
本文最初发表于 Towards Data Science 博客,经原作者 Satyam Kumar 授权,InfoQ 中文站翻译并分享。
数据集的质量和数量对机器学习模型有着很大的影响。如果一种机器学习模型能够在无需维护的情况下正常运行,那么它就是一种最常见的错误假设。
Netflix 推荐系统竞争就是模型部署失败的一个例子。获奖的模型赢得了 100 万美元的奖金,但从未投入生产。
在本文中,我列出了导致机器学习模型在生产中可能表现不佳的九种可能原因,以及数据科学家在训练模型时应该牢记的一些要点。
1. 对离群值处理不当
离群值是指数据集中存在的极端观测值,它会对模型的性能产生影响。离群值处理不当,会影响模型的估计。可以使用不同的技术来处理离群值:
离群值的存在对一些机器学习模型的影响较小,而对某些机器学习模型的影响则较大。因此,模型的选择应该是有效的。对极易产生异常值的模型,如线性回归,应在模型训练前对其进行处理。
多变量离群值的存在会影响模型在生产中的性能。多变量离群值常常被数据科学家所忽略,并根据每个特征对其进行处理。阅读这篇文章《单变量离群值与多变量离群值》(Univariate and Multivariate Outliers),可以了解更多关于多变量离群值的知识。
阅读这篇文章《检测和消除离群值的方法》(Ways to Detect and Remove the Outliers),了解更多关于如何检测和消除离群值的信息。
2. 类不平衡问题
目标类标签的类不平衡会影响模型的性能。类不平衡数据集的一些例子有欺诈检测、癌症检测等。针对类不平衡数据集训练机器学习模型的技术有很多种:
选择正确的度量:对于不平衡的数据集,机器学习模型必须根据 AUC-ROC 得分、F1、精度或召回率等指标来评估。
过采样和欠采样:对少数类样本进行过采样,以增加少数类对训练模型的影响,或者对多数类样本应进行欠采样,以减少多数类对训练模型的影响。
阅读这篇文章《处理类不平衡数据的七种过采样技术》(7 Over Sampling techniques to handle Imbalanced Data),了解更多关于处理类不平衡的技巧。
3. 不正确的性能指标
为了评估模型的性能,以及模型在生产环境中的高效性能,必须选择正确的评价指标。没有一个放之四海而皆准的指标。指标的选择应该符合业务方面的投资回报率指标。对模型进行特定指标的训练,应同时满足性能阈值和业务标准。
4. 缺乏监控
生产中的模型需要定期进行监控。之前表现良好的模型,数据可能会随着时间的变化而变化,随着时间的推移,性能会下降。响应变量或独立变量可能会随着时间的变化而变化,可能会影响到预测变量。无论是与其变量相关的模型,还是重新估计参数,小规模开发,还是模型的全新开发,都必须定期监控和更新。
5. 偏差方差权衡
偏差方差问题是一种试图使两种误差源同时达到最小化的冲突,这两个误差源使得监督机器学习算法不能在训练集之外进行泛化。
高偏差和低方差的模型对目标函数有更多的形式假设,而高方差和低偏差的模型对训练数据集进行过度学习。
低偏差和高方差机器算法的例子:决策树、k- 最近邻和支持向量机。高偏差和低方差机器学习算法的例子:线性回归、线性判别分析和逻辑回归。
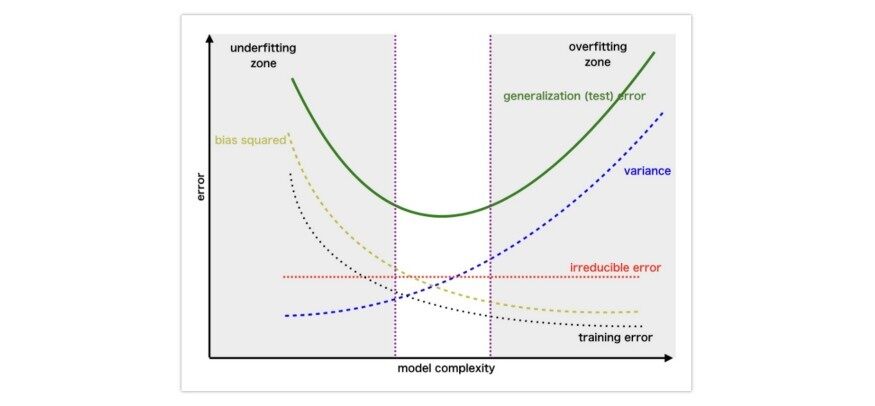
偏差方差权衡
为了得到最佳拟合模型,应该对模型的参数进行调整,使其在生产中表现最佳。
6. 不具代表性的采样
在很多情况下,我们最终会在一个与实际人群有很大差异的人群上训练模型。例如,对于在一个运动目标人群上进行模型训练,但之前没有之前的运动记录,这样的话,采样不具有代表性。
7. 不稳定的模型
有些模型往往很不稳定,并且随着时间的推移,性能会下降。这样,企业就需要对模型进行频繁的修改,对模型进行监控。当模型创建的提前期越来越长时,企业可能会开始回归基于直觉的策略。
8. 依赖于高度动态变量的模型
动态变量是指那些随着时间变化而变化的变量。如果模型对此动态变量有较强的依赖性,则可以对其进行有效的预测,从而提高模型的性能。在动态变量发生变化的情况下,模型的性能将受到很大影响。举例来说,如果模型最依赖的特征是,每月零售商的销售额,而当月仅有 10~15 天的营业时间,则可能会影响模型的性能。
9. 训练过于复杂的模型
模型的预测能力是机器学习解决问题的灵魂。但是,预测能力是以模型的复杂性为代价的。与简单的模型相比,更复杂的集合模型具有更好的性能,但模型的可解释性会较差。这样的模型可能在性能上很惊人,但一旦部署到生产环境中,性能就会开始下降。
总结
“垃圾进,垃圾出。”(Garbage In, Garbage Out)同样适用于机器学习。一个机器学习系统在生产过程中如果没有维护就不能正常工作,它也需要经常进行监控。此外,在将模型部署到生产环境之前,数据科学家应该牢记上述要点。
其他常见问题包括:
过度简化
实施问题
缺乏业务知识
数据不足或不正确
作者介绍:
Satyam Kumar,软件工程师、数据科学爱好者、程序员。
原文链接:




