GPU 小时(同样基于 NVIDIA H100)的训练,能够生成最高达 32 帧的 360p 视频。
为了方便你的使用,我们已经公开了相关的代码(这是我们基于 Open-Sora 的修改分支)、数据集以及模型(包括 32f 和 64f)。此外,你还可以通过 Gradio 演示来试用 64f 模型,感受其带来的震撼效果。
下面是一些示例输出,供你参考:
经过我们精心微调模型后,生成的积木动画效果如下:

当宇航员在月球上行走时,由于月球的引力较小,他们的步伐呈现出一种独特的轻盈和弹性,仿佛每一步都在轻轻跳跃。

在罗马狭窄的街道上,人们纷纷在咖啡馆外品尝着美味的冰淇淋,同时悠闲地啜饮着浓缩咖啡。街道两侧,琳琅满目的商店鳞次栉比,售卖着各式各样的商品。其中一家店铺专门售卖新鲜水果,另一家则专注于蔬菜的挑选,而第三家店则挂满了五彩斑斓的圣诞饰品,为即将到来的节日增添了几分温馨与喜庆。
设置
硬件:我们的训练基础设施是一个由 Lambda 提供的 32-GPU 一键集群。这个集群由四台 NVIDIA HGX H100 服务器构成,每台服务器均搭载了 8 个 NVIDIA H100 SXM Tensor Core GPU,并通过 NVIDIA Quantum-2 400 Gb/s InfiniBand 网络连接。节点间的带宽高达 3200 Gb/s,确保了分布式训练能在多个节点上实现线性扩展。此外,集群还配备了 Lambda Cloud 的按需付费共享文件系统存储,使得数据、代码和 Python 环境能够在所有节点间无缝共享。如需了解更多关于一键集群的信息,请查阅这篇博客。
软件:我们的 32-GPU 集群预装了 NVIDIA 驱动程序。为了简化环境配置,我们编写了一篇教程,指导用户如何创建 Conda 环境来管理 Open-Sora 的依赖项,这些依赖项包括 NVIDIA CUDA、NVIDIA NCCL、PyTorch、Transformers、Diffusers、Flash-Attention 以及 NVIDIA Apex。为了方便所有节点上的环境激活,我们将 Conda 环境放置在了共享文件系统存储中。
利用这个 32-GPU 集群,我们每小时可以训练高达 97,200 个视频剪辑(每个视频剪辑为 360p 分辨率,32 帧每秒)。
数据
数据来源:我们的数据集视频取材于几个热门的 YouTube 频道,如 MICHAELHICKOXFilms、LEGO Land、FK Films 和 LEGOSTOP Films。这些视频均是以 LEGO®积木为素材制作的高质量定格动画。完整的数据集可在 Huggingface 上获取:[完整数据集链接]。
为了方便用户从 YouTube URL 创建自定义数据集,我们提供了一个脚本。数据处理流程遵循 Open-Sora 的指导原则,首先是将视频剪切成 15 至 200 帧的片段,然后使用视觉语言模型对这些片段进行注释。我们的数据集中共包含 24000 个 720p/16:9 的视频剪辑。此外,Open-Sora 还建议加入静态图像以帮助模型更精细地学习对象的外观特征。因此,我们将每个视频剪辑的中间帧收集起来,以补充到数据集中。
数据注释:我们采用了 GPT-4o 和特定的提示来对视频剪辑进行注释。以下是我们的提示:
A stop motion lego video is given by providing three frames in chronological order, each pulled frame from 20%, 50%, and 80% through the full video. Describe this video and its style to generate a description.
If the three frames included do not give you enough context or information to describe the scene, say 'Not enough information'.If the three frames all appear identical, say 'Single image'.If the three frames depict very little movement, say 'No movement'.
Do not use the term video or images or frames in the description. Do not describe each frame/image individually in the description.Do not use the word lego or stop motion animations in your descriptions. Always provide descriptions for lego stop motion videos but do not use the word lego or mention that the world is blocky.
Pay attention to all objects in the video. The description should be useful for AI to re-generate the video.
The description should be less than six sentences.
我们为 GPT-4o 提供了来自 OpenAI 的 Sora 演示的几个提示作为示例,包括“一个时尚的女性自信地漫步在东京的街头”,“猛犸象在雪地草原中穿行”,以及“大苏尔”等场景。视频的中间帧也通过 GPT-4o 进行了描述,并对图像数据的提示进行了适当的调整。
尽管这些描述是由最新且先进的 GPT 模型生成的,但仍有可能存在不准确之处。以下是一个示例,其中加粗部分是存在问题的描述。这凸显了在特定主题领域获取高质量数据标签所面临的挑战。

