
1. 什么是深度学习?
深度学习( Deep Learning )是机器学习的分支,是一种以人工神经网络为架构,对资料进行表征学习的算法 [1] 。一般先学习简单表征(如图像边缘),然后以简单表征为基础进一步学习抽象层次更高的表征(如图像角点,进而到物体的一部分),最终获得适合于特定任务的高级表征。由于学习的表征层数一般较深,所以得名深度学习。
卷积神经网络( Convolutional Neural Network , CNN )是深度学习中常用的一种神经网络类型,因其独特的架构非常适合于各种图像处理任务,因此 CNN 在图像分类、物体识别、超分辨等很多领域取得了巨大成功。
2. 什么是环路滤波?
有损图像/视频压缩过程中引入了不可逆的量化操作,使得重建图像和原始图像之间存在失真。环路滤波技术通过对重建图像进行滤波,以减少失真,从而提升压缩效率和重建质量。视频编码标准中常见的滤波器包括去块效应滤波( Deblocking Filter , [2] ),像素自适应偏移( Sample Adaptive Offset , [3] ),和自适应环路滤波( Adaptive Loop Filter , [4] )。注意,由于失真后的图像对应的原图可能有无穷多种,因此这里的图像质量增强属于病态问题,几乎没有任何滤波器可以完美恢复出原图。
3. 为什么深度学习可以做环路滤波?
解决病态问题最常见的方式是将对信号的先验知识转化成正则化约束,从而缩小求解空间。卷积神经网络架构本身已经被证实可以很好地捕获自然图像的先验知识 [5] ,用其对图像进行滤波相当于使用了隐式正则化。此外, CNN 可以进一步从海量训练数据中学习到对特定任务(如这里的去压缩失真)有用的先验知识,建立起从失真图像到原图的映射,从而完成图像质量增强。
4.怎么做?
文献 [6] 是一项较早的尝试,其用 CNN 取代 HEVC ( High Efficiency Video Coding )中的环路滤波器 ( Deblocking 和 SAO ), 对压缩视频进行质量增强并取得较好效果。
为了完成这个任务,首先需要准备训练数据,即有失真图和对应的原图,这样 CNN 可以在训练过程中捕获失真图像到原图的映射。为此作者用 HEVC 对训练集图像进行压缩,以得到有失真的重建图像。将这些失真图像和对应原图组合在一起,便可以获得很多类似于{失真图像,原始图像}这样的训练样本。
接下来需要确定网络结构,这里 CNN 接受 MxM 大小的失真图像作为输入,然后输出 MxM 大小的滤波图像。因此,环路滤波任务属于图像质量增强的范畴,可以参考去噪, 超分辨等底层计算机视觉任务使用的网络架构。在这篇论文中,作者设计了如图 1 所示的 4 层 CNN ,其具体配置可见表 1 。由于此类任务输入和输出分辨率一致,为了保持高精度空间位置信息,网络结构中一般不包含下采样操作(注意是一般,部分网络会采用下采样操作增大空间感受野,同时通过增加卷积通道数,维持高精度重建)。该网络中间两层均使用了两种尺寸的卷积核,以获得多尺度特征。此外,网络包含一个跳层连接,即将输入图像和 CNN 最后一层的输出相加。这样一来,网络的实际输出变成了重建图像和原始图像之间的差异图像,体现了残差学习的思想 [7] 。残差学习的好处是可以在加快收敛速度的同时,提升收敛后的性能。
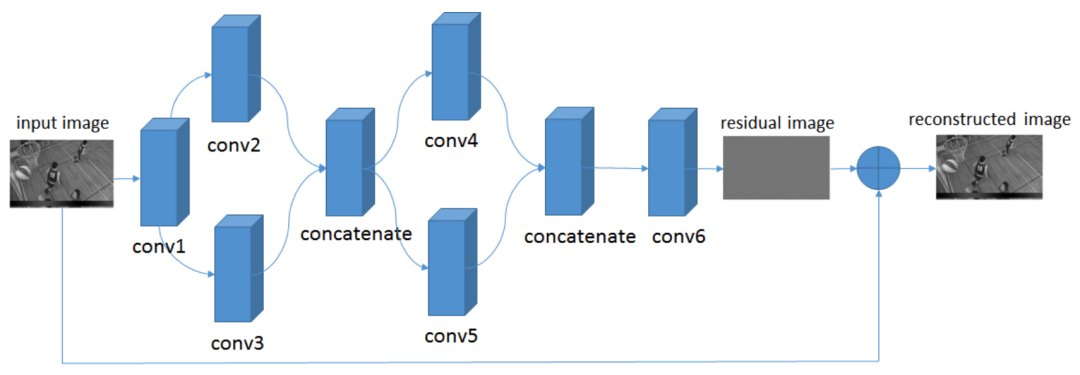
图 1. 文献 [6] 中的网络结构,一个 4 层的全卷积网络
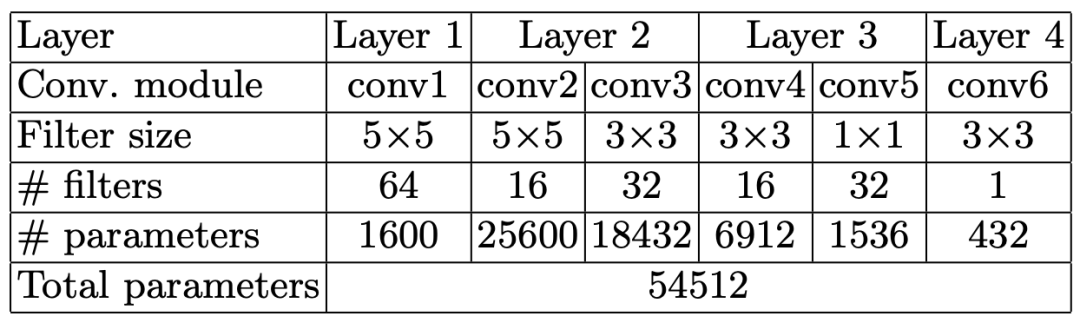
表 1. 文献 [6] 中的网络配置
为了驱动 CNN 训练,还需要损失函数,作者采用了如下式的 MSE 损失函数。这里 N 是训练样本个数, X 和 Y 分表表示失真图像和对应的原始图像, 𝜃 表示卷积网络的所有参数(权重以及偏置)。
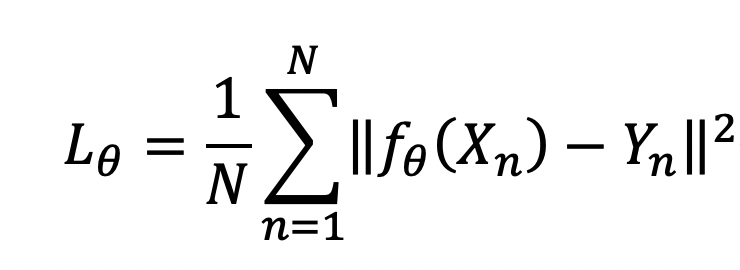
