
智能对话系统因其巨大的潜力和商业价值受到越来越多研究者和从业者的关注,对话的主要种类包括闲聊型、知识型、任务型、阅读理解型等,目前已经广泛应用在智能客服、智能音箱、智能车载等众多场景。近年来,智能对话还出现了新的应用场景,例如可以将自然语言转换为各种程序性语言,例如 SQL,从数据库中找到相应的答案,让用户和数据库的交互变得更加直接和方便。
为此,Datafun 发布了百分点首席算法科学家苏海波署名文章,文中主要介绍了智能问答中的问题语义等价模型、知识图谱问答模型、NL2SQL 模型,以及百分点在智能问答领域的实践案例。
智能问答的典型场景
1. 典型的智能问答应用场景
在典型的智能问答应用场景中包括:
闲聊式,开放域闲聊的典型例子,包括问天气,寒暄,情感陪伴等。
任务导向式对话,任务驱动的多轮对话的例子,包括智能音箱,语音智能点餐服务,这是特定任务模式下的服务。
信息问答式,知识型问答,回答信息,例如问姚明的身高等,是用作获取信息的服务。
2. 典型的智能问答对比应用场景
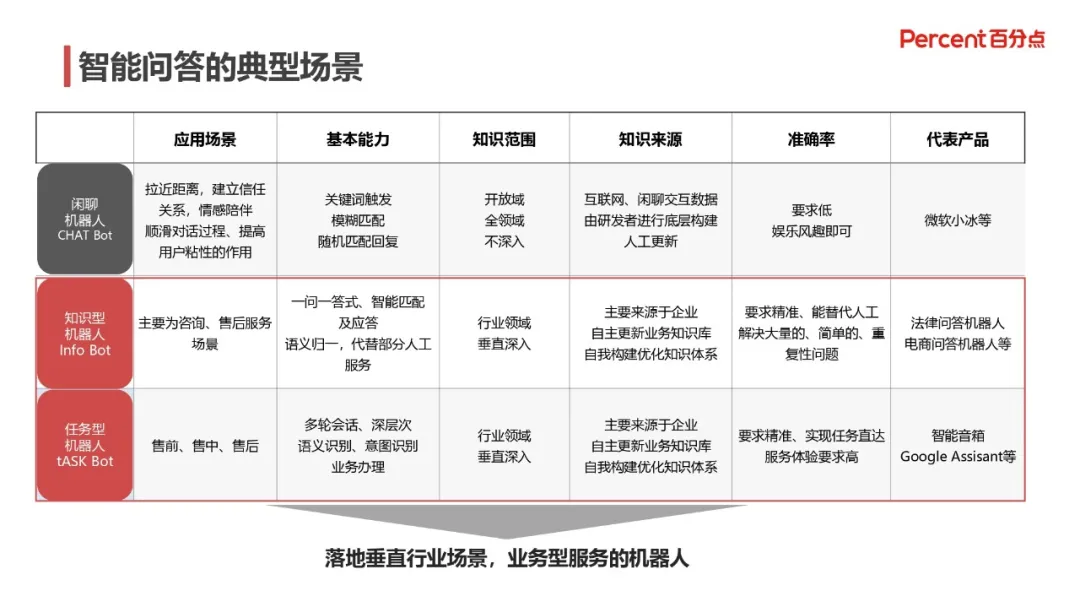
闲聊机器人,在拉近距离、建立信任关系、情感陪伴、顺滑对话过程、以及提高用户粘性等方面发挥着作用,一般以关键词触发,模糊匹配回复,知识范围为不深入的开放领域,数据与知识来自于互联网、闲聊交互开发者定期更新的数据。
知识型机器人,主要应用于咨询和售后服务的场景,拥有一问一答,智能匹配应答,实现语义归一的能力,在实际使用中代替部分的人工服务,服务于垂直单一行业领域,这部分的数据主要来自于企业自主更新的业务知识库和不断优化的知识体系。
任务机器人,在售前,销售,售后均有涉及,可以进行多轮对话,实现深层语义识别,意图识别等任务,主要服务于明确具体的任务场景,数据同样来自于企业自主更新的业务知识库和不断优化的知识体系。
