
开发人员为什么要阅读代码
他们之所以要阅读代码,是因为代码是真相所在。他们也会在其他多种情况下阅读代码。当他们想要学习如何使用 API 时,他们会阅读。当他们需要找到一个地方添加新功能时,他们会阅读。当他们在查找导致 bug 的根本原因时,他们会阅读。当他们在查找构建配置不能正常工作的原因时,他们会阅读。当他们在查找测试失败的原因时,他们会阅读。
在开发过程中,人们普遍都依赖阅读代码。事实上,开发人员在这方面花费了大量的时间。多项研究表明,通常超过一半的开发时间都花在阅读代码上。
阅读代码在日常开发工作中根深蒂固,以至于人们认为它是理所当然的。毕竟,他们为什么不能这么做呢?关于编程的一个普遍观点是,代码就像一本书,我们会像读写普通书籍一样读写代码。然而,代码并不完全像是一本书。一个关键的区别是代码通常比一般的书的内容要多得多。假设一个系统有 25 万行代码,这相当于 64 本《哈姆雷特》,而快速阅读,比如每天 8 小时,2 秒一行,大约需要一个月的时间,而这还不是全部。《哈姆雷特》的角色有限,情节也可以被简明扼要地概括出来,但一个软件系统却几乎没有可以摆脱掉的代码。只是阅读一次代码很少能够完全了解系统。由于软件系统的本质是相互交织的,要理解它,就必须考虑到所有的内部联系,并将其作为一个整体来理解。另外,一个软件系统的变化速度一直比我们通过阅读来了解它的速度要快得多。因此,不管是从质量还是数量上讲,我们面临的问题都不同于读书。
如果我们后退一步就会发现,虽然情况各不相同,但动机是一样的:开发人员通常想要足够了解系统的一些东西,以边确定下一步要做什么。他们阅读代码是因为他们想要做出决定。这和读《哈姆雷特》是完全不同的,和阅读天文学课本也不一样。
从这个角度来看,阅读代码只是一种从系统中获取信息的策略。只要存在一种方法,就会有另一种方法。实际上,关于系统的一切——无论是代码、配置、日志还是数据库中的数据——都只是数据,而数据最好是使用工具来处理。
当然,在过去的几十年里,各种各样的分析工具并不少见。然而,即使在今天,阅读代码仍然是从系统中获取信息的主要手段。你可能会问:“那又怎样?”
毕竟,正是这种活动让我们的行业变得如此有价值:大多数系统帮助人们对他们永远不会看到的数据做出决定,而开发人员有能力创造这种魔力。我们只需要把我们的能力应用在我们自己的问题上!
“好吧,但该如何做?”
软件系统还有一个我们需要考虑的特性:它们是高度上下文相关的。两个系统可能是针对同一个领域,使用完全相同的技术构建,但仍然完全不同。几年前,我们做了一个实验,试图重现这样的场景。伯尔尼大学的若干学生团队被要求构建相同的小应用程序,并且必须使用相同的库。他们需要满足的需求是一样的,并以相同的方式进行验收测试。在经过了 7 周的开发之后,我们对他们的系统内部进行了研究。
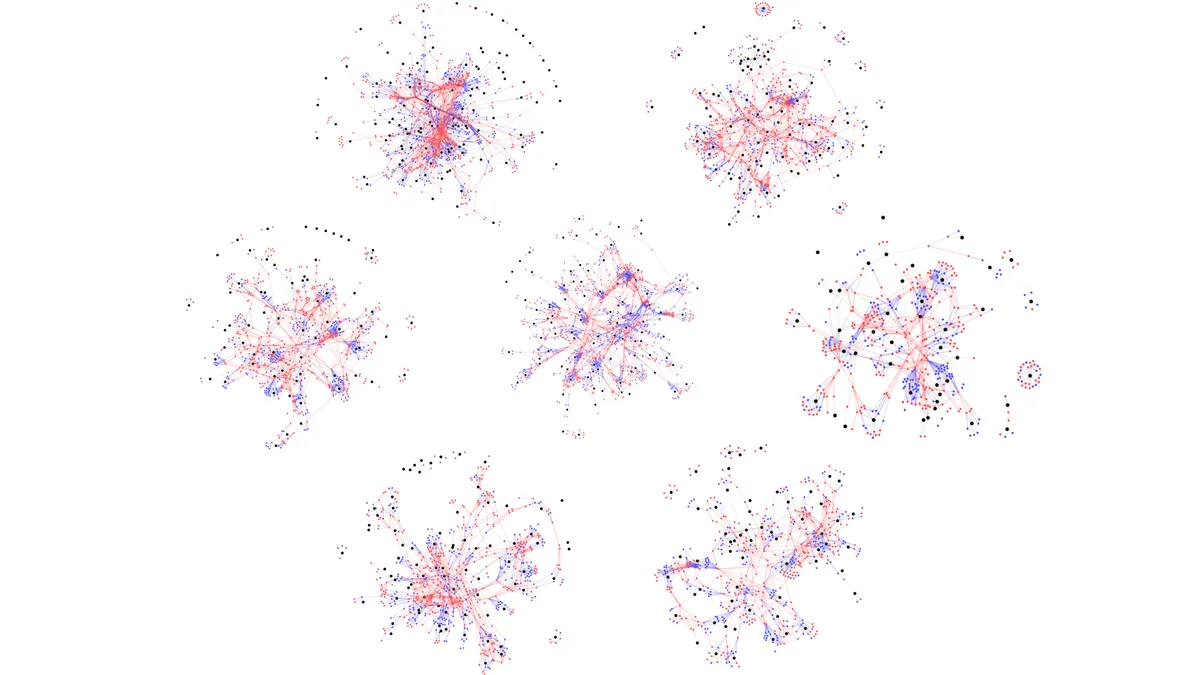
这张图中有 7 个系统,对于每个系统,我们用黑色表示类,用红色表示方法,用蓝色表示属性以及它们之间的相互依赖关系。从图中可以看出,尽管这些团队受到了高度约束,但仍然产出了不同的结构。系统的内部工作方式受到许多因素的影响,而这些因素远远超出了技术的范畴。
正是由于这种上下文性质,一般性工具在实践当中从未真正起到作用。它们可以生成漂亮的图片,但不会影响人们做出决定的方式。为了让决策具有相关性,需要考虑到上下文信息,而通用工具根本无法感知到这些。例如,上面的可视化是通用的,因为它适用于任何系统。描述软件的一般性质是有用的,但对于处理与系统相关的特定问题是没有用的。
另一种选择是创建自定义工具,以上下文为基础,并提供与之匹配的体验。工具的主要焦点应该是用一种易于理解的方式来显化问题,这样解决方案通常很快就会出现,我们称之为可塑性开发(Moldable Development)。
让我们来看一个具体的例子。
示例——特性切换推理
依赖关系在开发人员的意识中占据着重要的位置。他们添加依赖,删除依赖,管理依赖,并不断地打破依赖循环。这是一个普遍的问题。不过,并非所有的依赖都是平等的,有些比其他的更有趣,有些比其他的更明显。
当我在 2021 年 QCon Plus 大会上通过实例介绍可塑性开发时,我展示了一个由系统设置和特性切换导致的依赖关系的例子。从中可以看到,当特性切换在一个组件中定义并在另一个组件中使用时,两者之间会出现依赖关系。
最近,我和同事有机会一起了解了 Open edX 的特性切换。Open edX 是一个用 Python 编写的开源系统。下面的可视化图用红色突出显示了树图(TreeMap)上所有使用了特性切换的地方,树图是一种通过嵌套矩形显示层次数据的可视化图。在本例中,树图显示了系统的文件夹和文件。使用了至少一个特性切换的文件用红色突出显示。可以看出,这是一个非常依赖特性切换的系统。
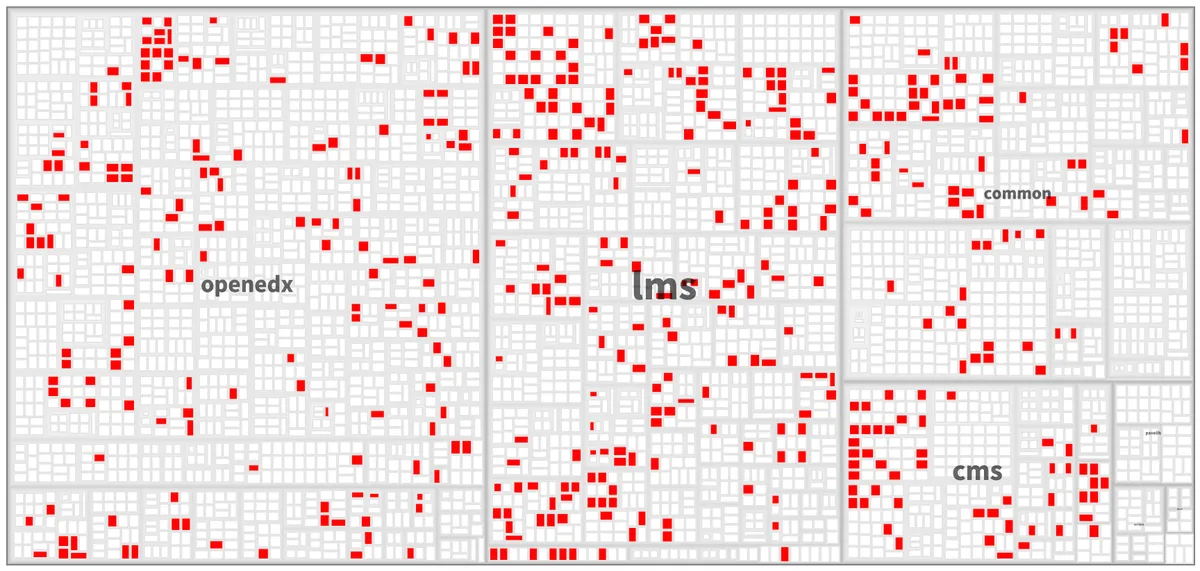
