
现代技术栈通常会至少包括一个前端和一个后端,但它很快就会演变成需要包含一个数据平台。这通常是由于需要特定的分析和报表,但它也可能会演变成一个完整的“炼油厂”,包括 cron 作业、仪表盘、批量数据复制等等。一般来说,需要推到数据平台的功能通常是:
延迟不是很关键,因此可以更晚地运行,延时可能长达 24 小时(与处于请求-响应周期中的响应式同步作业相反)
更容易表达成在大型数据集上操作的批处理作业,而不是对每个请求所进行的操作
报表就是一个很好的例子。假设你需要将所有交易导入到你的核算系统。比起直接在后端执行,编写一个每隔 24 小时执行一次的脚本可能更容易一些。
另一个例子是训练机器学习模型。假设你正在构建一个欺诈检测系统,并且有一个机器学习模型来检测某些用户行为是否具有欺诈性。训练模型可能需要一个小时,但预测却很快。每隔 24 小时甚至每周或每月对模型进行一次重新训练要容易得多。然后,你可以序列化模型,并在后端系统中使用它进行预测。
在 Spotify,数据平台是从版税报表开始的,但很快就用它将排行榜重构成每晚的数据作业了。数据平台不断发展壮大,尤其是音乐推荐系统中,它已经成为一条庞大的数据管道了。我们每隔几周就对核心模型进行一次重新训练,但通常每晚都会重新生成个性化推荐。对于人们需要的推荐来说,这种频率已经足够了。
为什么要这么麻烦呢?
为什么要这么麻烦地使用数据平台呢?因为通常情况下,能使产品的构建和交付容易 10 倍。将工作从后端推送到单独的数据平台有助于实现以下几点:
你不必担心延迟。
你可以自己控制流(而不是听命于等待响应的用户请求)
一般来说,你可以用一种更能容错的方式来编码(批处理通常更容易编写成一组幂等的运算)
批处理的效率更高(为 1,000,000 个用户生成音乐推荐可能只比为 1 个用户生成音乐推荐多 1000 倍的工作量)
如果失败了,这也不是世界末日,因为你通常可以在第二天修复 bug 后重新运行作业。
例如,假设要构建一个能够实时更新的全球头条的基本功能,比如在新闻网站上显示头条新闻。我敢打赌,与在数据平台中构建一个每小时或每天更新一次并将结果推回到后端的 cron 作业相比,纯粹地在后端完成这项工作要困难得多。
那么,你是否做到了(以最少的技巧)?
当然,后端架构更成熟一些,大约有 1000 篇关于其最佳实践的博客文章。比如,我首先想到的就是Martin Fowler。当我们构建后端系统时,我们会被教导要注意以下内容:
避免集成数据库(每个系统都应该有自己的数据库,两个系统永远不能共用同一个数据库)
数据库查询应该尽可能地简单(通常引用一个确切的键,并且连接尽可能少的表,理想情况下应该为零)
使用事务(以及约束、键、etc)确保数据的完整性
大量的单元测试
大量的集成测试
将较大的服务(也称为“单体”)拆解为较小的服务(也称为“微服务”)
无论如何,当你进入数据平台时,你可以把这些中的全部或大部分都扔出去了!

油画描绘的是 1618 年的布拉格扔出窗外事件(defenestration of Prague)
数据端:“狂野的西部”
我所看到的基础设施通常以如下的某一点来作为起点:
后端日志被发送到某些数据存储中
后端的生产数据库被转储到某些数据存储中
在过去,这个数据存储通常是 Hadoop(HDFS),但如今它通常是一些可扩展的数据库,比如 Redshift。有很多不同的解决方案,在这里我就不展开介绍了。
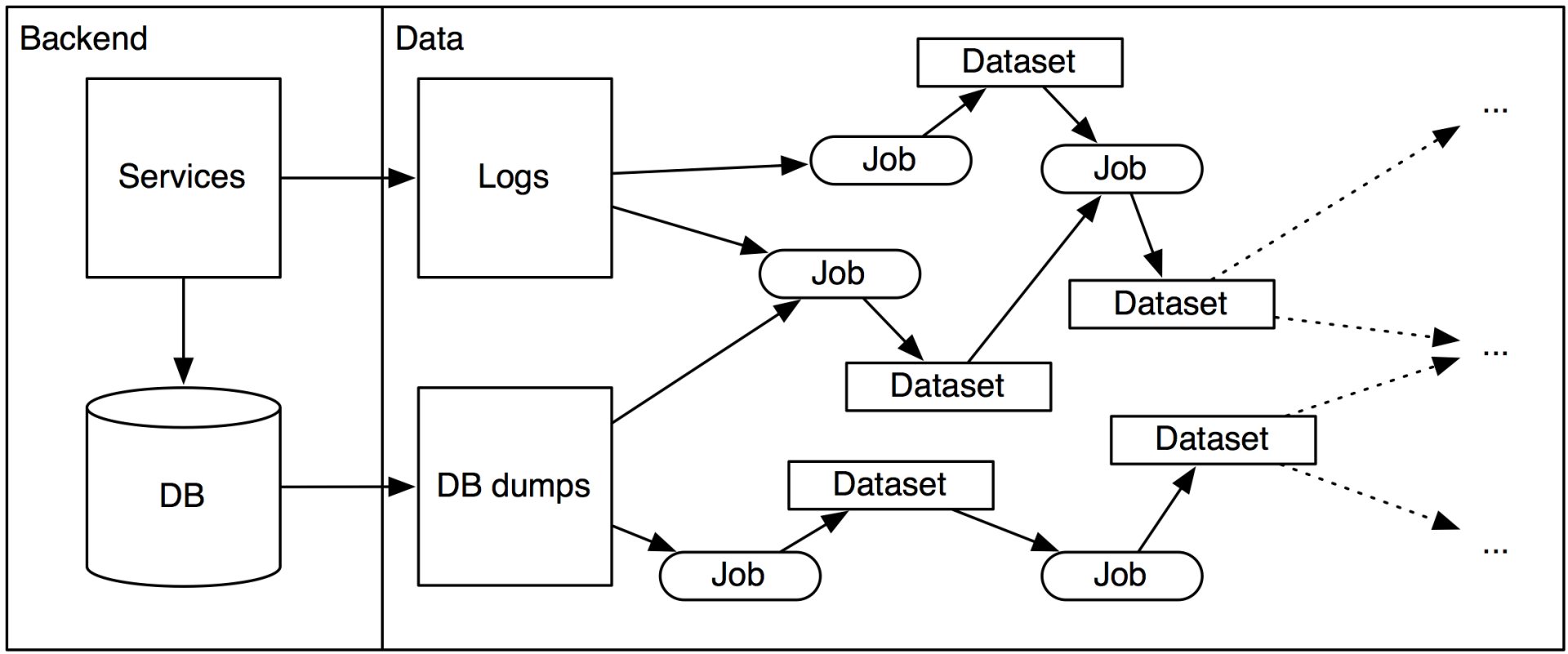
数据延迟的注意事项
数据平台中的任何内容通常都会延迟(在 Spotify 上,通常会延迟 24 小时甚至更长)。如果它没有延迟,也应该认为它是延迟的,这意味着对数据的任何操作,延迟都不应该是至关重要的。
你能拥有一个操作实时数据库数据而不是操作有延迟的数据转储的数据平台吗?在理论上是可以的。但我认为这会助长不良的行为。例如,如果在生产数据库上运行 cron 作业,很容易做一些诸如将数据写回数据库的事情,这样就创建了一个集成数据库,该数据库的同一个表有多个写入者和读取者。这可真是一团糟!因此,正确的分离应该是(a)cron 作业操作延迟的数据(b)任何返回后端系统的通信都通过内部端点进行。
还有一点要注意:不要让业务人员访问实时数据!否则他们提的任何需求都会要求基于此,而你将不得不永远支持它。
不管怎样,数据端会发生什么?根据我的经验,我认为,任何事情都会发生。下面我们来讨论其中的一些:
集成数据库
例如,传统的约束是服务不应该接触到彼此的数据库,并且这些层应该备受推崇。这就避免了所谓的“集成数据库”反模式,即同一数据有多个写入者和读取者。在数据世界里,这条规则已经过时了。在数据端,我发现完全可以加入来自不同服务的 3 个不同数据集。为什么这是可以接受的呢?我认为可以归结为以下三点:
破坏任何下游使用者的模式更改并不是世界末日,只需更新一些查询即可,仅此而已。
如果出现问题,则通常可以修复后并重新运行作业。如果在 UTC 午夜没有生成某些报表,你也可以在接下来的几个小时内修复该作业,也几乎没有人会抱怨。
所有查询都是只读的,这意味着你永远不必担心事务的完整性或读取不一致的数据。
我的结论是,集成数据库对于后端系统来说是很糟糕的,但是对数据层来说却非常棒。
大型查询
后端系统必须处理低延迟、低吞吐量的查询,通常一次只涉及一个用户。由于该用户发出请求并等待响应,因此查询需要很快。那么如何使查询更快呢?
尽量避免连接,如果需要,坚持使用非常简单的索引连接(通常是
left join from table A to B)每个查询都应引用一个特定的项 ID,例如
... where user_id = 234或类似的
每当我在后端系统中看到任何比关联几个表并带一两个 where 条件更复杂的查询时,我都会产生难以置信的怀疑。
在数据世界里,这些都不重要。几乎所有的查询都将“跨越”所有/大部分数据,事实上,大多数查询都将归结为“全表扫描”。难道跨越页的查询看起来不像是 20 世纪早期的德国哲学家写的吗?魅力四射!
这基本上就是 OLTP(on-line transaction processing,联机事务处理)和 OLAP(On-Line Analytical Processing,联机分析处理)之间的区别,它们是不同类型的查询模式。如果你愿意深入研究的话,也有很多的文章可以参考!
测试
写到这里我有些抱歉,也许是带着一种负罪感,因为我承认了一些黑暗的秘密。我非常支持非常全面的测试,但是在数据端要达到合理的测试覆盖率是很难的。
对于后端系统,你可以实现类似于 y=f(x) 这样的函数,其中 x 是一个输入(比如来自第三方 API 的响应), y 是结果(例如,将 API 响应转换为内部表示)。这真的很容易测试!有时你的函数是类似 Sn+1=f(Sn,A) 这样的,其中 Si 是“状态”, A 某些动作,但是状态和动作都非常小,可以在单元测试中很好地表示出来。
在数据端,x 和Si 都是很庞大的。这意味着只要设置所有的输入数据,任何单元测试基本上都会达到 99%。但是由于输入数据是超高维的,因此这也意味着边界情况的建模变得更加困难。更麻烦的是,数据管道通常是不确定的(机器学习模型),或者具有非常主观的输出,以至于你不能简单地编写一堆断言。由于所有这些原因,我发现数据管道的测试保真度很低(它们捕获到的 bug 很少),而且维护成本很高。伤心!我喜欢做一些基本的测试来确保其运行正常,但是验证正确性可能并不总是值得的。
结论
我发现,将尽可能多的功能从后端推到数据平台是非常有用的。这些功能包括:
向用户发送(非事务性)电子邮件(如个性化营销电子邮件)
生成搜索索引
生成推荐
报表
生成业务人员需要的数据
训练机器学习模型
所有这些都可以构建到后端系统中,但应该作为 cron 作业在数据平台中运行。这能使代码的复杂度降低(大致)一个数量级。
原文链接:
https://erikbern.com/2019/01/10/data-architecture-vs-backend-architecture.html




