
在服务器上使用 GraphQL 代替 REST 是有很多好处的,使用 Apollo Client 取代自己编写的数据获取逻辑也有很多优势。在这篇文章中,我们主要讨论 GraphQL 最突出的架构优势。
本文最初发布于 khalilstemmler.com 网站,经原作者授权由 InfoQ 中文站翻译并分享。
在过去的几年中,我们已经看到各种规模和形态的公司都开始在整个组织中逐渐采用 GraphQL,例如 Expedia、Nerdwallet 和 Airbnb。在本文中,我们将讨论在未来或现有的项目中使用 GraphQL 都将享受哪些架构优势。
六边形架构
Alistair Cockburn 在“六边形架构”中提到,我们架构的最内层是应用程序和域层。在这一层的外面是适配器(或端口)。
可以将端口视为“将外部世界连接到内部世界的一种方式”。外部世界有很多技术,我们可以在其之上构建应用程序。在外部,你能找到数据库、外部 API、云服务和种种内容。如果我们采用依赖倒置方法,就可以定义一些端口来将它们安全地包含在我们的应用程序中。端口是抽象、合约。它们通常以 接口 或 抽象类 的形式出现。
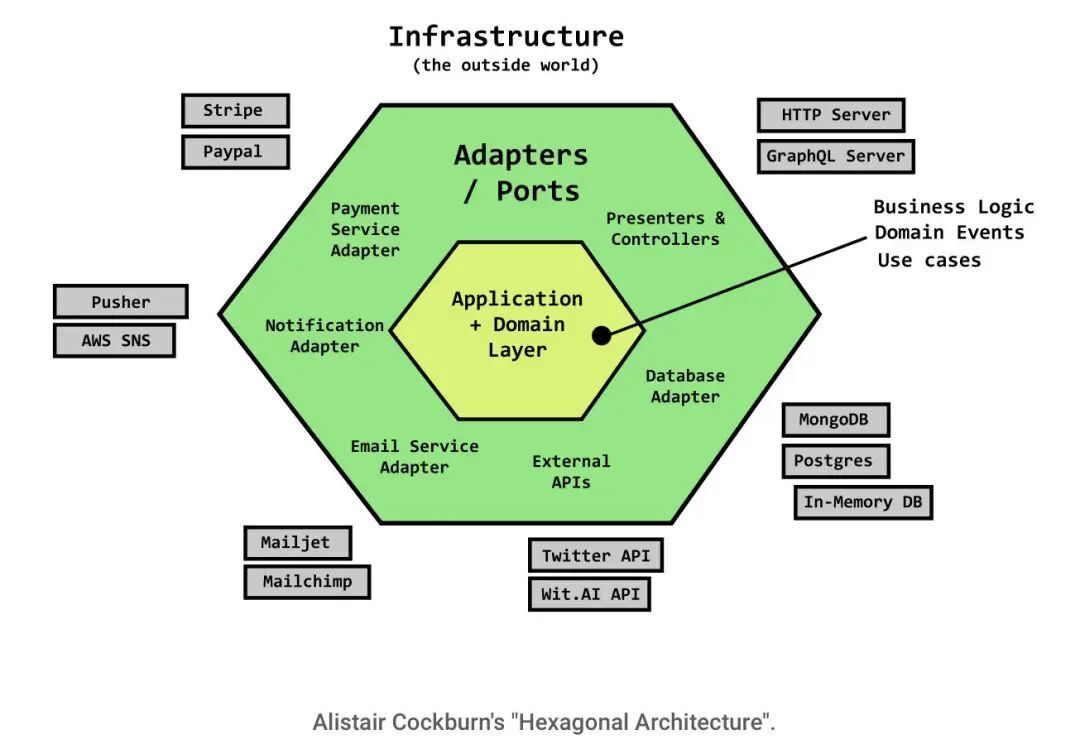
Alistair Cockburn 的“六边形架构”
我非常赞同这种类型的架构,因为它使我们能够:
直到真正有必要做出决策时,才决定到底采用哪种类型的 Web 服务器、数据库、事务电子邮件提供商或缓存技术。在开发工作早期,我们完全可以使用一个端口的内存内实现。
通过依赖注入方法,这种架构还会让开发人员优先编写可以测试的代码。这样我们就可以尽可能地减少可能导致代码不可测试的具体依赖项。
最后,它将我们的关注点转向了应用程序和特定于域的内容。这些内容是不能直接从市场购买或下载的。
基础架构组件
GraphQL 服务器和 HTTP 服务器都属于基础架构组件。
基础架构组件:构成 Web 应用程序基础的基本组件。根据整洁(或六边形)架构的思想,数据库、Web 服务器和缓存都是外层基础架构组件。
我们之所以将基础设施组件称为基础设施,是因为 我们会在它们的基础上构建应用程序。在这一基础(即框架)内,我们编写丰富的、领域特定的应用程序。基础设施只是驱动程序而已。
基础架构组件的另一个主要特征是,它们不是我们项目开发工作的重心。
基础架构组件是业界信任的一系列工具,我们只需对其配置即可使其正常工作。
GraphQL API 的配置工作包括:
安装 GraphQL
公开一个服务器端点
设计一个模式(schema)
将解析器连接到数据源
这是我们需要做的工作,但不是我们项目的工作重心。
如果某项基础架构技术受到业界的信任,我们就可以选择用这种工具来完成任务,而不是开发自己的基础架构组件,这样就可以加快我们的开发速度。
考虑数据库。它们也是基础设施。
例如,Postgres 数据库是我们可以用于新项目的几个数据库选项之一。想象一下,如果你试图说服你们的团队,你们的项目应该从头开始编写自己的数据库,其他人会有多么大的反对声。
如果有人说团队应该从头开始研发一种持久性存储技术,大家肯定会觉得这样的场面看起来很愚蠢;但选择你的 Web 应用程序 API 样式(传输 / 客户端 - 服务器技术)其实也是一样的道理。
去年(2019 年),我意识到 API 在技术栈中的深度已经超出了我们的想象。API 的触角伸到了前端框架的数据存储,也伸到了后端服务的合约层面。
这听起来可能有点虚幻,但它的确就是那样。在 Apollo GraphQL,我们将这种虚拟层称为数据图。并且 Apollo 构建了很多可提高开发人员生产效率的工具。
数据图
数据图 这个理念我是最早在 2019 年 GraphQL 峰会上听 Apollo GraphQL 的首席技术官 Matt DeBergalis 提出的。我强烈推荐 Matt 在 2019 年 GraphQL 峰会上的演讲,他介绍了数据图的概念。
数据图是虚拟层,位于我们的客户端应用程序和 GraphQL 服务器之间。它保存了整个组织的数据,并提供了用来在整个组织内获取和更改状态的语言。
数据图是一个声明性的、自文档化的、组织层面的 GraphQL API。
对我来说,数据图是现代应用程序技术栈中之前 缺少的一个层。
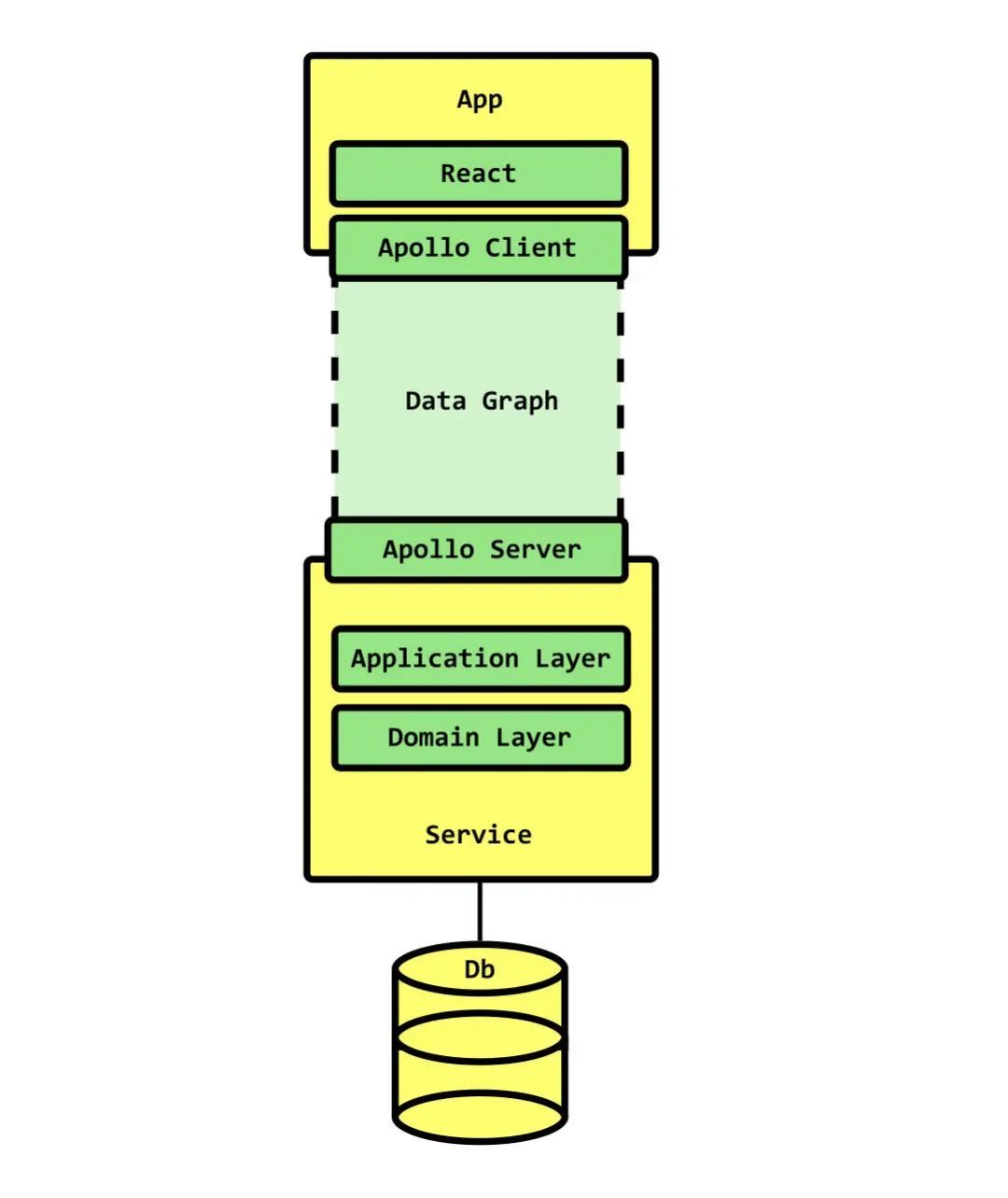
基本的全栈 Apollo Client+Server 应用程序栈
数据图让远程状态更接近客户端本地状态
所有前端框架都需要解决的三个挑战分别是数据存储、更改检测和数据流。
React 开发人员通常需要修补 Redux 或 Context,并编写大量样板代码来满足这些要求。
Apollo 发布了带有 apollo-link-state 的 Apollo Client 后,React 开发人员就能用更少的代码满足所有这三个需求了。
Apollo-link-state(现已直接放入 Apollo Client 2 和 3 中)让开发人员可以编写几乎同时解决远程状态和本地状态的查询。远程状态(位于服务器上)感觉比之前近多了。
比如说用这种查询来按照狗的品种(breed)来获取一只狗:
查询 /dog.js
const GET_DOG = gql` query GetDogByBreed($breed: String!) { dog(breed: $breed) { images { url id isLiked @client # signal to resolve locally } } }`;在主要用于获取远程资源的查询中,我们可以使用 @client 指令来引用要基于一个客户端模式从本地缓存中获取的属性。我们可以在同一请求中完成这一操作,这很厉害。想想之前在 Redux 环境我们要执行的 spread 和 Object.assign() 操作的数量有多少,就可以对比出差异了。
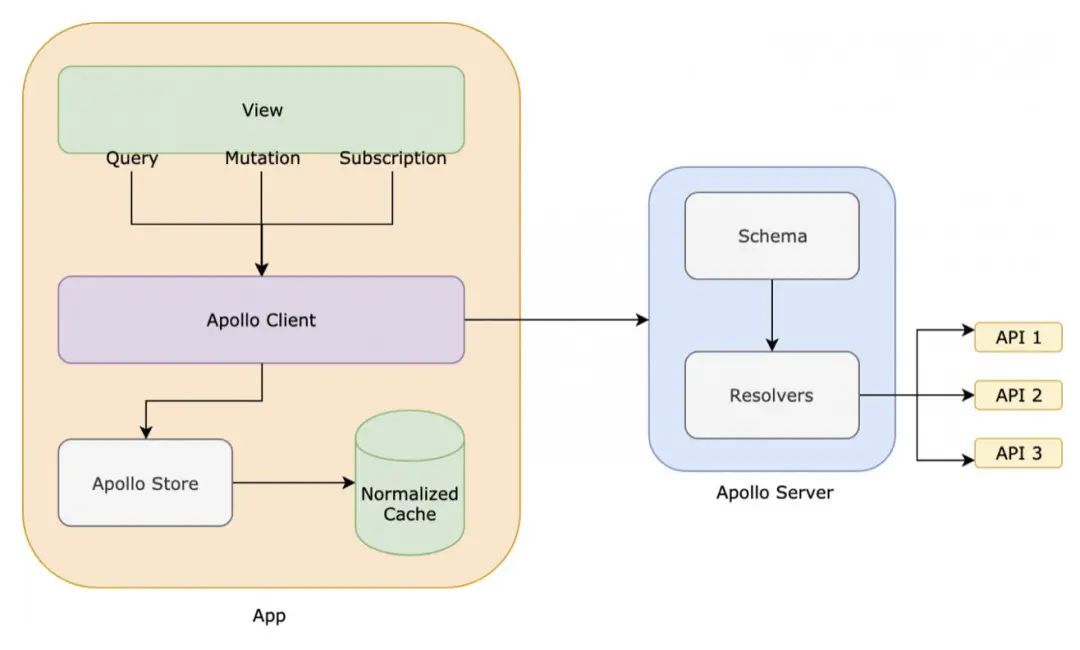
简化的数据获取架构,其中视图可以是任意前端框架——nerdwallet
数据图在连接的两端均有 Apollo 服务器和客户端,它可以简化获取逻辑、错误逻辑、重试逻辑、分页、缓存、optimistic UI 以及其他各种类型的样板数据管道代码。
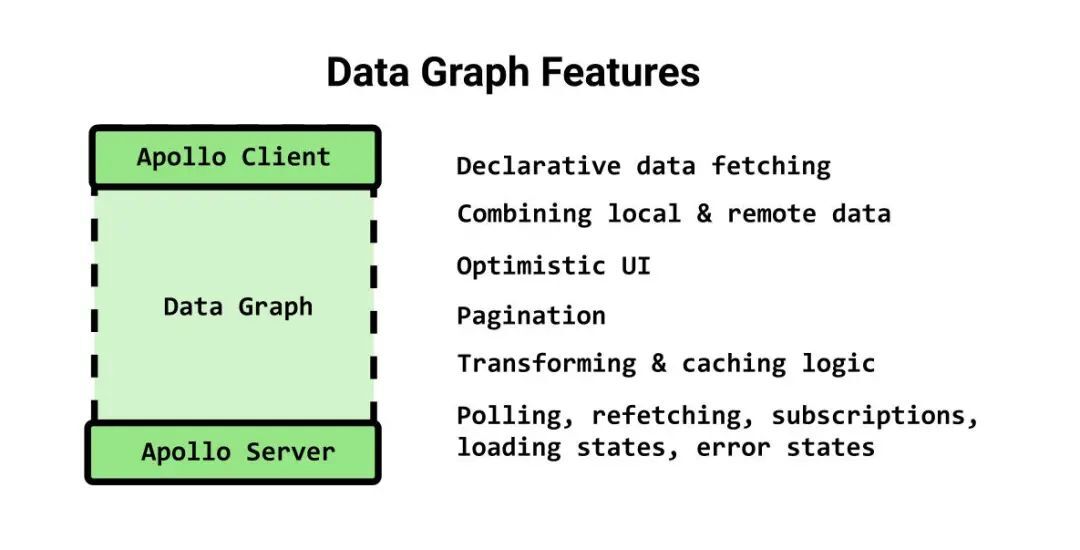
数据图从客户端延伸到服务器,并为现代 Web 应用程序中获取数据和更改状态时面临的最常见基础架构问题提供了答案
为了通过 GraphQL 与后端服务通信,Apollo Client 公开了几种客户端方法,这些方法在被调用时会将操作转换为适当的 API 以跨越数据图。
在 Apollo Server 端,这些 API 调用将控制权转交给负责使用 ORM、原始 SQL、缓存、其他 RESTfulAPI 或任何你想到的方法来获取数据的解析器。对于突变,解析器可以简单地将控制权传递给一个应用层用例。
将用例作为应用程序的重心后,从 REST 切换到 GraphQL(或同时支持两者)变得轻而易举。
GraphQL 是自文档化的
维护 RESTfulAPI 时需要做的一件麻烦事是保持文档及时更新和内容全面。
RESTfulAPI 有两处可以更改。
路由 + 方法组合
请求形式 + 参数
路由 + 方法组合 的一个例子是,某人可以很简单地将 创建一个用户 的操作从 POST /users 移至 POST /users/new。这样的 API 更改可能不会引起注意,却会破坏 API 的所有客户端,并且 API 客户端几乎不可能检测到该组合的更改。
请求形式 + 参数 的一个例子是,一个对 /users/new 的 POST 请求过去只需要一个 email 和一个 password,但现在它还需要一个 username 属性。API 客户端了解如何解决该请求的唯一方法是检查错误响应(指望错误消息描述了所需的信息,否则也没用)。
如果你认为自省(introspection)是全面的文档,那么可以说 GraphQL 是自文档化的,并且你的 API 文档无法失去同步。
使用 GraphQL Playground,可以浏览 GraphQL 端点的所有功能。
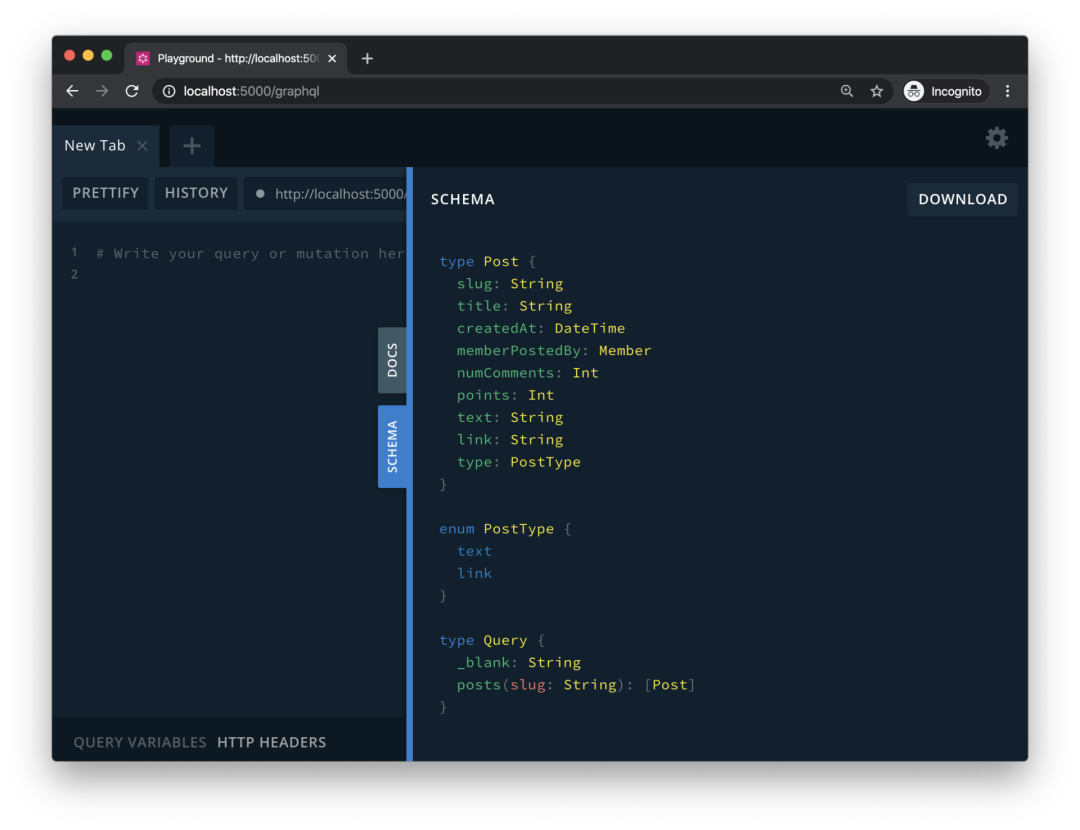
由于具备执行自省查询的能力,所以 GraphQL Playground 的 GraphQL 资源管理器可以显示 GraphQL 端点的所有功能
在 REST 领域中,我只看到了使用 Swagger 构建的 API 具有这么大的元数据量。这是一项非常强大的特性,它不仅让代码成为了文档的唯一真实来源,而且为我们提供了通过代码生成来自动创建 TypeScript 类型、客户端库或服务到服务通信的基础。
由于 GraphQL 语言是通行(ubiquitous)且标准化的,因此人类 和机器 会更容易理解如何集成和使用它。
关注点的扩展和分离
GraphQL 原则指出,
“你的公司应该有一个统一的图,而不是让各个团队创建很多图。”
随着越来越多的团队开始使用 GraphQL,公司内部会出现多个图的情况。
使用 Apollo Federation,每个服务团队都可以从其限界上下文中构建和管理自己的 GraphQL 服务,将其注册到一个 Apollo 网关,从而在整个企业中分布化 GraphQL 的运维工作。
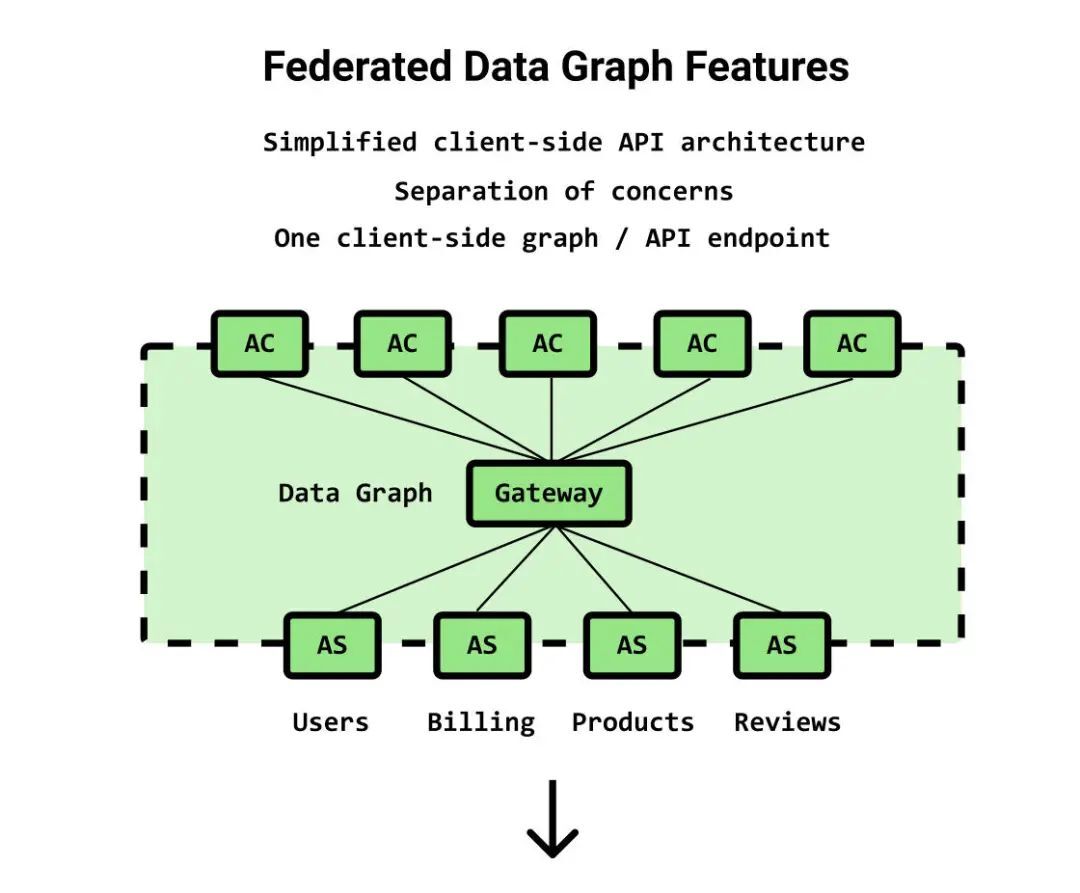
通过 Apollo Federation,我们可以绘制并公开由多个 GraphQL 端点组成的单个数据图
在 Federation 中,你可以组成模式并解析其他服务 / 限界上下文中的字段。收到请求时,将从相应的服务中解析这些字段。
对于规模庞大的组织来说,这种需求并不罕见。
单一端点
SOLID 原则中的开闭原则指出:
“组件 / 系统 / 类应对扩展开放,但对修改封闭”。
在架构层面,由于 GraphQL 仅向客户端公开单个端点,因此它满足了这一原则。
客户端隐藏了字段解析机制的所有复杂性,它只需关注如何在 GraphQL 服务器之上构建即可。
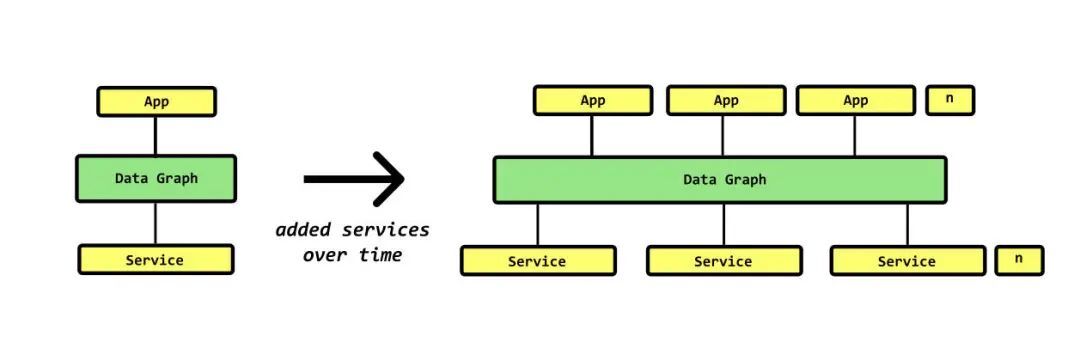
该图描述了组织的数据图随时间的演变
扩张前端开发人员的权力
数据图减少了前端开发人员对后端开发人员的依赖,这样前者就可以自行为新的用例开发新的端点。
很多时候,我们对 UI 所做的微小改动也会让我们替换掉组件,或意识到我们错误地判断了数据需求,并且需要为一些组件添加更多字段。因为这种情况经常发生,并且因为 REST 如此严格,所以每当我们需要调整的时候都必须依赖后端团队来更改 REST API。
根据团队的结构,以下每个问题都可能意味着开发人员的生产力下降,并需要依赖后端团队。
团队是碎片化的吗?前端开发人员是只做前端开发,还是允许他们完成技术栈另一端的工作?
你的后端开发人员是否在远程工作?
你的后端开发人员在办公室工作吗?
GraphQL 消除了管理 API 版本的需求
GraphQL 原则在版本控制方面也有很强的见解。它指出:
“模式应根据实际需求逐步构建,并随着时间的推移平稳发展。”
这意味着团队应该通过迭代来做更改,而不是在大版本中一次塞入很多更改,这样就可以实践敏捷模式开发了。
听上去一切都很完美,但是你我都生活在现实世界中。我知道这样理想化的情况并不总是存在,至少没有适当的工具链是不可能做到的。
Apollo 平台有一项称为模式验证的特性,可让你针对实时生产流量测试每个更改,并在建议实施重大更改时向你显示提示,让团队可以交流接下来的方案。
这种感觉很顺滑!
总结
在现代 Web 应用程序架构中,GraphQL 和 RESTfulWeb 服务器都是基础架构组件。
基础架构组件是基本组件,它们构成了我们编写的特定领域 Web 应用程序的基础。
基础架构组件并不是大多数 Web 开发项目的重心,因此我们应该将大部分时间用于应用程序和域层代码。
数据图是一个声明性的、自文档化的、组织层面的 GraphQL API,它使远程状态更接近客户端,可以使用 Apollo Federation 来扩展。
前端开发人员可以使用数据图来创建自己的数据获取用例,而不必依赖后端开发人员。
GraphQL 消除了管理 API 版本的需要,Apollo 的 GraphManager 可以简化生产模式验证。
原文链接
https://khalilstemmler.com/articles/graphql/graphql-architectural-advantages/