特性切换最基本的形式是使用布尔值。当然,在一个系统中会有许多布尔值,但其中只有少数用于特性切换。通常,定义和使用特性切换要么是依赖模式,要么是依赖库。我们当时发现有三种基于不同库的表示特性切换的方法。因此,为了绘制上面的可视化图,我们首先必须创建一个能够理解这些上下文库的专用工具。
我们使用了Glamorous Toolkit,一个可塑性的开发环境。Glamorous Toolkit 主要帮助开发人员用较低的成本创建定制工具。下面是一个使用这个工具包进行代码分析的示例。在左侧窗格中,我们可以看到一个实时的 notebook 页面,其中包含了一个查询,用于查找遗留的切换机制。在中间的窗格中,我们可以看到一个特性切换列表。在右边,我们可以看到一段显示特性切换的 Python 源代码。
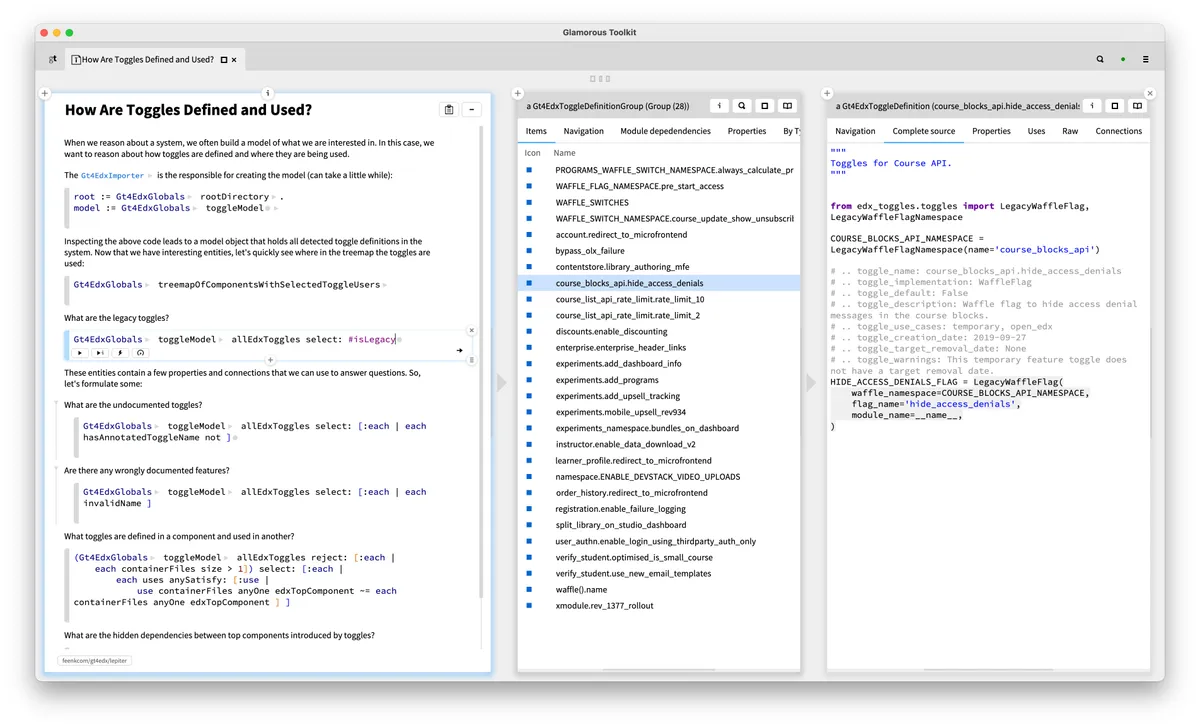
在我们的例子中,有一个特性切换是这样定义的:
HIDE_ACCESS_DENIALS_FLAG = LegacyWaffleFlag( waffle_namespace=COURSE_BLOCKS_API_NAMESPACE, flag_name='hide_access_denials', module_name=__name__,)
从名字可以看出来,这是用于在系统中定义变量的一种遗留机制,目的是为了方便进行迁移。当然,在迁移之前,首先需要找到违规的地方。为了找到它们,我们需要一个可以理解这个框架的工具。notebook 中的查询可以捕获到这些信息:
Gt4EdxGlobals toggleModel allEdxToggles select: #isLegacy
这个查询依赖了已有的切换模型,并基于之前设定的模型逻辑标志来选择它们。我们专门为 Open edX 系统创建了这个模型和逻辑。
这个场景捕获到了更多的东西。首先,notebook 对软件工程就像它对数据科学一样有用。其次,分析由依赖了基于系统自定义模型的自定义视图的检查器提供支持。例如,在右侧,我们可以看到一个叫作 Gt4EdxToggleDefinition 的类实例检查器。这是专门为分析而创建的模型中的一个实体。
在有了一个可以捕捉系统事实的模型之后,我们就可以去发现不容易被发现的问题。在本节的开头,我们讨论了由特性切换导致的依赖关系,下图是它们在我们系统里的样子。在图的左边,我们可以看到顶层模块的可视化,以及由特性切换导致的依赖关系。单击其中一个箭头就会显示导致这种依赖关系的特性切换。在最右边,我们可以看到使用特性切换的细节。
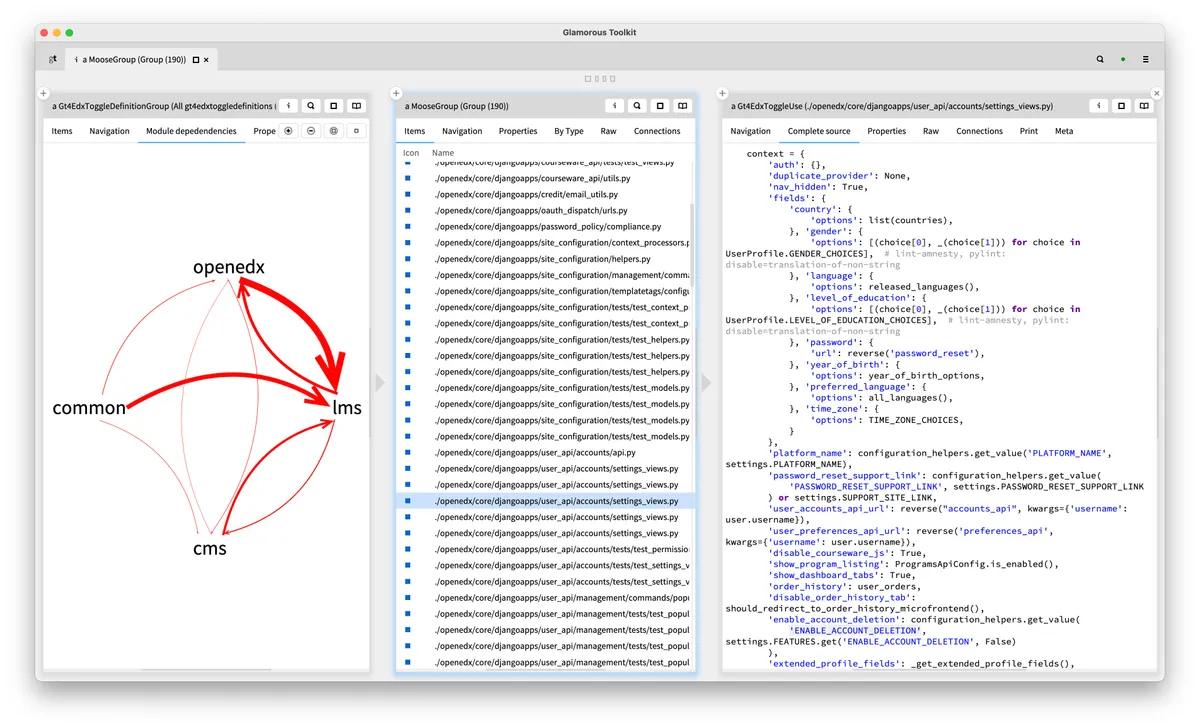
例子中展示了获取一个特性切换并将其保存在一个上下文变量中:
context = { ... 'enable_account_deletion': configuration_helpers.get_value( 'ENABLE_ACCOUNT_DELETION', ...) ... }
系统的 openedx 组件使用了特性切换,但它是在 lms 组件中定义的,因此两者之间存在一个隐藏的依赖关系。这只是其中的一个例子。
本节展示了几个在开发过程中可能出现的典型的问题。例如,如果我们想要拆分系统,就需要知道隐藏的依赖关系是怎样的。我们希望总是能够回答任何有关系统的问题。在我们的示例中,我们通过静态分析来回答这些问题,但可塑性开发思想适用于软件系统的任何方面,不管是静态的还是其他的——我们从一个问题开始,创建一个定制的工具,并解释结果,从中找到行动的路径。最后,我们发现我们可以在不阅读代码的情况下对系统进行推理。
事实上,通过定制工具来指导决策的想法与当前的实践状态相差甚远。乍一看,这一提议似乎是一种浪费。毕竟,这是否意味着开发人员将花费大量的时间来创建和完善工具,从而导致生产力下降?简单地说,不会。事实上,情况恰恰相反,我们过一会儿再来讨论这个。
Glamorous Toolkit——可塑性开发环境
在上面的例子中,我们使用 Glamorous Toolkit 对一个用 Python 编写的系统进行了分析。Glamorous Toolkit 是一个可塑性开发环境,用于降低创建定制工具的成本。例如,创建一个自定义视图通常只需要几分钟的时间。Glamorous Toolkit 提供了统一编程、数据科学和知识管理的体验。它是一个基于 Pharo 的 Smalltalk 系统,更关键的在于,我们可以通过多种方式对其进行编程和定制。
Glamorous Toolkit 本身也是一个示例,我们也是遵循可塑性开发的思想创建了它。它的基础发行版中已经包含了数千个小工具。我们是怎么知道的?这是一个好问题,就像任何关于系统的问题一样,我们可以通过定制工具来回答它。在本例中,我们将可以使用 Glamorous Toolkit 编写一个关于 Glamorous Toolkit 的简单查询。
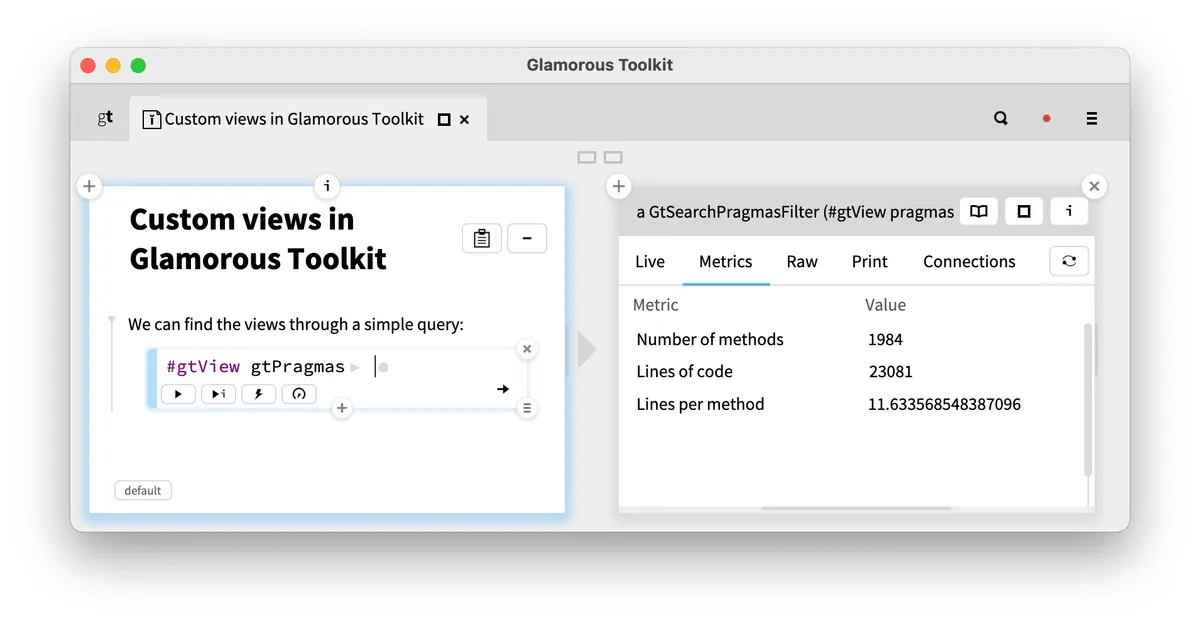
