
一、概述
端到端语音识别技术将语音识别系统中的各个组件整合至同一个神经网络框架中,与传统语音识别系统相比具有建模简洁,赋能组件之间联合优化以及系统占用空间小等优点,近几年逐渐成为语音识别领域里最重要的研究方向之一。现有的端到端语音识别系统主要包括基于 Connnectionist Temporal Classification (CTC),基于 Sequence-to-sequence(Seq2Seq) 以及基于 RNN Transducer (RNNT) 三类系统。
Minimum Bayes Risk (MBR) 作为序列学习中最常用的区分性训练准则之一,已经成功应用于传统的混合语音识别系统中并能显著提升模型性能。最近在工作 [1] 中谷歌的研究人员将 MBR 训练准则应用在了基于 Seq2Seq 的端到端识别系统中,并由腾讯人工智能实验室的研究人员在工作 [2] 中得到了进一步提升。然而,还未曾有针对 RNNT 端到端语音识别系统的 MBR 训练的相关研究。同时由于端到端系统中的语言模型在训练过程中仅使用了语料相对应的文本作为训练数据,无论从规模以及覆盖的领域都有很大欠缺,如何将在更大规模文本数据训练得到的外部语言模型信息同时在训练和解码时注入到端到端语音识别模型中仍然是一个尚未解决的问题。
本论文由腾讯 AI Lab 独立完成,首次提出针对 RNNT 端到端语音识别系统的 MBR 训练并给出详细的数学推导。论文已被 Interspeech 2020 接收。

以 RNNT 损失函数训练的模型作为初始模型,本文在 MBR 训练过程中使用在线解码生成的 N 个最好假设 (Nbest) 作为假设空间,以最小化 Nbest 和标注序列之间的期望 Levenshtein 距离作为目标函数。同时为了能够将在更大规模文本数据训练得到的外部语言模型结合进 RNNT 端到端语音识别系统,文章探索并给出相应的策略将外部语言模型引入至 MBR 训练以及解码过程中以进一步提升性能。
作者在 21000 小时的工业级语料规模上进行实验,在采用基于卷积和 Transformer 结构的 SOTA RNNT 系统上,团队观察到 MBR 训练可以带来显著的识别性能提升,同时在 MBR 训练和解码时采用文中提出的方法与外部语言模型结合时性能又能有进一步提升。最后在内部口语以及朗读测试集上 MBR 训练以及外部语言模型结合带来的识别率提升分别在 1.2% 以及 0.5%。
RNNT 端到端语音识别系统由于系统占用空间小的特点非常适用于在终端上部署的语音识别服务场景,在此系统中端到端可以在离线环境下对用户提供高质量的语音识别服务。
以下为方案详细解读。
二、方案详解
基于 RNNT 的端到端神经网络由 Transcription (Encoder), Prediction (Decoder) 以及 Joint 神经网络组成。其中 Transcription 和 Prediction 网络往往都是采用长短时记忆单元(LSTM) 的循环神经网络结构。最近,以自注意力机制为核心的 Transformer 网络结构在传统以及端到端识别系统中与 LSTM 相比都有显著提升。作者首先对 RNNT 端到端神经网络结构每个部分都进行了改进,采取卷积以及 Transformer 混合的网络结构。如图一,Transcription 网络由三个基本模块堆叠而成,其中每个模块由三层时延神经网络 (TDNN) 及一层 Transformer 组成。Prediction 网络同样包含三个基本模块,每个模块包含一层一维因果卷积及一个 Transformer 层。Transcription 及 Prediction 网络具体配置见表一及表二。Joint 神经网络通常会采用前向神经网络建模 (Feedforward Network), 但实验发现采用 Gated Linear Units (GLU) 的 Joint 网络可以获得显著的性能提升。
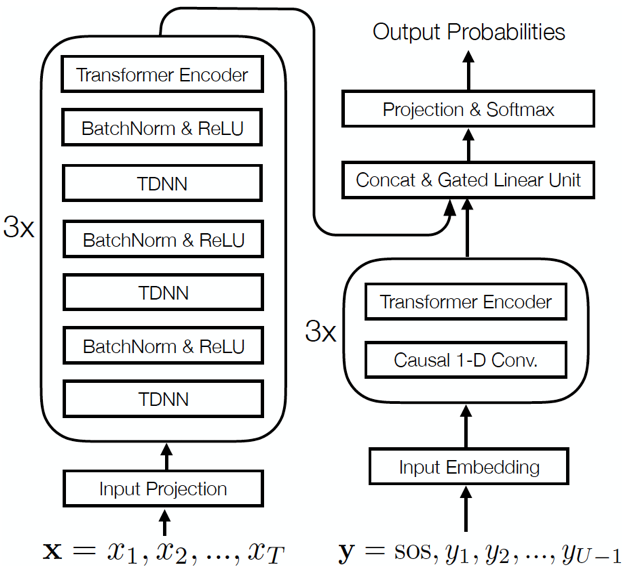
图一:本文采取 RNNT 网络结构
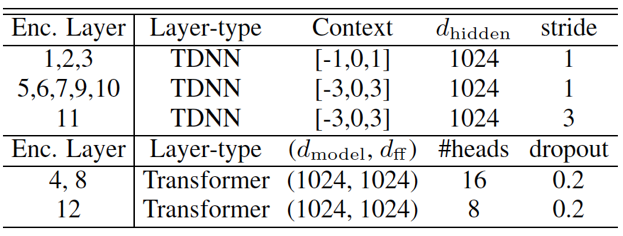
表一:Transcription(Encoder) 网络结构具体配置

表二:Prediction(Decoder) 网络结构具体配置
MBR 训练
如前文所提到的,MBR 训练的目标是将标注序列与 RNNT 模型在线解码生成 Nbest 之间的期望 Levenshtein 距离最小化,有了 MBR 训练的目标函数,为了进行 MBR 训练,还需要求出 MBR 目标函数针对 RNNT 网络输出节点的梯度。由于篇幅所限,对详细的数学推导过程感兴趣的读者可以阅读论文原文 [3] 。经过一系列的推导,可以得出 MBR 目标函数针对 RNNT 网络输出的梯度的具体形式,这个梯度形式就是作者进行 MBR 训练的数学基础。
外部语言模型结合
在端到端系统中常用的与外部语言模型结合的方法是 Shallow Fusion,其主要的思路就是在 RNNT 识别系统解码做 Beam search 时,将 RNNT 模型以及外部语言模型输出的得分做一个内插。然而对于 RNNT 端到端系统而言,不能做简单的内插,原因在于 RNNT 模型会输出一个额外的 blank 符号,而此符号在语言模型的输出中并不存在。为此本文提出一个 RNNT 模型与外部语言模型结合的策略,对于 RNNT 模型输出的 blank 概率保持不变,对于非 blank 概率输出部分,团队先和外部语言模型进行内插,为了保证最终的输出概率仍然保持概率分布的特性,需要对最终输出 RNNT 模型输出非 blk 概率进行归一化。具体的归一化细节可以参考论文原文 [3]。针对 RNNT 端到端系统做 MBR 训练附带的好处是可以在 RNNT 训练时引入外部语言模型的信息,由于在 MBR 训练时将 Beam Search 得到的 Nbest 作为假设空间,如果在 Beam Search 时使用上述介绍的办法结合外部的语言模型,很自然就可以将外部的语言模型信息引入至 RNNT 端到端模型的训练过程中。
实验结果
作者在 21000 小时的工业级语料规模上进行实验,测试集采用两个内部数据集,一个为包含朗读语音,另一个包含的是口语语音。从表三的第二行与第一行对比可以看到,文中提出的与外部语言模型结合的策略是有效的,在朗读的测试集上观察到了显著的提升。与基线 RNNT 系统相比较,本文提出的 MBR 训练在朗读和测试集上识别准别率分别提升了 0.6% 以及 0.4%。最后一行可以看到在内部口语以及朗读测试集上,同时在 MBR 训练以及解码时结合外部语言模型进行可以带来 1.2% 以及 0.5% 的识别率显著提升。
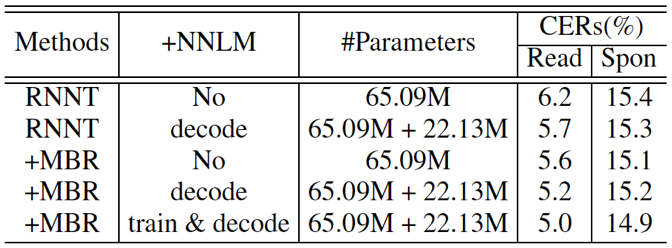
表三:RNNT 基线,MBR 训练,在解码和 MBR 训练时引入外部语言模型的错字率比较
三、总结及展望
本文提出的技术可以提升 RNNT 端到端语音识别系统的性能以及跨领域的鲁棒性,可以应用的场景包括在终端上部署的语音识别服务场景,在离线环境下对用户提供高质量的语音识别服务。
未来将进一步提升 MBR 训练的训练效率及稳定性,同时提出可以动态添加热词的外部语言模型结合算法,提升 RNNT 端到端识别系统在长尾词上的识别性能。
参考文献
1.R. Prabhavalkar, T. N. Sainath, P. N. Y. Wu, Z. Chen, C. Chiu, and A. Kannan, “Minimum word error rate training for attentionbased sequence-to-sequence models,” in ICASSP, 2018.
2.C. Weng, J. Cui, G. Wang, J. Wang, C. Yu, D. Su, and D. Yu, “Improving attention based sequence-to-sequence models for end-to-end english conversational speech recognition,” in Proc. Interspeech 2018, 2018, pp. 761–765.
3.C.Weng, C. Y, J. Cui, C. Zhang, D. Yu, " Minimum Bayes Risk Training of RNN-Transducer for End-to-End Speech Recognition", in Proc. Interspeech 2020




