
本文最初发表于STX Next博客网站,经原作者 Sebastian Buczyński 同意由 InfoQ 中文站翻译分享。
现在,每个人都在关注 API。API 最早开始流行于大约 20 年前,2000 年,Roy Fielding 在他的博士论文中首次提出了 REST 这个术语。同年,Amazon、Salesforce 和 eBay 向全世界的开发者介绍了他们的 API,永远改变了我们构建软件的方式。
在 REST 之前,Roy Fielding 论文中的原则被称为“HTTP 对象模型”,随后你会明白这为何非常重要。
随着阅读的深入,你还会看到如何确定你的 API 是否成熟,好 API 的主要品质是什么以及为何在构建 API 的时候,要注重适应性。
RESTful 架构基础
REST 代表表述性状态转移(Representational State Transfer),由 Roy Fielding 在他的博士论文中定义,长期以来,它就是服务 API 的圣杯。它并不是构建 API 的唯一方式,但是由于它的流行,即便是非开发人员也知道这种标准。
RESTful 软件有如下六种特点:
客户端-服务器端架构
无状态
可缓存
分层系统
按需编码(可选)
统一接口
但是,对日常使用来说,这过于理论化了。我们需要更具操作性的东西,这也就是 API 成熟度模型。
Richardson 成熟度模型
该模型是由 Leonard Richardson 提出的,它将 RESTful 开发原则结合成四个简单易行的步骤。

在模型中的位置越高,就越接近 Roy Fielding 所定义的 RESTful 原始理念。
Level 0:POX(Plain Old XML)的泥沼
Level 0 的 API 是一组简单 XML 或 JSON 的描述。在前文中,我曾经说过在 Fielding 的论文之前,RESTful 原则被称为“HTTP 对象模型”。
这是因为 HTTP 是 RESTful 开发中最重要的组成部分。REST 要尽可能多地使用 HTTP 固有属性中的理念。
在 Level 0,没有使用任何这样的东西。我们只是构建自己的协议并把它作为一个专有层。这种架构被称为远程过程调用(Remote Procedure Call,RPC),适用于远程过程/命令。
通常我们会有一个端点,可以对它进行调用以获取一堆 XML。在这方面,一个典型的例子就是 SOAP 协议:

另外一个很好的例子就是 Slack API。它有些多样化,有多个端点,但依然是 RPC 风格的 API。它暴露了 Slack 的各种功能,中间没有附加任何特性。如下的代码展示了如何向一个特定的通道发送消息:

虽然按照 Richardson 的模型,这是一个 Level 0 的 API,但是这并不意味着它是不好的。只要它是可用的,并且恰当地服务于业务需求,那它就是很棒的 API。
Level 1:资源
为了构建 Level 1 的 API,我们需要找出系统中的名词并将它们通过不同的 URL 暴露出来,如下面的样例所示:

其中,“/api/books”能让我访问一个通用的图书目录,“/api/profile”能够让我访问这些书的作者的基本信息。为了获取某个资源的第一个特定实例,我可以在 URL 中添加 ID(或其他引用)。
在 URL 中还可以嵌套资源,这展示了它们是以层级结构的形式组织的。
回到 Slack 的样例,如下展示了按照 Level 1 API,它们会是什么样子的:

现在,URL 发生了变化,从原先的“/api/chat.postMessage”变成了现在的“/api/channels/general/messages”。
信息中“channel”部分从请求体转移到了 URL 中。从字面就能看出,通过使用这个 URL,我们可以预期有条消息发布到了“general”通道上。
Level 2:HTTP 动作
Level 2 利用 HTTP 动作(verb)来添加更多的含义和意图。在这方面可用的动作比较多,我这里只用到一个基础的子集:PUT / DELETE / GET / POST。
借助这些动作,我们可以预期包含它们的 URL 有不同的行为:
POST:创建新数据
PUT:更新现有的数据
DELETE:移除数据
GET:查找特定 id 的数据输出,获取某个资源(或整个集合)
以上面提到的“/api/books”为例:

那这里的“安全”和“幂等”又是什么意思呢?
“安全”的方法指的是永远不会改变数据的方法。REST 建议 GET 方法只能用来获取数据,所以在上面的集合中,它是唯一一个安全的方法。不管你调用多少次基于 REST 的 GET 方法,它永远不会改变数据库中的任何东西。但是,这并不是该动作的固有特性,而是关系到你该如何实现它,所以我们需要确保它是这样运行的。所有其他的方法都会以不同的方式改变数据,不能随意使用。在 REST 中,GET 方法既是安全的,又是幂等的。
“幂等”的方法指的是多次使用不会产生不同结果的方法。按照 REST,DELETE 方法应该是幂等的,如果删除了某个资源,然后针对相同的资源再次调用 DELETE,它不会改变任何东西。资源应该早就已经消失了。在 REST 规范中,POST 是唯一一个非幂等的方法,所以我们可以对相同的资源多次调用 POST 方法,这样我们会得到重复的资源。
我们重新看一下 Slack 样例,如果我们使用 HTTP 动作来进行更多的操作会是什么样子:

我们可以使用 POST 方法发送消息到通用的通道,我们也可以使用 GET 方法从通用通道获取消息。我们还可以使用 DELETE 方法和特定的 ID 删除消息,这里比较有意思的一点在于,消息并不是与特定通道关联的,所以我可以设计一个单独的 API 来删除资源。这个例子表明,设计 API 并不总是那么简单,这方面有很多可选项和权衡。
Level 3:HATEOAS
还记得纯文字、没有任何图像的电脑游戏吗?我们只能看到一些文本,描述了你在哪里,以及接下来能干什么。为了取得进展,我们必须要输入自己的选择。在一定程度上来讲,HATEOAS 就是做这件事情的。
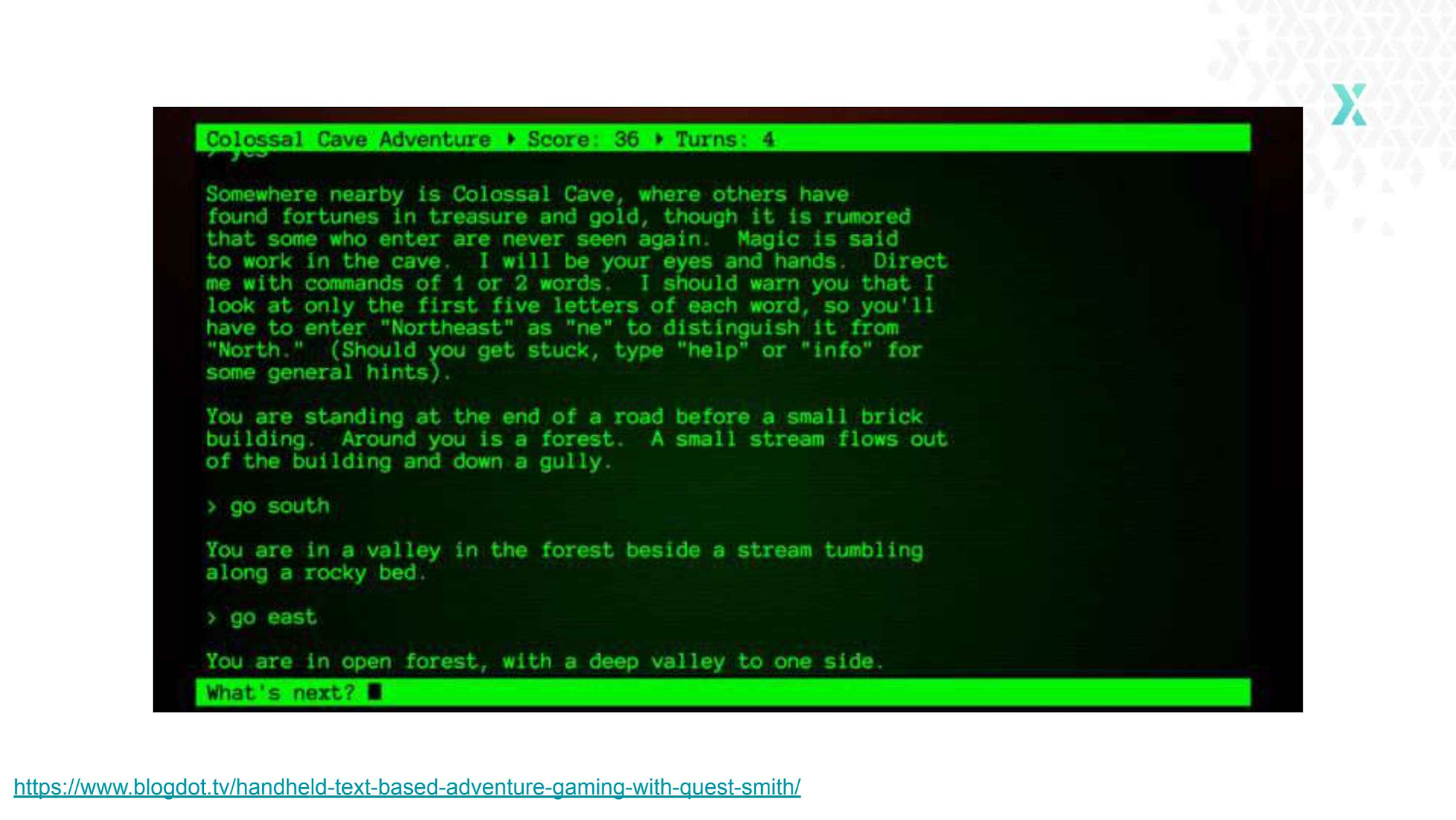
HATEOAS 指的是“超媒体作为应用状态引擎(Hypermedia as the Engine of Application State)”。
有了 HATEOAS 之后,当其他人使用你的 API 的时候,他们就能看到通过 API 还能做哪些其他的事情。HATEOAS 回答了“从这里出发,我还能去哪里?”的问题。

但这还不是所有的内容。HATEOAS 还可以对数据关系进行建模。我们可能会有一个关于图书的资源,并且在 URL 中没有将作者信息嵌套进来,但是我们可以包含它们的链接,如果有人对作者感兴趣的话,那么他们可以访问这些链接并探索相关的数据。
HATEOAS 不像其他成熟度模型的等级那样流行,但是有些开发人员确实在使用它。其中一个样例就是 Jira,如下是它们的搜索 API 的响应:

他们将链接嵌入到了其他我们可以探索的资源中,以及该 issue 的状态过渡列表。
另外一个使用 HATEOAS 的样例是 Artsy。他们的 API 严重依赖 HATEOAS,并且还使用了 JSON Plus 调用规范,按照该规范强制要求使用一种特殊的约定来构建链接。下面是一个分页的例子,这是使用 HATEOAS 最酷的样例之一:

我们可以提供到下一页、上一页、第一页和最后一页的链接,还可以按照需要添加其他页面的链接。这样简化了 API 的消费,因为这样不需要在客户端添加 URL 的解析逻辑,也不需要追加页码的方法。我们只需要在客户端使用已经实现结构化的链接就可以了。
好的 API 由什么组成
我们已经介绍完了 Richardson 模型,但这并不是实现好的 API 的全部内容。其他重要的品质还有什么呢?
错误/异常处理
我对自己使用的 API 的基本期望之一就是,需要有一种明确的方式来判断是否有错误或异常。我想要知道请求是否得到了处理。
HTTP 有一种简单的方式来实现这一点:HTTP 状态码。
管理状态码的基本规则是:
2xx 代表一切正常
3xx 代表你想要找的公主在另外一个城堡,也就是你要找的资源在其他的地方
4xx 代表客户端做错了某些事情
5xx 代表服务器端失败

我们的 API 至少要提供 4xx 和 5xx 状态码。有时候,5xx 是自动生成的。例如,客户端发送了一些内容到服务器端,但是这非法的请求,而我们的校验是有缺陷的,从而导致这个问题继续在代码中执行了下去,最终导致出现了异常,这样就会返回一个 5xx 的状态码。
如果你想要承诺使用特定的状态码,那么你会遇到“哪种状态码最适合当前情况?”的问题。这样的问题并不总是那么容易回答,我推荐你去阅读声明这些状态码的 RFC,它们给出了比其他来源更广泛的解释,并且告诉了你何时使用这些状态码更合适等。幸运的是,网上有些资源可以帮助我们做出选择,比如Mozilla的HTTP状态码指南。
文档
优秀的 API 必须要有优秀的文档。在文档方面,最大的问题在于,随着 API 的发展需要找人同步更新文档。有个更好的方案是不脱离代码自更新文档。
例如,注释与代码的脱节。当代码发生变化的时候,注释依然保持不变,这样的话,注释就过时了。这甚至会比根本就没有任何注释更糟糕,因为在随后的一段时间内,它们会提供错误的信息。注释不会自动更新,所以开发人员需要记得在维护代码的时候同时维护它们。
自更新的文档工具可以解决这个问题。在这方面,一个流行的工具就是 Swagger,它是基于 OpenAPI 构建的工具,可以很容易地描述你的 API。
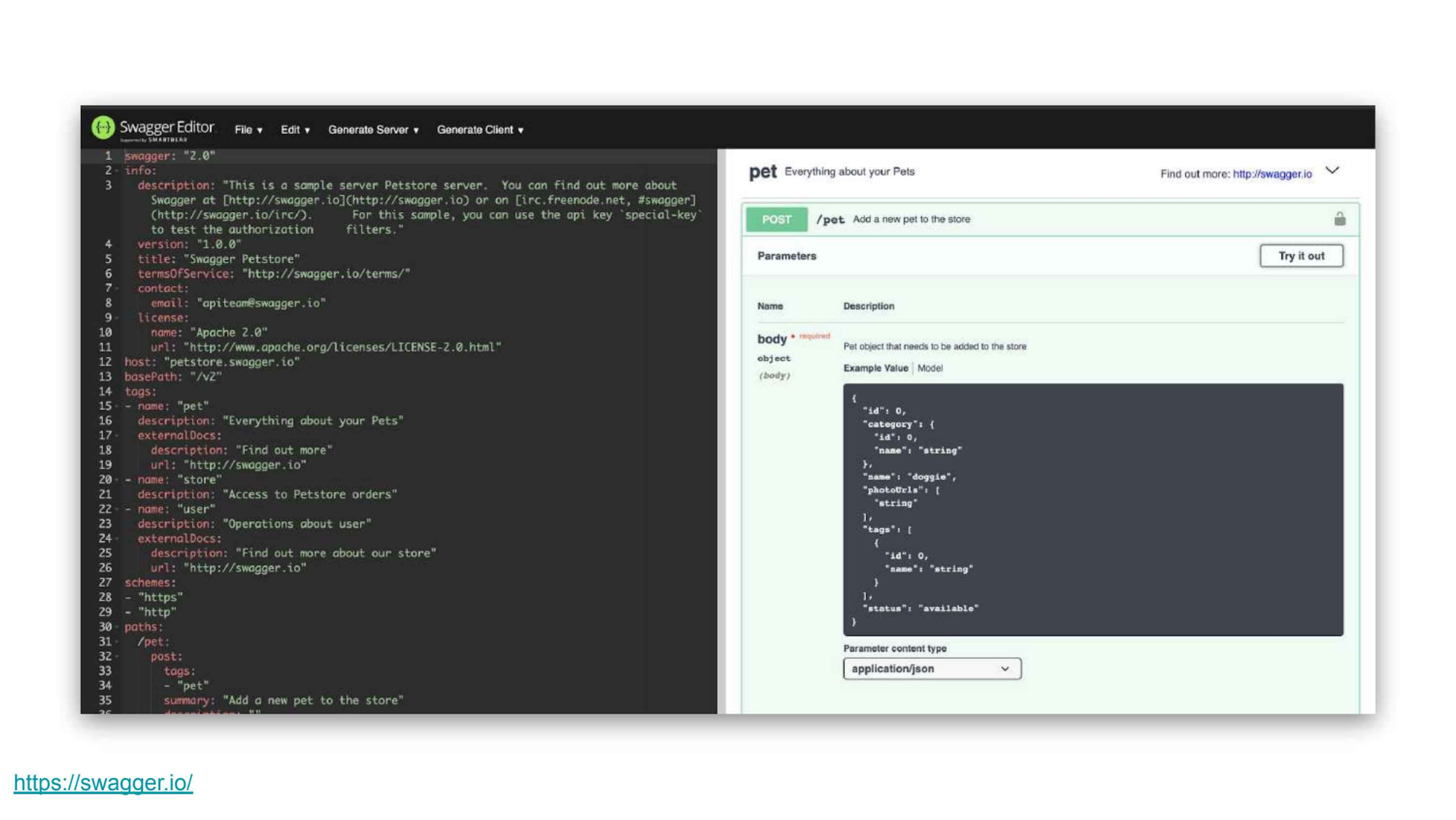
Swagger 很酷的一点在于它是可执行的,所以如果你尝试修改 API,能立即看到它的作用和变化。
为了给 Swagger 添加自动更新功能,我们需要使用其他的插件和工具。在 Python 中,有针对大多数主流框架的插件。它们能生成 API 请求该如何组织的描述,并定义数据的输入和输出。
如果你不想要使用 Swagger,而是想使用更简单的工具,那该怎么办呢?有个流行的替代方案是Slate。
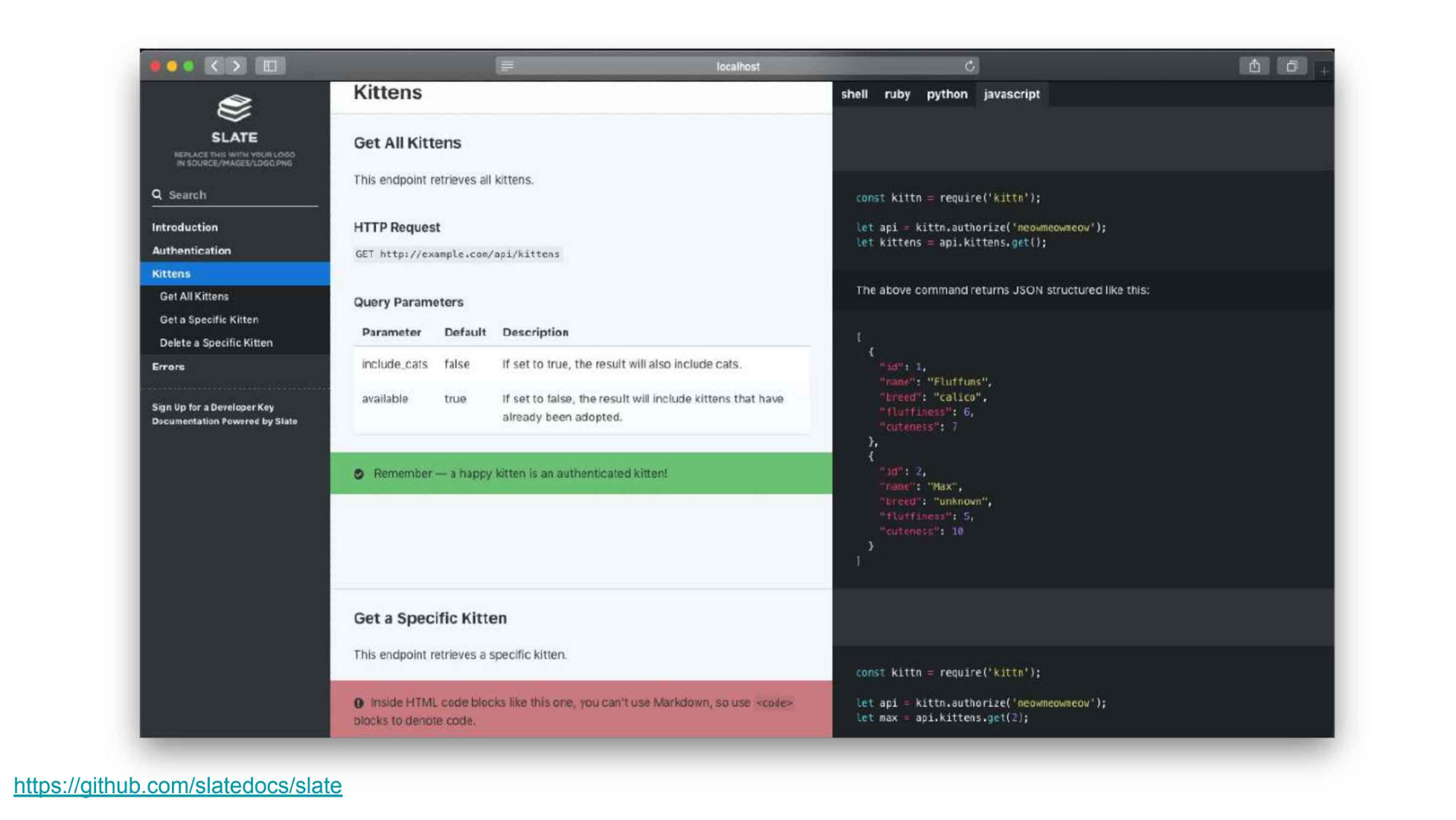
还有一些值得推荐的中间方案,如widdershins和api2html的组合,它允许我们从 Swagger 的定义中生成类似 Slate 的文档。
缓存
在有些系统中,缓存可能并不是什么大问题。这样的系统可能没有很多的数据可供缓存,所有的数据都在不断地发生变化,或者系统根本没有很大的流量。
但是,在大多数情况下,缓存对于良好的性能至关重要。它与 RESTful API 密切相关,因为 HTTP 协议在缓存方面做了很多事情,比如 HTTP 头信息允许我们控制缓存的行为。
你可能想要在客户端缓存东西,或者如果有注册表或值存储的话,那么你可能想要在应用程序中缓存数据。但是,HTTP 让我们能够基本上免费就可以获得一个很好的缓存,所以如果可能的话,请不要错过这个免费的午餐。
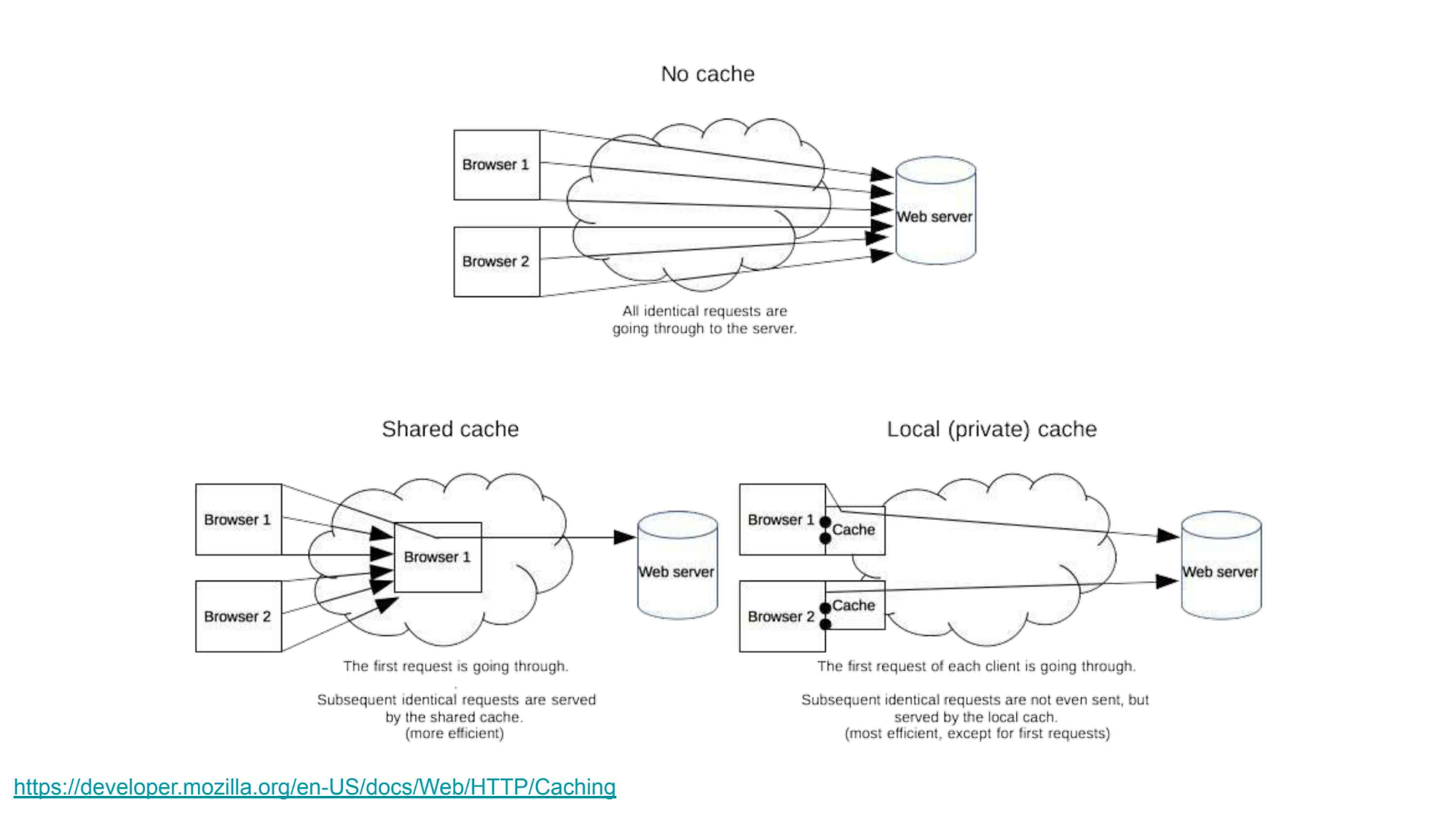
同时,因为缓存是 HTTP 规范的一部分,所以很多涉及 HTTP 的技术都知道如何进行缓存:浏览器原生支持缓存,客户端和服务器之间的中间技术也是如此。
API 设计的演化
构建 API 以及现代软件最重要的部分就是适应性。如果没有适应性,开发就会变慢,在合理的时间发布特性就会变得更加困难,当面对最后截止时间的时候更是如此。
“软件架构”在不同的上下文语境中有不同的含义,不过我们现在采用这个定义:
软件架构一种行为/艺术,能够避免会阻碍未来变化的决策。
记住了这一点,在设计软件的时候,当你必须要在具有相似优点的方案中做出选择时,你应该始终选择更多考虑到未来的方案。
好的实践并不是万能的。按照正确的方式构建错误的东西并不是你想要的结果。最好采取一种成长的心态,接受变化是不可避免的,尤其是如果你的项目要持续发展的话更是如此。
要想让你的 API 更具适应性,其中很关键的一点就是保持尽可能薄的 API 层,真正的复杂性应该往下层转移。
API 不应该限定实现
公开的 API 发布之后,它就已经完成了,是不可改变的,你就不能再去触碰它了。如果你已经有了一个设计古怪的 API,除了接受现状之外,还能做些什么呢?