在截图中,我们可以看到左边的 notebook 中有一段代码:
#gtView gtPragmas
执行这个脚本会在右侧的检查器中显示结果。在这个例子中,结果是一个叫作过滤器的东西,它知道如何显示代码中的实际位置,还知道指标概要。我们可以看到有 1984 个方法。这些方法定义了检查器所显示的自定义视图。例如,指标视图的定义是这样的:
gtMetricsFor: aView <gtView> ^ aView columnedList title: 'Metrics'; items: [ {'Number of methods' -> self amountOfMethods. 'Lines of code' -> self linesOfCode. 'Lines per method' -> self linesOfCodePerMethod} ]; column: 'Metric' text: #key; column: 'Value' text: [ :assoc | assoc value asString ]
为什么我们会有这个视图?因为我们曾经想知道我们有多少个自定义视图。可塑性开发流程通常从一个问题或假设开始,然后我们会问什么样的工具能够提供答案的概要,如果我们没有合适的工具,就创建一个。我们对所有关于系统的问题都这么做。而且,这些工具通常只使用一次。
“这是什么蠢事?创建一个工具,只使用一次?”是的。这只是一个成本问题,如果成本足够低,它实际上比手动阅读代码更划算。这并不像看起来的那么牵强。这个流程与数据科学中的流程类似,在数据科学中,人们会为每个问题创建自定义描述。
“那么,怎样的东西才算是工具?”对象的自定义视图是一种工具,自定义调试器是一种工具,自定义搜索是一种工具,自定义 API 浏览器是一种工具,自定义日志分析器也是一种工具。所有这些都是工具,而工具包环境的职责是确保用较低的成本来塑造它们。有了这些,编程流程就会发生根本性的变化。
“不过,重复利用工具不是更加经济吗?”如果你可以重用你的定制工具,那就这样去做。例如,Glamorous Toolkit 默认发行版提供的 1984 个定制视图是可重用的。但不要在一开始就考虑重用,而是考虑摊销成本,这样可以让你在创建工具之前不必从经济性角度去考虑问题。