一位角色带着震惊的表情坐在一间疑似浴室的地方,随后其表情逐渐转为放松和满意。角色身旁是一个棕色的柜子和白色的水槽。地板从蓝色渐变至绿色,上面还放着一个类似公文包的物品。整个场景展现了一个简洁的室内环境,角色在坐着时经历了快速的情绪变化。
模型
预训练模型:我们采用了最新发布的 Open-Sora 模型(发布于 2024 年 4 月 25 日),因为它在不同时空分辨率和纵横比下继续训练的灵活性备受瞩目。我们的计划是利用 BrickFilm 数据集对预训练的 OpenSora-STDiT-v2-stage3 模型进行微调,以生成具有相似风格的视频。有关训练模型的配置和命令,请查阅此指南。
我们的首个成功模型(text2bricks-360p-64f)具备生成 360p 分辨率、最多 64 帧视频的能力。在 H100 平台上,整个训练过程耗时 1017.6 H100 小时,详细步骤如下:
第一阶段(160 H100 小时):我们首先将焦点放在生成 360p 分辨率和 16 帧的视频上。为了确保微调的稳定性,我们在保持学习率恒定为 1e-5 之前,采用了 500 个余弦热身步骤。这一步骤有助于逐步“恢复”优化器状态,避免在训练初期出现模型行为异常的情况。第二阶段(857.6 H100 小时):随后,我们加入了图像数据集,并将配置扩展到支持 32 帧和 64 帧的视频生成。
此外,我们还训练了另一个模型(text2bricks-360p-32f),它能在 169.6 H100 小时内完成训练,并采用了单周期学习率调度策略。在 360p 分辨率和最多 32 帧的视频生成方面,该模型同样取得了可媲美的成果。具体训练步骤如下:
第一阶段(67.84 H100 小时):我们首先逐步提高学习率,从 1e-7 增加至 1e-4,并进行了 1500 个余弦热身步骤。第二阶段(101.76 H100 小时):随后,我们将学习率降低至 1e-5,并进行了 2500 个余弦退火步骤。
结果
以下面板展示了模型在微调阶段的输出演变过程。我们已固定随机种子,以确保对比的公正性。

text2bricks-360p-64f: 第一阶段(360p / 16 帧)

text2bricks-360p-64f: 第二阶段(360p / 64 帧)图片:

text2bricks-360p-32f: 第二阶段(360p / 32 帧)图片:

指标
训练指标
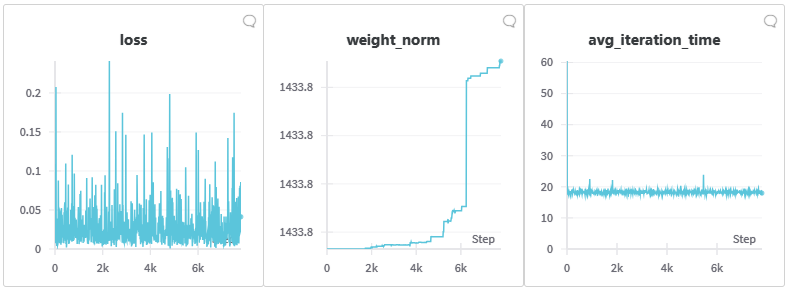
在微调过程中,我们观察到损失并未减少。但值得注意的是,从验证结果来看,模型并未崩溃,反而生成的图像质量逐步提高。这表明模型的性能提升并未直接反映在损失值上。
系统指标
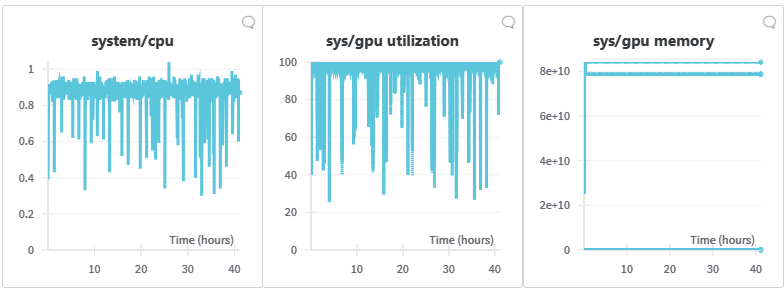
通过 W&B 的监控面板,我们观察到该微调任务的 CPU 使用率非常低,而 GPU 则持续忙碌于数据处理。尽管偶尔因评估和检查点而有所下降,但 GPU 的计算和内存使用率始终保持在高位。这凸显了在训练基础模型时高效扩展的重要性。Lambda 的一键式集群服务,凭借其互联的 NVIDIA H100 Tensor Core GPU 和 NVIDIA Quantum-2 400Gb/s InfiniBand 网络,为此提供了有力支持。
未来工作
尽管目前的结果令人鼓舞,但我们的模型仍有几个改进方向:
长序列中的时间一致性:在较长序列输出中,我们发现时间一致性较弱。这可能与 ST-DiT-2 架构在空间和时间维度上分别使用注意机制作为独立步骤有关。尽管这降低了计算成本,但可能限制了注意力在“局部”上下文窗口内的运用,导致生成的视频出现漂移。加强空间和时间注意力的整合可能是解决这一问题的关键。
无条件生成中的噪音:在无条件生成(设置 cfg=0)时,我们观察到了噪声输出。这表明模型在砖块动画表示的学习上仍有提升空间。可能的解决方案包括进一步扩展数据集,并探索让模型更有效学习表示的方法。
分辨率和帧数:将输出推向超过 360p 和 64 帧将是未来发展的一个重要方向。实现更高的分辨率和更长的序列将进一步提升模型的实用性和应用范围。
数据集:数据集的质量和数量都有待提高。
原文链接




