一、缘起
计算机世界中有一些非常基础、重要、应用广泛而又特别容易让人困惑的主题,这包括字符编码、字节序 (即大小端表示)、正则表达式以及浮点数实现、日期时间处理等等。其中,字节序、正则表达式跟字符编码的关系非常密切。字符编码以及字节序的问题我已经在另一个系列文章《刨根究底字符编码》中介绍过了,这个系列来讨论正则表达式。
不同于字符编码竟然连一本专著都没有的尴尬,正则表达式目前市面上并不缺乏专业著作,比如那本被誉为正则表达式学习圣经的《精通正则表达式》就很值得一读,另外该书的译者余晟先生所写的《正则指引》也不错;如果仅用于入门,则《正则表达式必知必会》肯定不能错过,还有网上流传极广的《正则表达式30 分钟入门教程》也是不错的入门资料。
但是,结合我自身痛苦的正则表达式学习经历和运用体会,仅有这些是远远不够的。记得被大家称之为“轮子哥”的大神级程序员vczh 在知乎上说过,当初被正则表达式虐得一气之下,干脆自己写了一个正则引擎(源码托管在 Github 上),才算真正彻底搞懂正则表达式 (于是被戏称为“一言不合”就造轮子)。当然不是每个程序员都能如此生猛,但即便都有这么生猛,似乎也没必要都像“轮子哥”这样自己再造一个“轮子”。
那到底应该怎样才能最高性价比地掌握正则表达式这个神器呢?这正是我写这个系列文章的目的。
正则表达式是典型的那种没用过的话,不觉得对自己有什么影响,可是一旦用过了,就再也回不去了的神器。当然,我这里所说的“用过”,不是指简单用用一些基本功能,而是指能够熟练运用其基本功能和高级功能。用得越熟练,就会越惊叹于其强大与神奇。
看到这里,我相信某些学过正则表达式、会使用一些基本功能的童鞋,心里或许在犯嘀咕了:神器是神器,可这玩意儿看起来就像天书一样,也太难学、太难懂了,要达到熟练运用的程度,谈何容易!短短的一个正则表达式,或许不到 10 个字符,其中的每个字符都认识,但连在一起,却越看越迷惑,越想越迷糊……
是的,正则表达式既然被捧上了神器级别的高度,自然是有着相当强大的功能,这当然就意味着其有非常深厚的内涵,也就意味着有很多需要注意的细节。
注意,我这里没有说正则表达式是由于复杂而难以理解,这是因为,深厚的内涵不等于复杂,细节很多不意味着难以理解。看到这里,或许有人有意见了,正则表达式还不算复杂?还不够难理解?你秀智商呢,还是秀优越感呢?哦,相信我,其实这两者我都不太沾边。智商我也只是中等而已,否则早就不在这里码字了;而优越感则更提不上——既不高也不富更不帅,何来优越感?!
其实,我真正想说的是,繁复或许是真的,杂乱倒未必。因此,简单地说正则表达式复杂,似乎不够准确而客观。正如跟一个牛叉而又性格独特(废话,真正牛叉的人基本上都有独特的性格)的人打交道,关键不在于纠结其性格的独特、脾气的古怪,而是重在充分了解并理解其独特的性格、古怪的脾气,然后在此基础上与他 / 她进行良好的沟通,以便能好好发挥其牛叉之处。
学习并熟练掌握正则表达式的过程也是如此——关键在于先要摸透其“性格”到底独特在哪里,其“脾气”又究竟古怪在何方。一旦摸清楚了其“性格”,其“脾气”,学习起来就事半功倍了。
因此,我下面准备从我自己的角度,先尝试着来分析一下正则表达式那独特的“性格”与古怪的“脾气”,看看究竟为什么正则表达式给那么多人的感觉都是那么难以“亲近”。
二、正则表达式为什么难学?
对于正则表达式的分析和解读,目前大多数文章和书籍多集中在正则表达式自身,比如对正则表达式的各个元字符、元转义序列以及匹配原理的分析和解读上。
当然,这些自然也是很有必要的,而且是学习的主要内容,是理解正则表达式所必需的。然而,很多人在看了大量这类文章和书籍之后,仍然觉得正则表达式很难看懂,不好理解,经常有一种智商被碾压的即视感。
难道真的是正则表达式的学习者智商不够吗?其实,理解一个事物,都应该有两个维度,或者说两个层面:
一是,深入到该事物本身里面去理解;
二是,跳出到该事物外面,站在更高的一个维度或层面来理解。
正如苏轼那首著名的哲理诗《题西林壁》所说的,“不识庐山真面目,只缘身在此山中”。很多时候往往是这样,当你只从该事物本身来看的话,就如在云里雾里,是远远不够的;而一旦跳出到该事物之外,站在更高的一个角度来看,则又正如王安石的《登飞来峰》中所说:“不畏浮云遮望眼,只缘身在最高层”。
对正则表达式而言,前者正是目前大多数文章和书籍在做的;而后者,却很少有文章和书籍能够跳出正则表达式,站在更高的维度或层面来分析和解读正则表达式。这里就包括了《精通正则表达式》和《正则指引》两书。
这里需要特别强调一下的是,我绝没有贬低上述这两本专著及其作者和 / 或译者之意,而且恰恰相反,这两本专著正是本系列文章的重要参考书。尤其无论是作为《精通正则表达式》的译者,还是作为《正则指引》的著者,余晟先生都绝对称得上是专业而又严谨的。
那么**,前面所谓 ****“更高的维度或层面”,到底指的是什么呢?那就是,从编程语言发展史以及编程范式的角度来看正则表达式。什么?正则表达式竟然也算得上是一门正式的编程语言吗?别急,请 **继续往下看。
正则表达式有一个非常明显的特点:高度简洁、高度抽象**。正则表达式中短短的 **几个字符,或许就代表了一段复杂的处理逻辑和匹配算法。
我们知道,程序代码是对现实事务处理逻辑的抽象,而正则表达式则是对复杂的字符匹配程序代码的进一步抽象;也就是说,高度简洁的正则表达式,可以认为其背后所对应的是字符匹配程序代码,而字符匹配程序代码,背后对应的是字符匹配处理逻辑。
因此可以这么认为,字符匹配处理逻辑,抽象为字符匹配程序代码;字符匹配程序代码,再进一步抽象为高度简洁的正则表达式。
所以说,高度简洁的正则表达式也是高度抽象的。
事实上,从编程语言发展的角度来看,正则表达式也是一种编程语言,而且是属于第 4 代语言 (4GL)——面向问题语言 (第 1 代语言为机器语言——由 0 和 1 组成的位串,第 2 代语言为汇编语言——用接近于英语单词的助记码 mnemonic code 来代替由 0 和 1 组成的位串,第 3 代语言为高级语言——用接近于自然语言的语法元素编写程序,如 C/C++、Java、C#、Perl、Python、PHP、JavaScript 等语言,第 4 代语言为面向问题语言——用针对问题领域专门设计的语法元素编写程序或表达式,如 SQL、SAS、SPSS、LaTeX、Regex(即正则表达式) 等,第 5 代语言为人工智能语言——Prolog、Mercury、OPS5 等;不过,从第 4 代语言到第 5 代语言的演化还不是很清晰,目前学术界争议较大,这里不作讨论)。
第 4 代语言相对于第 3 代语言,更专注于其所应用或者说其所适用的某个特定的业务逻辑和问题领域。程序员主要负责分析问题,以及使用第 4 代语言来描述问题,而无需花费大量时间去考虑具体的处理逻辑和算法实现 (事实上,最初之所以提出第 4 代语言的概念,就是希望非专业程序员也能做应用开发)。
从编程范式 ****(programming **paradigm)的角度上来讲,第 4 代语言属于声明式编程范式(Declarative p**rogramming paradigm),声明式编程重在目标而非过程、重在描述而非实现,以声明式语句直接描述问题,专注于问题的分析和表达,而非专注于处理逻辑和算法实现过程,其具体的处理逻辑和算法实现是由语言解析引擎 (编译器或解释器) 来负责的。
当然,这样一来,这些由语言解析引擎实现的处理逻辑和具体算法其通用性就会较差,只能适用于某些特定业务或特定领域。也正是这个原因,第 4 代语言基本都是局限于某些特定领域的,多被认为是领域特定语言 DSL(Domain Specific Language)。
区别于算法实现可由程序员自由灵活设计的通用编程语言 GPPL****(General-Purpose Programming Language,作为第3 代语言的高级语言基本上都属于通用编程语言),领域特定语言 ****DSL的算法基本上由语言解析引擎自动实现,程序员灵活设计、自由发挥的空间很小,因此 DSL 几乎没有通用性 (而且 DSL 大都是非图灵完备的语言),只能专用于解决特定业务方向和业务领域的问题。
比如,SQL 是专用于数据库操作的语言、SAS 和 SPSS 是专用于统计分析的语言、LaTeX 是专用于排版的语言,而正则表达式Regex(regular expression) 则是专用于 **** 处理字符匹配的语言。
理解了这一点,就比较容易理解正则表达式是字符匹配处理逻辑的抽象;更进一步地来说,正则表达式中的某些元字符与特殊结构,可理解为某种具体的程序逻辑和算法的体现。
比如,正则表达式中的量词 * 这一元字符,就是高级语言的处理逻辑“循环结构”的体现 (具体来说量词 * 代表的是不定次数循环),而前后多个量词的嵌套就是多层循环的嵌套;或运算符|这一元字符,就是高级语言的处理逻辑“选择结构”的体现。
而当或运算符|出现在由量词 * 所限定的圆括号中时,其实就是在“循环结构”中嵌套了“选择结构”;而如果进一步地,“循环结构”所嵌套的“选择结构”中的某个分支,又被某个量词 * 所限定,那么则相当于“循环结构”所嵌套的“选择结构”又嵌套了“循环结构”。
理解这一点非常重要,是快速**、深入理解正则表达式的一把钥匙、一条捷径。站在编程语言发展史和编程范式的高度,再结合对正则表达式本身原理的深入理解,里外结合,高下相较,既登高望远、一览众山小,又洞幽烛微、复观千水深,正则表达式的奥义,就能尽在掌握之中了 **。
当然,正则表达式之所以难学、难理解,除了由于正则表达式作为一个字符匹配领域的领域特定语言 (DSL),具有高度简洁、高度抽象的特点之外,大致上应该还有以下几个原因:
1) 学习者不求甚解,不了解正则引擎内部的基本 **** 原理
作为正则表达式的使用者,不需要深入了解正则引擎内部原理的技术实现细节,那是正则引擎开发者更应该了解的;但若完全不了解其基本工作原理和运行机制,也是不足取的。
2) ** 有多个多义元字符,特别容易使人混淆、**迷乱
比如 -、+、?、^,尤其是元字符?,既可以作为量词表示其所限定的子表达式为可选 (即匹配 0 次或 1 次),也可以置于量词之后表示懒惰匹配,而且还有很多特殊分组结构中用到它,比如 (?
3) 转义 **** 也是难点
什么情况下需要转义,什么情况下不需要转义,貌似复杂得令人抓狂;当然,其实是有一定的规律的,掌握了这些规律,再遇到转义问题,就不至于心潮澎湃了。
4) 学习期望与学习方法 **** 不对
不应该期望一次性记住、学会并熟练运用,正确的学习姿势应该是:先简单入门,对一些基本的规则与元字符大致了解一遍,有个印象就好,在需要时再回过头来看,不用刻意去强行记忆;然后接下来就应该多练、多实践、多运用,边学、边深入、边熟练。
5) 有用于入门的好教程、备忘单,也有用于深入的大部头专著**,但却缺乏好的速查手册 **
由于需要边学、边深入、边熟练,因此,平时手头边更需要的不是简单的入门教程、备忘单 (Cheat Sheet),也不仅仅是知识点分散于各处的大部头专著 (知识点分散导致查找起来不方便,用于深入学习原理是不错,但不够实用),而是一本按语法元素将知识点综合在一起进行编排的、在需要回过头来看时能够随时快速翻查的速查手册。这样,在实践运用中遇到问题就可方便随时快速翻查,而这一点恰恰对于正则表达式这种不可能短期内快速掌握并熟练运用的专业工具的学习与使用非常重要。
6) 没有使用好的学习 **** 工具
你知道 regex101.com、RegexBuddy、regexper.com 等正则表达式的专业网站和专业工具吗?这些堪称学习正则表达式的神器,可令学习事半功倍,但很多人不知道,或知道但很少使用。