“工具一定要是定制的吗?”看看我们的例子,如果我们不理解用来定义系统设置和特性切换的框架的细节,就无法回答与它们相关的问题。事实上,在这个系统中有不止一个这样的框架。软件开发中的大多数决策都与外部无法预测的特定情况有关。如果你的问题不够具体,可能就是没有用的。如果你发现自己正在使用的工具与在其他系统中使用的一样,那么这个工具很可能无法起到应有的作用。
我们来看一个常见的查看构建日志的场景。我们可以看到三个窗格。在第一个窗格中,我们可以看到构建状态嵌入在知识管理系统的页面中。在第二个窗格中,我们可以看到各个阶段的图表。所选的构建失败了,图表显示问题出在最后一个阶段。选择最后一个阶段将显示构建执行的详细步骤,其中一个步骤失败了。当我们查看步骤内部时,立即发现了红色高亮显示的错误。
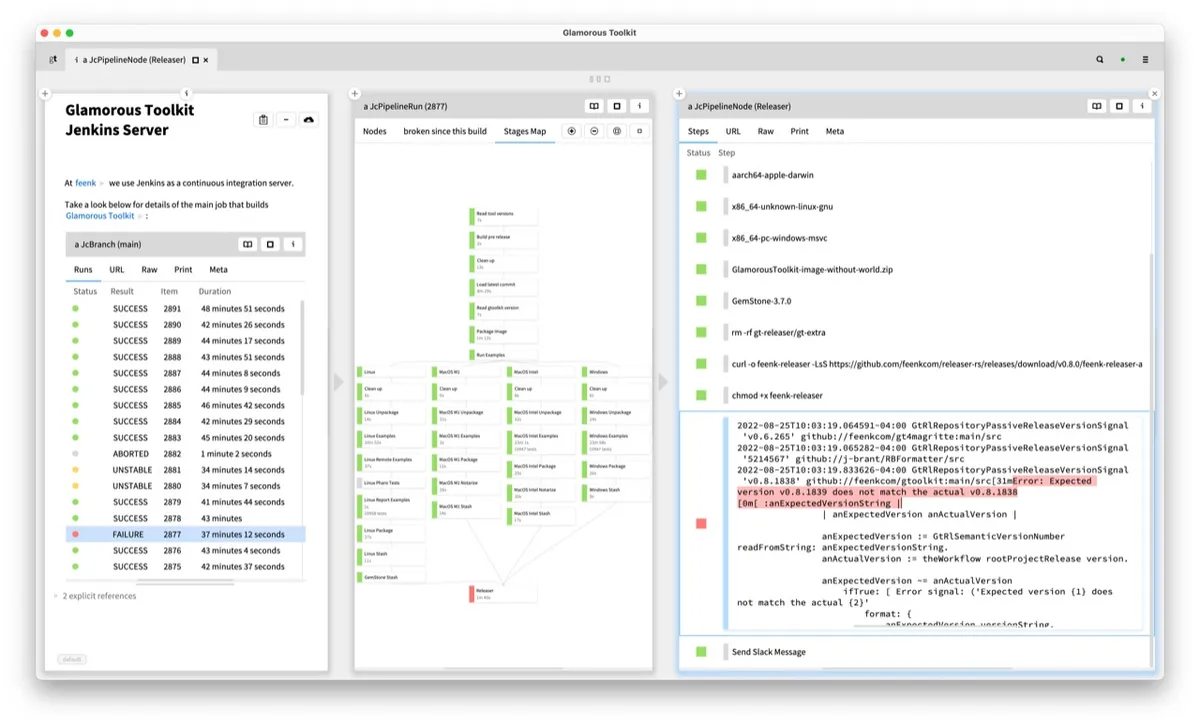
在这个例子里,错误信息是这样的:
Error: Expected version v0.8.1839 does not match the actual v0.8.1838
这个错误不是普遍性的错误,而是与我们构建系统的上下文相关。因此,要高亮显示它,视图必须了解上下文。事实上,我最近看到过这个错误,但没有被高亮显示,因为之前没有遇到过。很快,我用几行代码给它加了高亮:
('Error: Expected version' asPParser token , #endOfLine asPParser negate star token , #endOfLine asPParser) ==> [ :tokens | (aText from: tokens first start to: tokens second stop) highlight: Color red ]
环境中的任何东西都可以而且应该与上下文相结合。当然,如果环境已经能够快速创建自定义体验,那会有很大帮助。在我们的示例中,你可能会注意到,我们没有使用单独的工具来收集关于构建的信息。IDE 中的“I”是“集成”的意思。如果要集成环境,就不应该离开环境去寻找信息。相反,我们希望信息自己来到我们身边,以便让我们能够通过适合的方式操作它们。这就是可塑性开发的精髓。
为了让这个变得实际,环境必须降低工具的创建成本。这就是为什么我们不把环境看作现成的工具,而把它看作一种由交互式和可视操作符组成的语言,它们可以以多种方式组合在一起。Glamorous Toolkit 提供了许多这样的小部件,我们可以将它们拼凑起来形成上下文体验。
可塑性开发的意义
现如今,开发人员将大部分时间花在阅读代码上。然而,他们很少去谈论这件事情。正如 Felienne Hermans 之前发表的关于阅读代码的文章中所提到的那样,阅读代码实际上从未受到过任何挑战。当你学习一门新语言或问题已经被展现出来时,阅读代码是一个很好的策略,但当我们需要处理更大的问题时,它就不奏效了。
可塑性开发对将阅读代码作为一种从系统中收集信息的手段提出了挑战。可塑性开发提供了一种系统性的方法,依赖于创造可以概括系统的专门性体验。在本文中,我们详细介绍了一个场景,在这个场景中,我们在不依赖阅读代码的情况下了解系统。当然,这只是一个适合放在本文中展示的例子。因为开发人员每天要做很多决定,每一个决定都可以通过自动的、上下文相关的概要来推动。
我们谈论的是开发预算中最大的一部分,也就是我们现在正在以一种隐性且未经优化的方式在使用的部分。好消息是,这代表着一个巨大的机会——如果我们对其施加显著的影响,将直接影响整个开发过程。我们对行业决策中的繁琐部分进行自动化。我们通过创造专门的体验来概括数据,通过这种体验,人们无需看到原始数据就可以做出决策。这是一种神奇的技能,涉及到社会的方方面面,我们只需要把它应用到工作中。这个流程如下图所示。
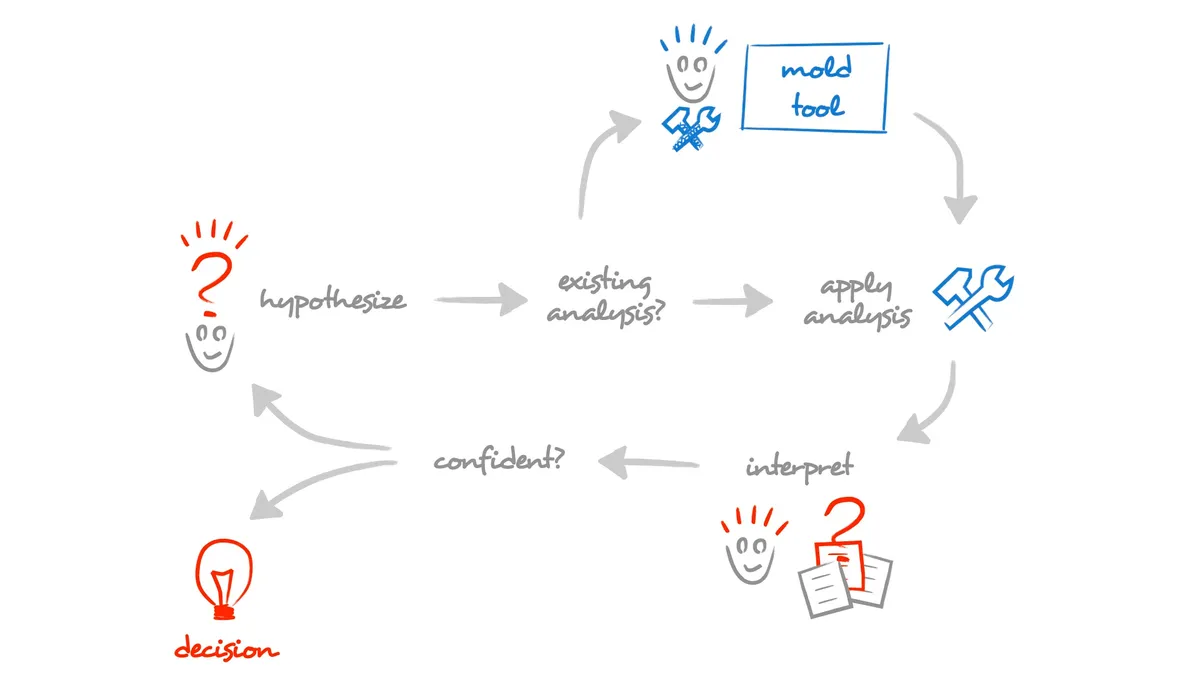
这一切都始于一个假设,或至少是一个明确的与系统相关的问题。我们希望通过工具来收集有关系统的信息。一旦有了结果,就可以对它们进行解释。如果我们对解释的结论有信心,就会采取行动。如果没有,就加以改进并进行重试。这不是什么新鲜事物,这是一种科学的方法。可塑性开发的独特之处在于,鉴于软件是高度上下文化的,我们无法确切地预测人们将遇到的问题,因此我们不能提供现成的工具。对于一个给定的假设,我们很可能还没有准备好合适的工具。在这种情况下,我们应该自己创建一个合适的工具,就是这样。
可塑性开发需要采用新技术来降低创建定制工具的成本。为了展示这种开发方法在实践中的工作原理和系统的可解释的程度,我们开发了 Glamorous Toolkit,并将其开源。不过 Glamorous Toolkit 只是一项技术,而可塑性开发是一种通用的方法,我们相信它可以成为软件工程的基础。
可塑性开发也需要专门的技能,最明显的就是创建定制工具的技能,这与创建自定义可视化图的数据科学家的工作没有太大区别。但这还不够,最重要的技能是形成假设和做出决策。虽然掌握技术方面的东西可以像学习其他技术一样,但具体问题的制定是一种只能通过时间来培养的技能。