你应该不断寻找简化实现的方法。有时候,你可以通过一个特定的 HTTP 头信息来控制 API 响应的格式,相对于构建另外一个叫做 v2 的新 API,这是一种更简单的解决方案。
API 只是另外一层的抽象。它们不应该决定如何实现,为了避免这种问题,我们可以采用如下几种开发模式。
API 网关
这是一种类似于门面的开发模式。如果你要把一个单体结构拆分为一组微服务,并且希望向外部暴露一些功能的话,那么你只需要构建一个类似门面的 API 网关。
它将为不同的微服务提供一个统一的接口(这些微服务可能有不同的 API,使用不同的错误格式等等)。
适用于前端的后端
如果你必须要构建一个 API 来满足一堆不同的客户端的话,那么这可能会非常困难。针对某个客户端所作出的决策可能会影响其他客户端的功能。
按照适用于前端的后端(backend for frontend)理念,如果你有不同的客户端,它们喜欢不同形式的 API,比如移动应用可能会喜欢使用 GraphQL,那么就单独为它们构建吧。
只有当你的 API 是一层抽象,并且这个抽象层很薄的时候,这种方式才有效。如果它与你的数据库耦合,或者太大,具有太多的逻辑,那么就无法这样做了。
GraphQL 与 RESTful
很多人都在热炒 GraphQL。它是一项新兴的技术,但是已经有了很多粉丝,以至于有些开发者声称它将取代 REST。
尽管 GraphQL 比 RESTful 要新的多,但是它们有很多相似之处。GraphQL 最大的不足之处在于它的缓存,它必须要在客户端或应用程序中实现。现在,有内置的实现了缓存功能的客户端库(比如Apollo),但是这仍然要比使用 HTTP 提供的几乎免费的缓存功能要困难。
从技术讲,GraphQL 位于 Richardson 模型的 Level 0 层级,但是它具有良好 API 的特质。我们可能无法同时使用多个 HTTP 的功能,但是 GraphQL 的出现就是解决这一问题的。
GraphQL 的杀手锏就是聚合不同的 API,并将它们作为一个 GraphQL API 暴露出来。
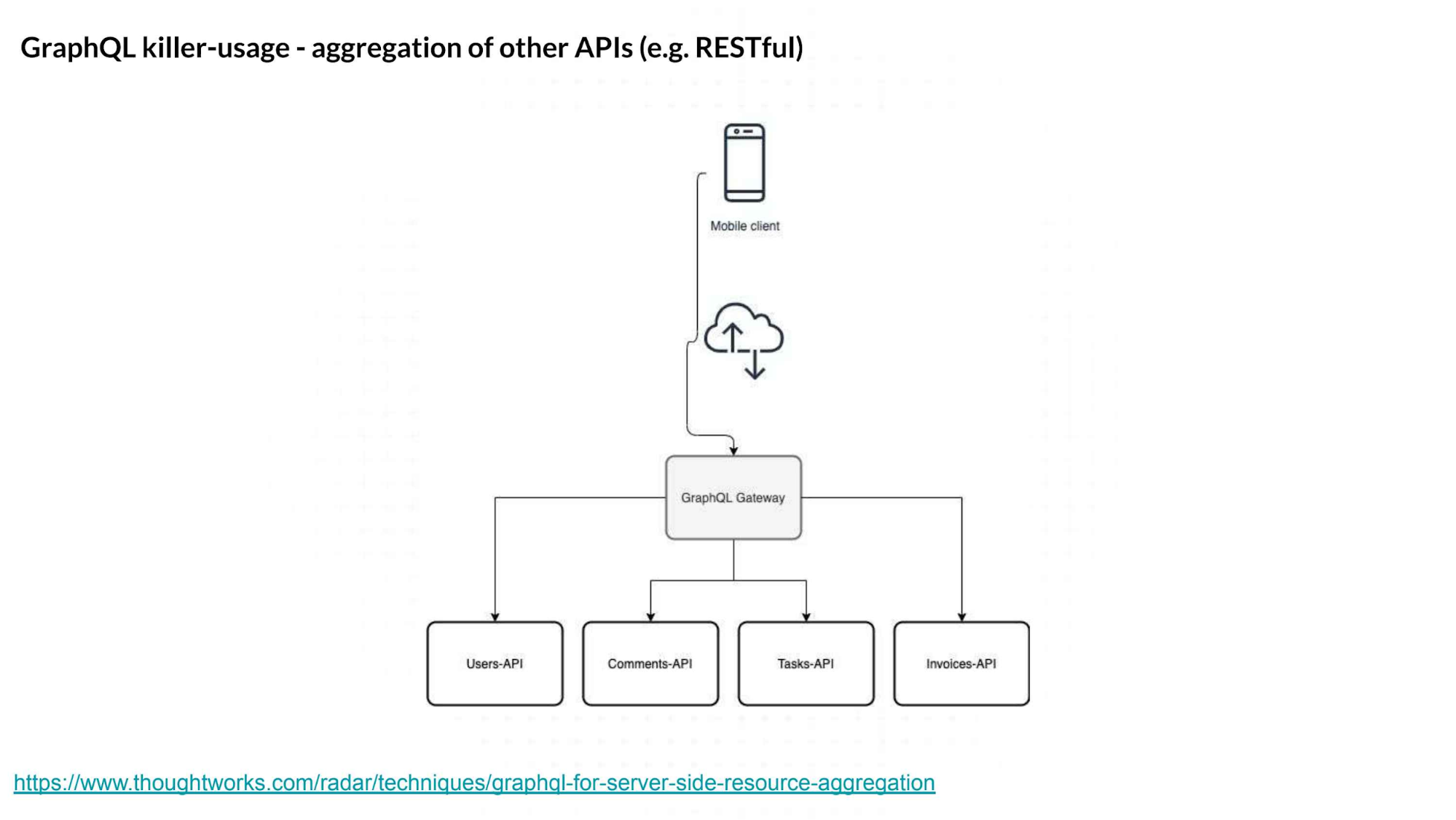
GraphQL 在处理数据抓取不足和数据过量抓取方面有很好的效果,而这些问题是 REST API 很难进行管理的。这两个问题都与性能有关,如果数据抓取不足,那说明你没有高效地使用 API,所以必须要进行大量的调用。如果数据过量抓取的话,那么 API 调用的数据传输会比必要的数据传输更大,这是对带宽的一种浪费。
小结
借助 REST 与 GraphQL 的比较,我们能够总结出一个好的 API 最重要的品质。
好的 API 的特性
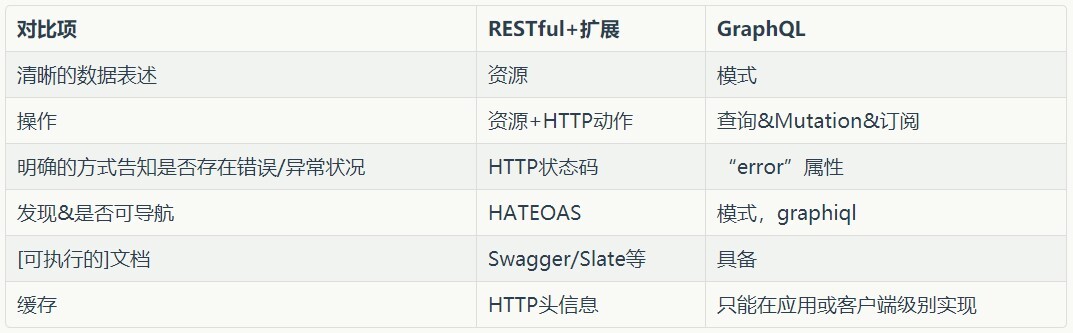
我们需要一个清晰的数据表述方式:RESTful 以资源的方式提供了表述。我们需要有一种方式显示有哪些可用的操作:RESTful 通过组合资源和 HTTP 动作实现这一点。我们需要有一种方式来确认是否存在错误/异常:HTTP 状态码可以实现这一点,可能还会包含阐述它们的响应信息。最好能够提供 API 发现和导航的功能:在 RESTful 中,HATEOAS 负责实现这一点。有好的文档是非常重要的:在这方面,可执行、自更新的文档可以解决这个问题,这超出了 RESTful 规范的范围。最后,但同样重要的是,优秀的 API 应该具有缓存功能,除非你的特定情况认为它是不必要的。
REST 和 GraphQL 之间最大的区别是它们处理缓存性的方式。当我们使用 REST 方式构建 API 的时候,我们基本上可以免费获得 HTTP 的缓存功能。如果选择 GraphQL 的话,你需要自行负责为客户端或应用程序添加缓存。
原文链接:
https://www.stxnext.com/blog/how-to-build-a-good-api-that-wont-embarrass-you




