
“前些天,AWS re:Invent 会议上发布了 S3 Table Bucket 新能力,支持创建兼容 Iceberg 的数据表,这也意味着,在数据分析场景,Lakehouse 就是新的 S3。”日前,镜舟科技 CTO 兼 StarRocks TSC Member 张友东在 STARROCKS SUMMIT ASIA 2024 峰会的演讲中如此形容 Lakehouse 的发展趋势,并将其比喻为数据分析领域“新的 S3”。
简单理解张友东的这番话,S3 协议在对象存储行业事实上已经成为标准,而 S3 Table Bucket 的推出,表明 S3 已经在主动拥抱 Lakehouse 架构,也就是说,Lakehouse 架构会逐步成为数据分析领域的架构标准。
在这场题为《Lakehouse is ALL you need》的演讲中,张友东不仅阐述了 Lakehouse 架构如何为企业释放数据价值,也分享了 StarRocks 在这一领域的技术演进和相关行业实践。
针对传统企业数据平台存在的“数据孤岛”问题,张友东在接受 InfoQ 采访时进一步指出,“传统企业里数据平台往往是以业务为导向构建的。企业常常为 A 业务搭建 A 平台,为 B 业务搭建 B 平台,这种分散的结构虽然满足了单一业务需求,但难以支持跨场景的创新,尤其是 AI 相关应用场景。”
Lakehouse 架构为这一问题提供了新出路,其核心理念是让数据具有多样性和开放性。同一份数据既可以用于 BI 的报表分析和运营分析,也可以用于 AI 模型的训练和推理,与大模型结合实现数据价值的最大化。
2025 年 4 月 10 日-4 月 12 日,QCon全球软件开发大会将在北京举办。本次大会特别策划了《Lakehouse 架构演进》专题,聚焦 Lakehouse 架构的最新演进,重点解读 Lakehouse 在实时化分析、非结构化数据处理、以及统一元数据管理等关键领域的变革,为企业高效整合多种数据源、实现智能决策提供前沿洞察。
传统数据架构不够用了
StarRocks 历经三年的发展,已经明确了下一步的演进目标——全面推动 Lakehouse 架构的普及和发展,让数据分析变得普惠、高效。
在演讲中,张友东回顾了数据分析架构的演进历程。从 1980 年代的数据仓库到 2010 年代的数据湖,数据分析的架构不断随着业务需求和数据规模的变化而演进。传统的数据仓库虽然具备高数据质量和事务处理能力,但面对日益复杂的半结构化和非结构化数据,以及海量数据的存储成本问题,逐渐显现出局限性。为解决这些问题,数据湖应运而生。数据湖通过开放的数据格式和统一存储能力,解决了数据类型多样化和存储扩展性的挑战。然而,数据湖也存在数据治理难度大、直接查询性能低等不足,怎么去发挥价值还是个比较大的挑战。
为弥补数据仓库和数据湖的各自不足,业界提出了数据湖与数据仓库分层组合的解决方案。然而,这种模式依然存在冗余数据存储、复杂 ETL 链路以及数据口径不一致等问题。
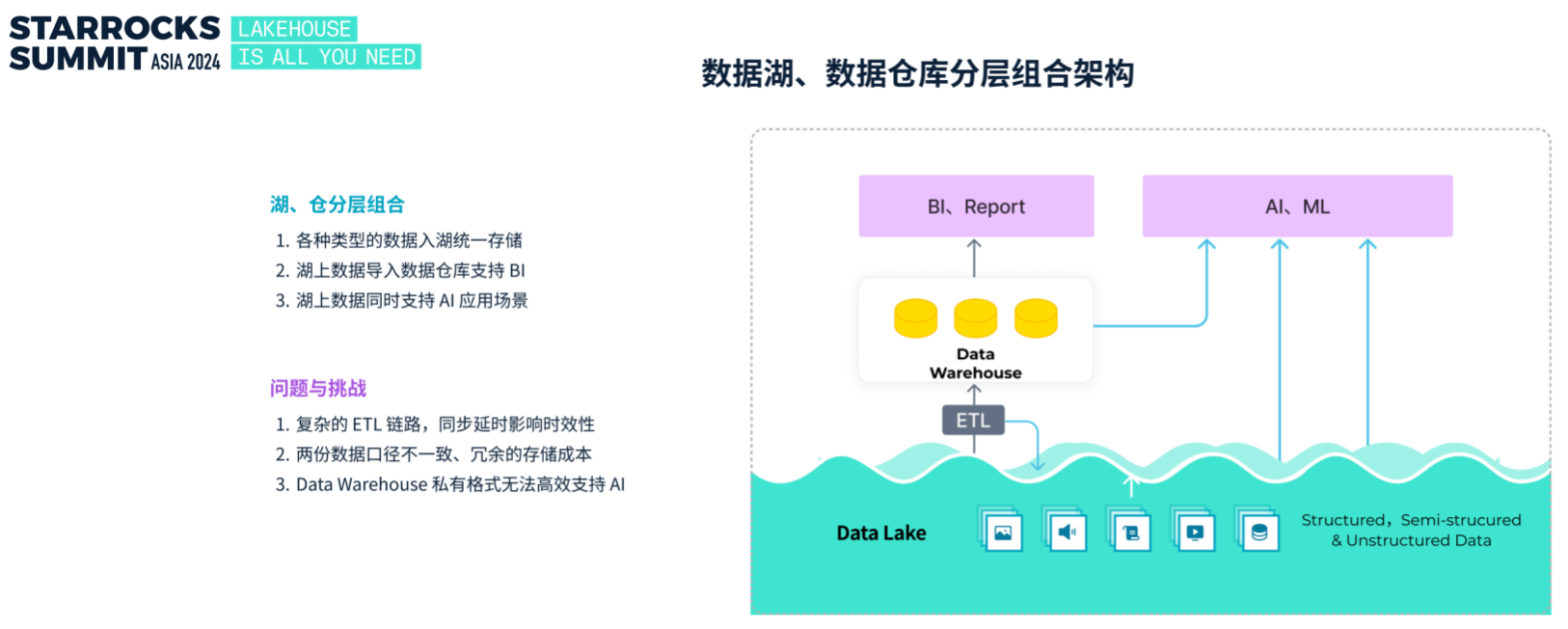
正是在这样的背景下,业界近年来加速数据仓库和数据湖的融合。
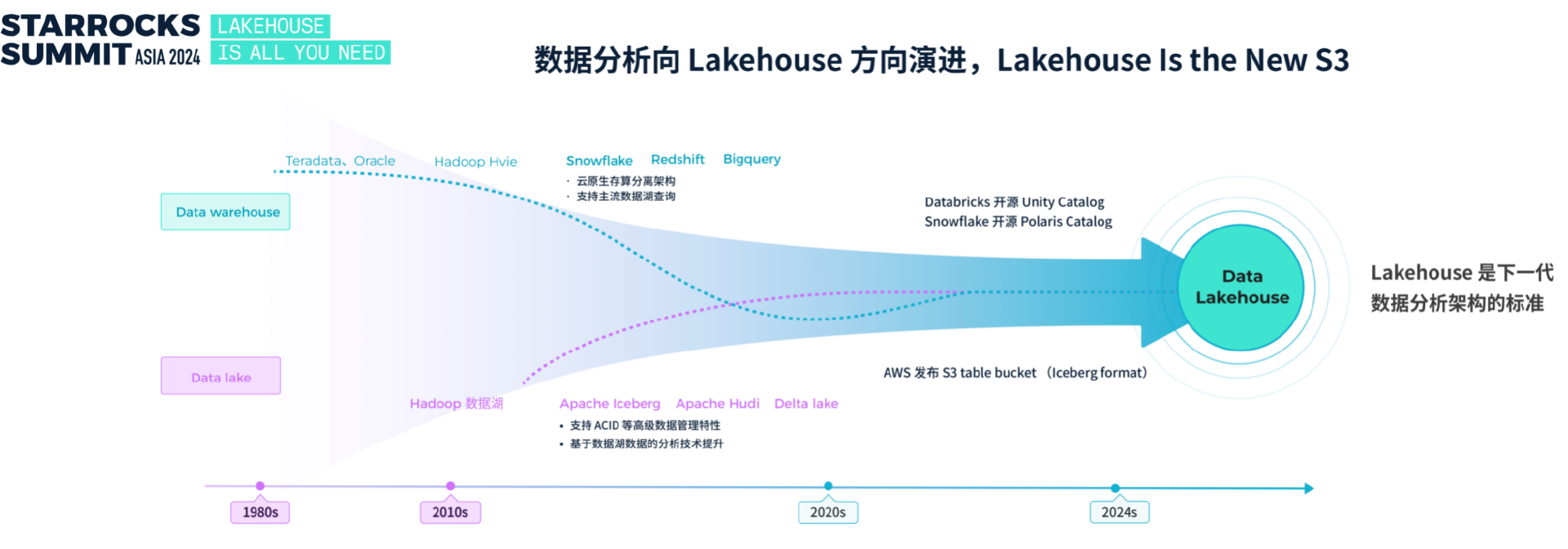
今年 6 月,两家全球领先的数据分析厂商 Snowflake 和 Databricks 相继在 Lakehouse 架构上有重大动作。Databricks 收购了 Tabular 并开源了 Unity Catalog,而 Snowflake 则开源了 Polaris Catalog。这些迹象表明,Lakehouse 正在逐步成为下一代数据分析架构演进的标准。
“Lakehouse 的理念不仅是数据湖和数据仓的融合,”张友东表示,它是一种新的架构范式。类似于 iPhone 的诞生,不是手机、电脑和浏览器的简单组合,而是重新定义了用户交互和功能整合的方式。”
头部大厂相继选择 Lakehouse