到此,便可以通过随机梯度下降法更新网络权重,这通常由深度学习框架(如 PyTorch )自动完成,训练结束以后获得的参数是对于整个训练集平均意义最好的参数。读者可能会问: 得到的参数是相对训练集最优,在未见过的数据集表现如何?通常我们假设:训练集和测试集从相同分布采样而来,这保证了 CNN 在测试集有相似表现。为了提升泛化性能,通常要求训练集包含足够多的样本,以反映数据的真实分布,此外,还有一些其他方法来避免网络过拟合,如对 CNN 参数(即上式中的 𝜃 )施加 1- 范数或者 2- 范数的约束,这类方法统称为正则化,是深度学习中很重要的一个研究领域。
作者为每个 QP 点,即 QP { 22 ,27 ,32 ,37 },分别训练了一个模型,然后将模型集成进参考软件进行测试,最终性能见下表 2 。这里对比的 anchor 是 HM-16.0 ,配置为 All-Intra 。由于只是在 All-Intra 配置下进行了测试,所以也可以将 CNN 滤波当成后处理操作。如果滤波后的帧作为后续帧编码时的参考,则成为环路滤波器。
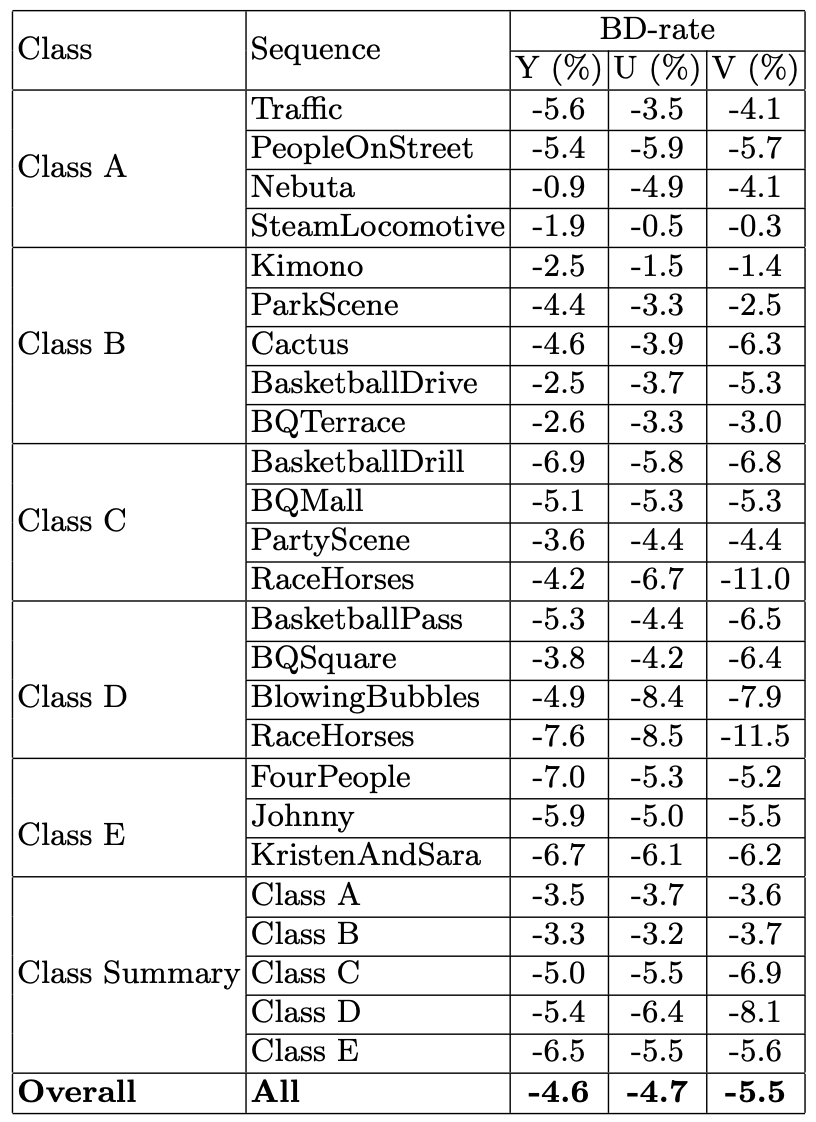
表 2. 文献 [6] 中算法相比于 HEVC 的 BD-rate 节省
5. JVET-U0068
接下来我们关注今年 JVET 一项提案中的环路滤波器设计 [8] ,该算法名为 DAM ( Deep-filters with Adaptive Model-selection ),是针对最新一代视频编码标准的参考软件 VTM-9.0 进行设计,并包含了模式选择等新特性。
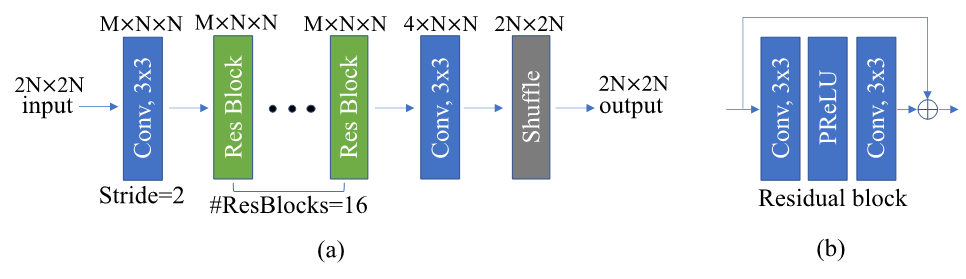
图 2. (a) DAM 使用的 CNN 架构, M 表示特征图的数量, N 代表特征图的空间分辨率;(b) 残差单元的结构。
网络架构:DAM 滤波方法的主干如上图 2 所示,为了增加感受野,降低复杂度,此网络包含一个步幅为 2 的卷积层,该层将特征图的空间分辨率在水平方向和垂直方向都降低到输入大小的一半,这一层输出的特征图会经过若干顺序堆叠的残差单元。最后一个卷积层以最后一个残差单元的特征图作为输入,输出 4 个子特征图。最后, shuffle 层会生成空间分辨率与输入相同的滤波图像。与此架构相关的其他细节如下:
1. 对于所有卷积层,使用 3x3 的卷积核。对于内部卷积层,特征图数量设置为 128 。对于激活函数,使用 PReLU 。
2. 针对不同 slice 类型训练不同的模型。
3. 当为 intra slice 训练卷积神经网络滤波器时,预测和分块信息也被馈入网络。
自适应模型选择:首先,每个 slice 或 CTU 单元可以决定是否使用基于卷积神经网络的滤波器;其次,当某个 slice 或者 CTU 单元确定使用基于卷积神经网络的滤波器时,可以进一步确定使用三个候选模型中的哪个模型。为此目的,使用{ 17 , 22 , 27 , 32 , 37 , 42 }中的 QP 数值训练不同模型。将编码当前 sequence 的 QP 记作 q ,那么候选模型由针对{ q , q-5 , q-10 }训练的三个模型构成。选择过程基于率失真代价函数,然后将相关模式表征信息写进码流。
推断:使用 PyTorch 在 VTM 中执行 CNN 在线推断,下表 3 给出了推断阶段的相关网络信息。
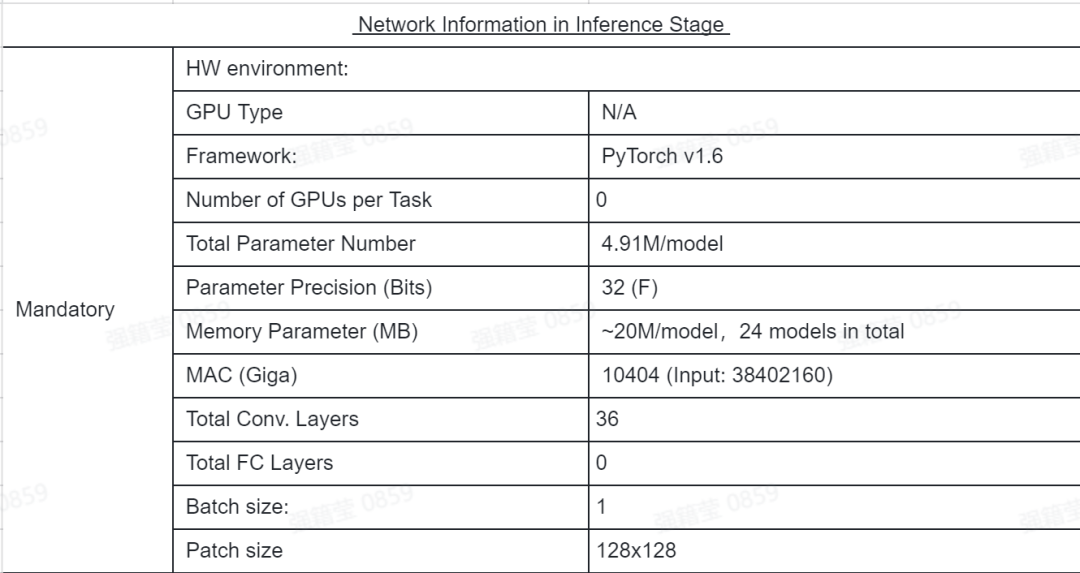
表 3. 推断时的网络信息
训练:以 PyTorch 为训练平台,分别训练针对 intra slice 和 inter slice 的卷积神经网络滤波器,并且训练不同的模型以适应不同 QP 点,训练阶段的网络信息列于表 4 中。
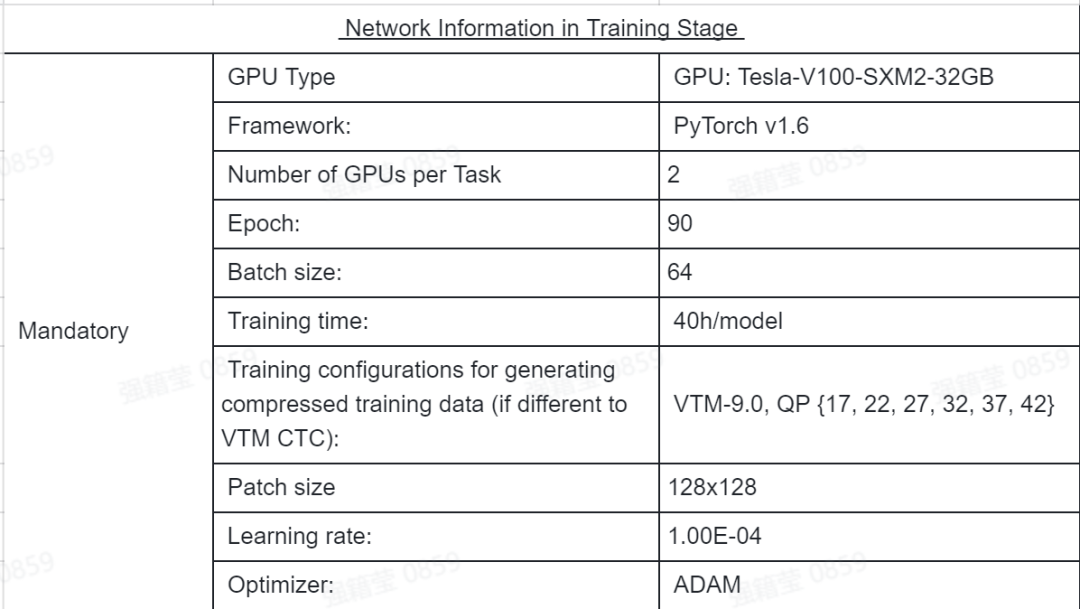
表 4. 训练时的网络信息
实验结果:作者将 DAM 在 VTM-9.0 上进行了集成测试,现有滤波器中的去块滤波和 SAO 被关掉,而 ALF (和 CCALF )则被置于基于卷积神经网络滤波器的后面。测试结果如表 5 ~表 7 所示,在 AI , RA ,和 LDB 配置下, Y 、Cb 、和 Cr 三个通道的 BD-rate 节省分别为:{ 8.33% , 23.11% , 23.55% }, { 10.28% , 28.22% , 27.97% }, 和{ 9.46% , 23.74% , 23.09% }。此外,图 3 给出了使用 DAM 算法前后的主观对比。
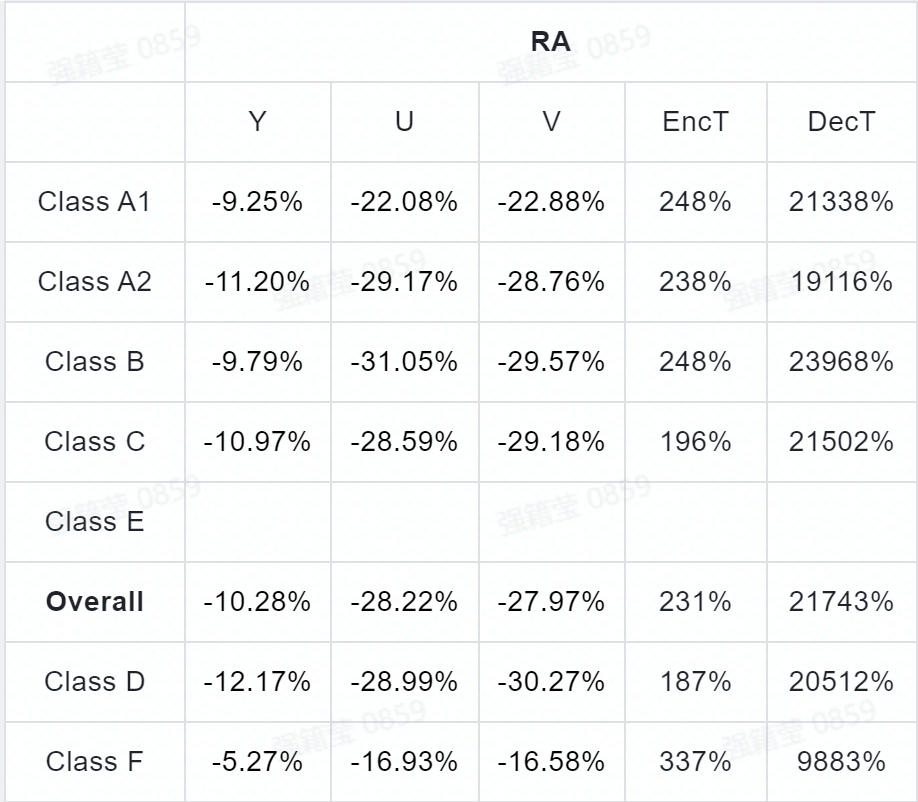
表 5. DAM 在 VTM9.0( RA )上的性能表现
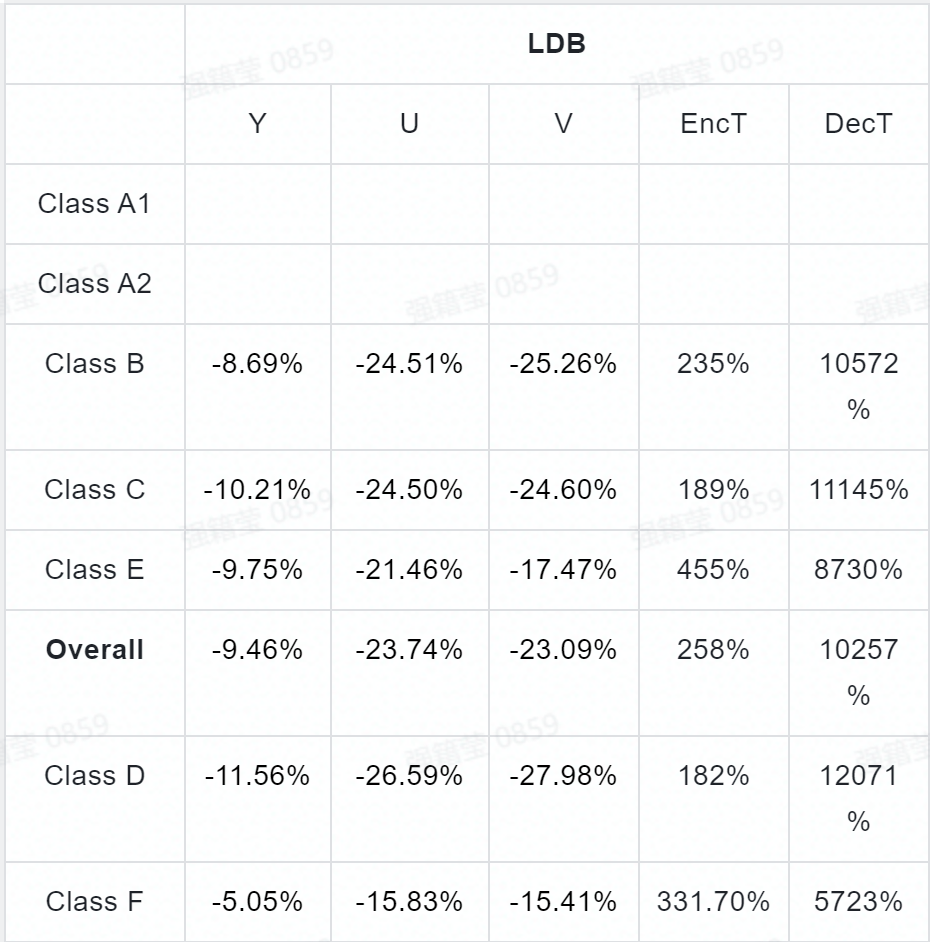
表 6: DAM 在 VTM9.0( LDB )上的性能表现
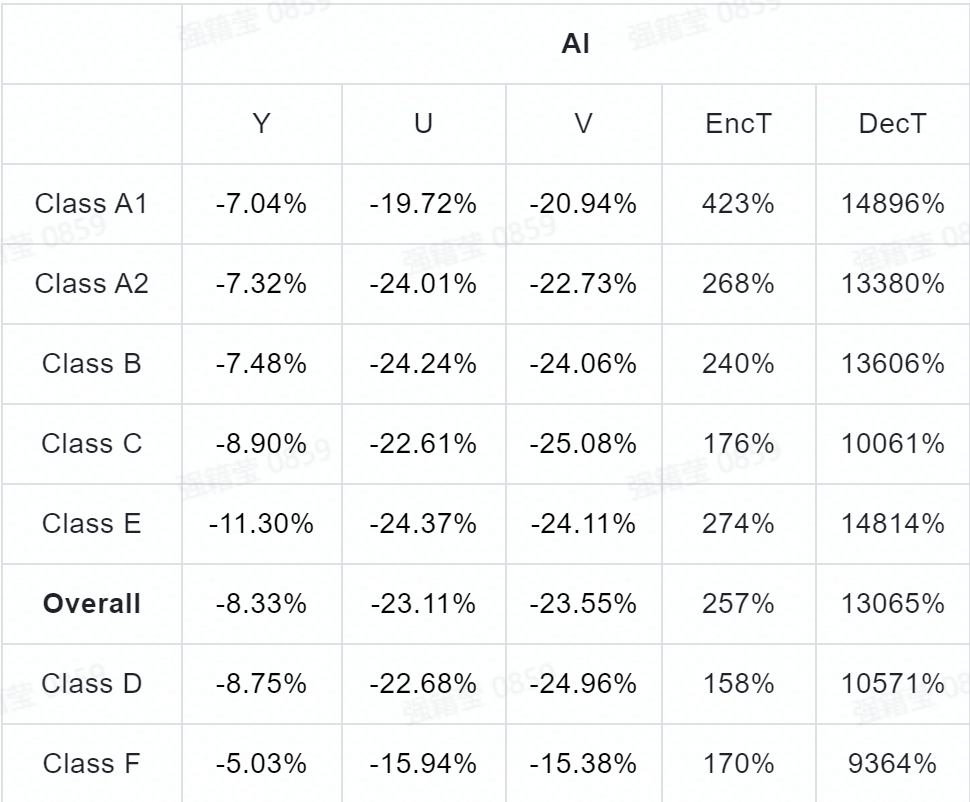
表 7: AVG 提案在 VTM9.0( AI )上的性能表现

图 3. 左:原图 (来自 JVET 通测序列 BlowingBubbles );中: VTM-11.0 压缩, QP42 ,重建质量 27.78dB ;右: VTM-11.0+DAM , QP42 , 重建质量 28.02dB .
6. 总结和展望
近年,环路滤波(包括后处理)的研究工作主要分布在以下若干方面(但不限于):
1) 使用更多输入信息,如除了重建帧还可以将预测和划分等信息作为 CNN 的输入 [9] ;
2) 使用更为复杂的网络结构 [9, 10, 11] ;
3) 如何利用视频图像帧之间的相关性提升性能 [12, 13] ;
4) 如何为不同的质量等级设计统一的模型 [14] 。
总体来说,基于深度学习的编码工具方兴未艾,其展现诱人性能的同时,亦引起较高的复杂度,未来为了将这些深度编码工具落地,复杂度-性能折衷优化将是一个很重要的研究方向。
7. 参考文献
[1] Wikipedia contributors. "深度学习." 维基百科, 自由的百科全书. 维基百科, 自由的百科全书, 10 Mar. 2021. Web. 10 Mar. 2021. ‹https://zh.wikipedia.org/w/index.php?title=%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0&oldid=64709501›.
[2] Norkin, Andrey, et al. "HEVC deblocking filter," IEEE Transactions on Circuits and Systems for Video Technology 22.12 (2012): 1746-1754.
[3] Fu, Chih-Ming, et al. "Sample adaptive offset in the HEVC standard," IEEE Transactions on Circuits and Systems for Video technology 22.12 (2012): 1755-1764.
[4] Tsai, Chia-Yang, et al. "Adaptive loop filtering for video coding," IEEE Journal of Selected Topics in Signal Processing 7.6 (2013): 934-945.
[5] Ulyanov, Dmitry, et al. "Deep image prior," Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
[6] Dai, Yuanying, et al. "A convolutional neural network approach for post-processing in HEVC intra coding," International Conference on Multimedia Modeling. Springer, Cham, 2017.
[7] He, Kaiming, et al. "Deep residual learning for image recognition," Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[8] Li, Yue, et al. “Convolutional neural network-based in-loop filter with adaptive model selection,” JVET-U0068. Teleconference, 2021.
[9] Lin, Weiyao, et al. "Partition-aware adaptive switching neural networks for post-processing in HEVC," IEEE Transactions on Multimedia 22.11 (2019): 2749-2763.
[10] Ma, Di, et al. "MFRNet: a new CNN architecture for post-processing and in-loop filtering," IEEE Journal of Selected Topics in Signal Processing (2020).
[11] Zhang, Yongbing, et al. "Residual highway convolutional neural networks for in-loop filtering in HEVC," IEEE Transactions on image processing 27.8 (2018): 3827-3841.
[12] Yang, Ren, et al. "Multi-frame quality enhancement for compressed video," Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
[13] Li, Tianyi, et al. "A deep learning approach for multi-frame in-loop filter of HEVC," IEEE Transactions on Image Processing 28.11 (2019): 5663-5678.
[14] Zhou, Lulu, et al. “Convolutional neural network filter (CNNF) for intra frame,” JVET-I0022. Gwangju, 2018.