一旦掌握了技术和技能,就打开了无限的可能性。我们通过沃德利图来理一理。
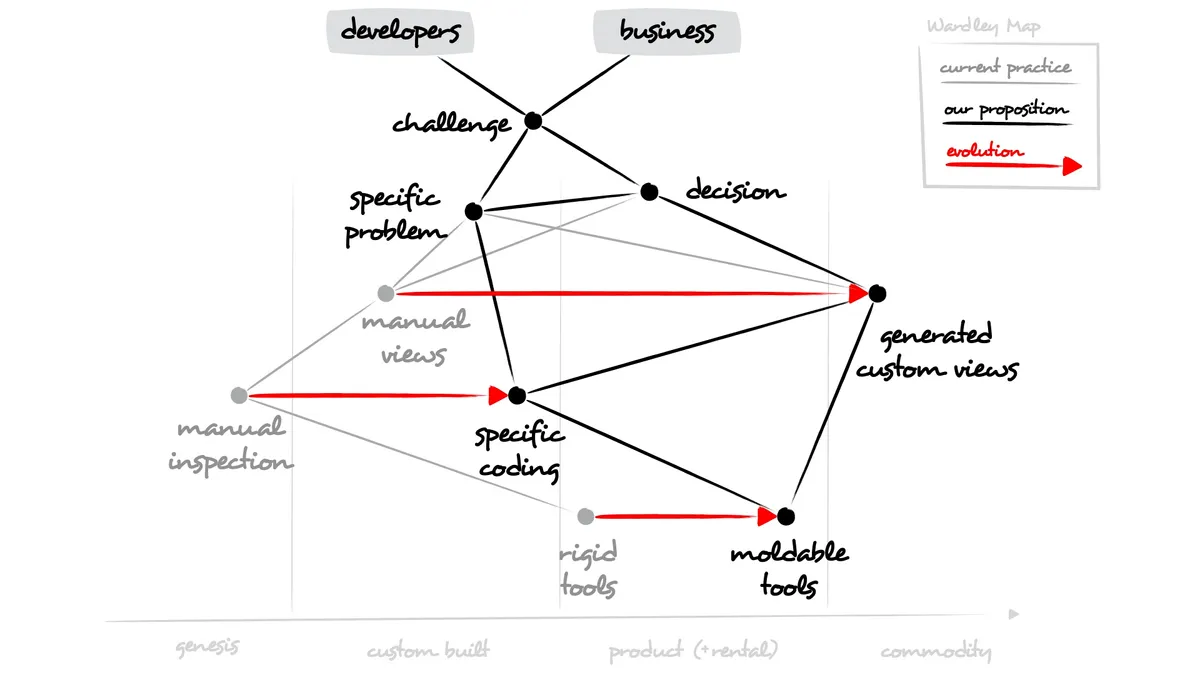
技术人员和非技术人员都面临做出系统决策的挑战,这些挑战总是与具体的问题相关。通常,这些决策是基于对系统进行手动检查得出的组合视图而做出的。考虑到系统的规模比通过手动检查能够收集到的信息要大得多,因此手动获得的视图总是不完整的,而且经常是错误的。另一种方法是自动生成视图。当然,为了使视图有价值,需要对它们进行特定的定义,而这需要进行特定的编码。只有当工具也变得具有可塑性,这一切才有可能。
与创建定制工具相关的工作不仅不会增加开发成本,反而会降低成本。因为预算已经花在人工上了,将部分能量转换为编码优化了手动工作,最终的总成本更低。
我们可以将可塑性开发视为降低成本的一种方法,光是这一点就值得了。然而,现如今,做出决策的速度和质量是最重要的。定制视图不仅降低了最大的成本,还让公司能够更快、更准确地做出决策,这是最大的潜力所在。
以我们最近合作的一家公司为例。几年来,他们一直试图优化用于关键营销活动的数据管道的性能,但都没有成功。当他们第一次介绍他们的系统时,画了一个包含四个大组件的架构图。经过更仔细的检查发现,事实上,他们的系统有五个大组件。这里我们不讨论数据沿袭的细粒度细节,我们要讨论的是对系统的粗粒度理解。实际上,他们并不知道这个系统是由什么组成的。这听起来很荒谬,对吧?构建这个系统的人怎么会不知道这个呢?而这与那些拥有遗留系统的大多数公司的情况也没有太大不同。我们一次又一次地遇到这样的团队,他们自以为了解系统,结果却发现实际情况截然不同。一般来说,如果决策是基于手动制作的图表做出的,我们就可以假设它们是不完整的,或者,更糟的是,它们是错误的。
系统随着时间的推移而演化,最初的知识会随之过时。在这种情况下,我们不能依靠记忆。相反,我们希望能够通过自动的方法来了解当前的系统。以较低的成本获得针对问题的准确观点,就有可能可以提出更多的问题,从而形成新的反馈循环。
这些问题本质上是技术问题,但具有非技术的意义。软件系统越来越多地记录和自动化组织的关键知识。访问和改变系统的能力将是未来十年竞争优势的关键来源。
作者简介:
Tudor Gîrba 是一个软件环保主义者和feenk的首席执行官,他与一个了不起的团队合作,致力于让系统的内部变得可解释。他的大部分工作都包含在Glamorous Toolkit中——一个支持可塑性开发的可编程环境。
原文链接:




