
本文要点
大数据应用程序开发人员在从 Hadoop 文件系统或 Hive 表读取数据时遇到了挑战。
合并作业(一种用于将小文件合并为大文件的技术)有助于提高读取 Hadoop 数据的性能。
通过合并,文件的数量显著减少,读取数据的查询时间更短。
当通过 map-reduce 作业读取 Hive 表数据时,Hive 调优参数也可以帮助提高性能。
Hive表是一种依赖于结构化数据的大数据表。数据默认存储在 Hive 数据仓库中。为了将它存储在特定的位置,开发人员可以在创建表时使用 location 标记设置位置。Hive 遵循同样的 SQL 概念,如行、列和模式。
在读取 Hadoop 文件系统数据或 Hive 表数据时,大数据应用程序开发人员遇到了一个普遍的问题。数据是通过spark streaming、Nifi streaming作业、其他任何流或摄入程序写入 Hadoop 集群的。摄入作业将大量的小数据文件写入 Hadoop 集群。这些文件也称为 part 文件。
这些 part 文件是跨不同数据节点写入的,如果当目录中的文件数量增加时,其他应用程序或用户试图读取这些数据,就会遇到性能瓶颈,速度缓慢。其中一个原因是数据分布在各个节点上。考虑一下驻留在多个分布式节点中的数据。数据越分散,读取数据的时间就越长,读取数据大约需要“N *(文件数量)”的时间,其中 N 是跨每个名字节点的节点数量。例如,如果有 100 万个文件,当我们运行 MapReduce 作业时,mapper 就必须对跨数据节点的 100 万个文件运行,这将导致整个集群的利用率升高,进而导致性能问题。
对于初学者来说,Hadoop 集群有多个名字节点,每个名字节点将有多个数据节点。摄入/流作业跨多个数据节点写入数据,在读取这些数据时存在性能挑战。对于读取数据的作业,开发人员花费相当长的时间才能找出与查询响应时间相关的问题。这个问题主要发生在每天数据量以数十亿计的用户中。对于较小的数据集,这种性能技术可能不是必需的,但是为长期运行做一些额外的调优总是好的。
在本文中,我将讨论如何解决这些问题和性能调优技术,以提高 Hive 表的数据访问速度。与 Cassandra 和 Spark 等其他大数据技术类似,Hive 是一个非常强大的解决方案,但需要数据开发人员和运营团队进行调优,才能在对 Hive 数据执行查询时获得最佳性能。
让我们先看一些 Hive 数据使用的用例。
用例
Hive 数据主要应用于以下应用程序:
大数据分析,就交易行为、活动、成交量等运行分析报告;
跟踪欺诈活动并生成有关该活动的报告;
基于数据创建仪表板;
用于审计和存储历史数据;
为机器学习提供数据及围绕数据构建智能
优化技术
有几种方法可以将数据摄入 Hive 表。摄入可以通过 Apache Spark 流作业、Nifi 或任何流技术或应用程序完成。摄入的数据是原始数据,在摄入过程开始之前考虑所有调优因素非常重要。
组织 Hadoop 数据
第一步是组织 Hadoop 数据。我们从摄入/流作业开始。首先,需要对数据进行分区。数据分区最基本的方法是按天或小时划分。甚至可以同时拥有按天和按小时的分区。在某些情况下,在按天划分的分区里,你还可以按照国家、地区或其他适合你的数据和用例的维度进行划分。例如,图书馆里的一个书架,书是按类型排列的,每种类型都有儿童区或成人区。

图 1:组织好的数据
以此为例,我们像下面这样向 Hadoop 目录中写入数据:
hdfs://cluster-uri/app-path/category=children/genre=fairytale ORhdfs://cluster-uri/app-path/category=adult/genre=thrillers这样,你的数据就更有条理了。大多数时候,在没有特殊需求的情况下,数据按天或小时进行分区:
hdfs ://cluster-uri/app-path/day=20191212/hr=12或者只根据需要按天分区:
hdfs://cluster-uri/app-path/day=20191212
图 2:分区文件夹摄入流
Hadoop 数据格式
在创建 Hive 表时,最好提供像 zlib 这样的表压缩属性和 orc 这样的格式。在摄入的过程中,这些数据将以这些格式写入。如果你的应用程序是写入普通的 Hadoop 文件系统,那么建议提供这种格式。大多数摄入框架(如 Spark 或 Nifi)都有指定格式的方法。指定数据格式有助于以压缩格式组织数据,从而节省集群空间。
合并作业
合并作业在提高 Hadoop 数据总体读取性能方面发挥着至关重要的作用。有多个部分与合并技术有关。默认情况下,写入 HDFS 目录的文件都是比较小的 part 文件,当 part 文件太多时,读取数据就会出现性能问题。合并并不是 Hive 特有的特性——它是一种用于将小文件合并为大文件的技术。合并技术也不涉及任何在线的地方,因此,这项特定的技术非常重要,特别是批处理应用程序读取数据时。
什么是合并作业?
默认情况下,摄入/流作业写入到 Hive,目录写入比较小的 part 文件,对于高容量应用程序,一天的文件数将超过 10 万个。当我们试图读取数据时,真正的问题来了,最终返回结果需要花费很多时间,有时是几个小时,或者作业可能会失败。例如,假设你有一个按天分区的目录,你需要处理大约 100 万个小文件。例如,如果运行 count,输出如下:
#Before:hdfs dfs -count -v /cluster-uri/app-path/day=20191212/*Output = 1Million现在,在运行合并作业之后,文件的数量将显著减少。它将所有比较小的 part 文件合并成大文件。
#After:hdfs dfs -count -v /cluster-uri/app-path/day=20191212/*Output = 1000注意:cluster-uri 因组织而异,它是一个 Hadoop 集群 uri,用于连接到特定的集群。
合并作业有什么好处?
文件合并不仅是为了性能,也是为了集群的健康。根据 Hadoop 平台的指南,节点中不应该有这么多文件。过多的文件会导致读取过多的节点,进而导致高延迟。记住,当读取 Hive 数据时,它会扫描所有的数据节点。如果你的文件太多,读取时间会相应地增加。因此,有必要将所有小文件合并成大文件。此外,如果数据在某天之后不再需要,就有必要运行清除程序。
合并作业的工作机制
有几种方法可以合并文件。这主要取决于数据写入的位置。下面我将讨论两种不同的常见的用例。
使用 Spark 或 Nifi 向日分区目录下的 Hive 表写入数据
使用 Spark 或 Nifi 向 Hadoop 文件系统(HDFS)写入数据
在这种情况下,大文件会被写入到日文件夹下。开发人员需要遵循下面的某个选项。
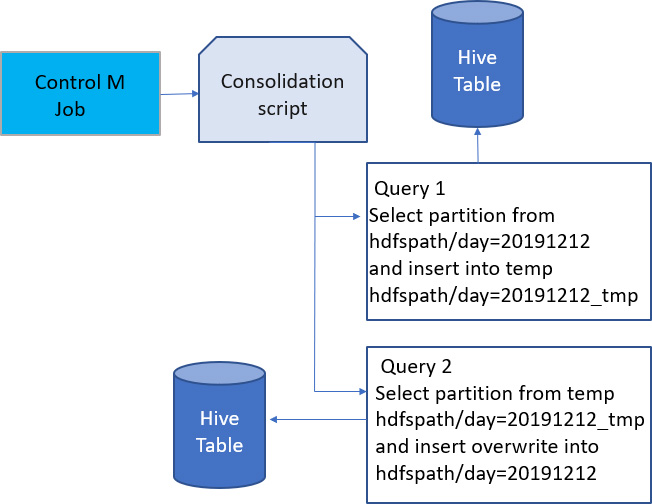
图 3:合并逻辑
编写一个脚本来执行合并。该脚本接受像天这样的参数,在同一分区数据中执行 Hive select 查询数据,并在同一分区中 insert overwrite。此时,当 Hive 在同一个分区上重写数据时,会执行 map-reduce 作业,减少文件数量。
有时,如果命令失败,在同一命令中重写相同的数据可能会导致意外的数据丢失。在这种情况下,从日分区中选择数据并将其写入临时分区。如果成功,则使用 load 命令将临时分区数据移动到实际的分区。步骤如图 3 所示。
在这两个选项中,选项 B 更好,它适合所有的用例,而且效率最高。选项 B 很有效,因为任何步骤失败都不会丢失数据。开发人员可以编写一个 control M,并安排它在第二天午夜前后没有活跃用户读取数据时运行。
有一种情况,开发者不需要编写 Hive 查询。相反,提交一个 spark 作业,select 相同的分区,并 overwrite 数据,但建议只有在分区文件夹中文件数量不是很大,并且 spark 仍然可以读取数据而又不需要指定过多的资源时才这样做。这个选项适合低容量的用例,这个额外的步骤可以提高读取数据的性能。
整个流程是如何工作的?
让我们通过一个示例场景来回顾上述所有的部分。
假设你拥有一个电子商务应用程序,你可以根据不同的购买类别跟踪每天的客户量。你的应用容量很大,你需要基于用户购买习惯和历史进行智能数据分析。
从表示层到中间层,你希望用Kafka或 IBMMQ发布这些消息。下一步是有一个流应用程序,消费 Kafka/MQ 的数据,并摄取到 Hadoop Hive 表。这可以通过 Nifi 或 Spark 实现。在此之前,需要设计和创建 Hive 表。在创建 Hive 表的过程中,你需要决定分区列什么样,以及是否需要排序或者使用什么压缩算法,比如Snappy或者Zlib。
Hive 表的设计是决定整体性能的一个关键方面。你在设计时必须考虑如何查询数据。如果你想查询每天有多少顾客购买了特定类别的商品,如玩具、家具等,建议最多两个分区,如一个天分区和一个类别分区。然后,流应用程序摄取相应的数据。
提前掌握所有可用性方面的信息可以让你更好地设计适合自己需要的表。因此,对于上面的例子,一旦数据被摄取到这个表中,就应该按天和类别进行分区。
只有摄入的数据才会形成 Hive location 里的小文件,所以如上所述,合并这些文件变得至关重要。
下一步,你可以设置调度程序或使用 control M(它将调用合并脚本)每天晚上运行合并作业,例如在凌晨 1 点左右。这些脚本将为你合并数据。最后,在这些 Hive location 中,你应该可以看到文件的数量减少了。
当真正的智能数据分析针对前一天的数据运行时,查询将变得很容易,而且性能会更好。
Hive 参数设置
当你通过 map-reduce 作业读取 Hive 表的数据时,有一些方便的调优参数。要了解更多关于这些调优参数的信息,请查阅Hive调优参数。
Set hive.exec.parallel = true;set hive.vectorized.execution.enabled = true;set hive.vectorized.execution.reduce.enabled = true;set hive.cbo.enable=true;set hive.compute.query.using.stats=true;set hive.stats.fetch.column.stats=true;set hive.stats.fetch.partition.stats=true;set mapred.compress.map.output = true;set mapred.output.compress= true;Set hive.execution.engine=tez;要进一步了解其中的每个属性,可以参考这个教程。
技术实现
现在,让我们用一个示例场景,一步一步地进行展示。在这里,我正在考虑将客户事件数据摄取到 Hive 表。我的下游系统或团队将使用这些数据来运行进一步的分析(例如,在一天中,客户购买了什么商品,从哪个城市购买的?)这些数据将用于分析产品用户的人口统计特征,使我能够排除故障或扩展业务用例。这些数据可以让我们进一步了解活跃客户来自哪里,以及我如何做更多的事情来增加我的业务。
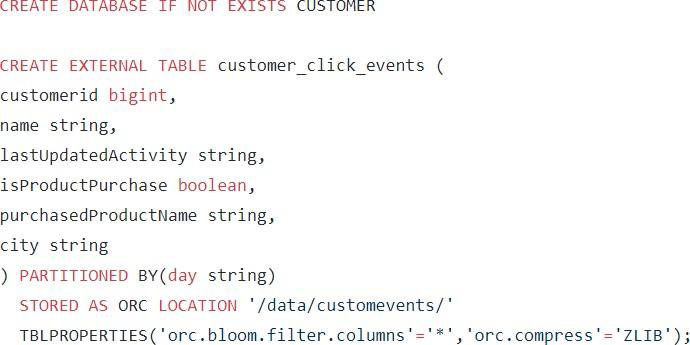
步骤 1:创建一个示例 Hive 表,代码如下:
步骤 2:设置流作业,将数据摄取到 Hive 表中
这个流作业可以从 Kafka 的实时数据触发流,然后转换并摄取到 Hive 表中。

图 4:Hive 数据流
这样,当摄取到实时数据时,就会写入天分区。不妨假设今天是 20200101。
hdfs dfs -ls /data/customevents/day=20200101//data/customevents/day=20200101/part00000-djwhu28391/data/customevents/day=20200101/part00001-gjwhu28e92/data/customevents/day=20200101/part00002-hjwhu28342/data/customevents/day=20200101/part00003-dewhu28392/data/customevents/day=20200101/part00004-dfdhu24342/data/customevents/day=20200101/part00005-djwhu28fdf/data/customevents/day=20200101/part00006-djwffd8392/data/customevents/day=20200101/part00007-ddfdggg292当一天结束时,这个数值可能是 10K 到 1M 之间的任意一个值,这取决于应用程序的流量。对于大型公司来说,流量会很高。我们假设文件的总数是 141K。
步骤 3:运行合并作业
在 20201 月 2 号,也就是第二天,凌晨 1 点左右,我们运行合并作业。示例代码上传到 git 中。文件名为 consolidated .sh。
下面是在 edge node/box 中运行的命令:
./consolidate.sh 20200101现在,这个脚本将合并前一天的数据。合并完成后,你可以重新运行 count:
hdfs dfs -count -v /data/customevents/day=20200101/*count = 800之前是 141K,合并后是 800。因此,这将为你带来显著的性能提升。合并逻辑代码见这里。
统计数据
在不使用任何调优技术的情况下,从 Hive 表读取数据的查询时间根据数据量不同需要耗费 5 分钟到几个小时不等。
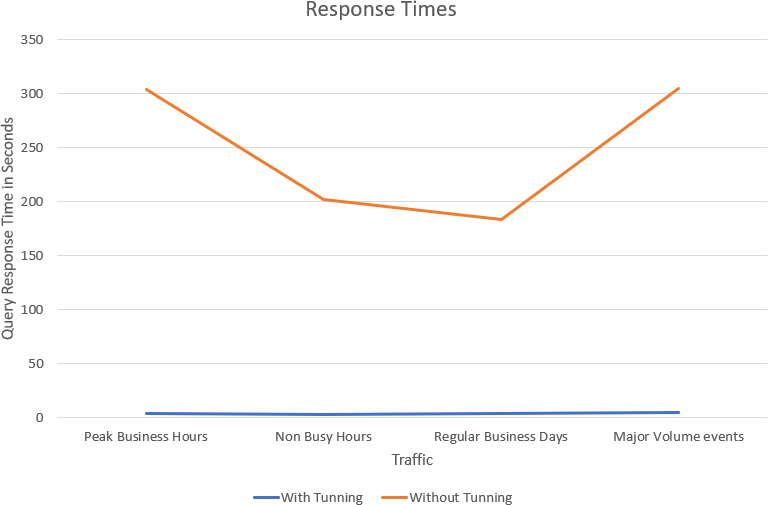
图 5:统计数据
合并之后,查询时间显著减少,我们可以更快地得到结果。文件数量显著减少,读取数据的查询时间也会减少。如果不合并,查询会在跨名字节点的许多小文件上运行,会导致响应时间增加。
参考资料
Koloth, K. S. (2020 年 10 月 15 日).大数据对人工智能的重要性.
Apache. (n.d.). Hive Apache.Hive Apache.
Gauthier, G. L. (2019 年 7 月 25 日).运行Apache Hive 3,新特性、要诀和技巧.
作者简介
Sudhish Koloth是一家银行和金融服务公司的首席开发。他已从事信息技术领域的工作 13 年。他使用过各种技术,包括全栈、大数据、自动化和 Android 开发。在 2019 冠状病毒病大流行期间,他还在交付有重要影响的项目方面发挥了重要的作用。Sudhish 用他的专业知识解决人类面临的共同问题,他是一名志愿者,为非营利组织的应用程序提供帮助。他也是一位导师,利用他的技术专长帮助其他专业人士和同事。关于 STEM 教育对于学龄儿童和年轻大学毕业生的重要性,Sudhish 先生也是一位积极的传道者和激励者。他在职业关系网内外的工作都得到了认可。
原文链接:




