
5 月 13 日,在零一万物成立一周年之际,低调许久的创始人李开复首度现身,阐述了零一万物这一年在大模型和商业化方面的进展和思考。
发布会上,李开复发布了千亿参数 Yi-Large 闭源模型,公开了开源闭源双轨大模型的战略布局。李开复透露,大模型从训练到服务都很昂贵,算力紧缺是赛道的集体挑战,行业应当共同避免陷入不理性的 ofo 式流血烧钱打法,让大模型能够用健康良性的 ROI 蓄能长跑。零一万物的主要精力则在全球化布局、模基共建、模应一体、和 AI-First 四个方面。
大模型策略:开、闭源并行

在大模型方面,李开复表示,零一万物将实行“开源+闭源”的双轨模型策略:以开源模型构建生态、以闭源模型展开 AI-First 商业探索。
本次发布会上,零一万物重磅推出了全球 SOTA 千亿参数闭源大模型 Yi-Large,评测超越 GPT-4。
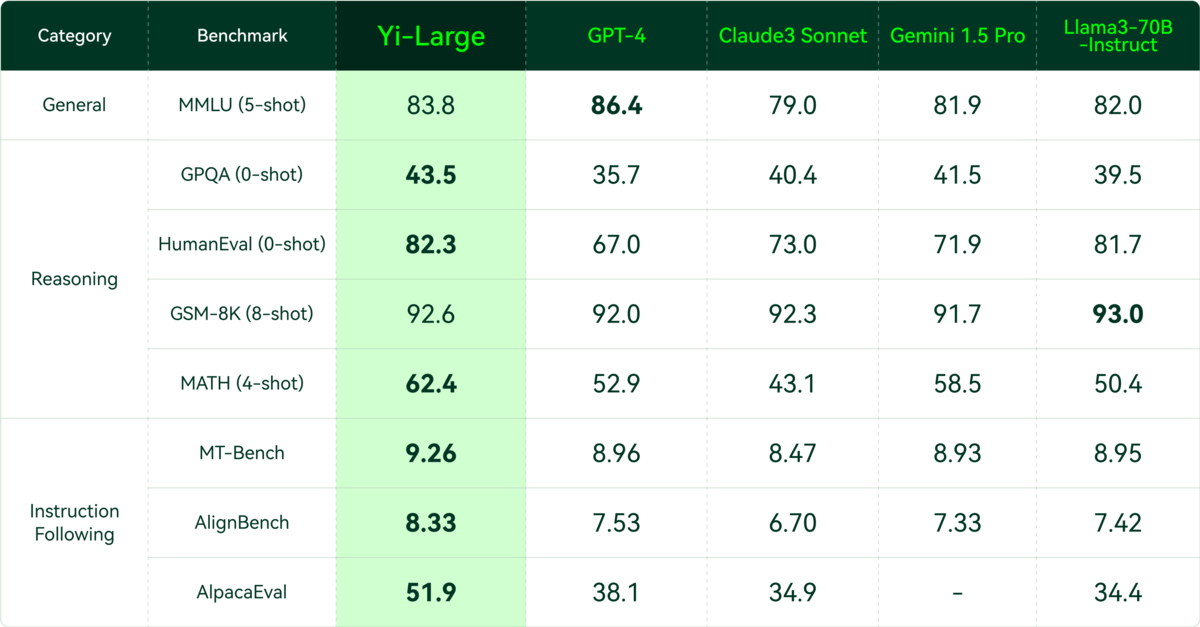
在最新出炉的斯坦福评测机构 AlpacaEval 2.0 经官方认证的模型排行榜上,Yi-Large 模型的英语能力主要指标 LC Win Rate(控制回复的长度) 排到了世界第二,仅次于 GPT-4 Turbo,Win Rate 排到了世界第一位,此前国内模型中仅有 Yi 和 Qwen 曾经登上此榜单的前 20。
斯坦福 AlpacaEval 2.0 Verified 认证模型类别,英语能力评测(2024 年 5 月 12 日)
在中文能力方面,SuperCLUE 更新的四月基准表现中,Yi-Large 的中文语言理解能力位列国产大模型之首。
在更全面的大模型综合能力评测中,Yi-Large 多数指标超越 GPT4、Claude3、Google Gemini 1.5 等同级模型,达到首位。在通用能力、代码生成、数学推理、指令遵循方面都取得了优于全球领跑者的成绩,跻身世界范围内的第一梯队。
值得注意的是,上述评测均是在零样本(0-shot)或少样本(4-shot/5-shot/8-shot)的前提下进行。在零样本或少样本的情况下,模型必须依赖于其在大量数据上训练时获得的知识和推理能力,而不是简单地记忆训练数据。这最大程度上避免了刷分的可能性,能更加客观真实地考验模型的深层次理解和推理能力。
此外,从行业落地的角度来看,理解人类指令、对齐人类偏好已经成为大模型不可或缺的能力,指令遵循(Instruction Following)相关评测也越发受到全球大模型企业重视。斯坦福开源评测项目 AlpacaEval 和伯克利 LM-SYS 推出的 MT-bench 是两组英文指令遵循评测集,AlignBench 则是由清华大学的团队推出的中文对齐评测基准。在中外权威指令遵循评测集中,Yi-Large 的表现均优于国际前五大模型。
发布会上,李开复博士还宣布,零一万物已启动下一代 Yi-XLarge MoE 模型训练,冲击 GPT-5 的性能与创新。
根据零一万物透露的情况,从 MMLU、GPQA、HumanEval、MATH 等权威评测集中,仍在初期训练中的 Yi-XLarge MoE 已经与 Claude-3-Opus、GPT4-0409 等国际厂商的最新旗舰模型互有胜负,训练完成后的性能令人期待。
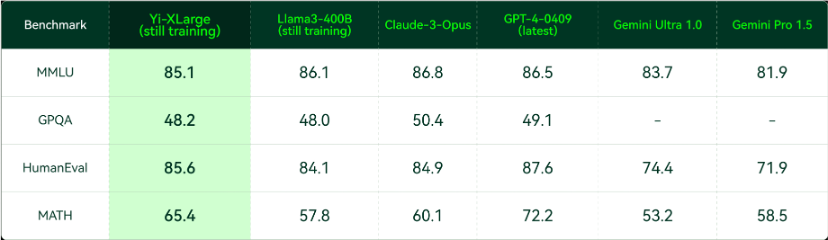
Yi-XLarge 初期训练中评测(2024 年 5 月 12 日)
此外,零一万物 Yi 系列开源模型也迎来全面升级,Yi-1.5 分为 34B、9B、6B 三个版本,且提供了 Yi-1.5-Chat 微调模型可供开发者选择。
开源地址
Hugginf Face:https://huggingface.co/01-ai
魔搭社区: https://www.modelscope.cn/organization/01ai
根据介绍,经过微调后的 Yi-1.5-6B/9B/34B-Chat 在数学推理、代码能力、指令遵循等方面更上一层楼。Yi-1.5-6B/9B-Chat 在 GSM-8K 和 MATH 等数学能力评测集、HumanEval 和 MBPP 等代码能力评测集上的表现远同参数量级模型,也优于近期发布的 Llama-3-8B-Instruct;在 MT-Bench、AlignBench、AlpacaEval 上的得分在同参数量级模型中也处于领先位置。
Yi-1.5-34B-Chat 在数学能力同样保持着大幅领先,代码能力与超大参数量级的 Mixtral-8x22B-Instruct-v0.1 持平,指令遵循方面更是在 MT-Bench、Alignbench、ArenaHard、AlpacaEval2.0 等多个权威评测集上完全超越了 Mixtral-8x22B-Instruct-v0.1。
李开复分享了一个开源方向的公益项目:小胰宝。通过问答的形式,基于零一万物 Yi 大模型的小胰宝 AI 小助手可以 7x24 小时为患者介绍综合治疗知识。使用 Yi API 调用 AI 大模型后,小胰宝突破了胰腺肿瘤治疗信息壁垒,可将胰腺癌治疗路线图和治疗方案精准且系统性地呈现给胰腺肿瘤病友。
据悉,目前该公益项目已经帮助了 3000 多位胰腺肿瘤病友,AI 小助手在病历和报告解读的准确率也有显著提升,已被某国家级权威三甲医院推荐。
发布会上,零一万物还面向国内市场一次性发布了包含 Yi-Large、Yi-Large-Turbo、Yi-Medium、Yi-Medium-200K、Yi-Vision、Yi-Spark 等多款模型 API 接口,保证客户能够在不同场景下都能找到最佳性能、最具性价比的方案,Yi API Platform 英文站同步对全球开发者开放试用申请。

Yi 大模型 API 开放平台:
https://platform.lingyiwanwu.com/
商业进展:海外单款产品今年预计收入超 1 亿
在移动互联网的鼎盛时期,PMF(Product-Market Fit,产品市场契合)曾是众多初创企业追求的核心目标。然而,随着大语言模型成为新的创业焦点,李开复认为,PMF 这一概念已经不能完整定义以大模型为基础的 AI-First 创业,应当引入 Technology(技术)与 Cost(成本)组成四维概念——TC-PMF。

李开复解释道,在大模型时代,模型训练和推理成本构成了每一个创业公司必须要面临的增长陷阱。用户增长需要优质的应用,而优质应用离不开强大的基座模型,强大基座模型的背后往往是高昂的训练成本,接着还需要考虑随用户规模增长的推理成本。这一普惠点如何达成、何时到来变得越发难以捉摸。
“做 Technology-Cost Product-Market-Fit(TC-PMF),技术成本 X 产品市场契合度,尤其推理成本下降是个‘移动目标’,这比传统 PMF 难上一百倍。” 李开复表示。
模应一体:初步跑通 TC-PMF,全球市场打磨造血能力
零一万物的海外生产力应用,已验证 TC- PMF。
去年 9 月开始,零一万物聚焦生产力、社交赛道于海外应用展开探索,已有 4 款产品陆续上线。李开复表示,目前零一万物海外生产力应用总用户接近千万,单款产品营收今年预期超过一亿人民币,已实践出大模型 2C 产品的 TC-PMF——产品 ROI 为 1,初步摆脱烧钱获客,成功验证了 AI-First 产品的用户订阅制商业模式。
由于海外市场与国内市场在付费意愿、市场环境方面存在差异,目前万知采取限时免费模式。但据零一万物生产力产品负责人曹大鹏介绍,后续万知会结合产品发展和用户反馈推出收费模式。
李开复博士表示,ofo 式的补贴逻辑不再适用于 AI 2.0,采用以资金“跑马圈地”商业模式的企业必然会率先力竭,冷静判断行业发展进程,脚踏实地打磨 TC-PMF 才是更符合长期主义的路线。“这场较量将包含模型、AI Infra、产品应用等三位一体多个方面,零一万物已经做足准备。”
大模型进入第二年,行业进入更为现实的商业落地阶段,客户/用户都会按照应用侧所展现的能力,用脚投票。如何基于基座模型能力,尽可能提升应用效果,是零一万物追赶 TC-PMF 的重要课题。
无论是 2C 还是 2B,“模应一体”的思路始终贯穿零一万物的商业实践——模型团队与产品团队紧密结合,摸清模型能力边界,针对某一应用场景去优化专有模型,并最终实现全球范围内的弯道超车。
“AI-First 不等于 AI Only,”曹大鹏表示,“模型、工程、算法、产品要基于场景深度结合,模型长板匹配刚需高价值场景,构建 AI-First 工作流,追求极致体验、一站式解决用户问题,而不是单纯秀模型能力肌肉,拿锤子找钉子。”
刚发布不久的“万知”是零一万物对这一理念的证明。从职场人“找、读、写” 的三大需求切入办公场景,AI 助力下,文件撰写提效超 10 倍,低专业判断的日常任务节约时间超 8 成,联网生成回答、PPT 速率远超行业平均水平。万知还将多模态能力与 PDF 文档阅读场景相结合,解决 PDF 文档中大量图表无法识别的痛点。
在零一万物 API 平台负责人蓝雨川看来,已经在海外充分得到商业模式验证的 API 会是更好的选择。作为标准化产品的 API 复用性更强,商业模式也更趋近于云服务。比起 AI 1.0 定制化重交付的模式,API 能够更快穿透千行百业,蓝雨川表示,零一万物提供世界第一梯队的模型、最佳性价比的方案,聚焦企业如何用 AI 为自身业务带来增长。
API 与万知等 C 端应用共同构建起了零一万物的商业落地版图,也成为零一万物追逐 TC-PMF 的重要实践。在李开复的规划中,零一万物将作为具有前瞻性的务实者一步步实现落地,并最终达到 TC-PMF,打造出 AI 2.0 时代的超级应用,实现让通用人工智能普惠各地,人人受益。
模基共建:模型和 Infra 团队高度共建,训练算力利用率领先
一个不容忽视的事实在于,中国大模型公司没有美国大厂的 GPU 数量,所以必须采取更务实的战术和战略。
AI Infra(AI Infrastructure 人工智能基础架构技术)主要涵盖大模型训练和部署提供各种底层技术设施,在李开复看来,自研 AI Infra 是零一万物必然要走过的路,零一万物也自成立起便将 AI Infra 设立为重要方向。
“第一年大模型行业在卷算法,第二年大家在卷算法 + Infra。在国外一线大厂,最高效训练模型的方式是算法与 Infra 共建,不仅仅关注模型架构,而是从优化底层训练方法出发。”零一万物模型训练负责人黄文灏表示,“这对大模型人才的知识能力提出了全新要求。”
目前来看,模型研究人员只关注算法而忽视 AI Infra 是国内大模型行业现状。而零一万物选择跟国际一线梯队齐平,模型团队和 AI Infra 团队高度共建,人数比为 1:1。“我们要求做模型研究的人一定要‘往下沉淀’,具备工程能力。这也对齐我们倡导的 TC-PMF 的方法论。”黄文灏说。
零一万物团队在计算效率优化方面取得了显著进展。据了解,零一万物 Yi-Large 训练环节的平均 MFU(Model Flops Utilization,模型算力利用率)已显著超越业内平均水平。多方面优化后,零一万物千亿参数模型的训练成本同比降幅达一倍之多。
今年 3 月,零一万物推出了基于全导航图的新型向量数据库笛卡尔(Descartes),其搜索内核已包揽权威榜单 ANN-Benchmarks 6 项数据集评测第一名。同样于 3 月,零一万物成功在 Nvidia GPU 上进行了千亿参数模型 Yi-Large 的端到端 FP8 训练和推理,成为全球率先落地该技术的三个案例之一。
底层技术的突破带来了优化成本的新可能。接入自研向量数据库后,零一万物的 C 端应用在保证响应速率与准确性的前提下,成本大幅降至了原用第三方向量数据库时的 18%。在端到端 FP8 训练的前提下,零一万物能够采用技术和工程手段得到与更高精度类型相媲美的训练结果,与此同时模型训练所需的显存占用、通讯带宽都极大降低。
结束语
面对大模型市场的竞争,李开复表示,“在美国市场,大部分的认知是超大模型可能会只有少数几家公司能够训练,但是他们需要用天价(成本)来做底座,那么其他的人已经开始在寻找别的解决方案,比如怎么做一个尺寸更合适、更能够达到普惠应用的 AI,这也是我们的方向。”
“AGI 就是我的梦想,今天有实现梦想的机会,这才是催化我努力的主要动力。至于变现,我跟我的投资人一年前做了一个承诺,就是我 10 年不套现。对于创始团队,我们会通过各种手段让他们合理套现。我认为套现最好的方式是赶快上市,这是我们未来努力的方向。”李开复说道。