另外,知识型机器人和任务型机器人均属于为垂直行业领域服务的业务型机器人。
智能问答的产品架构
1. 智能问答的具体流程
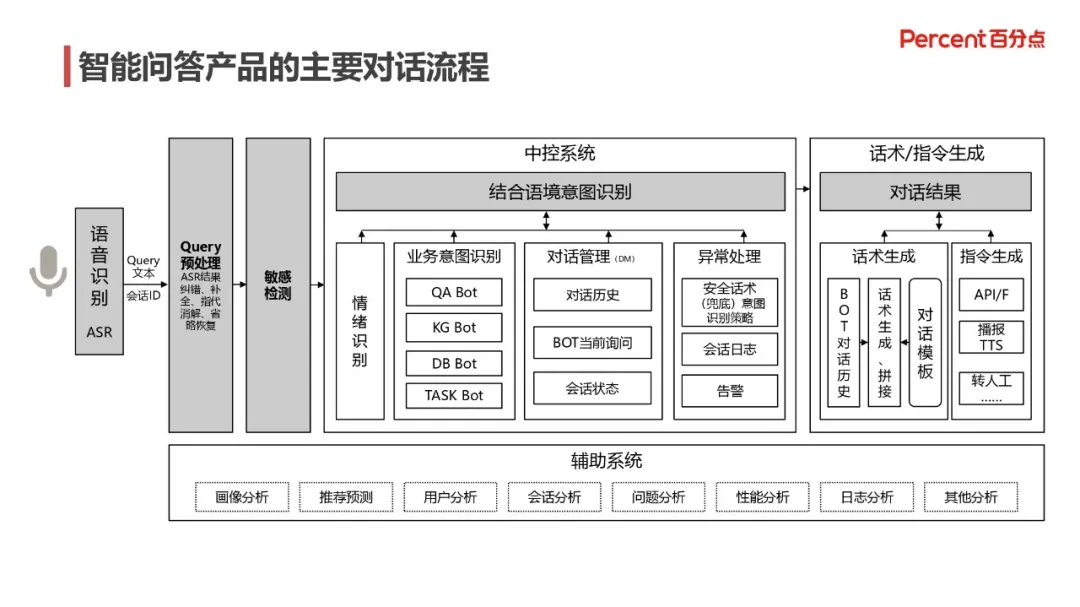
首先进行语音识别,将用户会话识别出来后,经过 ASR 结果纠错和补全、指代消解、省略恢复等预处理之后,经过敏感词检测,送入中控系统。中控系统是在特定语境下进行意图识别的系统,分为情绪识别、业务意图识别、对话管理、异常处理等四个模块,其中业务意图包括 QA 问答机器人(QA Bot)、基于知识图谱的问答机器人(KG Bot)、NL2SQL 机器人(DB Bot)、任务型机器人(TASK Bot)。对话管理包括多轮对话的对话历史管理、BOT 当前询问、会话状态选取等模块。异常处理包括安全话术(对意图结果的结果进行后处理)、会话日志记录、告警等功能。然后,进入话术/指令生成子系统,这是识别问句意图后的对话结果生成,包括话术生成和指令生成两个模块,在话术生成中,对话系统根据对话历史数据和对话模板生成和拼接产生话术,如果是任务型对话,将生成对应指令。另外,辅助系统通过画像分析、用户分析、问题分析等功能,进一步优化问答系统的效果。
2. 智能问答产品的具体架构
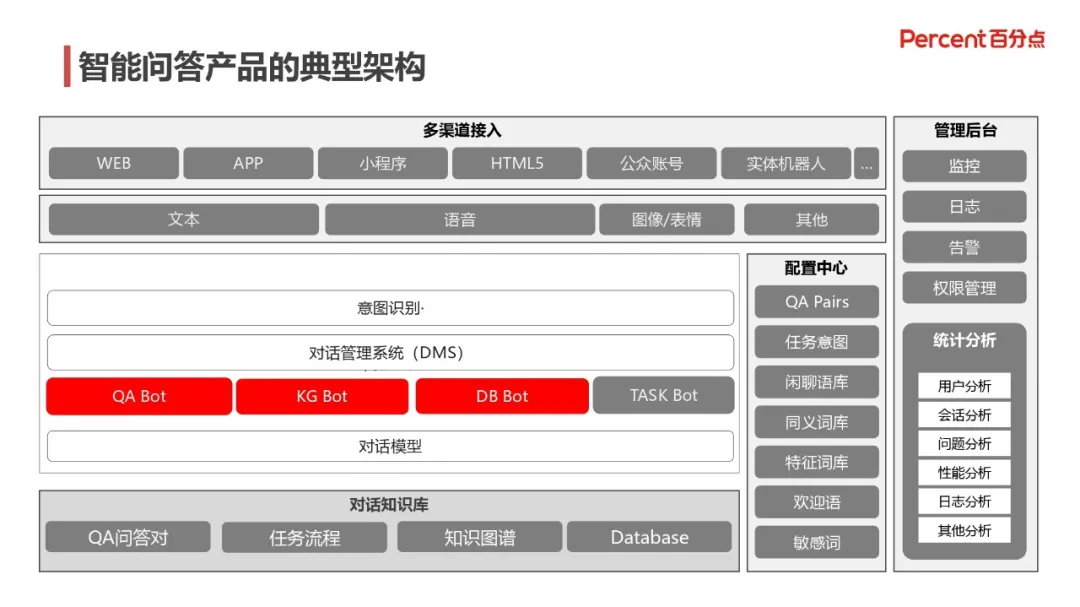
智能问答产品主要包括知识库、对话模型、配置中心、多渠道接入以及后台管理。针对不同的任务划分,准备不同的知识库,例如 QA BOT 需要引入问答知识对,KG BOT 需要知识图谱的支持等等。将针对不同任务的对话模型服务,部署接入各个平台接口,譬如小程序、微信、网页等,提供在线问答服务。配置中心主要提供 QA 对、闲聊语料、同义词库、特征词库等的可视化配置服务,实现知识配置的快速拓展。后台管理针对智能问答系统实施整体监控、日志管理、告警、权限管理等等,另外,它还提供各种维度的统计分析服务。
QA 知识问答的技术实现
1. QA 知识问答的简介
这是以智能匹配问答库为主要实现原理的问答机器人,将用户所提问题与问答库中的问题进行相似度匹配筛选,识别出语义等价的问题以及对应答案,完成对话。
首先用户访问 PC 网站或者公众号平台,通过语音描述要咨询的问题,输入 ASR 语音识别模块,将得到的问题经过纠错之后,进行问题语义等价的识别、相似问题的推荐,并对问答结果进行记录。经过一段时间的累积之后,后台就会得到实际应用中对于用户咨询问题的各种情况,这里包括未识别的问题、误识别的问题、新挖掘的高频问题,AI 算法团队针对这些问题进行优化,包括问题的新增、答案的优化、相似问题发掘、算法的优化等部分,并将这些重新梳理的数据作为补充的问答知识在人工审核之后录入知识库,持续迭代。另外,在实际的应用过程中,问答知识库的类型包括信息中心、组织人事处、后勤管理处、保卫处、计划财务处、离退休工作处等各种部门需要的业务知识数据。
2. 构建知识库的过程
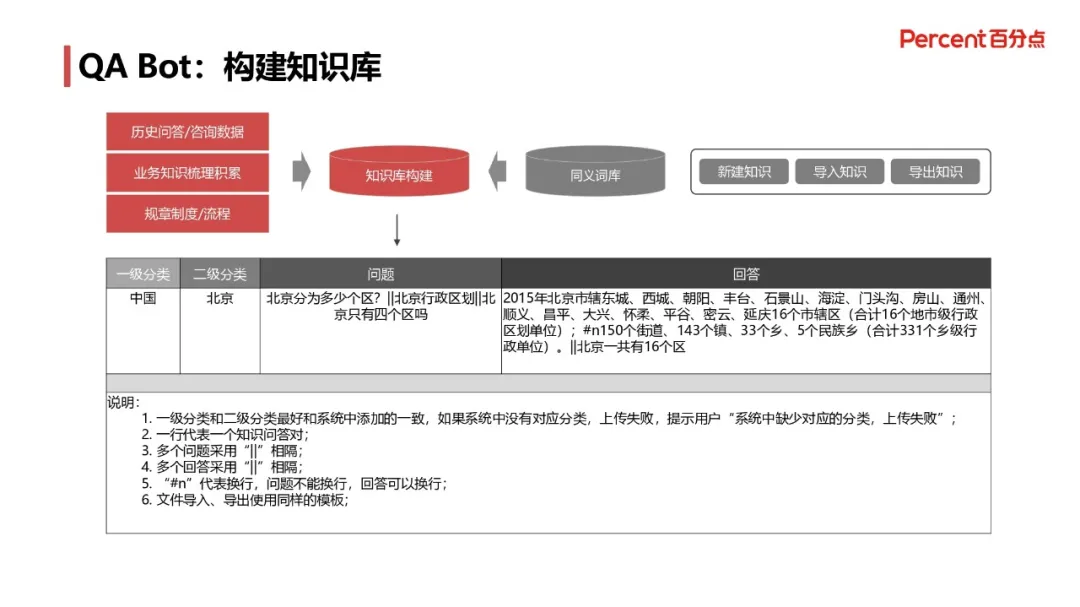
知识库的主要来源包括:历史的问答和咨询数据、业务知识梳理积累、规章制度和流程等内容、辅之以同义词词库等外部数据,在功能上设立新建知识、导出知识、导入知识等。举个例子来说明知识库的格式,例如“北京分为多少区||北京行政区划||北京有四个区吗”,这个个问题都是语义等价的,其一级分类为中国,二级分类为北京,对应的答案是“2015 年北京市辖东城、西城、朝阳、丰台、石景山、海淀、门头沟、房山、通州、顺义、昌平、大兴、怀柔、平谷、密云、延庆 16 个市辖区(合计 16 个地市级行政区划单位);#n150 个街道、143 个镇、33 个乡、5 个民族乡(合计 331 个乡级行政单位)。||北京一共有 16 个区;”如果新增问答知识,那么一级分类、二级分类、问题和回答是必须要添加的,以“||”作为分割多个问题和答案的分隔符等。
在配置中心,也可以通过可视化的配置功能,实现问答意图、QA 问答库、闲聊库等知识的快速创建以及分类管理。
3. 如何找到语义等价的问句
构建问答知识库之后,在检索知识库的过程中,最重要的是如何找到与输入语义等价的问句,如下图所示:
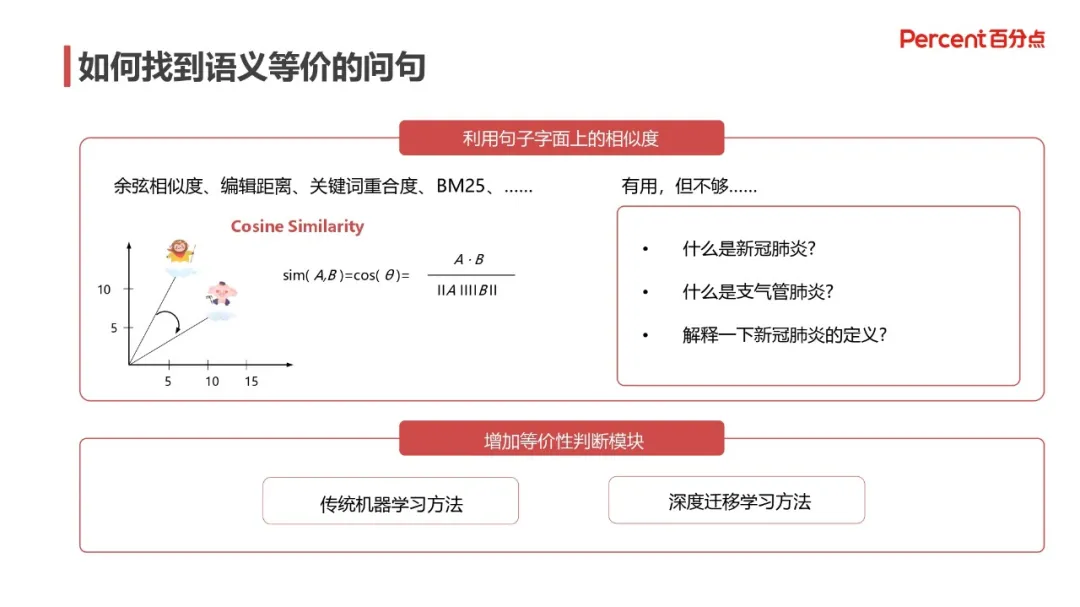
常用的相似度算法包括余弦相似度、编辑距离、关键词重合度、BM25 等等,实际使用中是有用,但仍然不够,因为可能遇到如下问题:
字面相似的句子语义不等价
字面不相似的句子语义等价
例如问题“什么是新冠肺炎”和“解释下新冠肺炎的定义”是语义等价,但和“什么是支气管肺炎”却不是语义等价的,采用编辑距离之类的算法是无法识别的。因而,只有基于语义理解的模型才能识别出来,这里包括两类,一是传统机器学习方法,二是深度迁移学习方法。
4. 基于 BERT 和 BIMPM 的语义等价模型方案
我们采用了基于 BERT 和 BIMPM 的语义等价模型方案,模型的网络结构如下图所示:
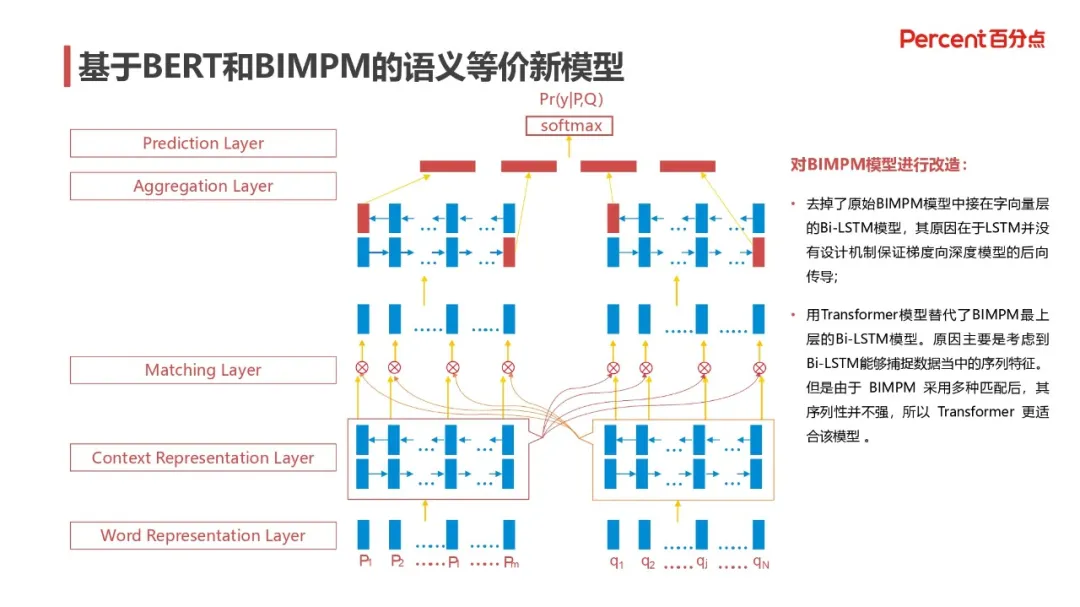