构建 Lakehouse 的关键在于存储、Catalog 和计算引擎三大要素。首先,存储层需要基于低成本的对象存储,并使用 Iceberg 或 Paimon 等开放数据格式实现统一管理。其次,Catalog 将数据湖中的数据以统一目录的形式对外提供,支持一致的数据访问和治理。最后,通过高效的计算引擎(如 StarRocks)进行分析和查询,是释放数据价值的核心。
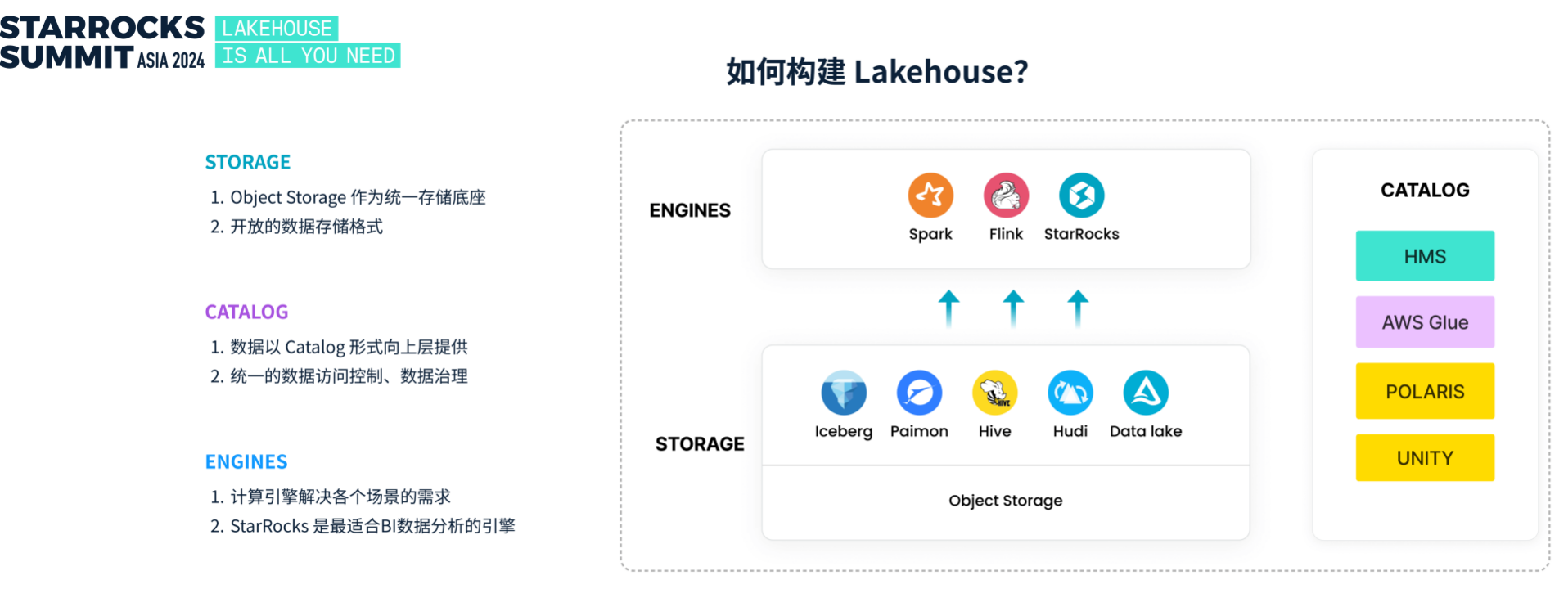
作为 Lakehouse 生态的重要组成部分,StarRocks 已经在多个行业和领域实现了落地应用。
张友东分享了一些标志性案例,展示了 Lakehouse 在不同场景中的价值。比如,StarRocks+Iceberg 的方案已在小红书和微信等企业落地。小红书通过这一架构,存储成本降低 50%,查询性能提升 3 倍;微信的数据时效从小时级缩短到分钟级,存储成本减少 65%。此外,阿里巴巴饿了么采用 Flink+Paimon+StarRocks 的组合,在数据时效、查询性能和存储成本上都实现了显著提升。
不过,张友东亦提到,目前 Lakehouse 的理念主要集中在头部企业中,而更下沉的企业群体对这个概念的认知还不够普及。因此,StarRocks 希望通过技术布道可以让更多企业了解 Lakehouse 架构的重要性。
StarRocks 的一小步,行业的一大步
StarRocks 的快速迭代和技术演进,也为 Lakehouse 架构的发展提供了坚实的基础。张友东分享了过去一年 StarRocks 的关键技术进展:
存算分离:StarRocks 自 2023 年 4 月发布存算分离特性以来,持续优化其功能与性能。在功能方面,基于对象存储的主键索引使得存算分离架构能够支持列式存储的实时更新,同时核心功能也已与存算一体方案完全对齐。在性能方面,热数据查询的表现与存算一体架构一致,而完全冷数据查询性能在多种测试集下达到了存算一体的三分之一。在腾讯音乐和得物等企业的实践中,存算分离方案帮助企业降低了 40%-50% 的资源成本。
实时数据分析:针对实时高并发写入场景,StarRocks 优化了主键模型的数据索引策略,并推出了 Merge Commit 能力,将多个小事务合并为大事务提交,从而减少了事务数量和小文件数量。在某国际网络设备厂商的场景中,StarRocks 成功支持了 300 张表 x 每张表每秒 300 并发写入的实时高并发场景。
半结构化数据支持:随着半结构化数据需求的增长,StarRocks 推出了 Flat JSON 功能,使数据导入和查询更加灵活高效。在 SSB-100g 测试中,与传统 JSON 存储方式相比,Flat JSON 性能提升数十倍,接近原始列存储的性能,为半结构化数据分析场景提供了理想解决方案。
向量检索 :在大模型应用场景中,StarRocks 引入了向量检索功能,为企业内部知识库提供高效检索能力。目前已支持 IVF-PQ 和 HNSW 等主流索引类型。在腾讯的混元文生图项目中,这一方案相比之前多系统组合的方案将检索延时从 15 秒缩短至 2 秒,同时资源成本降低了 70%。
物化视图:在过去一年中,StarRocks 深化了对物化视图的支持,特别是在数据湖场景,支持在 Hive、Iceberg 和 Paimon 等开放数据湖的加速查询。此外,StarRocks 增强包括 Aggregation、Join 和 Union 的智能改写功能,并扩展了基于视图、文本的查询改写能力,进一步简化了用户基于物化视图建模过程。

尽管大模型热潮让数据技术的关注度被 AI 应用抢去了风头,张友东强调,数据技术的重要性从未下降。“现代化的数据基础设施是 AI 落地的前提,高效的数据架构可以显著降低 AI 应用的 TCO(总体拥有成本)。”他进一步表示,Lakehouse 正是为了解决这些问题而诞生,未来企业需要在提升数据治理能力和实时处理能力方面加大投入,这正是 StarRocks 和 Lakehouse 的机会所在。
发展至今,StarRocks 早已不仅仅是一个数据库,而是迈向了更大的湖仓生态体系。张友东认为,国内的类似产品也会沿着这一方向演进和迭代,否则很快会被市场淘汰。




