我非常喜欢敏捷宣言的第一句话,“通过开发软件和帮助他人开发软件,我们正在发现开发软件更好的方法”。它点出了我们一直以来所采取的共同协作之道。伴随着我们不断的学习和探索,敏捷方法也在持续进化。更为重要的是,敏捷方法和实践,是我们从开发人员纷繁芜杂的实际日常工作中积累、提炼出来的,而不可能来自理论研究的象牙塔。
如何构建满足需求并且能随机应变的软件?关于这个话题,我们从敏捷方法中受益良多。大概最有影响的技术就是单元测试了。单元测试强调隔离接受测试的各个单元,而接口(通过总是存在争议的 mocks, stubs, 和 fakes)为待测试的每个单元提供了良好的可分离性。
问题出在软件系统各个单元之间的连接或缺口上,它们也许衍生自设计阶段,也许存在于待测的系统单元之间。但此类问题并不新鲜。各自功能完备的软件单元,所构成整体系统的功能不一定完备;正是由于上述原因,才出现了功能测试这个敏捷实践。
然而,当你想要开发在现实生活中实际运作的软件时,功能测试便显露出了不足之处。功能测试只能告诉你“当软件的所有部分都按照软件需求规约运作时,会得到什么样的结果”。没错,你可以强迫一个系统或子系统返回一个错误响应,但原来的规定中还是要对这个错误有对应说明!如果你正要调用一个 EJB 的远程方法,该方法要么返回“true”或“false”,要么抛出异常;这都没有问题。但没有功能测试会要求它返回一个“purple”或其它什么。也不可能有什么功能测试能使这个方法永远暂停,或每秒返回一个字节。
在《Release it》一书中,我重复提到的主题之一就是:每一个对其他系统的调用必定会在某一天试图把你的应用干掉,毫无例外!通常这是由软件规约中没有描述的行为所导致的。一旦发生类似情况,就必须追溯到抽象层,深入到“并发用户”、“会话”、甚至是“连接”中去,找出问题根源所在。
接下来我要讲述一个当时无法解释的恼人问题。看看到底为什么会发生这样的状况。
凌晨5点问题
软件在发布之前都必须通过 QA 测试,而其生命周期是存在于实际生产环境中的。事实上它总是在实际生产环境中出现无法解决的致命问题。这就是我想说的问题。我的腿并不瘸,我也不对 Vicodin 上瘾,但除此之外,我有点象 Gregory House 医生。当大流量事务系统宕机时,我所得到的案例,按照常理是无法解释的。你在电视剧里看不到这样的案例,但再次声明一下,我可做不出像 Hugh Laurie 那种性感的、愤世嫉俗的、鄙夷不屑的表情。(译者注:上述语句的出处,请看美剧《House. M. D.》)
House 医生认为发生问题的通常原因,要么是毒品,要么是感染,除非出现某个症状显示可能是其它理由。而面对我的案例,我总是先怀疑系统彼此之间的整合处。在引发系统崩溃的众多原因中,整合处引发的问题是最多的,其数量甚至超出了拙劣代码所造成的问题个数。我甚至敢于声明,在应用系统中,那些整合处迟早会因某些原因而出现故障。有可能是因为拒绝连接,也有可能因为返回了不完整的响应。有可能当你想得到 XML 时,它却返回了 HTML。有可能速度实在是太慢,甚至根本就不响应。
我认为数据库调用是整合处问题的一个特殊案例。数据库的复杂程度非常之高,但很多开发人员只是觉得它们应该可以正常工作。随便发送给数据库任何超级复杂的 SQL 语句,它都会返回整齐的结果集;开发人员认为这是理所当然的。多数情况下,他们更多的考虑在 SQLConnection 的清晰抽象之下,具体发生了什么。
不要被错误的安全感所麻痹,对数据库的任何操作都可能因为发生问题而被挂起,这些操作不仅仅局限于造成死锁的 insert 和 update,或是来源于存储过程。我曾经看到一个案例:一个不允许任何人进行 update 操作的只读数据库,由于对其进行循环查询,最终还是出现了问题。
快去找急救推车!这个网站不行了!
