
一、背景介绍
腾讯云数据库 PostgreSQL 作为支撑着腾讯内部大量的业务,这些业务不仅仅包含有正式线上运行的,也包括内部测试开发所使用的数据库。不同业务有着不同的述求,不同的使用方法会带来不同的数据库问题。
作为一个数据库平台,需要支持各种不同的业务场景,本文重点讲述在大量 drop 的业务场景下所遇到的问题。
当前业务场景因为其安全要求特别高,对数据的更新特别慎重,不能随意更新。所以业务架构设计将需要修改的主库数据通过数据转换拉取到可编辑的分支库中。只有在审核后才合入到主库当中。
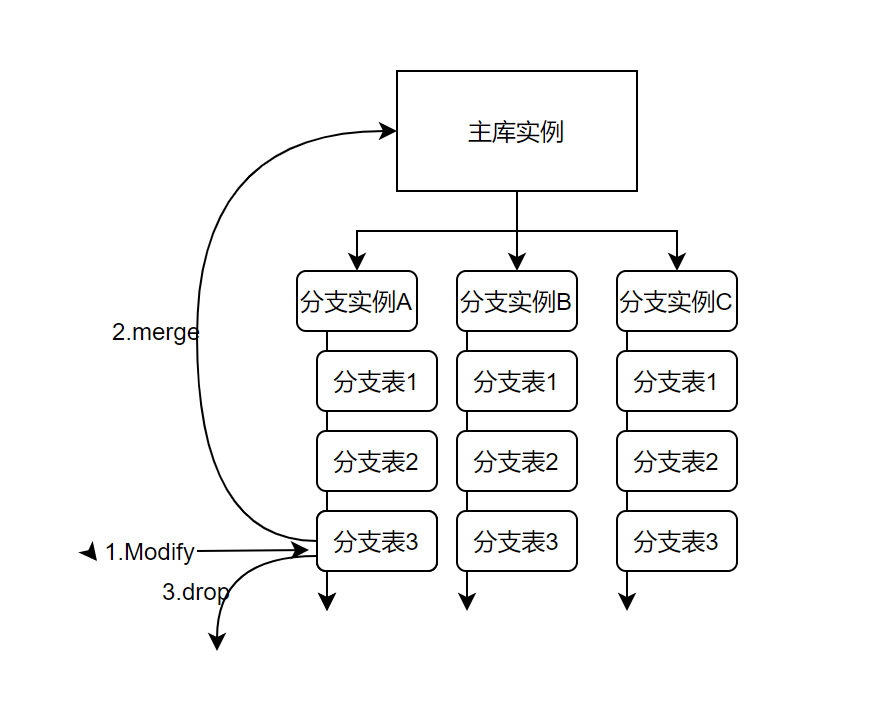
刚刚我们讲到了为了保证核心空间数据安全性,不能被任意修改,在业务系统中设计了可编辑分支库和主库的一套逻辑。具体实现是,不同类型的数据分散存放于不同数据库实例当中。
当终端采集到的数据需要对主实例数据修改时,不会直接修改主库数据,会从指定的分支库中进行变更。
变更完成后,通过校验和审核后,将变更数据同步至主库实例当中。
完成数据的 merge 之后,当前分支库就有可能不需要了,需要删除。但是分支实例是可以复用的,所以分支实例保留。
通过上述 3 个步骤最大程度的保证了数据的安全,然后落实到 PostgreSQL 数据层,意味着就需要分支库就会不断的新增表,并且完成更新会丢弃掉这些表。所以数据库中有着大量的 create/drop 表,这就引入了今天要讲到的重点—PG 内核关于主从同步的痛点。PostgreSQL 主从复制在大量处理此类的 drop 操作的时候会导致日志堆积,应用变慢的问题。不仅仅是在高可用场景下,拉一个从库作为只读实例也同样会出现此类情况,一旦遇到此类场景就会出现以下几种严重的后果。
数据应用慢,主从切换 RTO 受到严重影响,一旦处于业务高峰期,每一秒受到的损失都难以承受。
只读实例数据更新缓慢,导致主实例与只读实例数据不一致,严重的还会导致业务出现 BUG,导致数据错乱等问题。
若主从同步级别为 remote_apply,还会导致主库 hang 住,导致主库的 drop 同时也变慢,且 DDL 会持有排他锁,会导致实例的一系列故障等。
二、原理分析
关于 PostgreSQL 的主从复制处理逻辑,大家知道 PG 备机通过物理复制实现主从同步功能。日志同步到备机之后,备机会解析 wal 日志,来与主库保持数据一致,而 PG 备机在恢复一条 drop table 语句时要做的操作有哪些呢?
