
推荐系统无处不在,从 Netflix、谷歌、亚马逊到小型网店,都能看到它的身影。实际上,推荐系统可能是机器学习最成功的商业应用之一。它具备预测用户喜欢阅读、观看和购买什么的能力。推荐系统不仅对企业有益,对用户也是有益的。对用户而言,推荐系统提供了一种探索产品空间的方式;对企业而言,推荐系统提供了一种增加用户参与的方式,同时也能让企业对客户有更多的了解。本文中,我们将了解如何使用 ML.NET 来创建推荐系统。
本文主要包括以下五个部分:
数据集和前提
推荐系统的类型
协同过滤直觉
矩阵分解直觉
用 ML.NET 实现
1. 数据集和前提
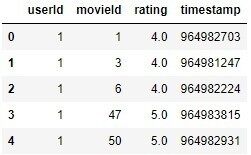
大家都喜欢 Netflix,其中一个原因就是他们的推荐做得很好,这家公司已经在推荐系统方面投入了大量资金。Netflix 因 “Netflix Prize”竞赛而闻名,工程师们在没有关于用户或电影的其他信息的情况下,根据先前的评级,试图预测用户对电影的评级,他们甚至提供了一个数据集,这个数据集包括 480189 个用户给 17770 部电影的 100480507 个评级。每个样本在数据集中被格式化为每组四个特征:用户 ID、电影 ID、评级、评级日期。用户 ID 和电影 ID 的特征是整数 ID,而评级则是从 1 到 5。这些数据看起来像这样:
本文的实现用 C# 语言完成,我们使用最新的 .NET 5,因此要确保你已安装此 SDK。若你正在使用 Visual Studio,则随附 16.8.3 版本。此外,确保你已安装下列软件包:
$ dotnet add package Microsoft.ML$ dotnet add package Microsoft.ML.Recommender你可以在 Package Manager Console 中执行相同操作:
Install-Package Microsoft.MLInstall-Package Microsoft.ML.Recommendation注意,这也会安装默认的 Microsoft .ML 包。你可以使用 Visual Studio 的 Manage NuGetPackage 选项来执行类似操作:
假如你想了解使用 ML.NET 进行机器学习的基本知识,请看这篇文章:《使用 ML.NET 进行机器学习:简介》(Machine Learning with ML.NET – Introduction)
2. 推荐系统的类型
如前所述,Netflix 的数据集包含用户如何为电影评级的信息。在此基础上,我们如何为该用户创建推荐呢?在推荐同类项目前,我们需要考虑用户看过的电影的一些特征并进行排名。此外,我们可以基于这些排名寻找相似用户,并推荐这些用户购买的项目。但这两个项目的相似意味着什么呢?用户之间的相似意味着什么呢?怎样用数学术语计算和表达这种相似呢?
针对这些问题,不同类型的推荐系统采用不同的方法。通常有四种推荐系统:
基于内容的推荐系统:这种类型的推荐系统侧重于内容。也就是说,它们只使用项目的特征和信息,并在此基础上为用户创建推荐。它们忽略了其他用户的信息。
协同过滤推荐系统:推荐系统最强大的地方在于,它们可以根据用户在特定平台上的行为,或者根据同一平台上其他用户的行为,来为用户推荐项目。举例来说,Netflix 会根据你以前看过的电视剧,在用户和你观看并喜欢相同内容的电视剧的基础上,为你推荐下一部精彩的电视剧。
基于知识的推荐系统:这种类型的推荐系统使用明确的用户偏好、项目以及推荐标注知识。本例中,推荐系统询问用户的偏好,并基于这些反馈建立推荐。
混合解决方案推荐系统:通常情况下,我们在一些定制的解决方案中使用所有类型的组合。
如果你想进一步了解这些系统的工作原理,请参阅这篇文章《推荐系统简介》(Introduction to Recommendation Systems)。在这三种类型中,前两种使用最频繁,也最受欢迎。在实践中,可能出现的情况是,我们创建了混合解决方案来实现更好的结果。
ML.NET 仅支持协同过滤,或者更确切地说:矩阵分解。因此,在本文中,我们将重点放在这种类型的推荐系统上。让我们进一步了解这些系统是如何在幕后运作的。
3. 协同过滤直觉
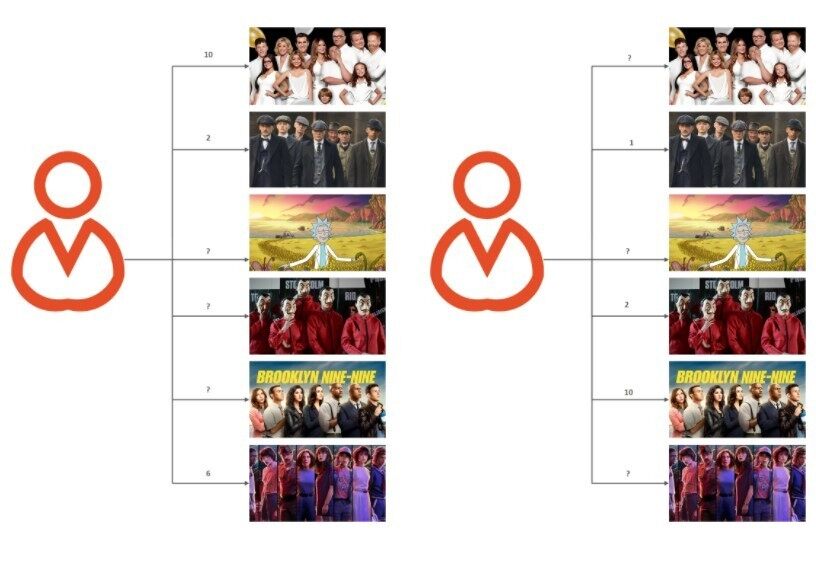
创建推荐系统的最流行的技术之一是协同过滤。不像基于内容的过滤,这种方法把用户和项目置于一个共同的嵌入空间中,沿着它们共有的维度(观看特征)。举例来说,让我们考虑两个 Netflix 用户及其对节目的评级。
在 TensorFlow 中,我们可以这样表示(别担心,我们不会研究 TensorFlow 的细节,只是举例说明):
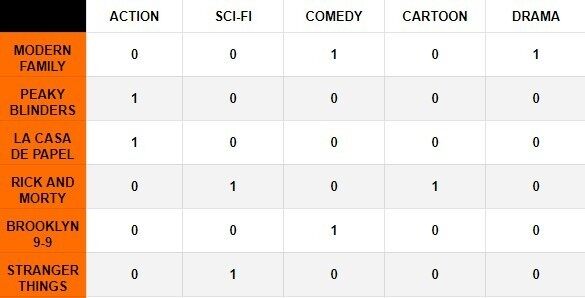
users_tv_shows = tf.constant([ [10, 2, 0, 0, 0, 6], [0, 1, 0, 2, 10, 0]],dtype=tf.float32)我们现在可以获取每个节目的特征,也就是这一类型的 k-hot 编码:
或者在 TensorFlow 中:
tv_shows_features = tf.constant([ [0, 0, 1, 0, 1], [1, 0, 0, 0, 0], [0, 1, 0, 1, 0], [0, 0, 1, 0, 0], [0, 1, 0, 0, 0]],dtype=tf.float32)这样就可以对这些矩阵进行简单的点乘,得到每个用户的相似度:
users_features = tf.matmul(users_tv_shows, tv_shows_features)users_features = users_features/tf.reduce_sum(users_features, axis=1, keepdims=True)top_users_features = tf.nn.top_k(users_features, num_feats)[1]for i in range(num_users): feature_names = [features[int(index)] for index in top_users_features[i]] print('{}: {}'.format(users[i],feature_names))User1: ['Comedy', 'Drama', 'Sci-Fi', 'Action', 'Cartoon']User2: ['Comedy', 'Sci-Fi', 'Cartoon', 'Action', 'Drama']我们可以看到,这两个用户的首要特征是喜剧,这意味着他们喜欢相似的东西。我们在这里做了什么?我们不只是用所提到的流派来描述项目,而是用相同的术语来描述每个用户。比如,用户 1 的意思是她喜欢喜剧片 0.5,而他喜欢动作片 0.1。注意,如果我们将用户的嵌入矩阵与转置项目嵌入矩阵相乘,我们会重新创建用户 - 项目交互矩阵。现在,这对于用户和项目很少的简单例子来说效果很好。但是,当向系统添加更多项目和用户时,它就变得不可扩展了。另外,我们如何确定我们所选择的特征是否相关?假如存在一些我们无法识别的潜在特征呢?我们怎样才能找到正确的特征?要想解决这些问题,就需要先了解矩阵分解。
4. 矩阵分解直觉
我们提到,人为定义的项目和用户特征在整体上可能并不是最佳选择。幸好,这些嵌入可以从数据中学习。也就是说,我们不会手工地给项目和用户分配特征,而是用用户 - 项目交互矩阵来学习最佳因子分解的潜在因子。与之前的思维练习一样,这个过程会产生一个用户因子嵌入和项目因子嵌入矩阵。从技术上讲,我们对稀疏的用户 - 项目交互矩阵进行了压缩,提取了潜在因子(类似主成分分析)。这就是矩阵因子分解的意义所在,它能将一个矩阵因子分解成两个较小的矩阵,利用这些矩阵,我们可以重建原始矩阵:
你的内容放在这里,在模块内容设置中编辑或删除此文本。你还可以在模块的设计设置中对这个内容的各个方面进行样式化,甚至在模块的高级设置中将自定义 CSS 应用到这个文本。
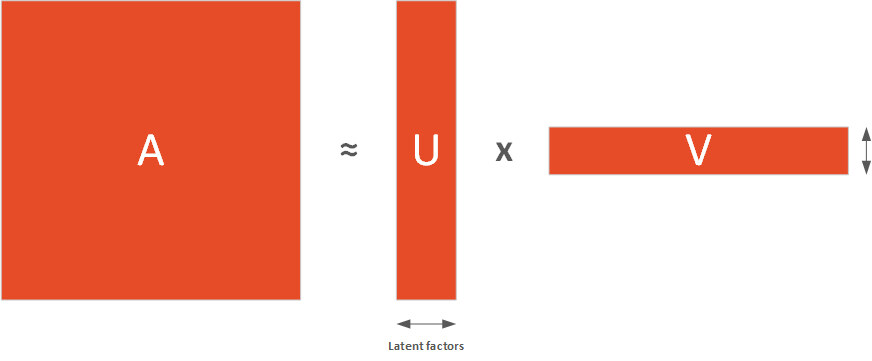

像其他降维技术一样,潜在特征的数量也是一个超参数,我们可以对其进行调整,使其在信息压缩和重建误差之间取得平衡。我们有两种方法进行预测,可采用用户与项目因子的点积,或项目与用户因子的点积。矩阵分解法也可以帮助我们求解另一个问题。假设你的系统有数千个用户,你希望计算它们之间的相似性矩阵,这是一个相当大的矩阵,矩阵分解能为我们压缩这些信息。
4.1 矩阵分解算法
数年前,Netflix 举办了一场价值 100 万美元的推荐系统竞赛。目标是根据用户的评级来改进系统的准确性。获胜者使用了奇异值分解算法来获得最佳结果。这种算法现在仍然很流行。形式上,可以这样定义:
设 A 是一个 m×n 矩阵,则 A 的奇异值分解(Singular Value Decomposition,SVD)为:

其中 U 是 m×m 且正交,V 是 n×n 且正交,Σ 是一个 m×n 的对角矩阵,具有非负对角线项 σ1≥σ2≥--≥σp,p=min{m,n},称为 A 的奇异值。
另一种非常流行的算法是交替最小二乘法或 ALS 及其变体。正如它的名字一样,该算法在保持 V 不变的情况下交替求解 U,然后在保持 U 不变的情况下求解 V,仅适用于最小二乘问题。但是,因为它是专用的,ALS 可以并行化,所以算法非常快速。

它的一个变体是加权交替最小二乘法或 WALS。其区别在于处理缺失数据的方式。正如我们在以前的文章中多次提到的那样,推荐系统最大的敌人之一是稀疏数据。WALS 为特定项目增加权重,并使用这些权重向量,它们可以通过线性或指数缩放来规范行和 / 或列的频率。
在矩阵分解中,NMF 是另一种常用算法。它表示非负矩阵分解。该算法基于获取低秩表示的矩阵,它包含有非负或正元素。NMF 使用迭代过程来修改 U 和 V 的初始值,使其积接近 V。

5 用 ML.NET 实现
ML.NET 目前仅支持带有随机梯度下降的标准矩阵分解。正如我们稍后将看到的,MatrixFactorization Trainer 支持这一点。
5.1 高层架构
在深入研究这个实现之前,让我们先来考虑该实现的高层架构。正如之前的 ML.NET 指南一样,我们想要建立一个易于扩展的解决方案,并且我们能够轻易地扩展出 ML.NET 未来可能包含的新矩阵分解算法。本文所提供的解决方案是 Auto ML 的一种简单形式。下面显示了我们的解决方案的文件夹结构法:
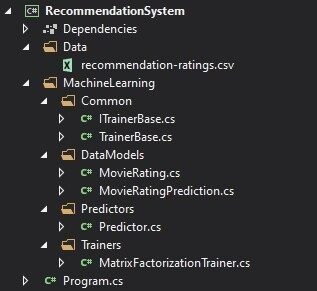
Data 文件夹包含输入数据的 .csv,MachineLearning 文件夹包含我们使用算法所需的所有东西。可以这样表示架构概述:
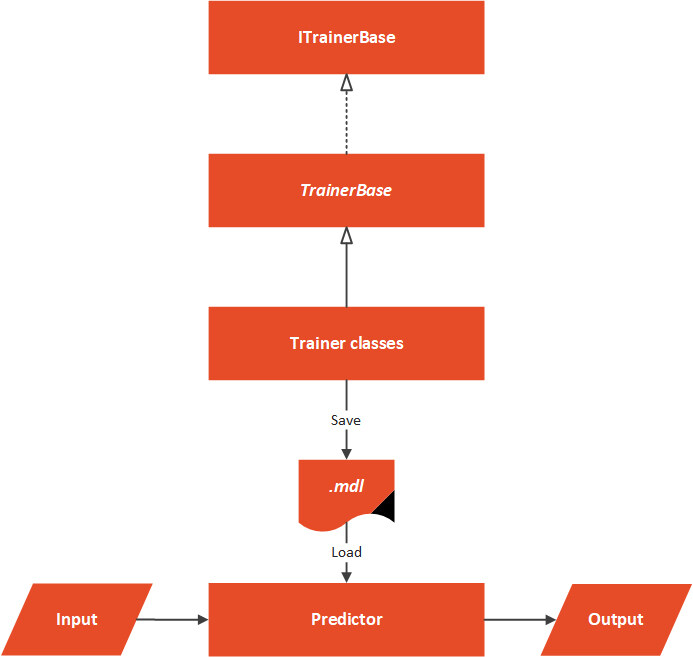
该解决方案的核心是一个抽象的 TrainerBase 类。这个类位于 Common 文件夹中,其主要目标是规范整个过程的完成方式。这是一个处理数据和进行特征工程的类,此类还负责训练机器学习算法。实现这个抽象类的类位于 Trainers 文件夹中,在这里我们可以找到多个利用 ML.NET 算法的类,这些类定义了应该使用哪种算法。在这种特殊情况下,我们只有一个 Predictor,位于 Predictor 文件夹中。
5.2 数据模型
要从数据集中加载数据,并使用 ML.NET 算法,需要实现类来建模这些数据。在 Data 文件夹中可以找到两个文件:MovieRating 和 MovieRatingPredictions。MovieRating 类为输入数据建模,看起来如下所示:
using Microsoft.ML.Data;namespace RecommendationSystem.MachineLearning.DataModels{ public class MovieRating { [LoadColumn(0)] public int UserId; [LoadColumn(1)] public int MovieId; [LoadColumn(2)] public float Label; }}正如你所看到的,我们不使用来自数据集的数据。
MovieRatingPredictions 类为输出数据建模:
namespace RecommendationSystem.MachineLearning.DataModels{ public class MovieRatingPrediction { public float Label; public float Score; }}5.3 TrainerBase 和 ITrainerBase
这个类是该实现的核心。从本质上讲,它有两个部分:一个是用于描述该类的接口;另一个是需要用具体实现重写的抽象类,不过,它实现了接口方法。下面是 ITrainerBase 的接口:
using Microsoft.ML.Data;namespace RandomForestClassification.MachineLearning.Common{ public interface ITrainerBase { string Name { get; } void Fit(string trainingFileName); BinaryClassificationMetrics Evaluate(); void Save(); }}该接口由 TrainerBase 类实现。但是,它是抽象的,因为我们希望注入特定的算法:
using Microsoft.ML;using Microsoft.ML.Data;using Microsoft.ML.Trainers;using Microsoft.ML.Trainers.Recommender;using Microsoft.ML.Transforms;using RecommendationSystem.MachineLearning.DataModels;using System;using System.IO;namespace RecommendationSystem.MachineLearning.Common{ /// <summary> /// Base class for Trainers. /// This class exposes methods for training, evaluating and saving ML Models. /// </summary> public abstract class TrainerBase : ITrainerBase { public string Name { get; protected set; } protected static string ModelPath => Path.Combine(AppContext.BaseDirectory, "recommender.mdl"); protected readonly MLContext MlContext; protected DataOperationsCatalog.TrainTestData _dataSplit; protected ITrainerEstimator<MatrixFactorizationPredictionTransformer, MatrixFactorizationModelParameters> _model; protected ITransformer _trainedModel; protected TrainerBase() { MlContext = new MLContext(111); } /// <summary> /// Train model on defined data. /// </summary> /// <param name="trainingFileName"></param> public void Fit(string trainingFileName) { if (!File.Exists(trainingFileName)) { throw new FileNotFoundException($"File {trainingFileName} doesn't exist."); } _dataSplit = LoadAndPrepareData(trainingFileName); var dataProcessPipeline = BuildDataProcessingPipeline(); var trainingPipeline = dataProcessPipeline.Append(_model); _trainedModel = trainingPipeline.Fit(_dataSplit.TrainSet); } /// <summary> /// Evaluate trained model. /// </summary> /// <returns>RegressionMetrics object.</returns> public RegressionMetrics Evaluate() { var testSetTransform = _trainedModel.Transform(_dataSplit.TestSet); return MlContext.Regression.Evaluate(testSetTransform); } /// <summary> /// Save Model in the file. /// </summary> public void Save() { MlContext.Model.Save(_trainedModel, _dataSplit.TrainSet.Schema, ModelPath); } /// <summary> /// Feature engeneering and data pre-processing. /// </summary> /// <returns>Data Processing Pipeline.</returns> private EstimatorChain<ValueToKeyMappingTransformer> BuildDataProcessingPipeline() { var dataProcessPipeline = MlContext.Transforms.Conversion.MapValueToKey( inputColumnName: "UserId", outputColumnName: "UserIdEncoded") .Append(MlContext.Transforms.Conversion.MapValueToKey( inputColumnName: "MovieId", outputColumnName: "MovieIdEncoded")) .AppendCacheCheckpoint(MlContext); return dataProcessPipeline; } private DataOperationsCatalog.TrainTestData LoadAndPrepareData(string trainingFileName) { IDataView trainingDataView = MlContext.Data.LoadFromTextFile<MovieRating> (trainingFileName, hasHeader: true, separatorChar: ','); return MlContext.Data.TrainTestSplit(trainingDataView, testFraction: 0.1); } }}这是一个大类,它控制着整个过程。我们把它拆开,看看它到底是怎么回事。首先,我们观察这个类的字段和属性:
public string Name { get; protected set; } protected static string ModelPath => Path.Combine(AppContext.BaseDirectory, "recommender.mdl"); protected readonly MLContext MlContext; protected DataOperationsCatalog.TrainTestData _dataSplit; protected ITrainerEstimator<MatrixFactorizationPredictionTransformer, MatrixFactorizationModelParameters> _model; protected ITransformer _trainedModel;继承该属性的类使用 Name 属性为算法添加名称。ModelPath 字段用于定义模型训练完成后将其存储在何处。注意,文件名的扩展名是 .mdl。接下来是 MlContext,以便我们能够使用 ML.NET 的功能。不要忘记,这个类是一个单例,因此在我们的解决方案中只有一个。_dataSplit 字段包含加载的数据。该结构将数据分割成训练数据集和测试数据集。
子类将使用字段 _model。这些类定义了该字段中使用哪种机器学习算法。_trainedModel 字段是结果模型,应该对其进行评估和保存。从本质上讲,继承和实现此类的唯一工作是定义应该使用的算法,通过实例化作为 _model 的所需算法的对象。
现在让我们来探索 Fit() 方法:
public void Fit(string trainingFileName){ if (!File.Exists(trainingFileName)) { throw new FileNotFoundException($"File {trainingFileName} doesn't exist."); } _dataSplit = LoadAndPrepareData(trainingFileName); var dataProcessPipeline = BuildDataProcessingPipeline(); var trainingPipeline = dataProcessPipeline.Append(_model); _trainedModel = trainingPipeline.Fit(_dataSplit.TrainSet);}这个方法是训练算法的蓝图。它接收 .csv 文件的路径作为输入参数。确定文件存在之后,我们使用私有方法 loadAndPrepareData。该方法将数据加载到内存中,并将其分割成两个数据集,即训练数据集和测试数据集。在 _dataSplit 中保存返回值,因为我们需要一个用于评估阶段的测试数据集。接着我们调用 BuildDataProcessingPipeline()。
这就是进行数据预处理和特征工程的方法。对于这些数据,无需做大量工作,我们只需通过以下方式对其进行编码:
private EstimatorChain<ValueToKeyMappingTransformer> BuildDataProcessingPipeline() { var dataProcessPipeline = MlContext.Transforms.Conversion.MapValueToKey( inputColumnName: "UserId", outputColumnName: "UserIdEncoded") .Append(MlContext.Transforms.Conversion.MapValueToKey( inputColumnName: "MovieId", outputColumnName: "MovieIdEncoded")) .AppendCacheCheckpoint(MlContext); return dataProcessPipeline; }接下来是 Evaluate() 方法:
public RegressionMetrics Evaluate(){ var testSetTransform = _trainedModel.Transform(_dataSplit.TestSet); return MlContext.Regression.Evaluate(testSetTransform);}通过使用 _trainedModel 和测试数据集创建 Transformer 对象是一种非常简单的方法。接着,利用 MlContext 来检索回归指标。最后,让我们看看 Save() 方法。
public void Save(){ MlContext.Model.Save(_trainedModel, _dataSplit.TrainSet.Schema, ModelPath);}这是另一个简单的方法,只是使用 MLContext 将模型保存到定义的路径中。
5.4 训练器
因为我们在 TrainerBase 类中完成了所有繁重的工作,所以唯一的 Trainer 类非常简单,只专注于 ML.NET 算法的实例化。下面看看 RandomForestTrainer 类:
using Microsoft.ML;using Microsoft.ML.Trainers.Recommender;using RecommendationSystem.MachineLearning.Common;namespace RecommendationSystem.MachineLearning.Trainers{ /// <summary> /// Class that uses Decision Tree algorithm. /// </summary> public sealed class MatrixFactorizationTrainer : TrainerBase { public MatrixFactorizationTrainer(int numberOfIterations, int approximationRank, double learningRate) : base() { Name = $"Matrix Factorization {numberOfIterations}-{approximationRank}"; _model = MlContext.Recommendation().Trainers.MatrixFactorization( labelColumnName: "Label", matrixColumnIndexColumnName: "UserIdEncoded", matrixRowIndexColumnName: "MovieIdEncoded", approximationRank: approximationRank, learningRate: learningRate, numberOfIterations: numberOfIterations); } }}正如你所看到的那样,这个类非常简单。我们覆写了 Name 和 _model。在 Recommendation 扩展中使用 MatrixFactorization 类。注意,我们是如何使用这个算法所提供的一些超参数的。有了这个,我们可以做更多的实验。
5.5 预测器
Predictor 类用于加载保存的模型并运行一些预测。通常,这个类与训练器不是同一个微服务的一部分。我们通常有一个微服务来执行模型的训练。该模型被保存到文件中,其他模型从该文件加载该模型,并基于用户输入运行预测。该类看上去如下:
using RecommendationSystem.MachineLearning.DataModels;using Microsoft.ML;using System;using System.IO;namespace RecommendationSystem.MachineLearning.Predictors{ /// <summary> /// Loads Model from the file and makes predictions. /// </summary> public class Predictor { protected static string ModelPath => Path.Combine(AppContext.BaseDirectory, "recommender.mdl"); private readonly MLContext _mlContext; private ITransformer _model; public Predictor() { _mlContext = new MLContext(111); } /// <summary> /// Runs prediction on new data. /// </summary> /// <param name="newSample">New data sample.</param> /// <returns>Prediction object</returns> public MovieRatingPrediction Predict(MovieRating newSample) { LoadModel(); var predictionEngine = _mlContext.Model.CreatePredictionEngine<MovieRating, MovieRatingPrediction>(_model); return predictionEngine.Predict(newSample); } private void LoadModel() { if (!File.Exists(ModelPath)) { throw new FileNotFoundException($"File {ModelPath} doesn't exist."); } using (var stream = new FileStream(ModelPath, FileMode.Open, FileAccess.Read, FileShare.Read)) { _model = _mlContext.Model.Load(stream, out _); } if (_model == null) { throw new Exception($"Failed to load Model"); } } }}简单地说,模型是从已定义的文件加载,并预测新的样本。要做到这一点,我们需要创建 PredictionEngine 来执行此操作。
5.6 用法和结果
让我们把所有这些放在一起。
using RecommendationSystem.MachineLearning.Common;using RecommendationSystem.MachineLearning.DataModels;using RecommendationSystem.MachineLearning.Predictors;using RecommendationSystem.MachineLearning.Trainers;using System;using System.Collections.Generic;namespace RecommendationSystem{ class Program { static void Main(string[] args) { var newSample = new MovieRating { UserId = 6, MovieId = 11 }; var trainers = new List<ITrainerBase> { new MatrixFactorizationTrainer(10, 50, 0.1), new MatrixFactorizationTrainer(10, 50, 0.01), new MatrixFactorizationTrainer(20, 100, 0.1), new MatrixFactorizationTrainer(20, 100, 0.01), new MatrixFactorizationTrainer(30, 100, 0.1), new MatrixFactorizationTrainer(30, 100, 0.01) }; trainers.ForEach(t => TrainEvaluatePredict(t, newSample)); } static void TrainEvaluatePredict(ITrainerBase trainer, MovieRating newSample) { Console.WriteLine("*******************************"); Console.WriteLine($"{ trainer.Name }"); Console.WriteLine("*******************************"); trainer.Fit(".\\Data\\recommendation-ratings.csv"); var modelMetrics = trainer.Evaluate(); Console.WriteLine($"Loss Function: {modelMetrics.LossFunction:0.##}{Environment.NewLine}" + $"Mean Absolute Error: {modelMetrics.MeanAbsoluteError:#.##}{Environment.NewLine}" + $"Mean Squared Error: {modelMetrics.MeanSquaredError:#.##}{Environment.NewLine}" + $"RSquared: {modelMetrics.RSquared:0.##}{Environment.NewLine}" + $"Root Mean Squared Error: {modelMetrics.RootMeanSquaredError:#.##}"); trainer.Save(); var predictor = new Predictor(); var prediction = predictor.Predict(newSample); Console.WriteLine("------------------------------"); Console.WriteLine($"Prediction: {prediction.Score:#.##}"); Console.WriteLine("------------------------------"); } }}非 TrainEvaluatePredict() 方法在这里做的是重头戏。使用这个方法,我们可以注入继承 TrainerBase 类的一个实例,以及一个新的样本,以便进行预测。接着调用 Fit() 方法对算法进行训练,并调用 Evaluate() 方法、打印出指标。最后,我们保存该模型。这样做之后,我们创建一个 Predictor 的实例,用一个新的样本调用 Predict() 方法,并打印出预测结果。在 Main 中,我们创建一个训练器对象列表,然后在这些对象上调用 TrainEvaluatePredict。
我们根据这些超参数创建了算法列表中随机森林的一些变体。结果如下:
*******************************Matrix Factorization 10-50*******************************iter tr_rmse obj 0 1.4757 2.4739e+05 1 0.9161 1.2617e+05 2 0.8666 1.1798e+05 3 0.8409 1.1348e+05 4 0.8240 1.1079e+05 5 0.8100 1.0897e+05 6 0.7980 1.0736e+05 7 0.7847 1.0575e+05 8 0.7691 1.0405e+05 9 0.7549 1.0284e+05Loss Function: 0.77Mean Absolute Error: .68Mean Squared Error: .77RSquared: 0.29Root Mean Squared Error: .88------------------------------Prediction: 3.94------------------------------*******************************Matrix Factorization 10-50*******************************iter tr_rmse obj 0 3.1309 9.0205e+05 1 2.3707 5.4640e+05 2 1.7857 3.3435e+05 3 1.5459 2.6501e+05 4 1.4055 2.2888e+05 5 1.3103 2.0634e+05 6 1.2430 1.9129e+05 7 1.1902 1.8002e+05 8 1.1493 1.7159e+05 9 1.1185 1.6546e+05Loss Function: 1.27Mean Absolute Error: .89Mean Squared Error: 1.27RSquared: -0.17Root Mean Squared Error: 1.13------------------------------Prediction: 4.01------------------------------*******************************Matrix Factorization 20-100*******************************iter tr_rmse obj 0 1.5068 2.5551e+05 1 0.9232 1.2707e+05 2 0.8675 1.1773e+05 3 0.8426 1.1358e+05 4 0.8260 1.1082e+05 5 0.8116 1.0874e+05 6 0.7984 1.0705e+05 7 0.7849 1.0547e+05 8 0.7699 1.0374e+05 9 0.7556 1.0222e+05 10 0.7407 1.0084e+05 11 0.7252 9.9587e+04 12 0.7108 9.8130e+04 13 0.6962 9.6890e+04 14 0.6845 9.6048e+04 15 0.6718 9.4877e+04 16 0.6615 9.4167e+04 17 0.6510 9.3413e+04 18 0.6419 9.2767e+04 19 0.6322 9.1971e+04Loss Function: 0.75Mean Absolute Error: .67Mean Squared Error: .75RSquared: 0.31Root Mean Squared Error: .86------------------------------Prediction: 4.06------------------------------*******************************Matrix Factorization 20-100*******************************iter tr_rmse obj 0 3.1188 8.9340e+05 1 2.4196 5.6643e+05 2 1.8203 3.4467e+05 3 1.5710 2.7129e+05 4 1.4210 2.3212e+05 5 1.3245 2.0894e+05 6 1.2559 1.9343e+05 7 1.2024 1.8189e+05 8 1.1592 1.7289e+05 9 1.1247 1.6594e+05 10 1.0956 1.6027e+05 11 1.0717 1.5566e+05 12 1.0506 1.5171e+05 13 1.0326 1.4838e+05 14 1.0169 1.4550e+05 15 1.0032 1.4306e+05 16 0.9907 1.4085e+05 17 0.9798 1.3893e+05 18 0.9698 1.3718e+05 19 0.9610 1.3563e+05Loss Function: 0.99Mean Absolute Error: .78Mean Squared Error: .99RSquared: 0.09Root Mean Squared Error: .99------------------------------Prediction: 3.92------------------------------*******************************Matrix Factorization 30-100*******************************iter tr_rmse obj 0 1.4902 2.5094e+05 1 0.9364 1.2934e+05 2 0.8672 1.1737e+05 3 0.8428 1.1349e+05 4 0.8264 1.1104e+05 5 0.8114 1.0883e+05 6 0.7966 1.0681e+05 7 0.7836 1.0532e+05 8 0.7698 1.0378e+05 9 0.7540 1.0209e+05 10 0.7402 1.0089e+05 11 0.7248 9.9437e+04 12 0.7098 9.7999e+04 13 0.6966 9.6791e+04 14 0.6826 9.5745e+04 15 0.6687 9.4572e+04 16 0.6593 9.3841e+04 17 0.6480 9.3017e+04 18 0.6404 9.2448e+04 19 0.6321 9.1986e+04 20 0.6238 9.1298e+04 21 0.6160 9.0879e+04 22 0.6090 9.0430e+04 23 0.6025 9.0006e+04 24 0.5962 8.9550e+04 25 0.5909 8.9269e+04 26 0.5859 8.9011e+04 27 0.5809 8.8598e+04 28 0.5764 8.8393e+04 29 0.5714 8.8086e+04Loss Function: 0.74Mean Absolute Error: .67Mean Squared Error: .74RSquared: 0.32Root Mean Squared Error: .86------------------------------Prediction: 3.98------------------------------*******************************Matrix Factorization 30-100*******************************iter tr_rmse obj 0 3.1699 9.2239e+05 1 2.4110 5.6279e+05 2 1.8361 3.4988e+05 3 1.5652 2.6961e+05 4 1.4201 2.3188e+05 5 1.3248 2.0902e+05 6 1.2537 1.9291e+05 7 1.2017 1.8175e+05 8 1.1583 1.7271e+05 9 1.1237 1.6575e+05 10 1.0953 1.6017e+05 11 1.0711 1.5555e+05 12 1.0502 1.5162e+05 13 1.0324 1.4834e+05 14 1.0168 1.4549e+05 15 1.0036 1.4316e+05 16 0.9905 1.4080e+05 17 0.9795 1.3886e+05 18 0.9697 1.3715e+05 19 0.9607 1.3558e+05 20 0.9526 1.3418e+05 21 0.9452 1.3293e+05 22 0.9384 1.3175e+05 23 0.9322 1.3070e+05 24 0.9265 1.2976e+05 25 0.9211 1.2883e+05 26 0.9163 1.2802e+05 27 0.9118 1.2727e+05 28 0.9075 1.2653e+05 29 0.9036 1.2589e+05Loss Function: 0.9Mean Absolute Error: .74Mean Squared Error: .9RSquared: 0.17Root Mean Squared Error: .95------------------------------Prediction: 3.86------------------------------我们使用用户 ID-6 和电影 ID-11 进行测试。如果你看一下数据集,你会发现这一对和评级是 4。 正如你所看到的那样,大多数矩阵分解的变体都很好用。迭代 10 次,近似秩 50,学习率 0.01 的变化似乎最接近。而且,它的指标似乎也非常好。但是,还需要进一步的测试才能确定那种变体表现最佳。
结语
本文涉及了很多方面。我们了解了不同类型的推荐系,接着研究了协同过滤和矩阵分解。另外,我们也有机会了解如何将其应用于电影推荐。最终,我们使用 ML.NET 实现了这一切。
作者介绍:
Nikola M. Zivkovic,是 Rubik's Code 的首席人工智能官,也是《Deep Learning for Programmers》(尚无中译本)一书的作者。热爱知识分享,是一位经验丰富的演讲者,也是塞尔维亚诺维萨德大学的客座讲师。
原文链接:
https://rubikscode.net/2021/03/15/machine-learning-with-ml-net-recommendation-systems/




