
在本文中,我将讨论专为机器学习 / 人工智能应用开发的硬件,以及该领域的机遇。并简要介绍英伟达是如何在机器学习硬件领域实现近乎垄断的地位,以及为什么几乎没有人能成功挑战它。
在过去的 10 年中,专用于机器学习应用的硬件研究迅猛发展,硬件与机器学习栈的每个部分都有关系。这种硬件可加速训练和推理,减少延迟时间,降低功耗,并降低这些设备的零售成本。当前通用的机器学习硬件解决方案是英伟达 GPU,这使得英伟达在市场上占据主导地位,并使其估值超越英特尔。
随着前景广阔的研究不断涌现,英伟达继续通过出售 GPU 和它的专有 CUDA 工具箱来主导这个领域。不过,我认为有四个因素将挑战英伟达的统治地位,并且最快今年,也肯定会在 2~3 年内改变机器学习硬件的格局。
这个领域的学术研究正在成为主流。
摩尔定律已死。随着它的消亡,“技术和市场力量正在将计算推向相反的方向,使得计算机处理器不再是通用的,而是更加专业化的。”(出处)
投资人和创始人都认识到,人工智能不仅能开辟新的领域,而且能增加他们的预算。
人工智能产生的碳排放量过高,而且越来越高。我们需要让计算更加节能。
背景
下面是典型的机器学习管道的样子:
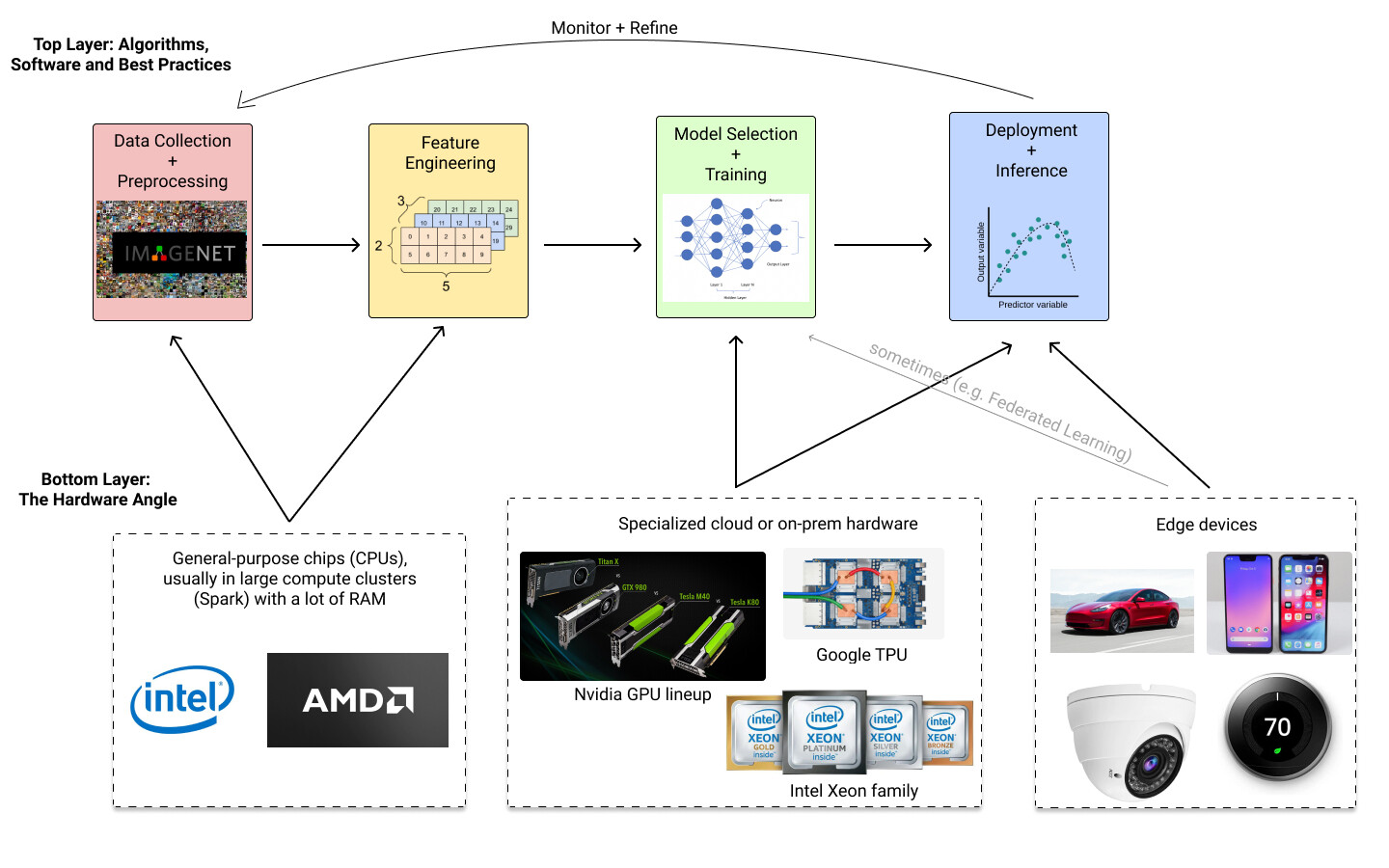
对于大多数数据科学工作流而言,在训练和部署大型模型之前,通用芯片,如 CPU,就已经足够了。GPU 在“深度学习”(涉及视觉和自然语言处理等任务的神经网络体系结构)中几乎总是必不可少的。为深度学习提供 GPU 工作站的 Lambda Labs 公司估计,包括英伟达的顶级 GPU 集群在内,训练 GPT-3 的费用大约为 460 万美元。
使用 GPU 的主要优点是,与传统 CPU 相比, GPU 可以并行地执行计算,数据吞吐量更高。计算过程中,机器学习的核心计算部分是矩阵乘法,并行运行时能大大提高运算速度。专有的英伟达CUDA提供了 API 和工具,以便开发者可以利用这种并行化。像 TensorFlow 和 PyTorch 这样的流行库将其抽象出来,其中一行代码会自动检测 GPU,然后利用 CUDA 后端。若要设计一种新的算法或库,需要利用并行计算的优势,CUDA 提供的工具会使这一工作更加简单。
上世纪 90 年代初,英伟达作为一家视频游戏公司起家,希望能提供能快速绘制 3D 图像的图像芯片。它在这一业务上取得了成功,在与另一家显卡制造商 AMD 的不断交锋中,始终如一地制造出一些最强大的 GPU。巧合的是,同样的图形硬件竟然成了深度学习腾飞不可或缺的因素。CUDA 让英伟达比其他 GPU 更有优势。

2006 年,英伟达发布了第一个 CUDA 工具包,它提供了一个 API,可以让使用 GPU 变得非常简单。3 年后,2009 年,斯坦福大学人工智能教授吴恩达及其合作者发表了一篇题为《使用图形处理器的大规模无监督式深度学习》(Large-scale Deep Unsupervised Learning using Graphics Processors)的论文,指出如果 GPU 用于训练,大规模的深度学习就有可能实现。
一年后,吴恩达和斯坦福大学的另一位教授,Google X 的共同创始人,Sebastian Thrun,向拉里·佩奇提出了在谷歌成立深度学习研究团队的想法,该团队后来成为 Google Brain。伴随着 Google Brain 的崛起和“Imagenet 时刻”的到来,英伟达的 GPU 已经成为人工智能 / 机器学习行业事实上的计算标准。如需更多信息,请参阅这篇文章《新的英特尔:英伟达如何从驱动视频游戏到革新人工智能》(The New Intel: How Nvidia Went From Powering Video Games To Revolutionizing Artificial Intelligence)。
概述:现状
英伟达凭借其 GPU 在深度学习硬件领域占据主导地位,这在很大程度上要归功于 CUDA。据福布斯报道,“2019 年 5 月,前四大云计算供应商在 97.4% 的基础设施即服务(IaaS)计算实例类型中部署了英伟达 GPU,并配备了专用加速器”。面对竞争,它也没有坐以待毙。
谷歌早在 2015 年就开发了专门为神经网络开发的人工智能加速器芯片 TPU。在其作为特定领域加速器的狭义用例中,TPU 比 GPU 更快,也更便宜,但在谷歌的 GCP 生态系统中,TPU 被隔离起来,仅有 TensorFlow 和 PyTorch 支持(其他库需要自己编写 TPU 编译器)。
AWS 正在对自己的芯片下赌注,尤其是机器学习。到目前为止,AWS Inferentia 芯片似乎是最成功的。这在很大程度上取决于开发者从 CUDA 切换到亚马逊 Inferentia 和其他芯片的工具包的难易程度。
2019 年 12 月,英特尔以 20 亿美元的价格收购了 Habana Labs,这是一家以色列公司,为训练和推理工作负载制造芯片和硬件加速器。英特尔的投资似乎得到了回报,上个月,AWS 宣布将提供运行 Habana 芯片的新 EC2 实例,“与当前基于 GPU 的 EC2 实例相比,为机器学习工作负载提供高达 40% 的价格性能”。英特尔还推出了新的 Xeon CPU 系列,它认为可与英伟达的 GPU 竞争。
Xilinx 是一家发明 FPGA 的上市公司,最近又涉足人工智能加速器芯片领域,2020 年 10 月被 AMD 收购。
对人工智能计算能力的需求正在加速。
变化与机遇
正如我在上面提到的,我的设想是,到 2021 年及以后,英伟达的主导地位将会受到越来越多的挑战和侵蚀。造成这种情况的原因有四个:
1. 学术研究变成真正的产品
学术界和工业界研究人员创立的一些初创公司已经开始研究机器学习专用硬件,而且还有更多的开发空间。在这个领域发表的论文并不只是提出理论上的保证,它还展示了真正的硬件原型,这些原型实现了比商业可用选项更好的指标。(实例 1、实例 2和实例 3)
芯片和硬件加速器的种类很多,每一种都有其蓬勃发展的研究社区。简单地列举一些:
专用集成电路(ASIC)。谷歌 TPU 和 AWS Inferentia 都是 ASIC 的例子。ASIC 产品的研发和生产成本可能高达 5000 万美元,但是复制产品的边际成本通常很低。ASIC 可以被设计成低功耗的,而且不会对性能有太大的影响。
现场可编程逻辑门阵列(FPGA)。FPGA 对于高频交易者来说已稀松平常,但在机器学习方面的例子包括微软的 Brainwave 和英特尔的 Arria。单个 FPGA 的生产成本较低,但多个 FPGA 的生产边际成本要高于 ASIC。
神经形态计算。该领域试图对人脑的生物结构进行建模,并将其转换成硬件。尽管神经形态学的思想可以追溯到 20 世纪 80 年代,但该领域仍处于起步阶段。在《自然》上有一篇很好的综述性论文。
更多内容请参阅此项调查报告《机器学习加速芯片综述》(Survey of Machine Learning Accelerators),并关注ISCAS。
使用上述研究结果的一些有前途的初创公司:
Blaize 于 2019 年宣称已经开发出一种完全可编程的低功耗处理器,可实现 10 倍的低延迟,并且“系统效率最高可提高 60%”。
SambaNova Systems 是由斯坦福大学教授和甲骨文前高管创立的初创公司,由谷歌风投和英特尔资本出资组建。它刚刚宣布了一项新产品,该产品是一个“完整、集成的软件和硬件系统平台,可以对从算法到芯片的数据流进行优化”。
Graphcore 是一家英国初创公司,由红杉、微软、宝马和 DeepMinds 创始人领投。
2. 摩尔定律已死,但无论如何,专用硬件都是未来趋势
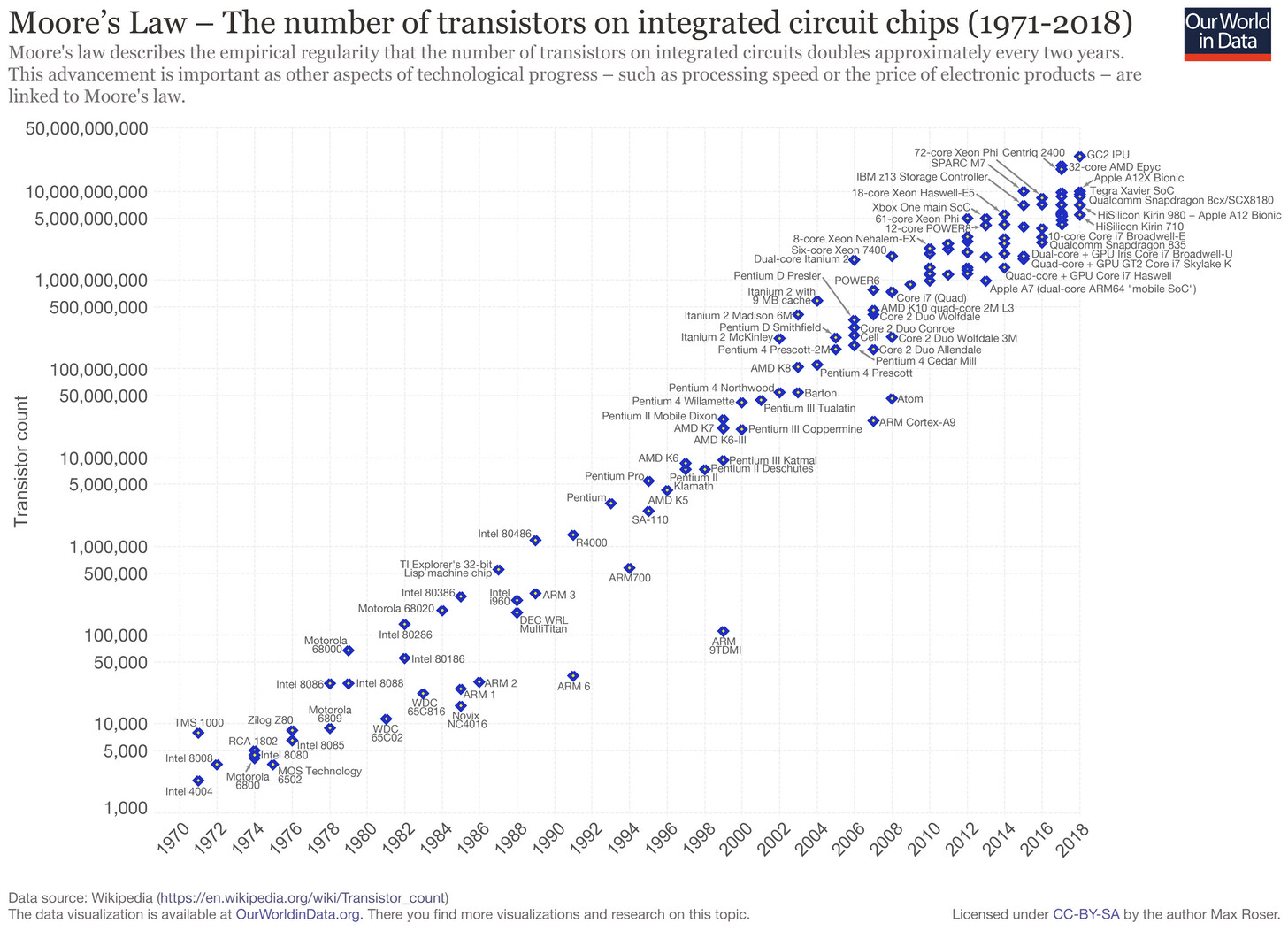
摩尔定律预测,集成电路上的晶体管数量每两年就会增加一倍。自 20 世纪 70 年代以来,这在经验上一直是正确的,并且是我们从那时起所看到的技术进步的代名词:个人计算革命、传感器和摄像头的改进、移动设备的兴起,以及为人工智能提供充足资源的崛起,凡是你能想到的一切。唯一的问题是,摩尔定律即将结束,如果它还没有结束的话。“缩小芯片的难度越来越大,这已经不是什么秘密了,而且这样做的好处也今非昔比了。去年,英伟达的创始人黄仁勋直言不讳地认为,‘摩尔定律已不再可能了’。”《经济学人》(The Economist)写道。
麻省理工学院经济学家 Neil Thompson 在《麻省理工科技评论》(MIT Technology Review)上解释说:“软件和专业架构方面的进步现在将开始有选择地针对特定的问题和商业机会,对那些有充足资金和资源的人有利,而不是像摩尔定律那样‘水涨船高’,通过提供速度更快、成本更低的芯片来普及。”一些人,包括 Thomspon 在内的,都认为,“这是一个消极的发展,因为计算硬件将开始分裂为“‘快车道’应用和‘慢车道’应用程序,前者使用功能强大的定制芯片,而后者则被卡在使用通用芯片上,而且其进展缓慢。”
对于这个问题,分布式计算常常是一种解决方案:让我们使用功能更少、成本更低的资源,但要使用大量的资源。但是,就连这种方案也越来越昂贵(更别提分布式梯度下降算法的复杂性了)。
那么,接下来会发生什么呢?2018 年,CMU 的研究人员在《自然》上发表了一篇论文,题为《摩尔定律末期的科学研究政策》(Science and research policy at the end of Moore’s law),该论文指出,私营部门将重点放在短期盈利上,这使得摩尔定律很难找到通用的继承者。他们呼吁公私合作,共同创造计算硬件的未来。

虽然我并不反对公私合作(给予他们更多的权利),但我认为未来的计算硬件将是专用芯片的集合,当它们协同工作时,它们比现在的 CPU 更能胜任通用任务。我相信苹果向自己的芯片过渡是朝着这个方向迈出的一步,这证明了软硬件集成系统将优于传统芯片。特斯拉也在自动驾驶中采用了自己的硬件。我们需要的是大量的新玩家涌入硬件生态系统,这样专业芯片的好处就可以实现大众化,并分布在昂贵的笔记本电脑、云服务器和汽车之外。(我敢说……是时候打造了吗?)
3. 创始人和投资者担心成本上涨
Andreessen Horowitz 的 Martin Casado 和 Matt Bornstein 在去年年初发表了一篇题为《人工智能的新业务(及其与传统软件的区别》(The New Business of AI (and How It’s Different From Traditional Software))的文章,他们认为人工智能的业务与传统软件是不同的。说到底,一切都与利润有关。“云计算基础设施对人工智能公司来说是一个巨大的成本,有时甚至是隐性成本”。正如我所提到的那样,训练人工智能模型可能需要花费数千美元(如果你是 OpenAI,你就得花数百万美元),但成本并不止于这些。人工智能系统必须得到持续监控和改进。如果你的模型是“离线”训练的,那么它很容易出现概念漂移,即现实世界中的数据分布随着时间的推移与你训练的数据发生变化。这种情况可能是自然发生的,也可能是对抗性的,比如当用户试图欺骗信用风险算法时。出现这种情况时,就必须对模型进行再训练。
对于降低概念漂移和创建与现有模型具有相同性能保证的更小的模型有一些积极的研究,但这是另一篇文章的主题。同时,该行业也正在推进更大的模型和更大的计算支出。更便宜、更专业的人工智能芯片无疑会降低这些成本。
4. 训练大型模型有助于气候变化

由马萨诸塞大学阿默斯特分校进行的一项研究发现,训练一个现成的自然语言处理模型所产生的碳排放量相当于从旧金山飞往纽约的一次航班。在三大云计算供应商中,只有谷歌的数据中心超过 50% 的能源来自可再生能源。
但我认为,我不必列出我们为什么要减少人工智能的碳排放。我想说的是,现有的芯片耗电量过大,而且研究表明,其他类型的硬件加速器,如 FPGA 和超低能耗芯片(如谷歌 TPU Edge),对于机器学习和其他任务来说,可以更加节能。
即使是地理也会影响到人工智能的碳排放。斯坦福大学的研究人员估计,“在主要依赖页岩油的爱沙尼亚举行一次会议,其产生的碳排放量是在魁北克举行的会议的 30 倍,而魁北克主要依靠水力发电。”
已露端倪
我已经提到了人工智能的硬件,但是人工智能的硬件怎么样?谷歌最近申请了一项专利,该专利是关于一种利用强化学习来确定跨多个硬件设备的机器学习模型操作的位置的方法。这项专利背后的研究人员之一是Azalea Mirhoseini,她在 Google Brain 负责机器学习硬件 / 系统的登月计划。
作者介绍:
Andrei Kozyrev,康奈尔大学攻读计算机科学与政治学。研究机器学习中的公平性、隐私性和可解释性。
原文链接:
https://fairlydeep.substack.com/p/2021-will-be-the-year-of-ai-hardware




