
在过去的 5 个月里,我与 50 多家公司讨论了他们的授权系统。其中超过一半的公司以某种形式使用微服务,我对它们带来的授权挑战非常感兴趣。在面向服务的后端进行授权这一问题上,似乎没有公认的最佳实践。我与很多团队进行了交谈,有的团队将用户角色附加到身份验证令牌上,有的将所有内容存储在专门用于授权的图数据库中,还有的团队在 Kubernetes 边车(sidecars)中自动执行授权检查。这些解决方案中都沉淀了数月或数年的工程工作,每个团队都发明了自己的轮子。这是为什么?
当你有一个单体应用时,你通常只需要访问一个数据库来决定是否允许用户做某些事情。单体应用的授权策略本身不需要太关心在哪里找到数据(比如用户角色)——你可以假设所有数据都可用,如果需要加载额外数据,它也可以很容易地从单体应用数据库中获取。
但是这个问题在分布式架构中变得困难了许多。也许你正在将单体应用拆分为多个微服务,或者你正在开发一个新的计算密集型的服务,在运行作业之前需要检查用户权限。现在,决定谁可以做什么的数据可能不那么容易获取。你需要新的 api,以便你的服务能够相互谈论权限:“谁是这个组织的管理员?谁可以编辑这个文档?他们可以编辑哪些文档?”为了在服务 A 中做出决策,我们需要服务 B 中的数据,服务 A 的开发人员如何请求这些数据?服务 B 的开发人员如何使这些数据可用?
这些问题有很多答案,所以我试图将这些答案归纳为几个广泛的模式。这些模式不一定能覆盖所有解决方案(解决方案的世界很复杂),但我发现它们能帮助我与不同的人谈论他们所构建的东西。当我与一个新团队进行对话时,它们让我更容易对解决方案进行分类。
在构建微服务时,我看到了处理授权数据的三种主要模式。我将在这篇文章中讨论这三种方法:
将数据留在原处,让服务直接请求它。
使用网关将数据附加到所有请求,以使其随处可用。
将授权数据集中到一个地方,并将所有决策转移到那个地方。
为什么微服务中的授权更困难?
让我们以某个授权场景为例,这是一个用于编辑文档的应用程序。它很简单,但应该能说明问题:
有用户、组织和文档。
用户在组织中拥有角色,包括成员和管理员。
文档属于组织。
如果用户在组织中的角色为成员,则可以阅读文档。
如果用户在组织中的角色为管理员,则可以阅读或编辑文档。
在一个单体应用中,用一种清晰的方式表达这种逻辑并不太难。当你需要检查用户是否可以阅读文档时,你可以检查该文档属于哪个组织,加载该组织中用户的角色,并检查该角色是成员还是管理员。这些检查可能需要额外的一两行 SQL 语句,但数据都在一个地方。
当你将应用程序拆分为不同的服务时,会发生什么情况?也许你已经剥离了一个新的“文档服务”——现在,检查特定文档的读权限需要检查位于该服务数据库之外的用户角色。文档服务如何访问它所需要的角色数据?