(点击放大图像)

正则表达式可视化工具(regexper.com)
三、正则表达式概念
一)先从“通配符”说起
对于初学者而言,正则表达式,仅从字面上来说不太好理解。但实际上,您可能早已经使用过了某些正则表达式的功能,只是自己还没有意识到而已。

因此,所谓“通配符”,即“通用匹配字符”,就是用某个通用字符按事先所规定的规则来查找匹配某些常规字符,从而实现“以一对多”(或“以一代多”)、“以简对繁”(或“以简代繁”) 地简化、抽象化、通用化用来进行查找匹配的表达式的目的。
然而,尽管使用“通配符”的匹配查找方法很有用,但它的功能还是非常有限的。和通配符类似,正则表达式也是用来进行文本匹配查找的工具。只不过相比通配符而言,正则表达式更为抽象化、通用化,功能也更为强大、更加灵活,能够更为精确地表达匹配条件(即匹配规则),当然也就更复杂,更难以学习和掌握。
二)正则表达式概念
正则表达式,又称正规表示法、常规表示法(Regular Expression,在代码中常简写为regex、regexp 或RE),计算机科学的一个概念。
正则表达式是一种字符串的匹配模式,描述的是某一类字符串的共同特征。
所谓模式,就是模板样式或模具样式。正如符合某种样式的模板或模具,可以用来生产符合这种样式的同一类产品一样;反过来,也可以用某种样式的模板或模具,来检验或框定哪些产品才是符合这种样式的同一类产品。
正则表达式正是类似于这样的模板或模具,用来检验或框定哪些字符串是符合正则表达式所描述的字符串共同特征的同一类字符串;而这个检验或框定的过程,就称之为匹配。
我们平时所使用的自然语言中,可以用“漂亮”、“坚固”、“挺拔”等高度抽象性词语来描述事物的共同特征一样,一个正则表达式正是某一类字符串的高度抽象,用来描述这类字符串的共同特征。也就是说,一个正则表达式代表了某类字符串的一个集合,而正则表达式相当于对该字符串集合的特征性质描述。(注:集合的常用表示方法有元素列举法、特征性质描述法和图示法。)
正则表达式还可看作是对字符串操作的一种逻辑公式,其构造方法和创建数学表达式的方法差不多,也就是用普通字符(如字母a 到z、数字0 到9 等) 和事先定义好的一些特定字符(专业术语称之为元字符),以及这些字符的组合,组成一个特定的规则字符串。而所谓特定的规则 **,即是正则 ****;因此特定的规则字符串,即是正则表达式。**
这些“特定的规则”,从被匹配的字符串的角度上来看,可以认为描述的是某一类字符串的共同特征;而从正则表达式的角度上来看**,也可以认为表达的是一种匹配规则 ****(或称过滤逻辑)。**
因此,正则表达式是一种特殊的字符串(即正则表达式字符串,往往直接简称为正则表达式或正则式),用来描述、匹配、过滤符合某些特征的其它字符串 (即输入字符串、源字符串、被测试的字符串、被匹配的字符串,往往直接简称为字符串)。
说某个正则表达式匹配某个字符串,通常是指这个字符串的全部或一部分或几部分分别符合或者说满足正则表达式所描述的字符串特征;也可以说是指这个字符串的全部或一部分或几部分分别符合或者说满足正则表达式所规定的匹配条件或匹配规则。
而从正则表达式作为一种编程语言的角度上来看,正则表达式的基本语法结构与一般高级编程语言差不多,主要就是顺序**(即连接)、选择(即分支)、循环 (即重复)** 三种,其他都是这三者的组合,再加上一些语法糖。
再更进一步地,从正则表达式作为一个声明式编程范式的领域特定语言 DSL的角度来讲,正则表达式的顺序、选择、循环这三种基本语法结构是非常简洁、紧凑的 (这几乎是声明范式 DSL 的基本特点,而正则表达式将这一点体现得尤为淋漓尽致)。其中,连接无需通过元字符表示,选择通过元字符“|”表示,而循环则通过元字符“*”、“+”或“{n,m}”表示。这三种基本语法结构在使用时,直接进行声明式描述即可,无需通过复杂的语句来进行算法设计。
事实上,还可从 ** 编程语言操作符(即运算符)** 的角度来理解,其中,“*”、“+”或“{n,m}”是单目后缀操作符,“|”是双目中缀操作符,连接其实也是双目中缀操作符,不过是隐含的 (即隐式的,因为连接是三种基本语法结构中最常用的,所以设计为隐式操作符最为合理)。
四、正则表达式功能
一般而言,典型的简单搜索和替换操作,可通过直接提供与预期的搜索结果相匹配的字面文本来实现。虽然这种方法对于文本执行简单的、静态的搜索和替换任务可能已经足够了,然而却缺乏足够的灵活性和动态性。
若通过使用正则表达式,则可以:
- 查找 **** 文本
- 提取 **** 文本
- 验证文本
- 替换文本
- 切分文本
显然,通过使用文本模式,正则表达式相比较于直接使用固定的、明确的字面文本进行简单的、静态的搜索和替换,更为灵活,也更具有动态适应性。而且,正则表达式同样也可以使用字面文本进行简单的、静态的搜索和替换(当然,这有点大材小用了,效率也比直接搜索和替换更低,因此,字面文本的直接搜索和替换,不推荐使用正则表达式)。
因此,正则表达式的熟练运用,是文本处理人员,尤其是编程人员的必备技能。其强大的功能、快捷的速度,一旦掌握,你将会既叹服于心,又享受其中。
五、正则表达式简史
正则表达式的“祖先”可以一直追溯至对人类神经系统如何工作的早期研究。Warren McCulloch 和 Walter Pitts 这两位神经生理学家在 20 世纪 40 年代研究出用一种数学方式来描述神经网络。
1956 年,一位叫 Stephen Kleene 的数学家在 McCulloch 和 Pitts 早期工作的基础上,发表了一篇标题为《神经网络事件表示法和有穷自动机 ( Representation of events in nerve nets and finite automata )》的论文,引入了正则表达式的概念。正则表达式就是用来描述他称为“正则集合 Regular Sets”的表达式,这就是“正则表达式”这个术语的来源。
随后,大名鼎鼎的 Unix 之父——Ken Thompson 于 1968 年发表了文章《正则表达式搜索算法 ( Regular Expression Search Algorithm )》,并且将正则表达式这一符号系统引入了他自己开发的编辑器 qed 以及之后的编辑器 ed 中,然后又被移植到了大名鼎鼎的文本搜索工具 grep 中。自此,正则表达式被广泛应用到各种 Unix 系统或类 Unix 系统 (如 Mac 系统、Linux 系统) 的工具中。
由于正则表达式异常强大而实用的功能,越来越多的语言和工具引入了正则表达式。不过遗憾的是,始终没有确立正则表达式方面的标准,导致各语言与工具中的正则表达式虽然功能上大体类似,但细微差别仍然不少。于是,诞生于 1986 年的 POSIX 开始进行标准化的尝试。
POSIX,是 Portable Operating System Interface for uniX(可移植 Unix 操作系统接口) 的缩写。 POSIX 是一系列规范,定义了 Unix 操作系统应当支持的功能,其中也包括正则表达式的规范。
因此,Unix 系统或类 Unix 系统上的大部分工具,如 grep、sed、awk 等,均遵循该标准。遵循 POSIX 正则表达式规范的这些语言和工具中的正则引擎,往往习惯将它们称之为 POSIX 流派的正则引擎。
之后,1988 年 6 月,Larry Wall 开发的 Perl 语言发布第 2 版,其中所引入的正则表达式引擎大放异彩。Perl 2 的正则表达式引擎源于 Henry Spencer 编写的 regex 的增强版。之后不断改进,影响越来越大。于是在此基础上,1997 年又诞生了 pcre ——Perl 兼容正则表达式 (Perl Compatible Regular Expressions)。
PCRE 是一个由 Philip Hazel 开发的、为很多现代语言和工具所普遍使用的 Perl 正则表达式兼容引擎,现已成为除了 Unix 上的工具所遵循的 POSIX 标准之外的其他大部分语言和工具所隐然遵循的另一个事实上的标准。因此,往往习惯将这些 Perl 正则表达式兼容引擎称之为 PCRE 流派的正则引擎。
POSIX 流派与 PCRE 流派是目前正则表达式引擎流派中的两大最主要的流派。
之后,正则表达式在各种计算机语言或各种应用领域进一步得到了更为广泛而普遍的应用和发展。
六、正则表达式流派
如前所述,目前正则表达式主要有两大流派 (Flavor):POSIX 流派与 PCRE 流派。
1)POSIX(Portable Operating System Interface for uniX) 流派
POSIX 是一系列规范,定义了 UNIX 操作系统应当支持的功能,其中也包括正则表达式的规范。POSIX 规范的正则表达式流派是 PCRE 之外的另一大流派。
POSIX 规范定义了正则表达式的 BRE(Basic Regular Expression 基本正则表达式)和 ERE(Extended Regular Express 扩展正则表达式)两种标准。早期,BRE 与 ERE 的区别主要在于:
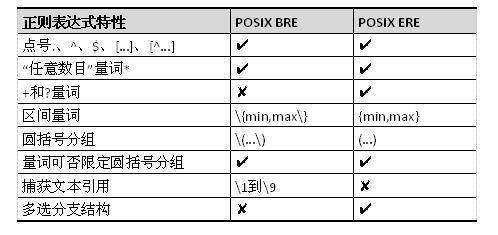
不过,后来随着 BRE 与 ERE 逐渐相互融合,现在的 BRE 和 ERE(包括 GNU 改进的 GNU BRE 和 GNU ERE)在功能特性上并没有太大区别,主要的差异是在元字符的转义上。
在遵循 POSIX 规范的 UNIX/LINUX 系统上,vi/vim、grep 和 sed 遵循 POSIX 规范的 BRE 标准,egrep、awk 则遵循 ERE 标准。这些 UNIX/LINUX 系统常用工具的正则表示法与 PCRE 对比如下:
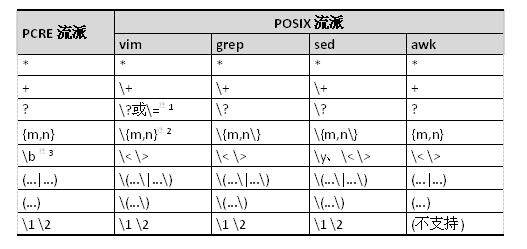
注 1:vim 中的\? 和\= 都表示匹配 0 或 1 个前面的子表达式,但\? 不能在反向查找的“?”命令中使用。
注 2:vim 中的右花括号}之前可以不加反斜杠,也可以加反斜杠,比如:\{n,m\}。
注 3:PCRE 中常用\b 来表示“单词的起始或结束位置”,但 Linux/Unix 的工具中,通常用\< 来匹配“单词的起始位置”,用\> 来匹配“单词的结束位置”,而 sed 中的\y 则与 PCRE 中的\b 一样,可同时匹配这两个位置。
2)PCRE(Perl Compatible Regular Expression) 流派
目前大部分常用编程语言中常见的正则表达式语法,其实都源于 Perl。其中,PCRE 就是从 Perl 衍生出来的最为著名的一个流派,\d、\w、\s 之类的字符组简记法,是这个流派的显著特征。
不过,虽然 PCRE 流派是从 Perl 语言中衍生出来的,但与 Perl 语言的正则表达式还是有一些细微差异的,比如 PHP 的 preg(Perl Regular Expression)与 Perl 的差异可看这里。
(注: PHP 支持两种不同的正则引擎:ereg 与 preg,ereg 全称为 Extended Regular Expression,属于 POSIX ERE;ereg 由于功能方面的不足,已经逐渐被 preg 替代了,ereg 将在未来被废弃。因此,若非特别说明,后文中当提到 PHP 正则引擎时,默认指的是 PHP preg 正则引擎。)
考虑到目前绝大部分常用编程语言所采用的正则引擎基本属于 PCRE 流派,因此,本系列文章将以 PCRE 流派为主、以 POSIX 流派为辅进行介绍;文中有关各语法元素的解释,若非特别说明,均以 PCRE 流派为准。
另外,如前所述,当我们在介绍正则表达式的流派时,与 Perl 正则规范相兼容 (包括直接兼容与间接兼容) 的流派习惯用 PCRE 来称呼。
而本系列文章在介绍与Perl 正则规范直接兼容(但除Perl 外并非完全兼容) 的语言或正则库或工具程序,比如Perl、PHP preg、PCRE 库时,一般称之为Perl 系;与之对应的还有间接兼容的Java 系(包括Java、Groovy、Scala 等)、.Net 系(包括C#、VB.Net)、Python 系(包括Python2 和Python3)、JavaScript 系(包括原生JavaScript 和扩展库XRegExp) 等等。