恢复系统表,例如 pg_class,pg_attrbute,pg_type 等,相当于移除表的元信息;
close 表对应的文件;
遍历 buffer 中的页面,如果缓存的是该表的页面,则标记为 invalid,后面其他进程可以使用该页面,这里就调用的前文提到的 DropRelFileNodesAllBuffers;
发异步失效消息给其他 backend,通知该表已删除;
删除表对应的外存文件。
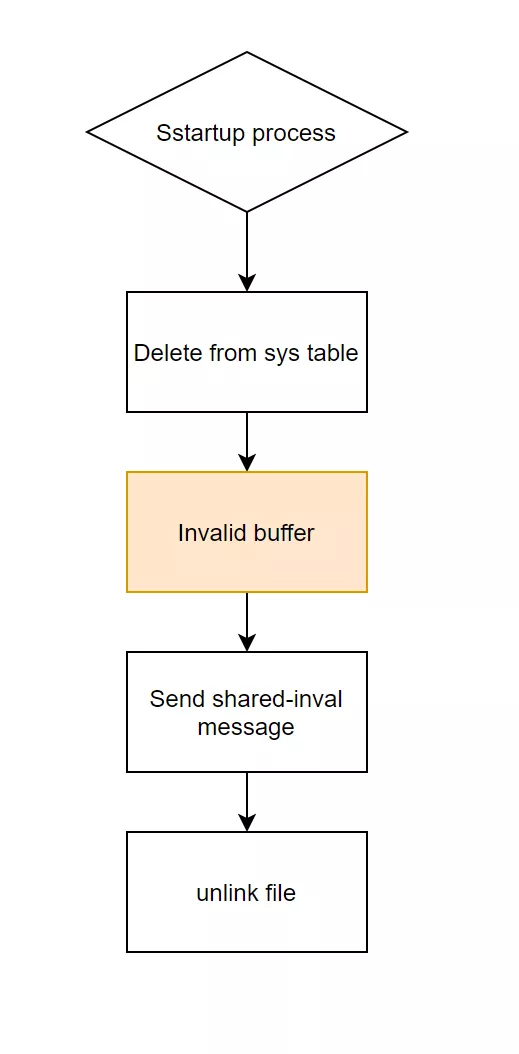
单看上面的流程图中感觉挺简单,但是 PG 内核在第三步 invalid buffer 的时候,有一个罪魁祸首就是 DropRelFileNodesAllBuffers 这个函数。
因为这里 PG 的实现是需要从头到尾遍历整个 shard_buffer,查看 buffer 是否缓存有将要删除的表的数据,将其标记为失效。而 PG 中页面大小默认为 8K,以 shard_buffer 大小 16GB 为例,则一共有 16GB/8K = 200W 个 page,每删除一个表这里需要循环 200 万+次,如果表上面有索引,每个索引也要循环 200 万次(当然如果一个事务内删除的表比较多,PG 做了优化,循环内可以使用二分查找判断是否是需要淘汰的页面)。
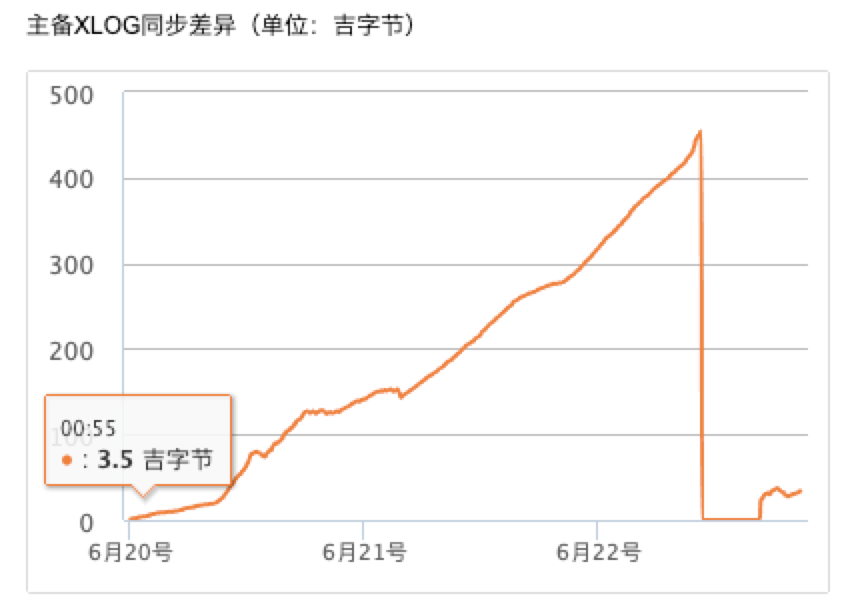
所以从业务上看,当存在大量数据导入并且快速删除表的循环的时候,因为主库可以并发执行所以感觉不出性能的影响,但是因为 PG 的备库是单进程的 recovery,就会出现主备同步日志堆积,数据延迟问题的问题,如下图所示(吉代表 G):
三、问题修护
在官网发布的补丁和修护计划中也没有发现想要修改这个点的一个计划,所以就只能我们自己开始操刀了。那么如何解决呢?
回到刚刚的流程图中可以发现,第三部 invaild buffers 这个步骤实际上并非一个串行的操作,和其他步骤没有什么联系,于是我们做了一个优化,就是将 invalid buffers 步骤从整体步骤中抽出来,单独放到一个子进程中去实现,这样整体消耗日志的速度就会加快,即可解决日志堆积的问题。
但是按照上面的做法,解决了日志堆积问题之后,也带来了另外几个问题:
当清理 buffer 动作未完成时,最后一步 unlink file 时就已经完成了,此时数据库如果正在做 checkpoint 时,就会去 flush buffer 中还未标记为不可用的 page,此时就会导致打开文件错误。
当清理 buffer 动作未完成时,删除文件执行完成后,又创建了一个和刚刚删除的文件同名的文件,会导致后续的文件在内存中的映射会被异步的置为 invalid。
那么如何解决呢,我们这里是将 recover drop table 操作的时候将表信息写入一个共享的 hash 表中,当 invalid buffer 结束时将表从 hash 表中移除,这样如果在此过程中发生打开文件失败,则就检查是否存在此 hash 表中即可。
并且如果在新创建文件的时候也去遍历一下此队列,如果队列中存在同名文件正在 invalied buffer,则等待即可。而 PG 关于表文件命名是一个 uint32 整数保存,采用的是“全局分配,局部存储”的方式,即一个实例下的所有数据库使用一个计数器生成文件号,生成的文件保存在各自库的目录下,分配时,如果当前库下已有同名文件,则尝试下一个,直到没有冲突为止,计数器绕圈后重新开始。所以一个数据库下面支持的文件数理论上最多为 uint32 类型上限,40 亿左右。表,索引,物化视图,toast 表等都使用该计数器统一编号,所以发生文件名重用的情况可能存在,概率不大。
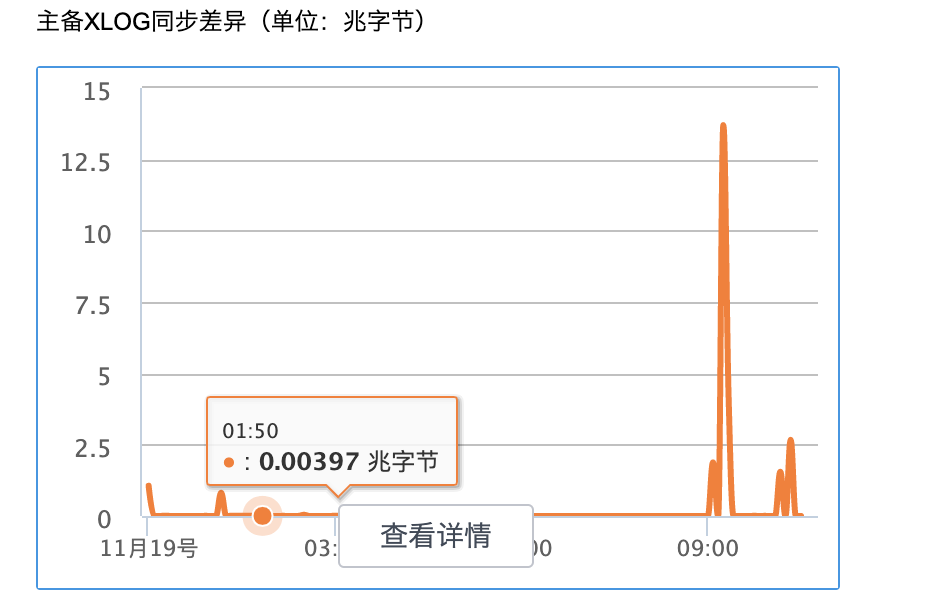
经过优化后,可以明显发现同类场景下主备同步差异由以前的最高 4 百多 GB 下降到了十多 MB,主从同步性能增强了 3W 多倍。
四、结语
数据库是所有业务的基石,其每一个微小的改动都会对业务造成极大影响。所以在后端优化时每一步都是小心翼翼,本次优化对 PostgreSQL 数据库本身性能和能力也是一个极大挑战,我们克服了种种问题,完美的适应了业务场景。并且此特性在开源版本中仍未进行修改,后续我们继续优化此类特性,并且计划将提供至社区中。
头图:Unsplash
作者:唐阳
原文:https://mp.weixin.qq.com/s/Us0HE0KmO5rxhj8Le70DJA
原文:三万倍提升,起飞的 PostgreSQL 主从优化实践
来源:云加社区 - 微信公众号 [ID:QcloudCommunity]
转载:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。