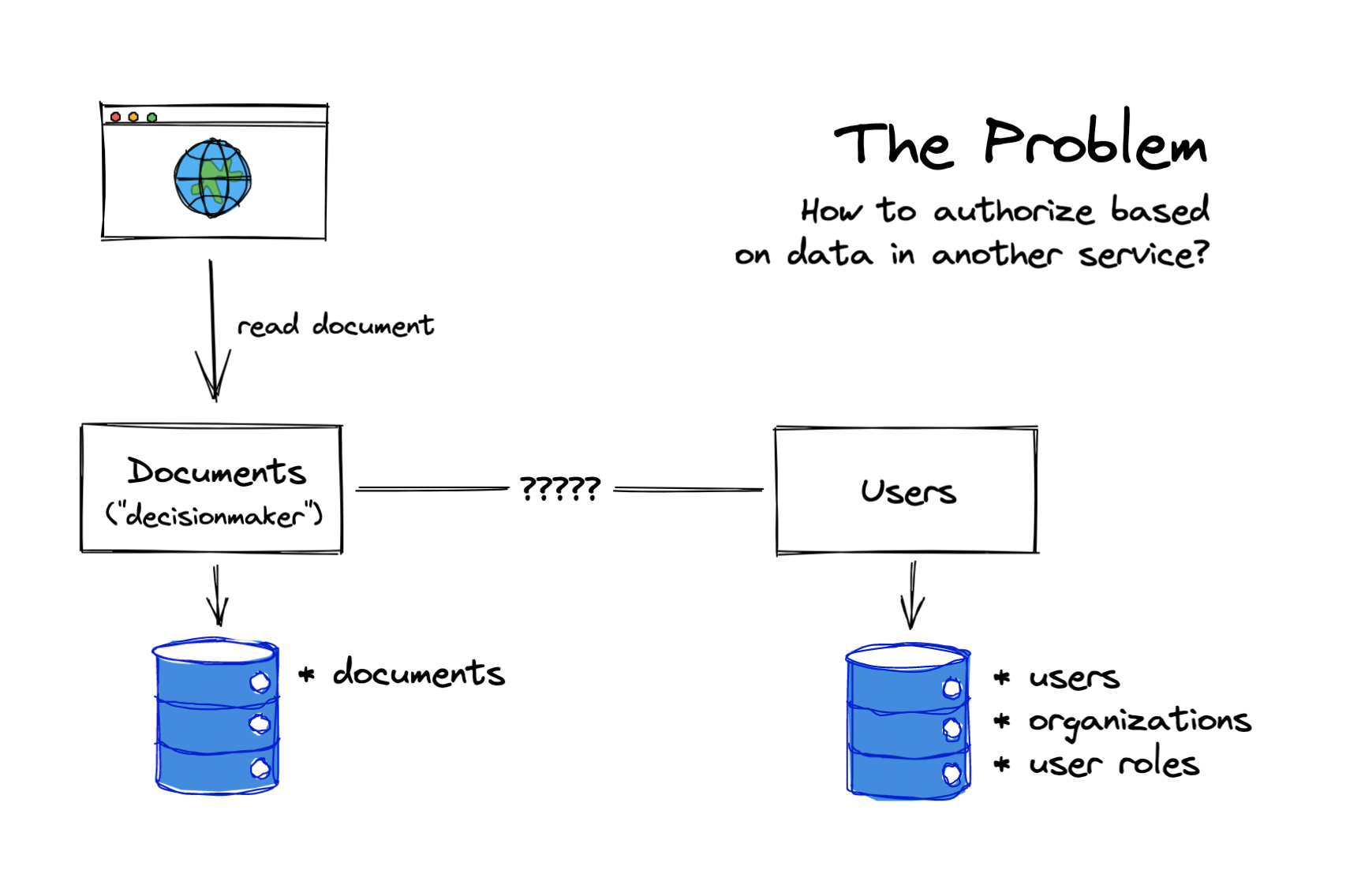
模式 1:将数据留在原处
通常,最简单的解决方案是将数据留在原处,并让服务在需要时请求它所需要的数据。对于上述问题,你可能认为这是最明显的解决方案。
你可以将数据模型和逻辑分开,这样文档服务就可以控制向哪个角色授予哪些文档相关的权限(管理员可以编辑,成员可以读取,等等),然后用户服务公开一个 API 来获取组织中用户的角色。有了这个 API,权限检查可以像这样进行:
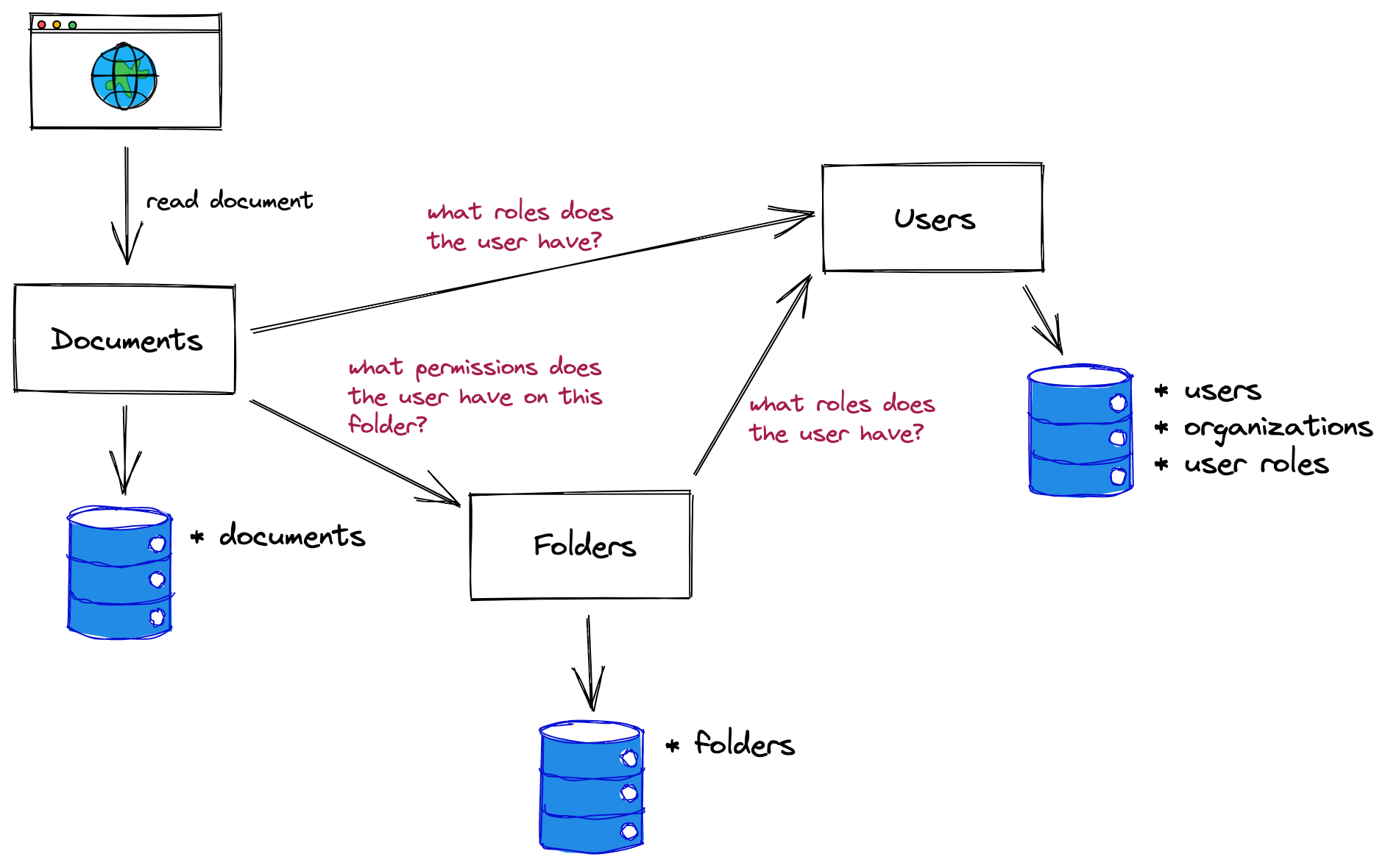
尽管有变得混乱的风险,但这种模式可以让你走得很远。无需部署和维护额外的授权基础设施可能是一个巨大的优势,如果具有数据的服务能够处理来自需要数据的服务的负载,那么将它们串在一起就是一个很好的解决方案。
有一些团队遵循这种通用模式,但他们认为应该用某种专门的授权服务替换所有这些请求流,我和这些团队有过交谈。我总是问他们真正的问题是什么。如果问题是时延,也许在正确的位置添加缓存可以解决这个问题。如果授权逻辑在服务中变得越来越混乱,那么可能需要强制采用标准策略格式。(Oso 是一个解决方案;还有其他解决方案。)
但是,如果问题是你的数据模型变得过于复杂,或者你在重复实现相同的 api,或者权限检查需要与太多不同的服务通信,那么也许是时候重新考虑架构了。
模式 2:请求网关
解决授权数据问题的一个优雅的解决方案是将用户角色包含在对服务(这些服务可能需要做出授权决策)的请求中。如果文档服务在请求中获得有关于用户角色的信息,那么它可以基于这些信息做出自己的授权决策。
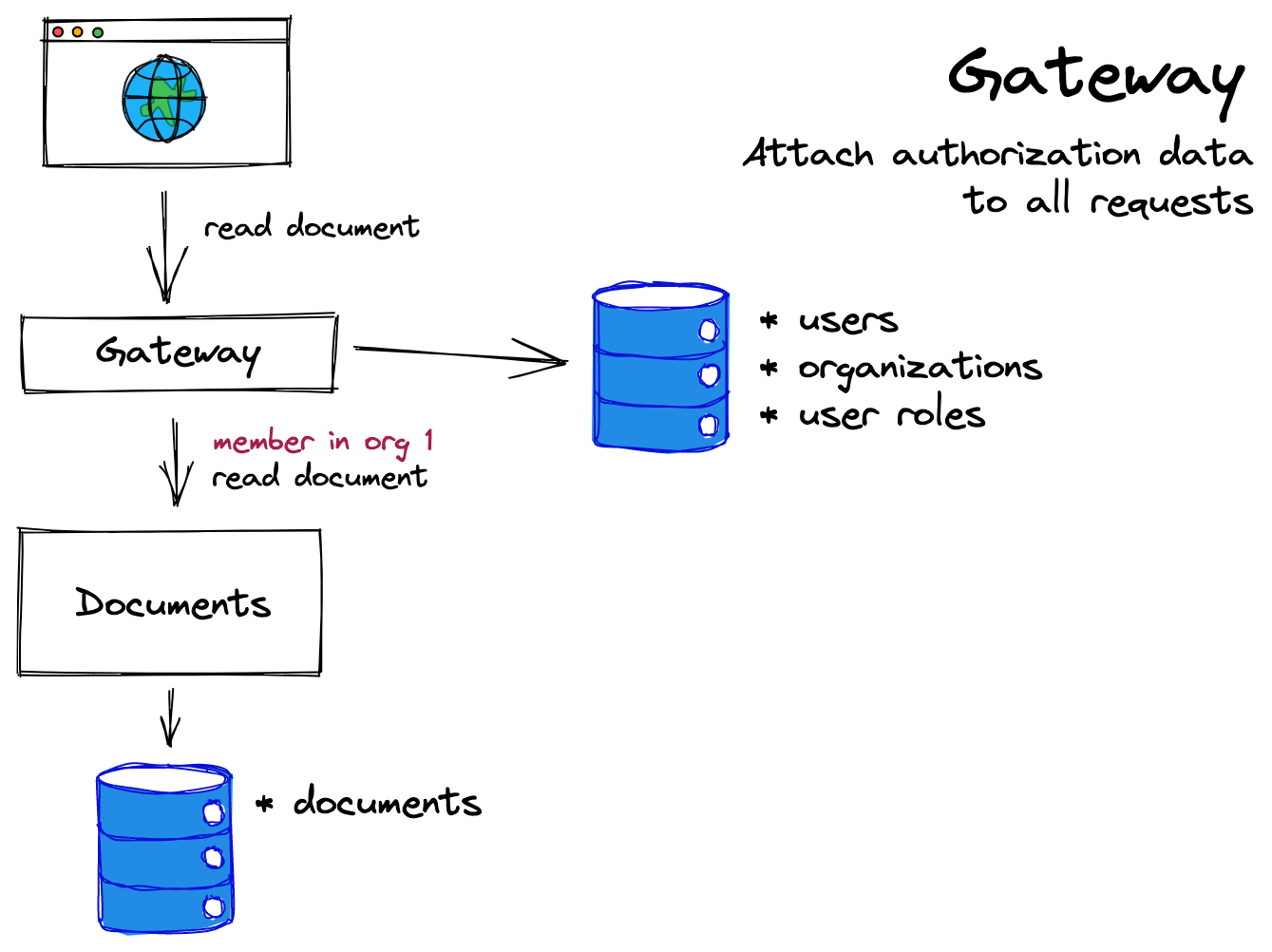
在这种模式中,“网关”位于 API 和其最终用户之间。网关可以访问用户信息和角色信息,它可以在将请求传递给 API 本身之前将这些信息附加到请求中。当 API 接收到请求时,它可以使用来自请求的角色数据(例如在请求头中)来检查用户行为是否被允许。
网关通常同时负责身份验证和授权。例如,网关可能使用 Authorization 头对特定用户进行身份验证,然后另外获取该用户的角色信息。然后网关将带有用户 ID 和角色信息的请求代理给下游服务(上面示例中的文档服务)。
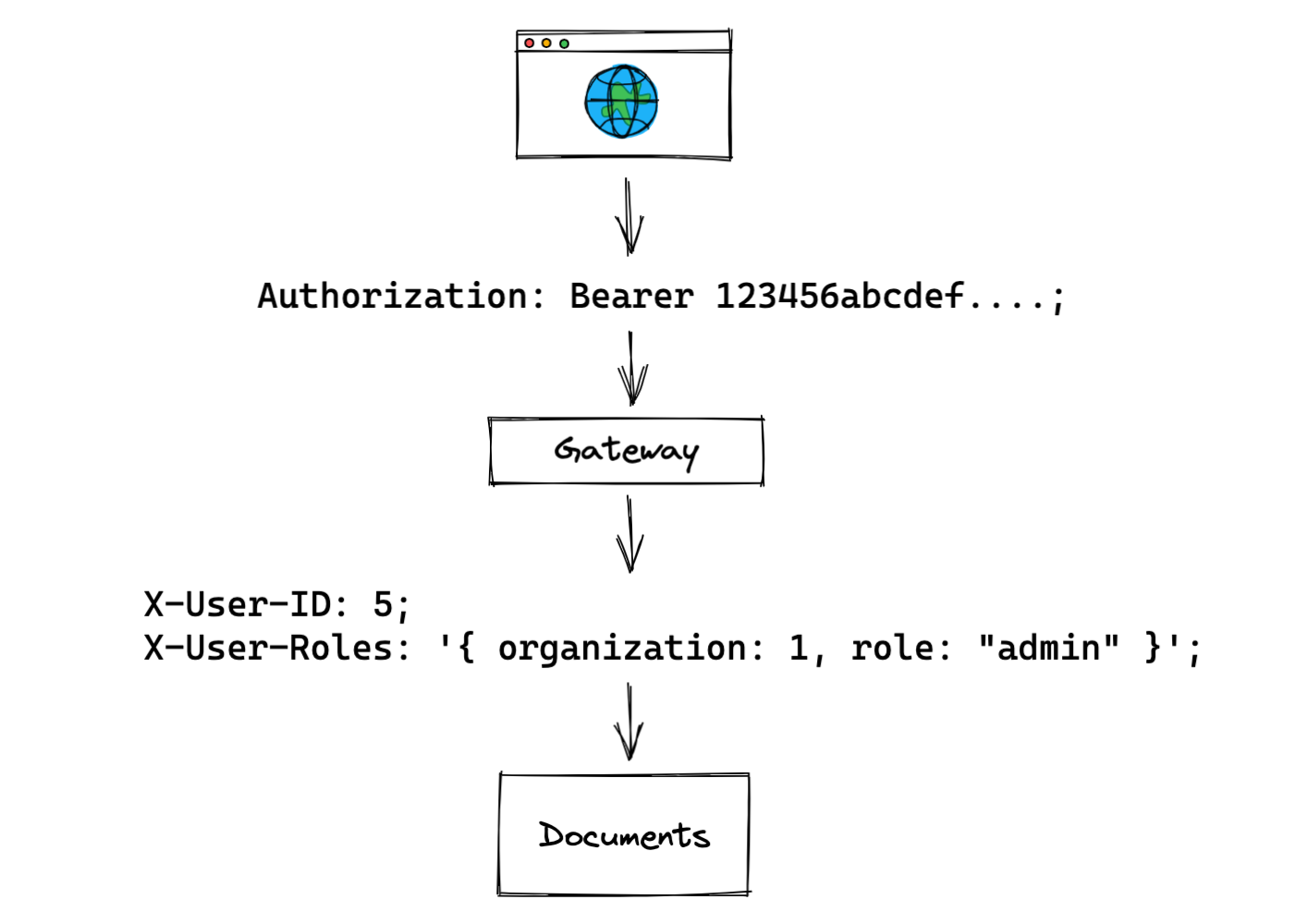
网关模式的主要好处是其架构简单。它使下游服务(如文档服务)的开发人员不必关心角色数据来自哪里。授权数据在请求中始终是可用的,因此可以立即执行权限检查,而不需要任何额外的调用。
请注意,在这里使用明文头信息开辟了新的攻击途径——你需要确保恶意客户端不能注入它们自己的头信息。作为一种替代方法,用户角色或其他访问控制数据可以包含在他们的身份验证令牌中,通常表示为JWT。
如果授权数据由少量角色组成(例如,每个用户在一个组织中只能有一个角色),网关模式的效果最好。当权限开始不仅仅依赖于用户在组织中的角色时,请求的规模就会激增。也许用户可以有不同的角色,这取决于他们试图访问的资源类型(特定事件的组织者,或特定文件夹的编辑器)。有时,这些数据太大以至于无法放入请求头中,而其他时候,一次获取所有数据效率很低。如果是这种情况,将所有相关的授权数据塞到令牌或请求头中并不能完全解决问题。
模式 3:集中存放所有授权数据
另一种解决方案是将所有授权数据和逻辑放在一个地方,与需要实施授权的所有服务分开。实现此模式的最常见方法是构建专用的“授权服务”。然后,当其他服务需要执行权限检查时,它们会转向询问授权服务:
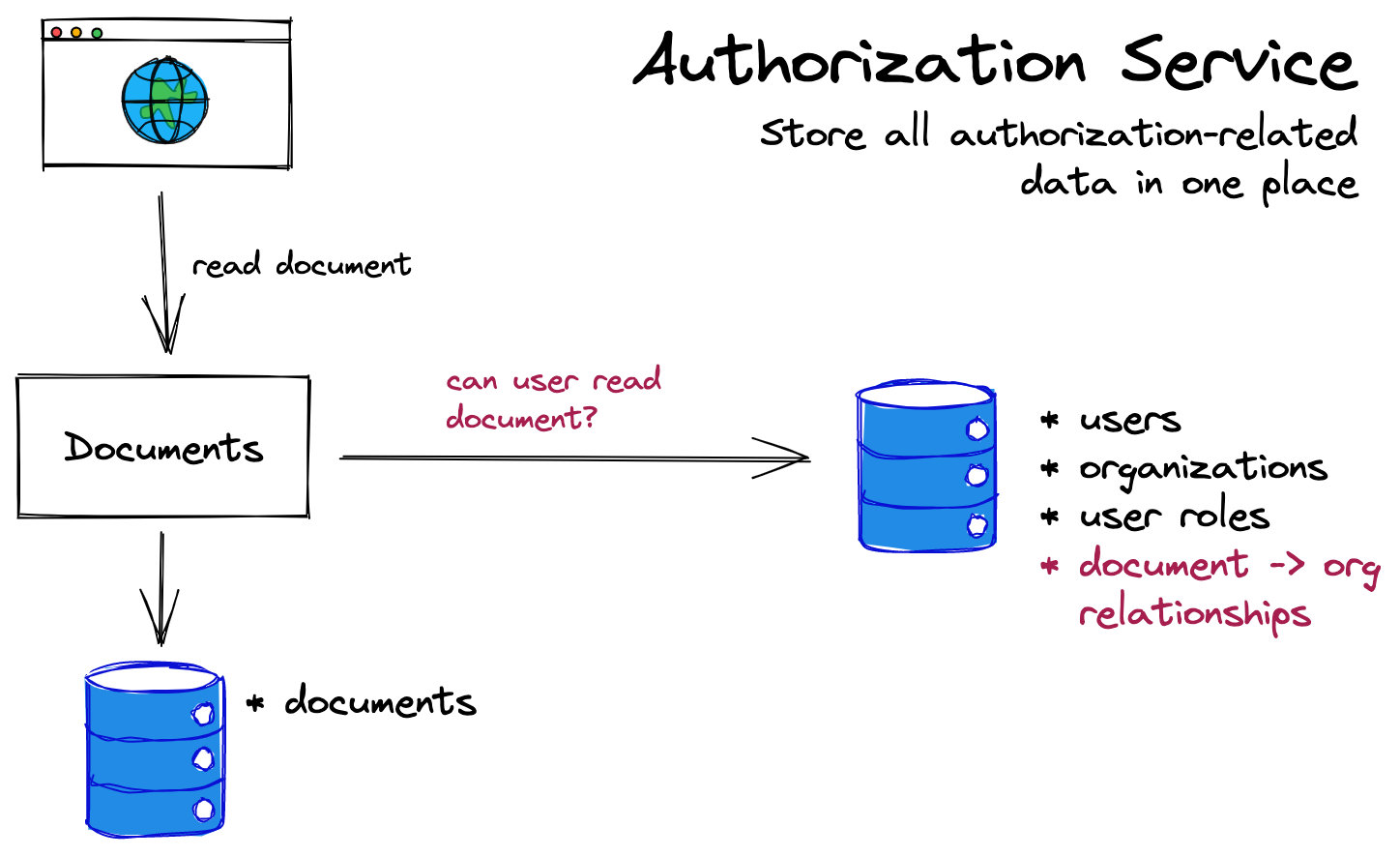
在这个模型中,文档服务根本不关心用户的角色:它只需要询问授权服务,用户是否可以编辑文档,或者用户是否可以查看文档。授权服务本身包含做出该决策所需的所有内容(包括角色数据)。
这可能非常有吸引力:你现在有一个负责授权的系统,这符合微服务的哲学。以这种方式进行责任分离有一些好处:团队中的其他开发人员不需要关心授权是如何工作的。因为它是独立的,所以你对授权服务所做的任何优化都有助于加速整个系统的其余部分。
当然,这种责任分离是有代价的。现在,所有授权数据都必须保存在一个地方。决策中可能使用的所有内容都必须保存在一个集中式服务中,这些内容包括用户在组织中的身份、文档与其组织的关系。要么授权服务成为该数据的唯一真实来源,要么必须将数据从应用程序复制并同步到该中心(可能性更大)。授权系统必须理解作为所有权限基础的整个数据模型:组、共享、文件夹、来宾、项目。如果这些模型经常改变,授权系统可能成为新的开发任务的瓶颈。任意微服务中的任何更改都可能需要对授权服务进行更新,从而打破你在最 初转向微服务时可能寻求的关注点分离效果。
还有其他因素会使授权服务变得棘手:部署这一负责保护每个请求的服务意味着你要负责实现高可用和低延迟。如果系统出现故障,则所有请求都会被拒绝。如果授权系统系统的响应很慢,那么每个请求都很慢。
谷歌的Zanzibar论文概述了这种模式的一种实现,但它也带来了挑战。你必须将所有数据以“元组”的形式插入到 Zanzibar 中(Alice 拥有这个文档,这个文件夹包含另一个文件夹,等等)。由于它限制了可以存储的数据,有些规则实际上不能仅用 Zanzibar 来表示,例如一些必须与时间、请求上下文有关的规则,或者依赖于某种计算的规则。有人将这些称之为“基于属性”的规则。例如,用户每周只允许创建 10 个文档,或者管理员可以将某些文件夹设置为“只读”,以防止对其中文档的编辑。在这些情况下,开发人员必须在 Zanzibar 之外编写自己的策略逻辑。
集中式授权存在的挑战往往会阻止大多数团队采用这种模式。采用该模式的应用往往有很多服务和足够复杂的数据模型,接受授权服务本身增加的复杂性对它们来说是有意义的。例如,为了从单体应用向微服务转型,Airbnb建立了一个名为Himeji的授权服务以支持他们的授权模式。已经有一个专门的工程师团队为它工作了两年,而且可能会无限期地工作下去。
但是,如果你能够去除一些这类开销,那么对于许多使用微服务架构的团队来说,集中式授权服务可能是一个很有吸引力的选择。我的团队正在努力构建一个授权服务,力求避免集中所有授权数据的挑战。如果这是你所面临的问题,请联系我们。
你应该用哪一个?
当与工程师团队交谈时,我的指导意见总是“围绕应用程序构建授权,而不是反过来。”对于简单系统,维护大量额外基础设施代价高昂,最好将数据保存在其所在的位置,并将服务与专用 api 放在一起。某些应用程序可以通过基本用户角色(可使用 GWT)扩展到大规模,在这种情况下,授权网关可能是最佳的。一些拥有各种产品、授权模式和用户类型的公司可能更愿意将其数据集中到专用的授权服务中。
如果你对讨论你的授权系统感兴趣——例如你正在考虑进行一些重构,或者只是对它的工作方式不太满意,请与我们联系。你可以与Oso工程师安排1x1讨论,或者加入我们的slack。我们喜欢讨论授权。
如果你曾经对混乱的授权系统感到沮丧,或者和我一样喜欢好的分布式系统问题,欢迎加入我们团队!我们正在招聘,来帮助我们推动进一步的思考。
原文链接:https://www.osohq.com/post/microservices-authorization-patterns




