
在质量和成本方面,将 VectorRAG 与 GraphRAG 相结合的新方案将为行业带来革命性的变革。
近日微软推出了一种“不同于以往的方法”,名为 LazyGraphRAG,追求的是以高效、低成本的方式实现图形 RAG 功能。
微软方面的研究人员声称,这种新型 RAG 方案“在成本和质量方面实现了天然可扩展性”,能够“在理想的成本和质量范围之内表现出强大性能”。此外,它还降低了整个数据集的全局搜索成本,并使得本地搜索更加高效。
有些朋友可能不太熟悉,GraphRAG 是“Graph”图形与 RAG(检索增强生成)的混合词。这项技术通过单一端到端系统利用文本提取、网络分析以及大模型提示/摘要的方式,深入理解基于单词的数据集内容。
今年 7 月,微软首次开源了 GraphRAG,仅 4 个多月的时间在 Github 已有 19.7k 颗星,成为目前最火的 RAG 框架之一。
在人工智能领域,RAG 系统对于文档摘要、知识提取和探索性数据分析任务至关重要。但现有系统的主要问题之一在于成本与质量之间的权衡。
传统方法(如基于向量的 RAG)在处理局部化任务时表现良好,例如从特定文本片段中检索直接答案。然而,当涉及需要全面理解数据集的全局性查询时,这些方法往往难以胜任。相比之下,图支持的 RAG 系统通过利用数据结构中的关系,可以更好地解决此类更广泛的问题。然而,与图 RAG 系统相关的高索引成本,使其难以被成本敏感的场景所接受。因此,在可扩展性、经济性和质量之间实现平衡,仍然是现有技术的关键瓶颈。
这次微软推出的 LazyGraphRAG 是一种全新系统,不仅克服了现有工具的局限性,还融合了它们的优势。LazyGraphRAG 通过消除对高成本初始数据摘要的需求,将索引成本降至接近向量 RAG 的水平。
后续,微软也会很快发布 LazyGraphRAG 开源版本并加入到 GraphRAG 库中。
开源地址:https://github.com/microsoft/graphrag
成本降低至 1/1000
LazyGraphRAG 代表了检索增强生成领域的突破性进步,微软称它是“适用于所有场景的低成本解决方案”。
为了评估 LazyGraphRAG 的性能,微软设计了三种不同的预算场景,观察其在多种条件下的表现。
最低预算(100 次相关性测试,使用低成本 LLM,与 SS_8K 成本相同),LazyGraphRAG 在本地和全局查询中显著优于所有条件,仅在全局查询时略逊于 GraphRAG 的全局搜索条件。
中等预算(500 次相关性测试,使用更高级的 LLM,查询成本为 C2 的 4%),LazyGraphRAG 在本地和全局查询上全面超越所有对比条件。
高预算(1,500 次相关性测试),LazyGraphRAG 的胜率进一步提升,展现出其在成本与质量平衡方面的优异扩展性。
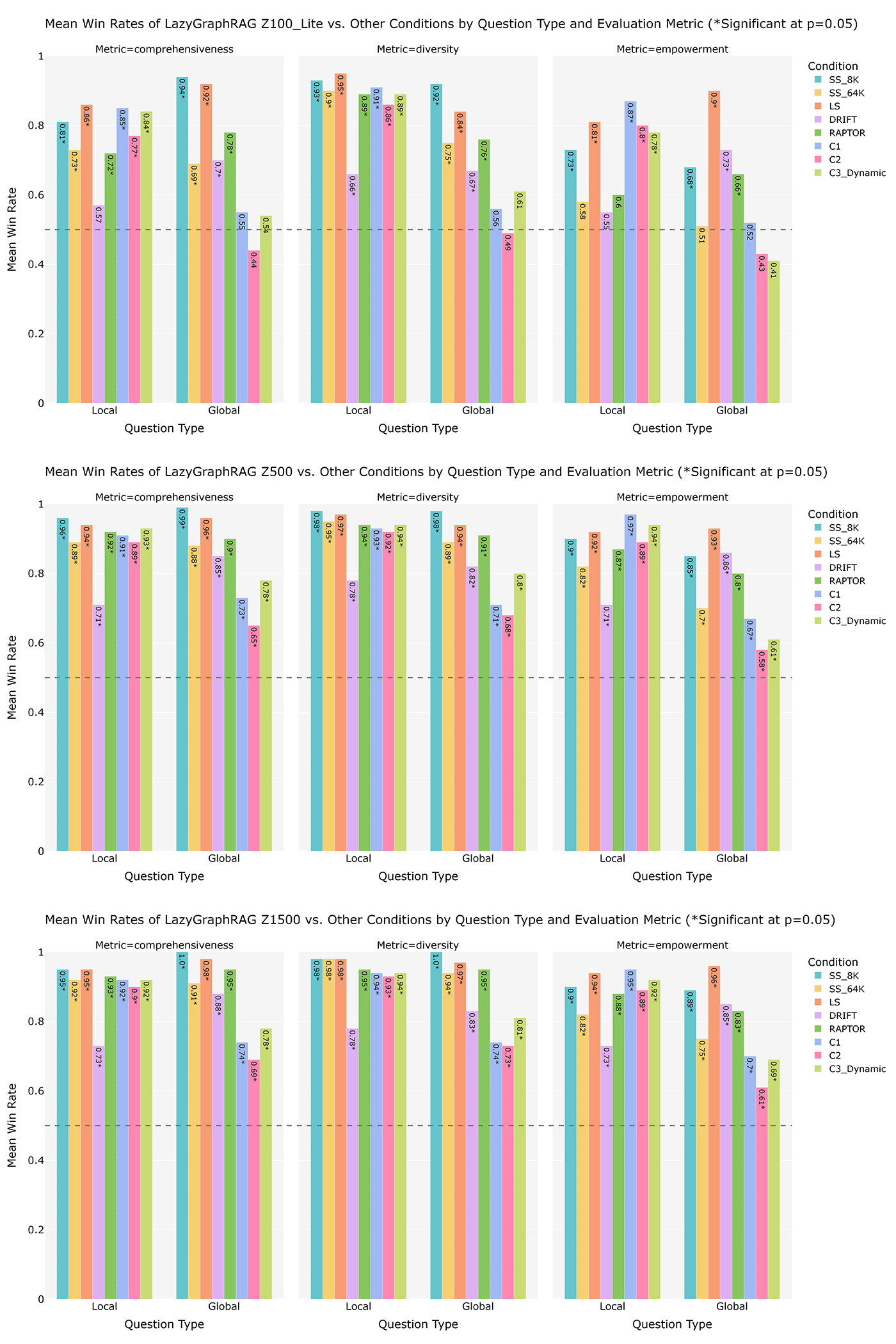
也就是说,LazyGraphRAG 将 VectorRAG 与 GraphRAG 相结合,“同时克服了二者的各自局限性”。微软方面写道,“LazyGraphRAG 表明,单一、灵活的查询机制有望在本地全局查询范围之内大大超越各类专用查询机制,而且消除了大语言模型的前期数据汇总成本。”
“其极快且几乎免费的索引功能,使得 LazyGraphRAG 成为致病性查询、探索性分析以及流式数据用例的理想选择。与此同时,它还能够随着相关性测试预算的增加而平衡提高答案质量,这使其成为对其他 RAG 方法进行基准测试的重要工具。”
Vector RAG 也被称为语义搜索,根据微软方面的解释,这是一种“最佳优先搜索形式,使用与查询的相似性来选择最佳匹配的源文本块。”“然而,语义搜索仍有一大短板,即无法满足全局查询所需要考虑的数据集广度。”
研究人员写道,“GraphRAG 全局搜索则是一种广度优先搜索,它使用源文本实体的社区结构以确保查询结果中能充分考虑到数据集广度。但问题在于,它无法识别本地查询所需要的最佳社区。”
在回答关于整个数据集内容的全局查询请求时,后一项技术往往比传统向量 RAG 效果更好,其适合的问题包括“核心主题是什么?”或者“这些信息体现了 X 的什么特征?”等等。总之,GraphRAG 更擅长提供重视广度的问题。
在另一方面,Vector RAG 则更适合本地查询场景下,答案跟问题结构相似的情况。例如涉及“谁、什么、何时、何地”之类的问题,微软强调这也是所谓“最佳优先”这种算法形式的由来。
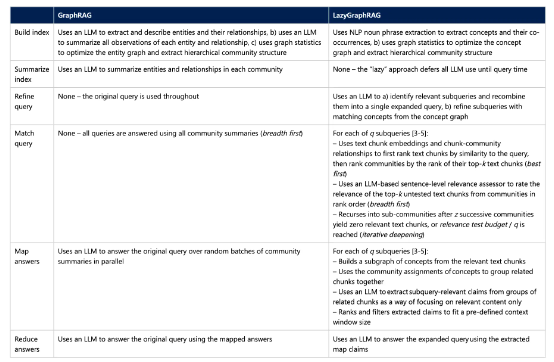
GraphRAG 与 LazyGraphRAG 之间的区别。
LazyGraphRAG 以迭代深化的方式将最佳优先与广度优先两种搜索动态结合起来——首先在有限的深度上进行搜索,之后再通过迭代深入数据集内部。
微软公司表示,LazyGraphRAG 的数据索引成本与向量 RAG 相同,而仅为完整 GraphRAG 成本的 0.1%。
“在同等配置下,LazyGraphRAG 也表现出与 GraphRAG 全局搜索相当的答案质量,但全局查询的成本却降低至 1/700 以下。只需要相当于 GraphRAG 全局搜索查询成本的 4%,LazyGraphRAG 就能在本地和全局两方面表现出明显优于所有竞争方法的查询效果。”
微软是这样回答这个问题的:“与完整的 CraphRAG 全局搜索机制相比,这种方法在某种程度上确实更「懒」,因为它会推迟对大模型的使用,从而大大提高答案生成效率。其整体性能可以通过一条主要参数(相关性测试预算)进行扩展,该参考则以一致的方式把控成本与质量之间的权衡。”
因此,这种勤奋的 RAG 方法确有“懒”的一面,因为它只在绝对必要时才会应用大语言模型(LLM),由此优化了对大语言模型的使用。它不会预先处理整个数据集,而是先进行初始相关性测试,分析较小的数据子集以识别出潜在的相关性信息。
在完成这些测试之后,系统才会使用资源密集型的大语言模型开展更加深入的分析。
虽然跟如今他的个人风格不尽相同,但这还是让我们想起比尔·盖茨当初执掌微软时说过的一句话: “我宁愿选个懒人去做困难的工作,因为懒人会找到一种更简单的办法来完成任务。”
参考链接:




