
一、调度系统简介
Buffalo 调度系统是京东自主研发的分布式 DAG 作业调度系统,为京东的数据开发工程师、算法工程师、数据分析师等用户提供离线作业的编排与调试、监控运维、DAG 调度等功能。其目标是打造行业领先的稳定高效、产品简洁高体验、任务监控全面、资源容器化、系统能力开放化的 ETL 调度系统。
京东调度系统的核心挑战包括:
业务复杂导致的依赖关系复杂:复杂的数据链路使得部分任务有数百甚至上千个上下游,层级多达数十层。跨天依赖、数据回刷、月度汇总等业务场景使任务间的依赖关系形成一个庞大且复杂的有向无环图(DAG)。
业务体量大且稳定性和性能要求高:当前平台拥有数十万任务,百万级依赖关系,日均百万级调度频次。任务关系复杂、执行量大,系统的任何细微异常都可能导致数据链路异常,核心数据受损,对调度系统的稳定性和性能提出了巨大挑战。
数据加工场景复杂需要支持丰富的调度能力:平台支持多个 BG 业务,涉及数据采集、计算、推送、转换等多种任务类型、多种执行方式、多种触发规则,以及任务间的数据传递、数据补录等场景,对系统功能的丰富度和灵活度提出了新的要求。
二、核心技术方案
为支撑灵活的业务加工和工作流编排,快速应对业务发展带来的任务量增长,并保障系统的稳定性,我们在易用性、稳定性和高性能方面做了很多优化。以下将从这三个方面详细介绍。
1. 实体和编排调度模型
a) 双层实体模型
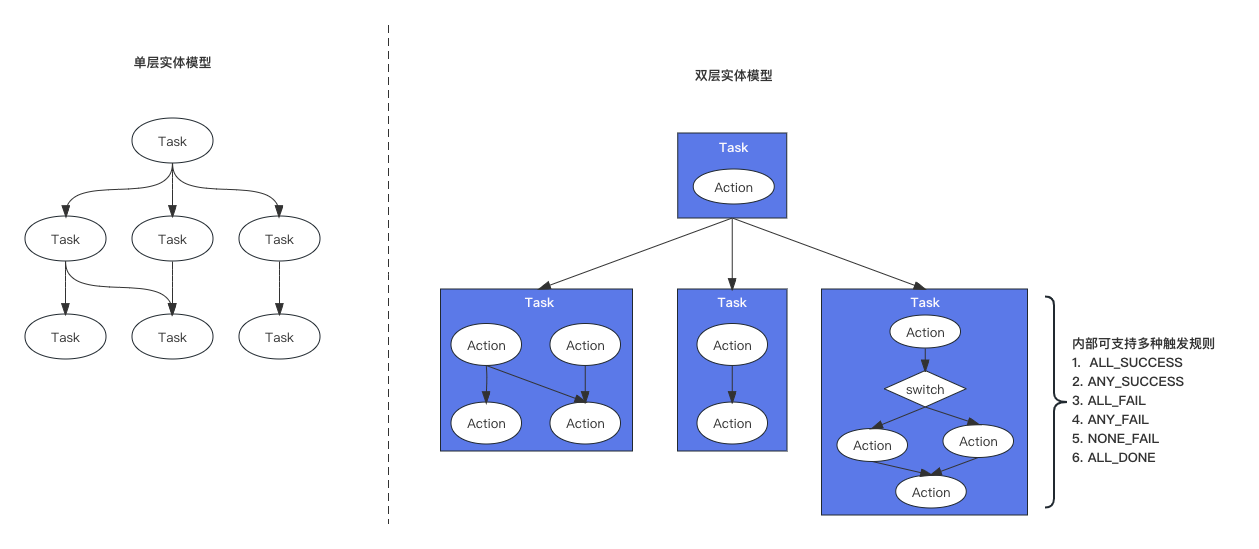
采用主流的双层实体模型,包含两个核心概念:
Action(环节):最小粒度的执行单位,携带执行相关的信息,如脚本、参数、环境等。
Task(任务):由一个或多个环节和触发规则构成的 DAG,Task 之间也可以相互依赖,形成外层 DAG,实现双层调度。
相比单层实体模型,双层模型具有更强的编排能力和灵活性,同时对单个业务的整合和管理也更友好。
b) 基于实例的调度
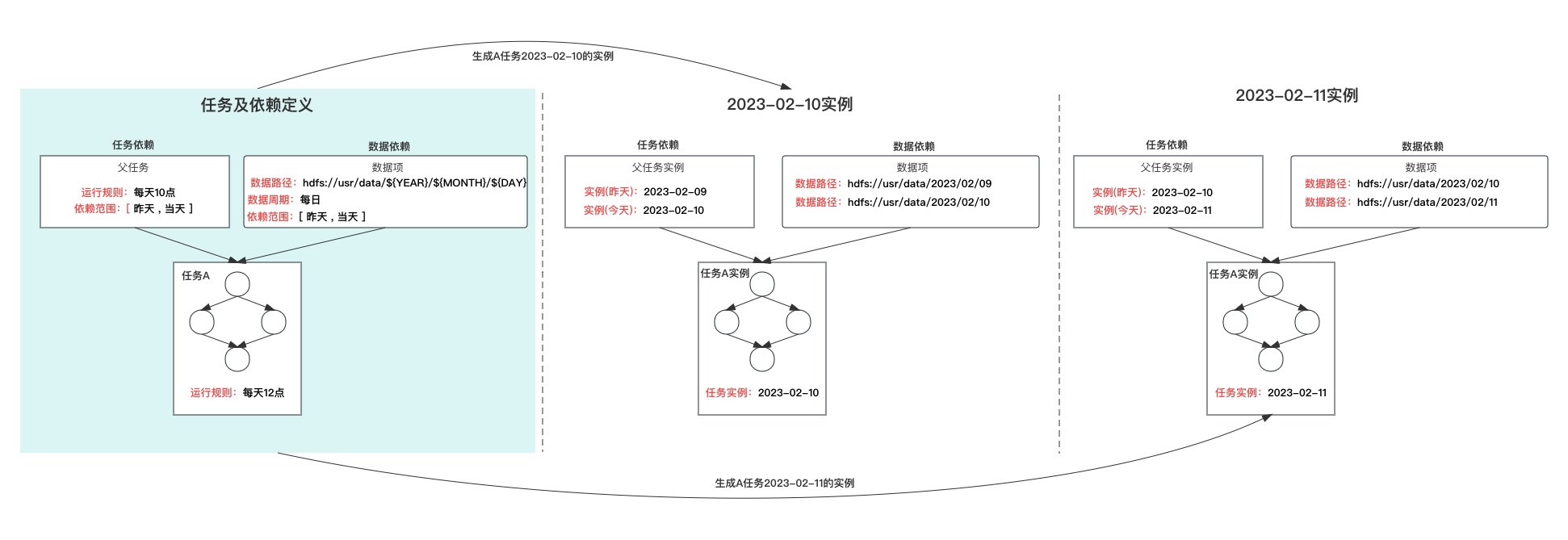
任务定义是任务配置的载体,无状态、不可执行。当任务达到运行周期时,会产生相应周期的任务实例(实例化过程)。实例化时会根据任务的配置信息(环节、上游依赖、数据依赖、运行周期等)生成当前周期实例,实例是真正可执行并具有状态的对象。
基于实例的调度模式优点包括:
周期稳定:每个周期都会有实例,不会出现周期缺失的情况,且每个周期的实例可独立操作。
依赖明确:任务实例的依赖关系明确且可预期,可以快速追溯和修复问题。
c) 分类分级调度能力
平台提供任务分类分级管理和基于分级的调度能力,确保在资源紧张时优先保障重要业务。同时任务等级信息会传递到底层集群,底层计算集群增加相应保障策略,确保核心业务的稳定性。
2. 高可用架构
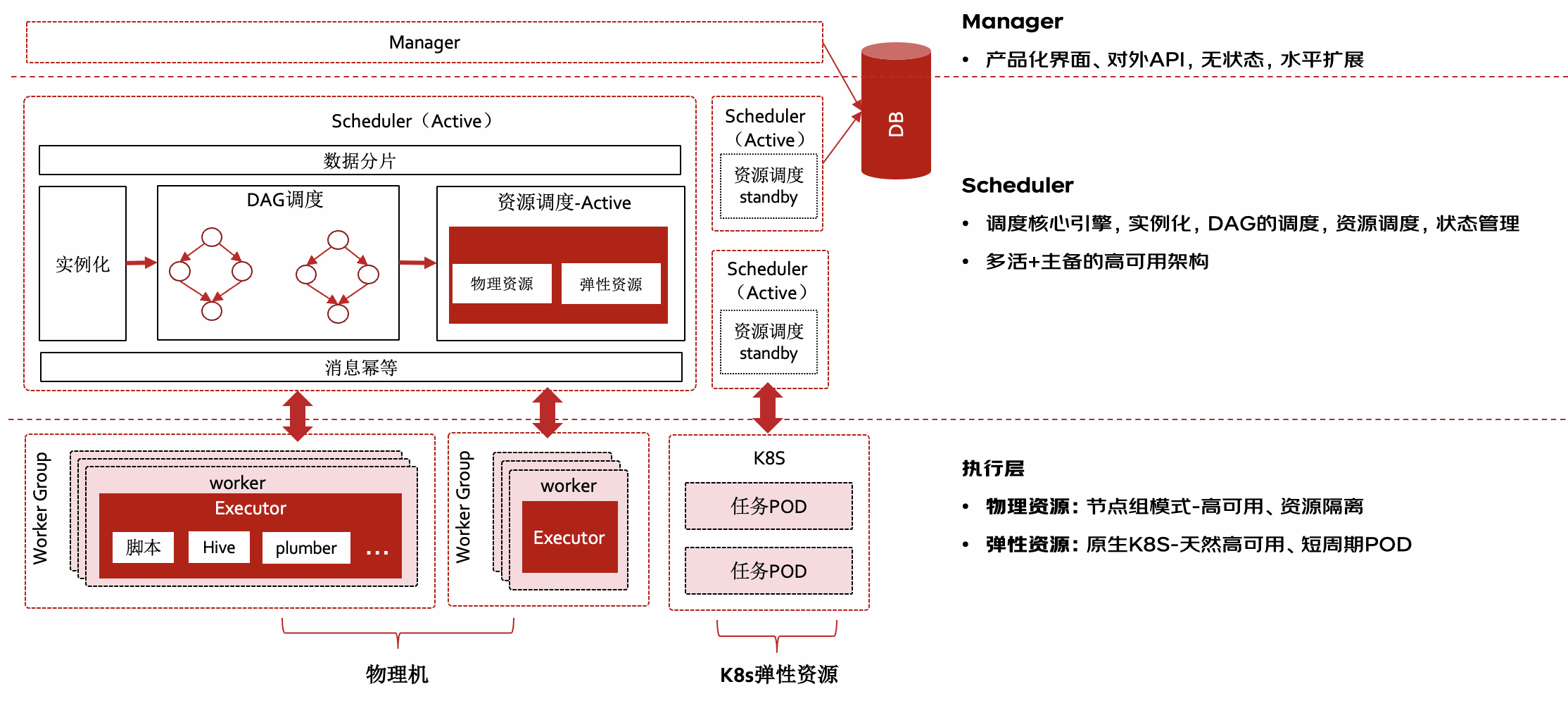
Buffalo 整体分为三层,每层具备高可用架构,确保系统的高可用和容灾能力:
Manager 管理层:提供任务创建、管理和运维功能,管理端无状态,可横向扩展。
高可用 Scheduler:作为核心调度引擎,负责任务实例的生成和调度,采用多活+主备架构,保障任务执行的唯一性和高效性。多个 scheduler 会通过数据分片负载处理任务,同时对于任务状态消息进行幂等处理,其中资源调度模块采用主备模式,以便支撑灵活和高效的资源调度能力。当一个节点故障时,其他节点会监测到节点下线,并自动触发接管逻辑,将异常节点任务接管处理,保障故障节点上的任务执行不受影响。
容错执行层:负责任务启动和执行,支持物理机和基于 K8s 的容器化资源,具备高可用特性和灵活的资源管理能力。
▪ 物理机:部署 worker(也称 TaskNode)长进程,任务以独立进程方式运行,多个 worker 构成节点组对(虚拟节点)外服务,避免单点故障问题。同时 worker 本身支持消息重传、cgroup 资源隔离等高可用特性。
▪ k8s 弹性资源:与原生 k8s 对接,任务以短周期 pod 方式执行,任务结束时 pod 销毁,天然具备高可用特性,同时具备更精细化的资源管理、差异化执行环境的动态构建能力。
3. 高性能
为应对任务量增长和业务复杂度提升,Buffalo 通过以下方式实现高容量、低延迟的编排和调度:
a) 水平扩展
调度引擎采用多活架构,通过数据哈希分片将任务负载分布到多台服务进行调度,保障任务执行的唯一性。
b) 事件驱动
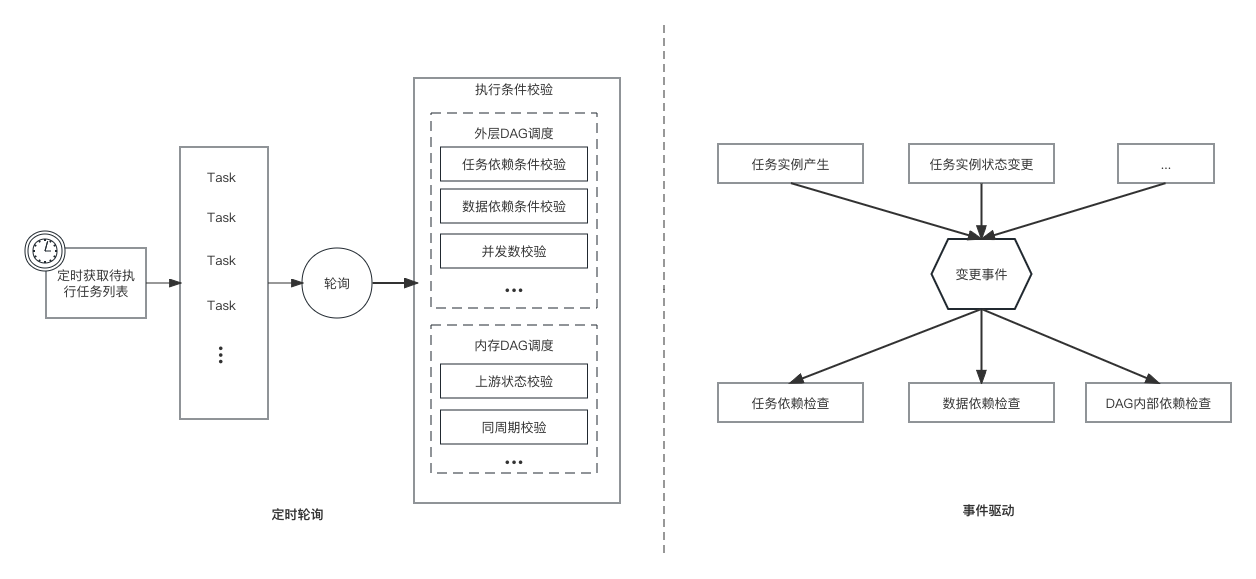
相较传统的定时轮询方式,事件驱动模式在任务依赖条件变更时进行条件计算和校验,避免了遍历耗时和无用计算,提高整体处理性能。
c) 内存调度
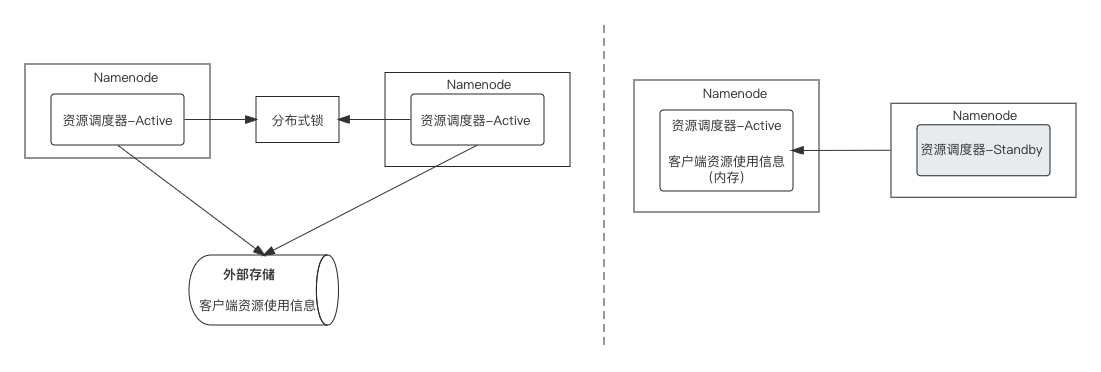
前面提到 Buffalo 具备在物理机集群和 k8s 集群上启动任务执行的能力,所以需要具备这两种资源的管理和资源调度能力,资源调度的性能也是影响任务分发时效的关键部分。
调度引擎 namenode 采用的是多活的高可用架构,如果资源调度部分也采用该架构(如左图),那么涉及到同一资源的并发访问和修改的问题,进而引入分布式锁和外部存储,这样整体的性能很难达到理想的目标。
因此,我们在 namenode 多活架构的基础上,将资源调度部分做了一个主备架构的处理(如右图),会从多个 namenode 里选择一个作为主资源调度器,其他作为热备,所有 namenode 的任务资源请求都由主节点进行处理,这样主节点在内存中保存了所有的资源信息,资源调度过程在内存中就可进行,避免了分布式锁和对外部存储的依赖,性能有大幅提升。
d) 冷热数据分离
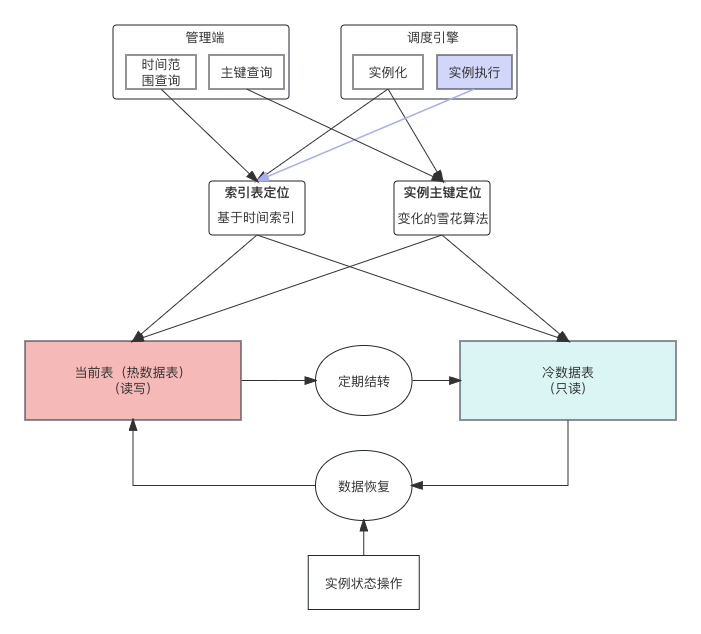
当系统中任务量较大,任务执行产生的实例数据会快速增长,buffalo 每日的实例数据增量超过百万,随着任务量的增长还会持续增长,如果没有适当的方案来处理,数据库很难支撑如此快速的数据增长。
调度系统中的任务有个明显特征 - 定时,就是任务会定时执行,执行完成后的实例,除人为干预外其状态不会再自动发生变更,这部分数据一般只会做查询,所以这部分数据可以做独立存储。我们将状态还会发生变更或频繁操作的数据称作热数据,将这些已经执行结束且基本只有查询需求的数据称作冷数据,并将冷数据单独存储。
当冷热数据分离后,有三个核心问题需要解决:
1)数据结转
任务实例执行完成,处于结束状态的实例都可以被结转,目前采用定时结转的策略。为避免冷数据单表数据量过大,结转规则可以按照季度、月或则更小周期进行拆分存储。
2) 数据定位
当数据结转到冷数据表后,这些实例的状态不会发生变更,单可能还会被未执行的实例所依赖,用户也可能会对这些实例做检索操作,所以这些实例需要能从冷数据表中快速被定位。
•索引表:数据结转到冷数据表时,会根据冷数据表的分区粒度,在索引表记录各冷分区表中的数据范围,如计划运行时间在 2023-01-01 至 2023-03-31 的数据存储在 2023Q1 分区表,这样基于时间的范围查询场景,可快速定位。
•主键定位:为了能够根据任务实例主键快速定位,我们参照雪花算法,做了一定的调整,根据任务实例计划运行时间、当前时间、以及 namenode id 等信息,构建顺序增长的 long 型 id,当给定主键,可从中解析计划运行时间,从而快速定位所在分区。
3)冷数据操作
冷数据被操作的几率比较低,但也存在操作的可能性,比如历史实例的重跑、强制成功等操作。为了保持调度引擎架构的简单性,所有相关的任务执行的处理,都是基于当前表(热表),所以为了能保障被结转的冷数据和热数据一样支持所有操作,冷数据被操作时会从冷数据表恢复至热数据表,从而实现与热数据相同的效果。
4. 开放能力
开放 API:通过 HTTP 协议提供任务配置管理、任务实例操作、状态查询和日志查询等能力。
开放事件:基于 JDQ 异步消息方式,将任务状态和实例状态开放给业务系统,实现状态变更的及时同步。
三、未来规划
Buffalo 调度系统将持续优化和迭代升级,提供更好的用户体验和极致性能,包括容器化能力、插件化扩展能力、开放能力和精细化资源管理能力。希望大家提出更多的想法和建议,共同打造稳定、高效、易用的调度平台。




