计算机世界中有一些非常基础、重要、应用广泛而又特别容易让人困惑的主题,比如字符编码、字节序 (即大小端表示) 浮点数实现、日期时间处理以及正则表达式等等,而正则表达式是其中的典型代表。
然而正则表达式作为那种没用过的话,不觉得对自己有什么影响,一旦用过并且用熟练了,就再也回不去了的神器,要熟练掌握并能灵活运用,实非易事。
那到底应该怎样才能最高性价比地掌握正则表达式这个神器呢?这正是我写这个系列文章的目的。
首先,应从编程语言发展史和编程范式的角度,理解正则表达式是一个字符匹配领域的领域特定语言 (DSL),具有高度简洁、高度抽象的特点。
另外,学习过程中,不能不求甚解,应充分了解正则引擎的基本原理 (当然,如果不是正则引擎开发者,一般用户也不必过于深究其技术实现细节);应充分辨析多个多义元字符,以免混淆,比如 -、+、?、^,尤其是元字符?;深入理解转义,掌握其规律;不要期望短期内迅速掌握,正确的学习方法是:先简单了解一些基本的规则与元字符,不用刻意去强行记忆,而是应在实践中多运用,边学、边深入、边熟练。
还有就是除了看入门教程、经典著作之外,可以关注本系列文章。前面提到过,考虑到正则表达式的学习不可能短期内通过死记硬背掌握,必须边用、边学、边深入,因此需要一本按语法元素将知识点综合在一起进行编排的、在需要回过头来看时能够随时快速翻查的速查手册。而本系列文章的编排体例正是以速查手册的方式来安排的。
最后一点是,牢记“工欲善其事,必先利其器”,应充分利用 regex101.com、RegexBuddy、regexper.com 等这些堪称学习正则表达式这个神器的神器。
本系列文章出自于我自己在学习正则表达式的过程中所经历过的真切体会和真实痛点。虽然会涉及到正则引擎内部的相关匹配原理与匹配机制的解释,但出于更偏向实践运用的目的,不会花费过多的笔墨在 DFA、NFA 等过于深入的正则表达式幕后技术细节的讲解上。
我相信通过反复阅读本系列文章,再多加练习、勤于实践,然后在实际运用时再不断回过头来随时翻看,应该完全可以熟练掌握正则表达式这个像“毒品”一样会让人上瘾的神器。
下面为本系列的前两篇文章:
前文大致上对正则表达式构成、字符串构成、匹配过程以及匹配定位指针与匹配控制权、占有字符(消费字符与消耗字符) 匹配和不占有字符(零宽度) 匹配、八大原则进行了简要概述,接下来将正式进行开始逐个正则元素的介绍,本文首先介绍正则表达式的定界符与转义符。
一、定界符
定界符,也称为分隔符,一般为正斜杠(正斜线)/,但实际上除了字母、数字和反斜线\以外的任何字符都可以作为定界符号,只要前后成对出现即可,比如##、||、//、{}、!!、%% 等等。
不过习惯上多以正斜杠/ 作为定界符,因而若有正斜杠/ 本身要匹配时就必须用\/ 来转义;但如果正则表达式中正斜杠/ 频繁出现时,这样就会很不方便,也不美观,并且可读性也不好,所以此种情况下就可以使用其他字符来作为定界符。
也就是说,如果使用正斜杠/ 作为正则表达式的定界符,那么正则表达式中的正斜杠/ 则必须转义;如果不使用正斜杠/ 作为正则表达式的定界符,那么正则表达式中的正斜杠/ 则不必转义。
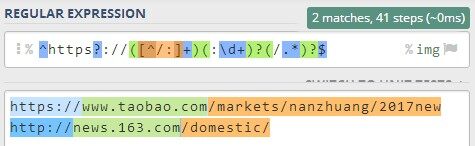
比如,URL 中含有正斜杠/,为了避免对匹配URL 的正则表达式中的正斜杠/ 进行转义,可使用正斜杠/ 之外的其他字符作为定界符,比如使用百分号%% 作为定界符:
%^https?://([^/:]+)(:\d+)?(/.*)?$%img
(说明:^ 匹配 URL 的起始位置,https? 匹配以 http 或 https 开头的 URL,第 1 个捕获组 ([^/:]+) 匹配主机名,第 2 个捕获组 (:\d+)? 匹配可能存在也可能不存在的端口号,第 3 个捕获组 (/.*)? 匹配可能存在也可能不存在的路径,$ 匹配 URL 的结束位置,i 表示不区分大小写,m 表示多行模式,g 表示全局模式)
在 regex101 的 PHP 版本中测试结果如下:
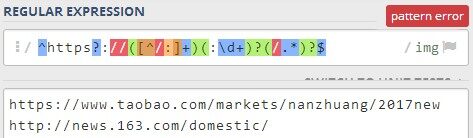
若仍使用正斜杠 / 作为定界符,则必须对正则表达式中的正斜杠 / 进行转义,否则提示“pattern error”错误:
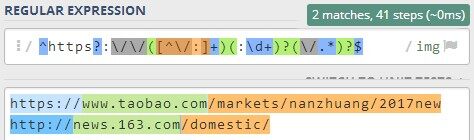
当然,这种情况下,若正则表达式中存在百分号 %,则百分号 % 必须写成转义形式:\%,否则报错。
显然,应该尽量选用不出现在正则表达式中的字符作为定界符。
二、转义符
反斜杠 (反斜线)\用作转义字符序列中的前导符,因此称之为转义符。【“\”其实是一个多义字符,也用于表示一个引用 (后向引用、捕获组引用、引用捕获组,详见本表后文)】
所谓“转义”,可理解为前导字符“\”转变了紧接其后的字符的原本含义,从而具有了新的含义;因此,“转义”即“转变含义”。
下列几种情况都必须使用以前导符“\”开始的转义序列予以转义:
1、将某些具有特殊含义的字符 (称之为元字符) 使其失去特殊含义而成为普通字符,比如要匹配量词 * 本身这个字符,则必须写成:\*;
2、将某些不具备特殊含义的字符 (在正则表达式中按其本义出现,它们匹配自身) 使其具有特殊含义,包括;
1)将不可见字符 (即不可视字符,也称为不可打印字符、不可显示字符,比如换行符、制表符等) 可见化 (可视化) 以便于书写,比如换行符写成:\n;
2)其他情形,比如\d 代表 0~9 中的任一数字,\b 代表单词边界等。
因此,正则表达式中的转义序列按其所表示的含义,可分如下 3 种:
1、\加上元字符 (特殊字符),将元字符转义为普通字符:表示将具有特殊含义的元字符 (包括:\、(、)、[、]、{、}、.、-、*、+、?、|、^、$,共 15 个元字符) 转义为不再具有特殊含义的普通字符 (即匹配元字符所使用的普通字符本身),如“\*”表示匹配普通字符星号 *,详见下表(注意,右方括号]、右花括号}虽然也属于元字符,如果不会发生二义性,一般无需转义,但转义了也没问题)。
2、\加上非元字符 (普通字符),将普通字符转义为特殊序列——元转义序列:表示将普通字符转义正则表达式中具有特殊意义的序列,如“\b”表示“单词边界”,这种转义序列或可称之为元转义序列。包括:
固定字符:\a、\b(字符组内部)、\e、\f、\n、\r、\t、\v(非 Perl 系);
字符组简记:\d、\D、\h、\H、\N{}、\p{}与\pP、\P{}与\PP、\s、\S、\v(仅 Perl 系)、\V、\w、\W
进制转义字符:\octal-num(Perl 系中也可写作\o{octal-num})、\xhex-num(Perl 系中也可写作\x{hex-num})、\uhex-num(非 Perl 系,Ruby1.9+ 等个别语言中还可写作\u{hex-num});
控制字符:\cX 系列;
锚点:\A、\z、\Z、\b(字符组外部)、\b{}、\B、\B{}、\G;
引用:\num、\g{num}、\gnum、\k{name}、\k
修饰:\E、\F、\l、\L、\Q、\u(仅 Perl,不是仅 Perl 系)、\U;
其他:\C、\K、\N、\R、\X、\<、\>。
注意:不同语言或工具中支持情况不一致:不同语言或工具中支持情况不完全一致,详情可参看后续各元转义序列的介绍。
注意:字符组内部与字符组外部的元转义序列:在 PCRE 流派中,上述元转义序列里,与字符相关的前四类 (即固定字符、字符组、进制转义字符、控制字符这四类),除了固定字符中的\b 之外的元转义序列在字符组内部与字符组外部含义相同;剩下的后四类 (即锚点、引用、修饰、其他这四类,除其他类中的部分元转义序列之外,均不与字符相关),仅在字符组外部具有特殊含义,在字符组内部不具有特殊含义,不要在字符组内部使用。详见“字符组”的相关内容。
3、\加上任意其他字符 (普通字符):这其实是一种无效或者说是错误的转义;一般默认情况就是匹配反斜线\后面的字符 (也就是说,反斜线\被忽略了;若反斜线\后面既没有再跟一个反斜线\以代表反斜线自身,也不能与紧跟其后的字符构成元转义序列,则因为单个反斜线没有意义而只能忽略),但实际情况依不同语言或工具的不同而会有所差异 (比如有的语言或工具中会报错等等),所以尽量注意不要出现这种转义。
比如,正则表达式中的“\?”匹配字符串中的一个“?”(问号“?”为正则中的元字符,要匹配“?”本身则必须转义),“\n”匹配一个换行符(“\n”为不可见的换行符,要匹配不可见字符则必须在正则表达式中通过转义来使其可见化才便于书写),“\\”匹配一个“\”(“\”在正则表达式中为转义前导符,要匹配字符串中的反斜杠“\”其自身也必须转义),“\\n”匹配字符序列“\n”(“\”在正则表达式中为转义前导符,要匹配字符串中的反斜杠“\”其自身也必须转义)。
下表为正则表达式中的元字符,当需要匹配该字符本身时,必须转义:
元字符
元字符说明
转义序列
备注
\
转义符
\\
(
左圆括号
\(
要匹配左右圆括号本身,左右圆括号都必须转义,不能只对左圆括号转义
)
右圆括号
\)
[
左方括号
\[
要匹配左右方括号本身,一般只需对左方括号转义,不需要对右方括号转义(虽然右方括号也是元字符),除非会引发歧义 (即二义性)。
比如字符组内部的右方括号一般情况下都要转义:[a-z\]](匹配一个小写字母或右方括号);而表达式"\[ab]"会被解释为单独的 4 个字符:[、a、b、],能匹配字符串“[ab]”;表达式"ab]"会被解释为单独的 3 个字符:a、b、],能匹配字符串“ab]”。
不过,转义了也没问题。因此,为了减轻记忆负担,凡是要在正则表达式中表示左方括号“[”字符本身和右方括号“]”字符本身,一律转义也是可以的,这样可读性反而更高,更好理解。
{
左花括号
\{
要匹配左右花括号本身,一般只需对左花括号转义,可以不用对右花括号转义(虽然右花括号也是元字符),不过转义了也没问题。
因此,为了减轻记忆负担,凡是要在字符组外部 (花括号在字符组内部不是元字符) 表示左花括号“{”字符本身和右花括号“}”字符本身,一律转义也是可以的,这样可读性反而更高,更好理解。
.
句点
\.
-
连字符、减号
\-
只有连字符 - 在字符组的内部,并且出现在两个字符之间时,才是元字符,用来表示字符的范围;否则如果出现在字符组内部的开头 (即左方括号后面) 或结尾 (即右方括号前面),以及在字符组的外部不作为减号时,则不是元字符,只表示连字符 (或减号) 本身。
比如,[a\-c] 等价于 [-ac] 或 [ac-],[-a-z] 匹配一个连字符或任意一个小写字母,[0-9-] 匹配任意一个数字或一个连字符,-[-] 匹配两个连续的连字符。
不过,为了减轻记忆负担,凡是要在字符组内部表示“-”字符本身,一律转义也是可以的,这样可读性反而更高,更好理解。
减号包括:取消内联匹配模式修饰符 (Java、C#、PHP、Go 等)、字符组运算符 (C#)、平衡组运算符 (C#)。
*
量词
\*
+
量词
\+
?
量词、懒惰匹配说明符、前导符
\?
前导符包括:命名捕获分组前导符、非捕获分组前导符、固化分组前导符、预查 (即环视) 分组前导符、嵌入条件分组前导符、内联匹配模式选项前导符、平衡组前导符、注释分组前导符
|
或运算符
\|
^
字符串开始位置、字符组非运算符 (即字符组排除运算符)
\^
在字符组内部,^ 只有紧跟在左方括号“[”之后时才是排除运算元字符,如果想表示“这个字符组中可以出现 ^ 字符”,不要让它紧挨着左方括号即可,如果非要紧挨着左方括号就必须转义。
比如“^[^012]$”匹配“^”,“^[\^012]$”、“^[0^12]$”也匹配“^”,但“^[^0^12]$”则不匹配“^”。
当然,将“^[^0^12]$”写成“^[^0**\^12]$”也是允许的,两者等价,都不匹配“^”;而“^[0^12]$”和“^[0\**^12]$”两者也是等价的,都匹配“^”。
因此,为了减轻记忆负担,凡是要在字符组内部表示“^”字符本身,一律转义也是可以的,这样可读性反而更高,更好理解。
$
字符串结束位置、替换引用前导符
\$ 或 $$
替换时,Java 中使用\$ 进行转义,比如:System.out.println(“the price is 12.99”.replaceAll("\\d+\\.\\d{0,2}", “\\$ $0”));,输出:the price is $12.99;C#中使用 $ $ 进行转义,比如:Console.Write(Regex.Replace(“the price is 12.99”, @"\d+\.\d{0,2}", “$$$0”));,输出:the price is $12.99。
提示:单个元字符的转义与成对元字符的转义:如果需要对单个出现的元字符转义,直接添加反斜线字符转义也是可以的,所以 *、+、?、*?、+?、?? 的转义形式分别是\*、\+、\?、\*\?、\+\?、\?\?。如果需要对成对出现的元字符转义,比如花括号 (即大括号)、方括号 (即中括号),则一般只对左括号转义,比如{abc}和 [abc] 的转义分别是\{abc}和\[abc]。
但对同样是成对出现的圆括号 (即小括号) 的转义与花括号、方括号都不同,圆括号的左括号 (、右括号) 都必须转义。因为圆括号非常重要,所以无论是左括号还是右括号,只要出现,正则表达式就会尝试寻找整个圆括号对,如果只转义了左圆括号而没有转义右圆括号,一般会报告“圆括号不匹配”的错误。
其实,对右花括号}和右方括号] 转义也是可以的,比如\{abc}和\{abc\}等价、\ [abc] 和 \ [abc\] 等价。
因此,为了减轻记忆负担,凡是要在正则表达式中表示括号本身,包括左右圆括号 ()”、左右花括号“{}”、左右方括号“[]”本身,一律转义也是可以的,这样可读性反而更高,更好理解。
** 即便是在字符组中,左右圆括号“()”、左右花括号“{}”、左方括号“[”不是字符组元字符,绝大部分常用语言和工具中,转义与不转义均可(实际上,这是 PCRE流派中的情形,在 POSIX流派的 MySQL、Oracle以及其它 Unix/Linux工具的字符组中是不能转义的,因为这些程序和工具字符组内的反斜线\**属于普通字符,详见后文相关介绍)。
注意:双重转义问题:正则表达式中的“转义”与编程语言字符串中的“转义”在概念上有些类似,而且转义序列前导符也都是反斜杠\,但又不是一回事,完全属于两套不同的系统,两者不能等同。不过,虽然两者属于不同的系统,因此元字符与元转义序列的规定也分属于不同的系统,但在绝大部分语言中这两者却有部分元字符与元转义序列是相同的 (即重叠的)。
在很多语言中,正则表达式既可以用正则字面形式 (正则文字形式、正则直接形式) 来直接书写,比如:
JavaScript 中使用定界符定义的正则表达式字面量 (这里假设定界符为正斜杠 /):/regex/(但如果 /regex/ 位于字符串双引号内:"/regex/",则不属于正则字面形式,仍然属于后面要说到的常规字符串形式,比如 PHP 中用双引号字符串定义的正则表达式即是如此)。
正则表达式也可以使用原义字符串形式 (原生字符串形式、逐字字符串形式、强制不转义字符串形式) 来直接书写,比如:
C#中用 @标注的字符串:@“regex”(除了用两个双引号“""”表示单个双引号“"”之外,其他包括反斜线\在内的所有字符均被看作原义字符本身);
Python2 和 Python3 中用 r 标注的字符串:r’regex’或 r"regex"(包括反斜线\、双引号字符串中的单引号以及单引号字符串中的双引号在内的所有字符均被看作原义字符本身;另,Python 中无论是常规字符串还是原义字符串,单引号字符串中包含单个单引号、双引号字符串中包含单个双引号将导致出错,而单引号字符串中包含的连续两个单引号、双引号字符串中包含的连续两个双引号将被忽略)。
但也有些语言只能使用常规字符串形式 (规则字符串形式、强制转义字符串形式,写作:“regex"或”/regex/") 来间接书写,这种情况下由于正则表达式与字符串都涉及到转义,并且转义符都是反斜杠“\”,而这两者的转义又各自属于独立的系统,因此使用常规字符串形式来间接书写正则表达式就导致了令初学者非常困惑的“双重转义”问题。
比如,某个匹配原始文本“abc.txt C:\temp”的、以常规字符串形式来书写的正则表达式为“"[a-z]+\\.txt\\tC:\\\\temp"”,其中原始文本中的单个反斜杠“\”竟然必须写成四个反斜杠“\\\\”才能匹配,这一点最令初学者“震惊”与迷惑。其实,由于反斜杠“\”属于正则表达式中的元字符,因此原始文本中的单个反斜杠在正则表达式中必须转义为两个反斜杠“\\”:[a-z]+\.txt\tC:\\temp(另外句点. 为正则中的元字符、制表符为不可见字符,所以也都必须转义);而前面强调过,正则表达式中的“转义”与常规字符串中的“转义”完全属于两套各自独立的系统,因此正则表达式中的两个反斜杠“\\”以常规字符串形式来书写的话则必须再次分别转义,于是就变成了四个反斜杠“\\\\”:"[a-z]+\\.txt\\tC:\\\\temp"。
实际上,以常规字符串形式书写的正则表达式经历了两个完全独立的解析过程:1)字符串解析程序将常规字符串解析还原为正则表达式 (准确地说是正则表达式字面形式),然后提供给正则引擎;2)正则引擎再将字面形式的正则表达式解析后予以执行。这就是“双重转义”问题的内在“秘密”。
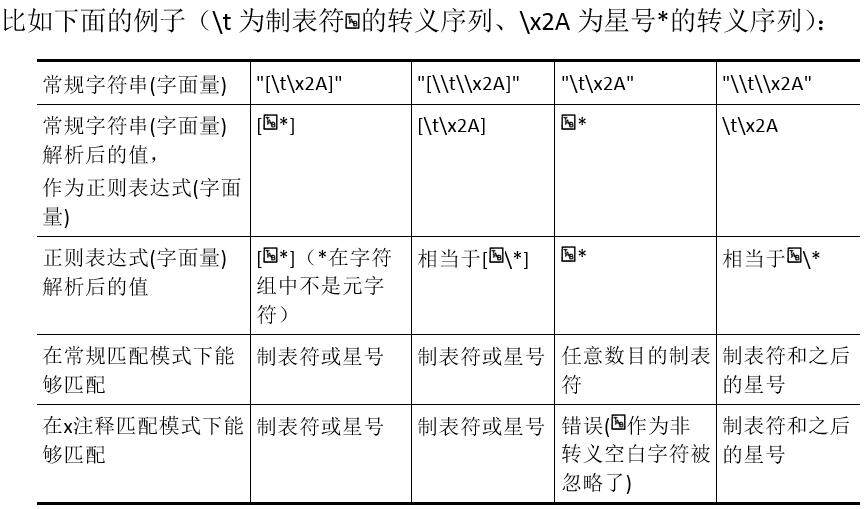
** 注1:** 正则表达式中字符组 (字符集合) 内部与外部关于元字符的规定是不一样的(详见本表后文有关字符组的介绍),星号 * 在字符组内部不属于元字符,在其外部才是元字符;因此,在字符组内部,字符组外部的正则元字符无论是否转义均被看作是字符本身。
** 注2:** 正则表达式字面量中字符组外部的星号 *,被正则引擎看作是元字符,于是解析为匹配任意个制表符;而星号 * 的 ASCII 编码值转义序列\x2A,不会被正则引擎看作是元字符,而是被看作是星号 * 本身,等价于\*,于是解析为匹配 1 个星号 * 本身。
** 注3:** 在 x 注释匹配模式下,正则表达式中未转义的空白字符将被忽略(详见本表后文有关匹配模式的介绍)。
当然,以原义字符串形式书写的正则表达式也需要经历这两个完全独立的解析过程,但原义字符串中的转义符与正则表达式中的转义符不同,比如 C#原义字符串中的转义符为双引号“"”且也只需要对双引号进行转义“""”。因此,以原义字符串形式书写的正则表达式中,不存在由于常规字符串与正则表达式的转义符相同 (都是反斜杠“\”) 而引发“双重转义”问题所导致的困惑,所以这里不予讨论。
注意:如果不想过于深究正则表达式中的转义问题,那就谨记如下原则:
- 书写正则表达式时,如果可以使用正则字面形式或原义字符串形式来直接书写,就应当尽量使用这两种方法之一来书写,因为这样无需双重转义,更为简单直观,方便理解。
- 如果确定必须使用常规字符串形式来间接书写,首先按正则字面形式将正则表达式书写出来,然后再将该字面形式的正则表达式中的每个反斜线 **\** 在常规字符串中都改写为\\,即便\n 和\t 中的反斜线也不例外 (虽然编程语言在进行字符串解析时可以将常规字符串中的\n 和\t 分别正确地识别为换行符和制表符,但写成\\n、\\t 也并不难理解);不要依赖于某些编程语言自身所提供的“将常规字符串中无法识别的转义序列保留下来而不报错”的规定,比如要在正则表达式中使用字符组简记法\d,其在常规字符串形式中要写成\\d,而不是直接写成\d(虽然某些编程语言在进行字符串解析时即使不能识别\d,也不会报错,而是会将\d 原样保留下来直接提供给正则引擎解析,但强烈建议不要依赖这一点),因为这样一致性更好、可读性更高,更容易理解,也就更不容易出错。
参考资料
一)文档
Perl:
Perl regular expressions (perlre)(英文)
Perl Regular Expressions Reference (perlreref)(英文)
Perl Regular Expression Backslash Sequences and Escapes (perlrebackslash)(英文)
Perl Regular Expression Character Classes (perlrecharclass)(英文)
regular-expressions.info: Perl’s Rich Support for Regular Expressions(英文)
PHP:
regular-expressions.info: PHP Provides Three Sets of Regular Expression Functions(英文)
PCRE2:
regular-expressions.info: The PCRE2 Open Source Regex Library(英文)
.Net(C#、VB):
regular-expressions.info: Using Regular Expressions with The Microsoft .NET Framework(英文)
Java:
Regular Expressions Tutorials(正则表达式教程)(英文)
regular-expressions.info: Using Regular Expressions in Java(英文)
JavaScript:
EMCAScript:RegExp (Regular Expression) Objects(英文)
regular-expressions.info: Using Regular Expressions with JavaScript(英文)
Python2.7:
Regular expression operations(英文)
regular-expressions.info: Python’s re Module(英文)
Python3.4:
Regular expression operations(英文)
regular-expressions.info: Python’s re Module(英文)
regular-expressions.info: Using Regular Expressions with Ruby(英文)
Vim:
模式及查找命令 For Vim version 7.4(中文)
Search commands and patterns For Vim version 7.3(英文)
GNU Grep:
regular-expressions.info: GNU Regular Expression Extensions(英文)
GNU Sed:
regular-expressions.info: GNU Regular Expression Extensions(英文)
GNU awk:
regular-expressions.info: GNU Regular Expression Extensions(英文)
二)书籍
《精通正则表达式》英文版及中文版 作者:Jeffrey E·F·Friedl 译者:余晟 电子工业出版社 2012-07
《正则指引》作者:余晟 电子工业出版社 2012-05
《正则表达式必知必会》作者:Ben Forta 译者:杨涛 人民邮电出版社 2015-01
《冒号课堂:编程范式与 OOP 思想》作者:郑晖 电子工业出版社 2009-10
三)其他
本系列文章还参考了网上的大量资料,除了少部分资料由于未作大量修改 (但基本上也有少量修改,因为网上文章随意性较大,很多明显的笔误或前后矛盾之处,如若不改反而让人迷糊) 而标明了原作者和出处之外,其余由于基本上已按自己的理解作了大量改写,因此没有再一一予以说明,在此对原文作者表示歉意并感谢。
另外,文中图片小部分来自网络,大部分为本人制作,也不再一一说明,在此对原图作者表示歉意并感谢。