也就是说,Perl 系、Java 系、.Net 系、Python 系、JavaScript 系(另外还有Ruby、C++Builder、Delphi 等) 均属于PCRE 流派,但与Perl 的兼容性(即兼容程度) 各有不同。其中,Perl 系兼容性最好,虽然PHP preg 与PRCE 库并非与Perl 完全兼容,但基本兼容,因此属于直接兼容;而其他语言或工具相对Perl 系而言,与Perl 的兼容性较差,则属于间接兼容。
七、本系列文章的体例及后续内容
本系列文章出自于我自己在学习正则表达式的过程中所经历过的真切体会和真实痛点。因此,正如前面所述,采取的编排风格会类似于速查手册。不过,与一般的仅供入门使用的字典式简易手册不同,这将会是一本更为深入的专业级速查手册。这也正是文章名称中特别强调“刨根究底”,而不是直接名之为速查手册、快速参考之类的原因。
本系列文章当然会涉及到正则引擎内部的相关匹配原理与匹配机制的解释(而且还独创性地总结为了八大原则,便于“以简驭繁”、“提纲挈领”地快速掌握要领以便于记忆和理解),只是与其他专著用专门章节进行介绍不同,而是各自糅合于对相关语法元素的解释之中了。
这种为了便于快速翻查而没有将匹配原理与匹配机制予以专章介绍的特殊编排,自然也有其缺点(比如,你可能会在不同的语法元素中发现类似的雷同解释,这或许有重复啰嗦之嫌,但毕竟这符合我们的编排目的),但问题在于市面上进行专章介绍的专著已经有很多了,再重复它们意义不大;而专门针对前述的正则表达式学习和运用痛点的文章和专著则基本没有,而这正是本系列文章的意义和目的所在。
也因此,出于更偏向于实践运用的目的,本系列文章不会花费过多的笔墨在DFA、NFA 等过于深入的正则表达式幕后技术细节的讲解上。事实上,我认为只要大致了解它们的基本原理与工作机制以及两者之间在功能特性上的差异,就完全可以熟练掌握并运用正则表达式了,除非你是想自己开发一个正则引擎,实在没必要陷入DFA、NFA 等的技术实现细节中。
我相信通过反复阅读本系列文章,再多加练习、勤于实践,然后在实际运用时再不断回过头来随时翻看,应该完全可以熟练掌握这个像毒品一样会让人上瘾的神器。
最后,再说一下本系列文章后续将会涉及到的内容:首先会大致简单介绍一下正则表达式语法基础,接下来对元字符、元转义序列、特殊构造(特殊结构) 等正则表达式的语法元素进行逐个详解;之后,再讲解一下匹配模式、POSIX 字符组方括号表达式以及字符组运算;最后是正则表达式各语法元素优先级介绍。
参考资料
一) 官方文档
Perl:
- Perl regular expressions (perlre)(英文)
- Perl Regular Expressions Reference (perlreref)(英文)
- Perl Regular Expression Backslash Sequences and Escapes (perlrebackslash)(英文)
- Perl Regular Expression Character Classes (perlrecharclass)(英文)
PCRE:
PHP:
.Net(C#、VB):
Java:
JavaScript:
Python2.7:
Python3.4:
Vim:
GNU Grep:
GNU Sed:
GNU awk:
二) 书籍
- 《精通正则表达式》英文版及中文版 作者:Jeffrey E·F·Friedl 译者:余晟 电子工业出版社 2012-07
- 《正则指引》作者:余晟 电子工业出版社 2012-05
- 《正则表达式必知必会》作者:Ben Forta 译者:杨涛 人民邮电出版社 2015-01
- 《冒号课堂:编程范式与 OOP 思想》作者:郑晖 电子工业出版社 2009-10
三) 其他
本系列文章还参考了网上的大量资料,除了少部分资料由于未作大量修改 (但基本上也有少量修改,因为网上文章随意性较大,很多明显的笔误或前后矛盾之处,如若不改反而让人迷糊) 而标明了原作者和出处之外,其余由于基本上已按自己的理解作了大量改写,因此没有再一一予以说明,在此对原文作者表示歉意并感谢。
另外,文中图片小部分来自网络,大部分为本人制作,也不再一一说明,在此对原图作者表示歉意并感谢。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