BIMPM 本身是十分经典的模型,底层是通过 word2vec 向量来进行语义匹配计算,这里我们将 word2vec 词向量全部替换为 BERT 的最上面若干层的输出,并将原有模型中的 BI-LSTM 结构,替换为 Transformer,以提高其在序列性上的表现,实际测试中,该模型在 Quora 和 SLNI 数据集中达到了 state-of-the-art 的效果,如下图所示:
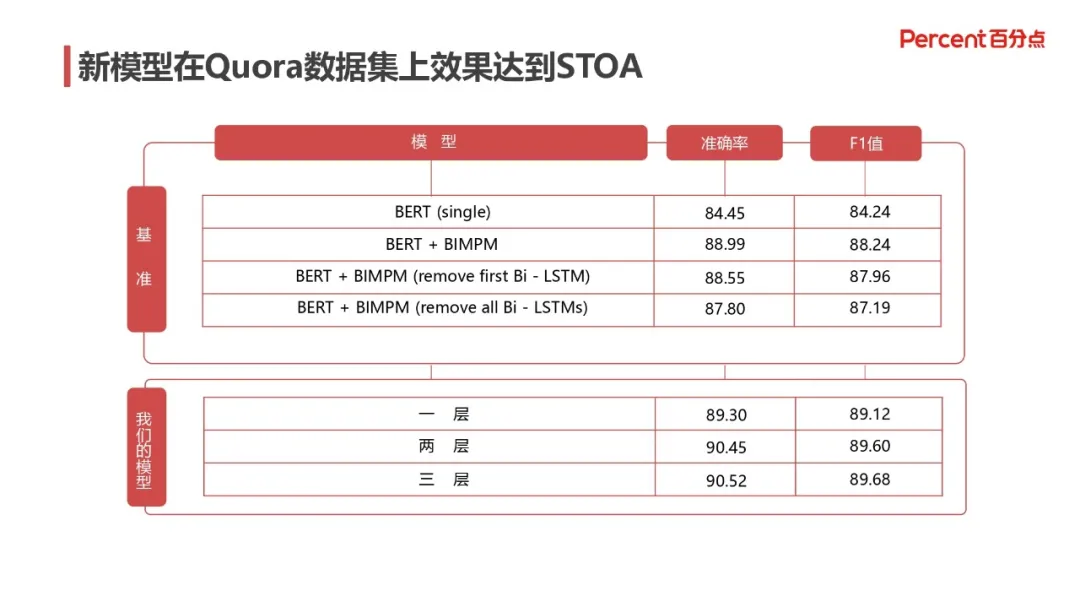
上面的表格中显示了 BERT 层数在效果表现上的差异,其中使用 BERT 最上面三层的参数,作为模型的输入,整体表现效果最佳。
5. 智能问答中语义等价模型
接下来介绍智能问答中语义等价模型的训练、优化和发布过程,该模型的目标是判断两个问句在语义上是否完全等价。
模型的具体训练和发布闭环流程,如下图所示:
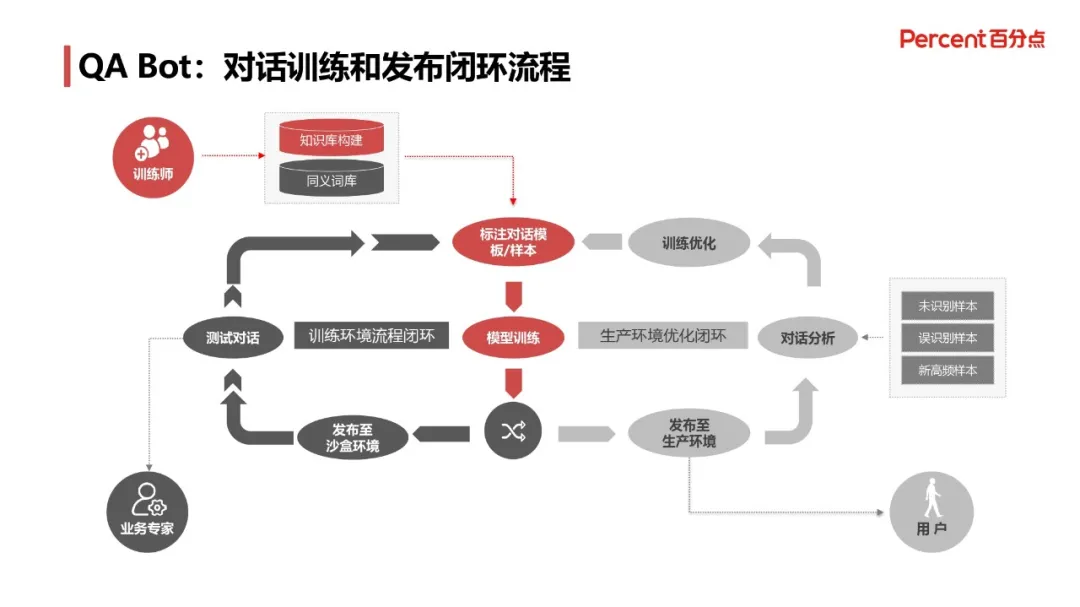
在完成对标注数据样本集的模型训练,生成模型之后,我们将在沙盒环境中测试模型的表现,针对模型表现不好的样本,提取并标注再放入数据集重新训练调优,模型发布至生产环境之后,针对实际使用中未识别样本、误识别样本和新高频样本做对话分析,进行模型优化后再重新发布模型。
实例:疫情问答系统
此问答系统基于上述技术,采用疫情相关的问答知识库,提供智能化、自动化的疫情知识问答,并且实现了实时统计数据、实时门诊咨询、实时数据咨询、协助求医报警等。

知识图谱问答的技术实现
1. 基于知识图谱问答的算法实现原理
本系统主要是通过将输入问句,转化为 SparQL 的语句,实现对知识图谱的智能问答,例如武汉大学出了那些科学家,需要识别出武汉大学和科学家的两个查询条件才能得到交集答案,当不能使用常规 NER 识别出实体的时候,可以将训练语料中的实体词汇导入到 ES 搜索引擎中,实现对一些难以识别样例的查询。具体实现原理,如下图所示:

首先针对用户问题,经过文本预处理,先进行实体识别,将实体送入别名词典和 ES 中去,得到备选的实体名称;再问题分类,这一步是为了得到问题结果的模板类型是什么,然后槽位预测,填写实体和关系槽位;在实体分析模块中,针对实体识别得到的备选实体,通过语义特征和人工特征进行实体消歧和实体检索,生成实体链接,并将实体填入 SparQL 查询模板语句之中;继而,根据上一步实体链接,找到实体在知识图谱中的所有关系,并对所有关系和用户问题语句进行语义匹配的排序,得到了相似度最高的关系路径,并将该实体在该关系下的结果填入 SparQL 的查询模板之中;最后,根据填写完成的查询语句,在图数据库之中检索校验,得到答案。
仔细来谈,在问题分类部分中,一个问题所属的类型有三个判断依据:
链式和夹式,链式解释其查询语句遵循链式查找,一步一步的查询;夹式是指查询的结果满足两个条件的交集;
问题的跳数,指的是需要建立的查询次数;
每一跳是问实体还是问关系。
2. 实体分析模块:实体链接
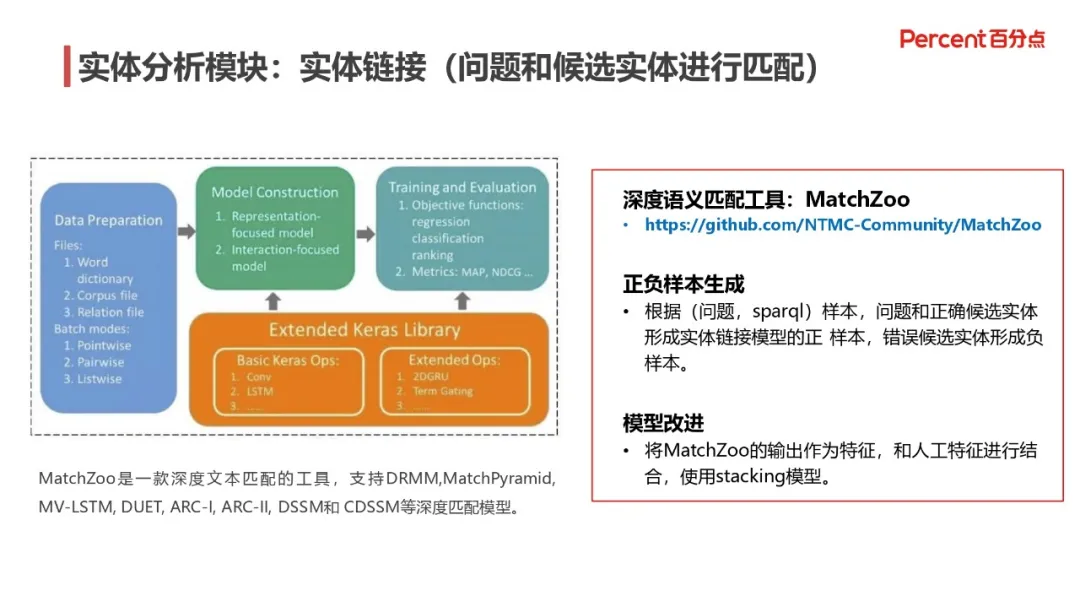
在实体分析模块,实体链接就是用来处理问题和候选实体进行匹配的步骤,以确定所需的实体究竟是哪一个实体,毕竟同名实体是比较常见的。MatcgZoo 是一款深度文本匹配的工具,支持 DRMM、MatchPyramid、MV-LSTM、DSSM 等深度匹配模型。采用该工具,我们需要准备实体匹配的正负样本,将<问题、SparQL>样本数据中,问题和正确的候选实体形成实体链接模型的正样本,错误候选实体形成负样本。在模型的改进方面,将上述得到的文本匹配特征和人工特征结合,使用 stacking 模型取得更好的效果。
3. 查询生成模块:路径排序
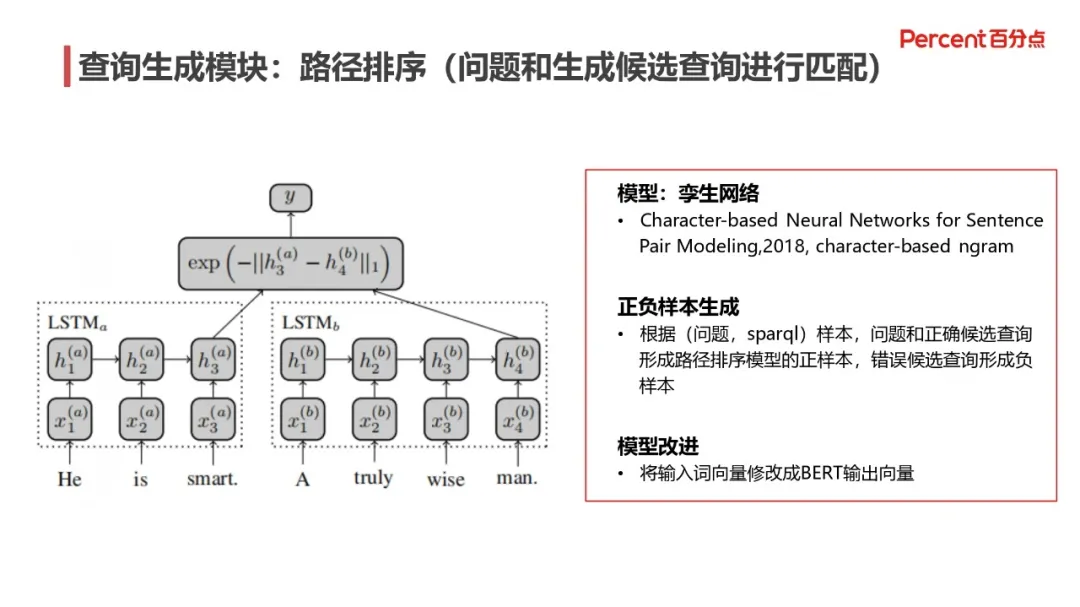
在查询生成模块,针对问题和生成候选查询匹配的问题上,就需要实现路径排序。这里使用了孪生网络来判断其语义相似度,正负样本生成与实体分析模块类似,在模型改进上,BERT 向量会比传统词向量取得更好的效果。
上面的方案在 2020CCKS 大赛上取得了 F1 为 0.901 的成绩,并部署在 GPU 平台上响应时间只需要 200ms。
NL2SQL 问答的技术实现
与上述两种问答类型不同的是,NL2SQL 问答不是基于问答对或者知识图谱知识库,它是基于结构化数据表进行智能问答,实现自然语言转 SQL 查询的功能。
1. NL2SQL 问答的技术实现原理
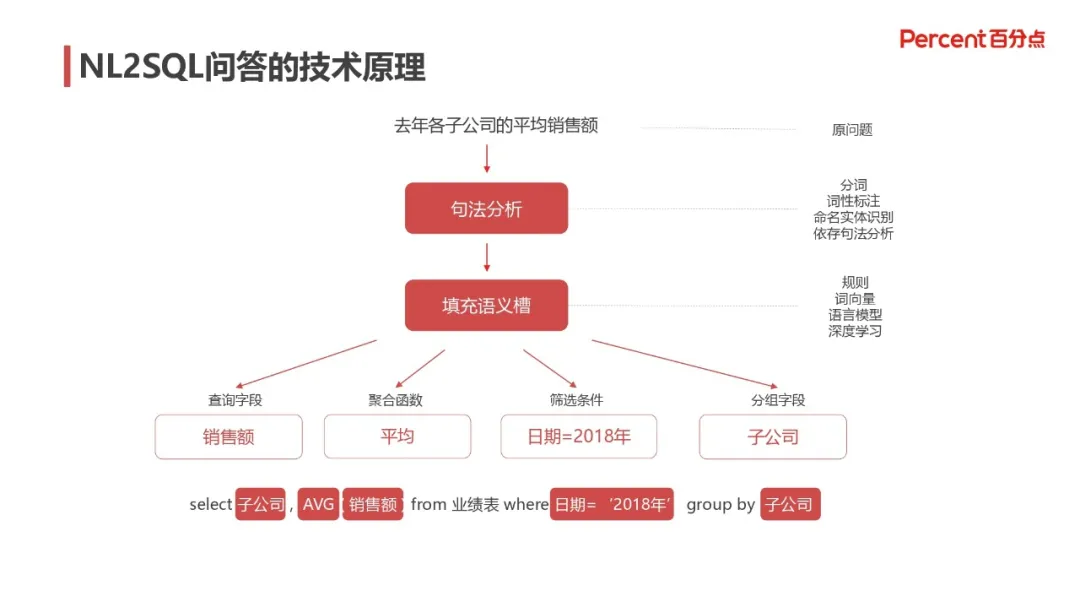
首先,针对自然语言查询语句,使用分词、词性标注、实体识别、依存句法等对句子进行句法分析,然后使用规则、词向量、语言模型、深度学习等多种方法填充语义槽,具体包括查询字段、聚合函数、筛选条件、分组字段等,然后基于这些填充的信息生成对应的 SQL 查询语句。
在经典的 NL2SQL 方案中,基于 Seq2Seq 的 X-SQL 模型是十分常见的,该模型的思路是先通过 MT-DNN 对原始问题及字段名称进行编码,再在问题前面人为地添加一个 [CXT] 用于提取全局信息。中间的 Context Reinforcing Laryer 层是这个模型的核心部分,它的目的是把 MT-DNN 得到的预训练编码在 NL2SQL 任务上进行增强和重组。这个中间层不仅能体现上下文信息,还能通过 Attention 机制对字段名称的编码进行强化。这一层输出的结果包括问题的编码,以及强化后的字段编码,后面的输出层都会在这个基础上进行。输出层包括 6 个子模型:S-COL 和 S-AGG 用于预测 select 的字段,只依赖于强化后的字段名称编码,通过 softmax 对每个字段打分就行了;W-NUM 只依赖全局信息,用于预测 where 条件个数;W-COL、W-OP 和 W-VAL 用于预测过滤条件的具体内容,通过组合字段编码,当前的 where 条件编号及问题编码,通过 softmax 评分就能得到需要的结果。
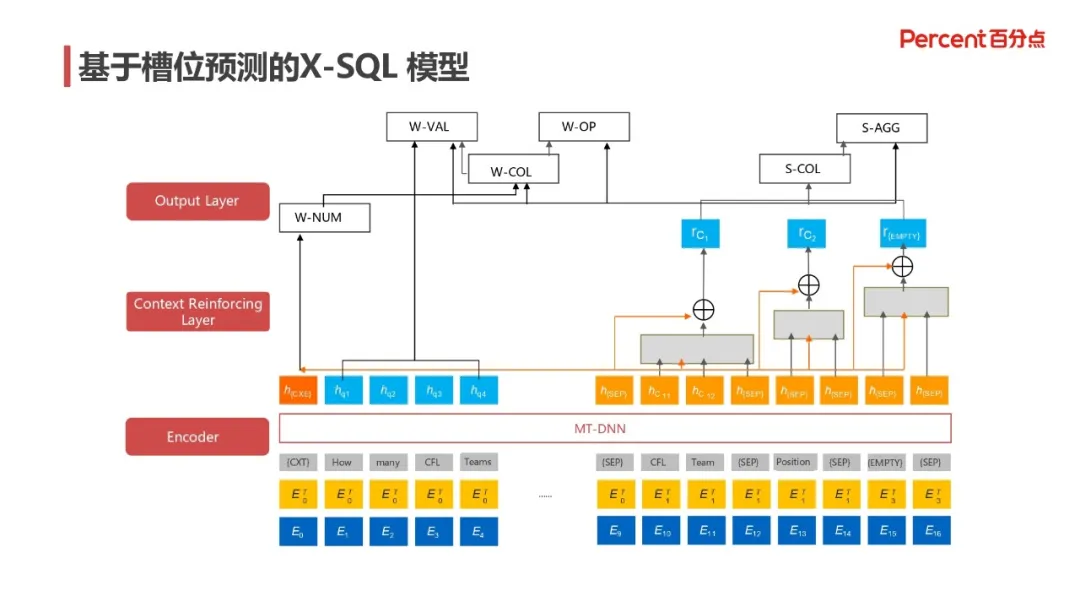
这个架构已经十分完善了,但是由于数据的局限,模型无法预测多个 select 及 group 的内容。而且模型完全依赖字段名称去提取过滤条件和 select 的内容,在中文字段名称特征不够明显或者领域数据与训练数据偏差较大时,容易出错。我们提出了一种结合依存语法树的新方案在实际项目中得到了应用,下图显示此新方法的具体思路:

2. 基于 X-SQL 和依存句法树的 NL2SQL
首先,对问句进行分词,再做依存句法分析,得到问句每一个成分在词性、实体、是否为数据表字段、聚合函数等信息,再经过词库和后序遍历解析依存树,将各个问句成分组合,最终得到解析结果。在基于 X-SQL+句法分析+时间模板的模型设计下,达到 90%以上的解析准确率,达到实用的效果。
总结
以上就是百分点关于智能问答技术的全部分享,总结起来有以下三点:
(1)基于预训练模型的深度迁移学习技术在智能问答中将得到普遍应用。
(2)NL2SQL 问答技术目前还存在很多的技术挑战和提升空间,是目前前沿热门的技术研究方向。
(3)垂直行业性的智能问答场景,技术更容易落地,用户能获得更好的问答体验。
本文转载自:百分点(ID:baifendian_com)