每天的同一时间宕机
在我所参与过的网站中,有一个网站所发生的问题非常诡异:几乎每天早上 5 点,它都会宕机。发生问题时,有大约 30 多个不同的应用实例正在运行;某种原因使这 30 多个实例全部死掉,并且是在 5 分钟之内(通过我们的 URL pinger 产生的数据解析而得)。重启应用服务器后,问题解决;也就是说,是由于那短短 5 分钟内发生的事情导致网站宕机。不幸的是,每天的流量都是从这时候开始攀升。从午夜到早上 5 点,每小时只有 100 个连接,但当东海岸的人开始上线后,这个数字迅速上升(美国东部时间比中部时间早一小时)。正当人们要开始认真使用网站的时候,重启所有的应用服务器并不能算是一种理想的解决方案。
这个问题发生的第三天,我从一个发生问题的应用服务器中取出了其中堆积的线程。在服务实例启动和运行后,所有的请求处理线程都被阻塞在 Oracle 的 JDBC 库中,更明确的说,是发生在对 OCI 进行调用时。(我们使用的是瘦客户端驱动,因为它具有出色的故障转移特性。)实际上,当消除了那些试图调用同一个同步方法的线程后,我发现活动线程们都在进行低层 socket 的读写调用。
接下来要做的就是使用 tcpdump 和 ethereal(Ethereal 现在被称为 Wireshark)。可是采取措施之后,成效微乎其微。从应用服务器向数据库服务器发送一些数据包后,却得不到任何响应,也没有任何信息从数据库发送到应用服务器。但通过监控发现数据库是正常工作的,没有任何死锁,运行队列为空,而且几乎没有 I/O 操作。
抓取数据包
从抽象到具体
使用抽象的方式可以让你的表达变得更加简明扼要。直接讨论如何从一个 URL 中得到文档的过程,要比从初始连接、数据打包、应答、接收窗口等等这些冗长乏味的细节入手要容易得多。即使有了高层抽象,当出现问题的时候,我们还是需要抽丝剥茧,深入这些抽象内部的底层细节,寻找发生错误的原因,以利于后面的修正。在网络环境中,要进行问题诊断或是性能调优,数据包抓取工具是我们追根寻源的唯一工具。
tcpdump是 UNIX 系统下从网络上抓取数据包的常见工具。当在“混淆(promiscuous)”模式下运行时,它会通知网卡 (NIC) 接收所有经过它的数据包,甚至是那些发送到其它计算机的数据包。在数据中心,NIC 几乎肯定是连接到分配给某个虚拟局域网(VLAN)的交换机端口上(switch port)。此时,交换机保证了发往该虚拟局域网内所有地址的全部数据包都被 NIC 所接收。这是一个很重要的安全措施,因为它可以防止外部不怀好意的人做坏事,比如探测网络中他所感兴趣的信息之类。
Wireshark 具有探测器(sniffer) 和协议分析器 (protocol analyzer) 的功能。 它不但可以象tcpdump一样探测数据包,而且还可以为我们解开数据包。Wireshark 在过去曾经有过一些或轻或重的安全纰漏。有些时候,恶意软件或是已经中招的计算机会向网络发送经过“特殊”处理的数据包,这个包会触发缓冲区溢出,并执行攻击者设定的恶意代码。像其他数据包抓取工具一样,Wireshark 必须使用 root 的权限,才能运行“混淆(promiscuous )”模式,因此上述漏洞会使得攻击者在网络管理员的机器上获得 root 权限。
除了安全问题以外,Wireshark 还是一个很笨重的 GUI 程序。在 UNIX 系统上,它需要一些 X 库,而这些库在 headless 系统上是不会安装的。在任何配置的计算机上运行 Wireshark,它都会占用很多内存和 CPU 来解析和显示数据包。在生产环境中使用的服务器上,不应安装 Wireshark 以避免其形成负担。由于上述原因,最好以非交互的方式使用 tcpdump 来完成数据包的抓取,并将其保存在文件中,然后将抓取文件移动到非生产环境中进行分析。
下面的截屏图显示了在我的家庭网络上捕获的一些数据包。第一个包显示了一个从我的无线网桥发送到我的有线 modem 的一个 ARP 请求,看起来这好像是个问题。第二个包很奇怪:是发送到 Google 的 HTTP 查询,请求一个 URL,链接为 /safebrowsing/lookup,还带了一些参数。接下来的两个数据包显示了一个 DNS 查询和响应,其主机名为“michaelnygard.dyndns.org”。第五、六、七数据包是建立 TCP 连接的三段式握手。我们可以跟踪 web 浏览器和服务器之间的整个会话。在数据包追踪下面的方格中,展示了第二个数据包中的层次结构,这个结构由 TCP/IP 堆栈围绕 HTTP 请求所创建;外层是一个包含了 IP 数据包的以太网数据包,IP 数据包中又包含了一个 TCP 数据包。最后,TCP 数据包的有效负载是一个 HTTP 请求。整个数据包的准确字节数在第三个方格中。
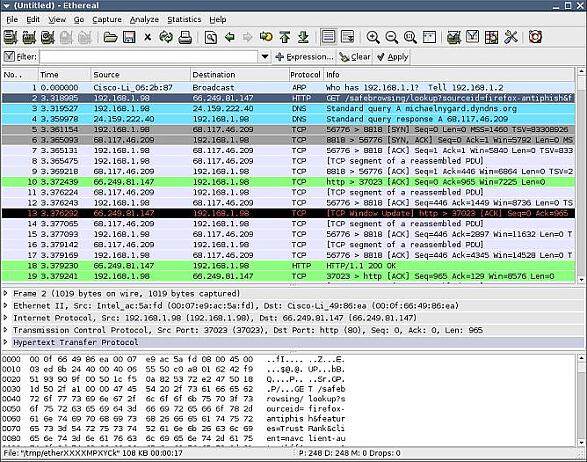
对这类问题,我强烈推荐在身边放一本 Kozierok 的《The TCP/IP Guide》或者 W. Richard Steven 的《TCP/IP Illustrated》。
重复与偏执
理解灾难背后的根本原因
到了这时候,我们不得不重启应用服务器。我们的第一要务是恢复服务;然后在不破坏服务品质协议(SLA)的前提下,做一些力所能及的数据收集工作。更深层次的研究只能等灾难再次发生才能进行了。没有人怀疑问题会再次出现。
确实如些,第二天早上,灾难再一次降临了。应用服务器死的硬硬的,像绷紧的鼓皮,一堆线程挂在 JDBC driver 上,整个情况一团糟。这次,我可以看到数据库网络上的流量情况。竟然毫无动静!防火墙另一侧的数据库服务器上没有发生任何流量。根据这个最大的线索,我做出一个假设。通过对应用服务器资源池处理类的反编译,验证了我的假设似乎是有道理的。
我提到过 socket 连接是一个抽象。他们作为网络一端的计算机内存中的一个对象存在。一旦建立之后,一个 TCP 连接对象可以一直存在好几天,即使没有收到任何数据包。只要两个计算机在内存中保存了 socket 的状态,这个“连接”就依然有效。路由可以改变,物理链路可能发生断路并重新连接。这都没关系。只要两端的计算机认为它还在,这个“连接”就一直保有在内存中。
有一次,所有的一切都可以正常运转。那些日子里,有些偏执的家伙破坏了整个网络运行所基于的理论与实践。没错,我是在说防火墙出了问题。
防火墙只不过是个特别的路由器。它将数据包从一些物理端口路由到另一些物理端口。在每个防火墙内部,一整套访问控制列表定义了允许连接的规则。这些规则看起来就象“IP 地址从 192.0.2.0 到 192.0.2.24 的这些计算机,可以向 192.168.1.199 的 80 端口发起连接”。当防火墙发现一个进来的 SYN 数据包时,它会根据那些规则进行检查。这个数据包可能被批准(被路由到目标网络),也可能被拒绝(TCP 重置数据包并发回),也可能被忽略(扔掉数据包而且不做任何响应)。如果连接被批准,那么防火墙在它自己的内部表中做一个标记,例如“192.0.2.98:32770 已连接到 192.168.1.199:80”。此后的数据包只要匹配这个标记,就可以在防火墙的网络中进行路由。
到目前为止一切顺利。那么这与那些早上 5 点把我叫醒的电话有什么联系呢?
问题关键在于防火墙内部建立的那个连接表。它是有限的,所以它不许无限期的连接,尽管 TCP 本身允许无限期连接。除了记录连接的端点之外,防火墙也记录了“最后到达数据包”的抵达时间。如果很长时间不在连接中传递数据包的话,防火墙会认为端点已经无效,并从列表中删除这个连接。TCP 的设计却不这么高明。也没有什么第三方来告诉网络的两个端点,连接已经被停掉了。尽管没有传递数据包,这两个端点还是认为它们之间的连接有效,并且可以一直持续下去。
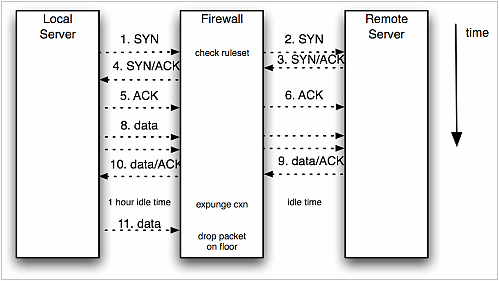 打那儿开始,由于 socket 端口的半开状态,从任何一端的 socket 端口进行读写操作,都不会引起 TCP 重置或报错。相反,TCP/IP 堆栈发送这些数据包,等待 ACK 应答信号;如果等不到,就再次发送。忠实的堆栈一次又一次地重建连接,而防火墙不断地把发送过来的数据包扔到一边去,而且不返回“ICMP 目标不可达”这样的消息(攻击者可以通过欺骗源地址来侦测活动连接)。我所使用的 Linux 系统,运行在 2.6 内核上,它把自己 tcp_retries2 的默认值设置为 15,这样,在 TCP/IP 通知 socket 库之前就会有一个 20 分钟的时间间隔。我们当时使用的 HP-UX 服务器的超时时限设置为 30 分钟。因此发生问题的应用所发出的 socket 写操作可以阻塞 30 分钟!socket 读操作遇到的情况更加糟糕,它会被永远阻塞下去!
打那儿开始,由于 socket 端口的半开状态,从任何一端的 socket 端口进行读写操作,都不会引起 TCP 重置或报错。相反,TCP/IP 堆栈发送这些数据包,等待 ACK 应答信号;如果等不到,就再次发送。忠实的堆栈一次又一次地重建连接,而防火墙不断地把发送过来的数据包扔到一边去,而且不返回“ICMP 目标不可达”这样的消息(攻击者可以通过欺骗源地址来侦测活动连接)。我所使用的 Linux 系统,运行在 2.6 内核上,它把自己 tcp_retries2 的默认值设置为 15,这样,在 TCP/IP 通知 socket 库之前就会有一个 20 分钟的时间间隔。我们当时使用的 HP-UX 服务器的超时时限设置为 30 分钟。因此发生问题的应用所发出的 socket 写操作可以阻塞 30 分钟!socket 读操作遇到的情况更加糟糕,它会被永远阻塞下去!
当我反编译了资源池类以后,我发现它采取了后进先出策略。漫漫长夜之中,网站流量非常小,只需要从资源池中取出一个数据库连接就可以完成工作。下一个请求会用同一个数据库连接。直到流量上来以前,另外三十九个连接全部处于空闲状态。在防火墙中空闲连接超时设置为一个小时,而且三十九个连接空闲时间也超过了一个小时。
一旦流量开始升高,另外三十九个连接马上就锁定了。尽管剩余的一个连接还可以生成页面,但它迟早会被某一个线程占用,该线程阻塞在其余资源池的连接上。因此,唯一好使的连接也被阻塞线程占用了,整个网站也就掛了。
Dead Connection 起效
找到解决方案
明白了故障发生的完整过程,我们就该找出解决方案了。我们可以让资源池在提供 JDBC Connection 前可检查它们的有效性;它可以通过执行类似 SELECT SYSDATE FROM DUAL 这样简单的 SQL 查询来进行检查;可这会使请求处理线程挂起并导致服务器当掉。我们也可以让资源池追踪 JDBC Connection 的闲置时间,并抛弃那些超过一小时的 JDBC 连接。可不幸的是,在这些连接中,有些是用来向数据库服务器发送数据包以通知它 Session 失效的。结果服务器同样就“挂了”。
于是我们开始采取一些非常复杂的措施,其中就包括创建“收割”线程,去查找那些驻留时间过久的连接,并在超时之前把它们干掉。庆幸的是,有一个机灵的 DBA 想起一件事:Oracle 有一个叫作“dead connection detection” 的特性,通过它你可以发现客户端的崩溃时间。将其参数设为“enabled”后,数据库服务器会周期性的发送一个 ping 数据包到客户端。如果客户端有响应,数据库就知道它仍然是激活的。如果重试几次后客户端还没有响应的话,数据库就认为客户端已经崩溃,并释放该连接所掌握的所有资源。
我们不太关心客户端是否崩溃,ping 数据包应该可以为当前连接重置防火墙的“最后到达数据包”的抵达时间,以保证连接有效。“Dead connection detection”这一特性会保证连接是激活的,这就可以让我们睡个好觉了。
得到的教训是什么?
过去我们从没想过要去写一个单元测试,以模拟在 TCP/IP 协议下数据库调用被无限期挂起的行为。为什么要写呢?甚至更糟的是,这些容易出错的网络、服务器和应用,有无数种方式产生类似的“超出规约”的故障。那我们可以做些什么呢?这是否意味着,在 agile 的世界中,人们错失了某个实践呢?是否存在某种测试技术或代码实践可以让我们避免这类故障呢?
以前没有人能想象程序员会测试自己的代码。二十年前,这样的想法会让人笑掉大牙。而现在,单元测试却是大家所期望的,有时甚至是必须的。越来越多的人甚至用 Michael Feather’的定义来识别“遗留代码”,这个定义就是:没有单元测试的代码。也许,有人会发明一种测试技术,可以防止由于最基本的抽象层面发生问题而导致的无数故障。
在那之前,我认为我们必须考虑架构问题,甚至在敏捷项目中也一样,以避免类似的错误再发生在我们身边。我们在功能性方面使用设计模式;同样的,为了保证灵活性,我们也要应用设计模式。在《Release It》中,我创建了一套这样的“稳定性模式”。我希望这只是一个开端。
关于作者
致力于在全国范围内帮助开发人员减轻他们的痛苦。他向遇到的人共同分享他的热情和能量,来帮助他们提高,即使有些人并不情愿。Michael 花了将近二十年的时间,来学习如何成为一个关心艺术、质量和工艺的专业程序员。现在他已经是一个具有二十年经验的专业程序员和架构师。其间,他的工作领域涉及美国政府机构、军事、银行、金融、农业和零售业。 除此之外,Michael 常常自己开发一些系统。 这些来自现实世界的经验永远改变了他对软件架构和开发的看法。
最近,Michael 完成了一本书,名为《Release It! Design and Deploy Production-Ready Software》。他认为软件不应该仅仅是通过QA 测试,更要在现实世界中长期运行;众多关于如何构建此类软件的想法,都在书中得到了阐述。本书发行以后,它在Amazon 的软件开发书籍类别中,名列热销第一名达一个月之久。Michael 之前也写了很多文章和评论,并在Comdex 会议上演讲,并且是早期Java 相关书籍的合著者。




