
2600 亿参数,在 60 多项任务上取得最好效果,全球首个知识增强千亿大模型背后技术细节解读。
预训练大模型是现阶段 AI 领域的研究重点。
AI 大模型就像“发电厂”,能够以数据作为“燃料”,转化成智能能力,并驱动所有的 AI 应用。因此,大模型被认为是下一代 AI 基础平台。
未来,可能将是 AI 大模型的时代。这几年,国内外很多企业和学术机构竞相推出自己的大模型,尤其是国产化大模型研发工作进展飞速。
12 月 8 日,InfoQ 获悉,百度与鹏城自然语言处理联合实验室发布了鹏城-百度·文心(模型版本号:ERNIE 3.0 Titan),国产化大模型阵营再添一军。

鹏城-百度·文心是全球首个知识增强的千亿 AI 大模型。
2600 亿参数,解析全球首个中文单体模型技术细节
发布现场,中国工程院院士、鹏城实验室主任高文表示,“预训练模型对整个科学的发展、社会的发展、创新的发展来说,都是非常重要的工具。运用这个工具,可以帮助做很多人工智能的赋能,不局限于某个领域,这是人工智能的发展的福音。”
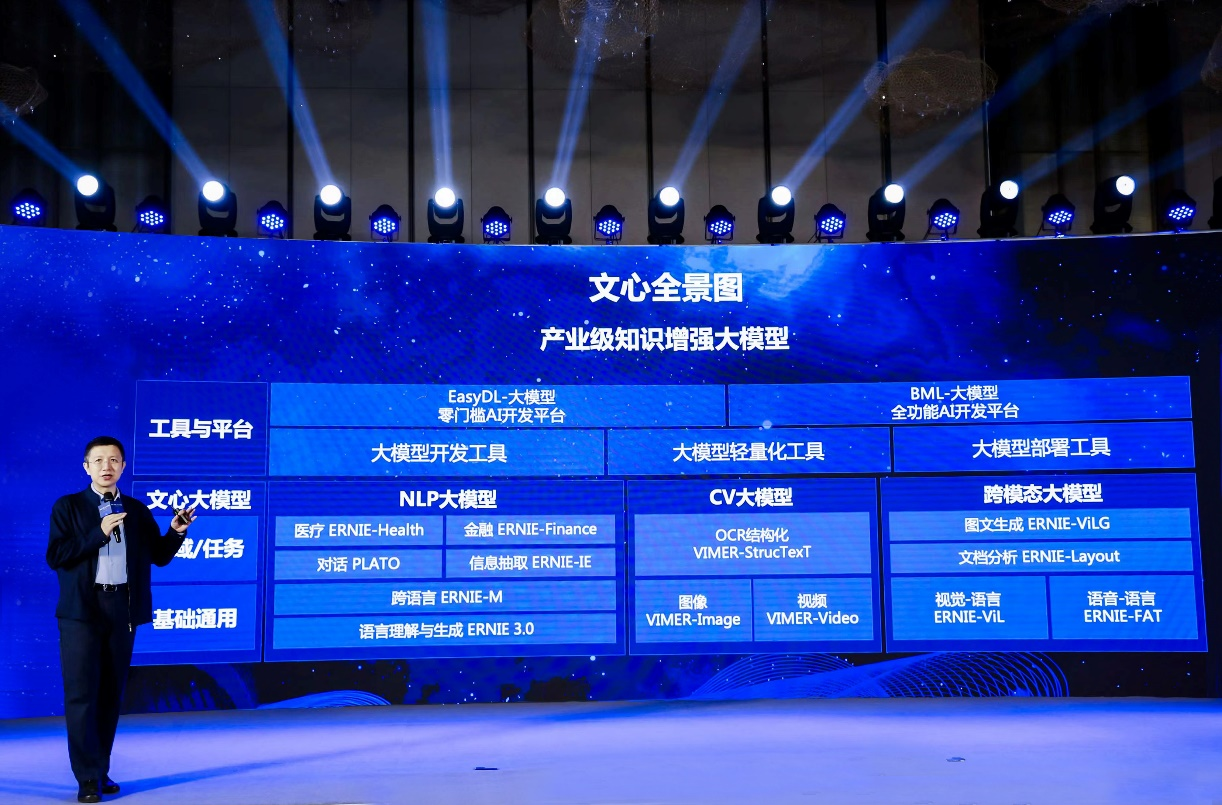
百度首席技术官、深度学习技术及应用国家工程实验室主任王海峰介绍,百度知识增强大模型从大规模知识和海量数据中融合学习,效率更高,效果更好,具有良好的可解释性。从 2019 年 3 月发布文心 ERNIE 1.0,到最新的产业级知识增强大模型文心全景图,既包含基础通用的大模型,也包含面向重点领域、重点任务的大模型,以及丰富的工具与平台,有助于促进技术创新和产业发展。
基于鹏城实验室算力系统“鹏城云脑Ⅱ”和百度飞桨深度学习平台联合,鹏城-百度·文心模型参数规模超越 GPT-3,达到 2600 亿。
鹏城-百度·文心模型希望解决传统 AI 模型泛化性差、强依赖于昂贵的人工标注数据、落地成本高等应用难题,降低 AI 开发和应用的门槛。
参数规模较 GPT-3 提升 50%
鹏城-百度·文心基于百度知识增强大模型 ERNIE 3.0 全新升级,模型参数规模达到 2600 亿,相对 GPT-3 的参数量提升了 50%。
在算法框架上,该模型沿袭了 ERNIE 3.0 的海量无监督文本与大规模知识图谱的平行预训练算法,模型结构上使用兼顾语言理解与语言生成的统一预训练框架。
为提升模型语言理解与生成能力,研究团队进一步设计了可控和可信学习算法。
训练方面,结合百度飞桨自适应大规模分布式训练技术和“鹏城云脑Ⅱ”算力系统,解决了超大模型训练中多个公认的技术难题。在应用上,首创大模型在线蒸馏技术,大幅降低了大模型落地成本。
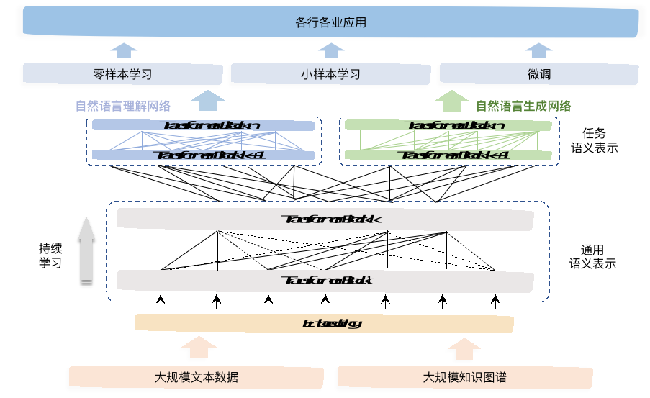
鹏城-百度·文心模型结构图
可控和可信学习算法
在算法设计上,为进一步提升模型语言理解能力以及写小说、歌词、诗歌、对联等文学创作能力,研究团队提出了可控学习和可信学习算法。
具体在可控学习方面,通过将模型预测出的文本属性和原始文本进行拼接,构造从指定属性生成对应文本的预训练数据,模型通过对该数据的学习,实现不同类型的零样本生成能力。
用户可以将指定的体裁、情感、长度、主题、关键词等属性自由组合,无需标注任何样本,便可生成不同类型的文本。
在可信学习方面,针对模型生成结果与真实世界的事实一致性问题,鹏城-百度·文心通过自监督的对抗训练,让模型学习区分数据是真实的还是模型伪造的,使得模型对生成结果真实性具备判断能力,从而让模型可以从多个候选中选择最可靠的生成结果,提升了生成结果的可信度。

高可信的可控生成预训练
千亿模型背后的强大 AI 算力支撑
鹏城-百度·文心基于百度百舸集群初始化,并基于“鹏城云脑 II”高性能集群训练。
“鹏城云脑Ⅱ”由鹏城实验室联合国内优势科研力量研发的算力集群,是我国首个国产 E 级 AI 算力平台。
“鹏城云脑Ⅱ” 运行的是鹏城实验室自主研发的分布式 AI 操作系统,连接广州超算和合肥中科大类脑计算平台,已实现异地资源共享与统一服务。“鹏城云脑Ⅱ” 采用搭载鲲鹏、昇腾处理器的 Atlas 900 集群,提供充沛算力,其云脑平台关键技术由鹏城实验室开发。何为“云脑”?简而言之,云脑就是一台既算得快,又能支持人工智能计算的超高速计算机。
去年年底,鹏城云脑Ⅱ基本型发布,正式开启 1000P 级云脑,启动时的算力为 100P OPS(每秒十亿亿次计算)。据悉,今年年底,鹏城云脑Ⅱ基本型将迈入 1000P OPS(每秒百亿亿次计算)算力规模。
1000P 算力是什么概念?相当于 52 万台家用电脑的算力之和,当今世界上最强的超级计算机算力约为 235P,这也意味着,到时候鹏城云脑Ⅱ的算力将超过现今世界最强大的超级计算机。
对于从事人工智能研发的企业或研究机构而言,鹏城云脑Ⅱ都将是“利器”。
此前,高文院士曾介绍,在鹏城云脑上,科研人员既可以开展新一代人工智能基础理论、核心算法、高端芯片、关键设备、操作系统的研究;另一方面基于鹏城云脑提供的算力,可实现在城市交通、医疗健康、金融风控、智能制造等领域的 AI 赋能,打造新一代人工智能开源开放创新平台。
数据显示,最近两年,“鹏城云脑”多次在相关领域国际权威竞赛中获得佳绩,如在今年 5 月,“鹏城云脑Ⅱ”在“MLPerf training V1.0”基准测试中获得自然语言处理领域模型性能第一名和图像处理领域模型性能第二名。基于“鹏城云脑”智能计算性能和软硬件系统协同水平方面的支撑,鹏城-百度·文心在训练性能上表现不俗。
采用飞桨深度学习框架进行分布式训练和推理
超大规模模型的训练和推理给深度学习框架带来很大考验,需要利用大规模集群分布式计算才能在可接受时间内完成训练或推理的计算要求,同时面临着模型参数量单机无法加载、多机通信负载重、并行效率低等难题。
今年 4 月,百度深度学习框架飞桨发布了 4D 混合并行技术,可支持千亿参数模型的高效分布式训练。
但鹏城-百度·文心的训练任务给飞桨带来了新挑战:
一方面,鹏城-百度·文心的模型结构设计引入诸多小形状的张量计算,导致层间计算量差异较大,流水线负载不均衡;
另一方面,“鹏城云脑 II”的自有软件栈需要深度学习框架高效深度适配,才能充分发挥其集群的领先算力优势。
针对以上挑战,并综合考虑当前主流硬件、模型的特点与发展趋势,飞桨设计并研发了具备更强扩展能力的端到端自适应大规模分布式训练架构(论文链接:https://arxiv.org/abs/2112.02752)。
该架构可以针对不同的模型和硬件,抽象成统一的分布式计算视图和资源视图,并通过硬件感知细粒度切分和映射功能,搜索出最优的模型切分和硬件组合策略,将模型参数、梯度、优化状态按照最优策略分配到不同的计算卡上,达到节省存储、负载均衡、提升训练性能的目的。
经过检验,飞桨自适应大规模分布式训练架构使得鹏城-百度·文心的训练性能是传统分布式训练方法 2.1 倍,并行效率高达 90%。
超大规模的模型训练不稳定一直上业界难题。针对这个问题,飞桨设计了容错功能可以在不中断训练的情况下自动替换故障机器,加强模型训练的鲁棒性,提高模型训练的稳定性。
在推理方面,飞桨基于服务化部署框架 Paddle Serving,通过多机多卡的张量模型并行、流水线并行等一系列优化技术,获得最佳配比和最优吞吐。
通过统一内存寻址(Unified Memory)、算子融合、模型 IO 优化、量化加速等方式,让鹏城-百度·文心的推理速度持续提升。
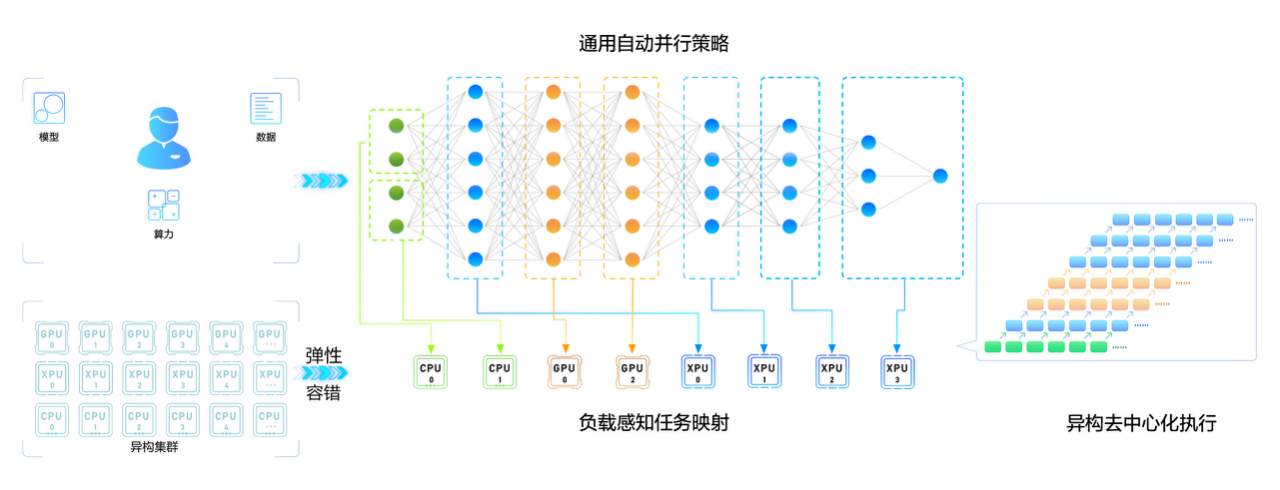
飞桨超大模型训练与推理
模型代码近期将开源
自 2019 年诞生至今,文心 ERNIE 在语言理解、文本生成、跨模态语义理解等领域取得多项技术突破,多次公开权威语义评测中获得冠军。
本着“开源开放”的理念,该模型代码近期会在 OpenI 启智社区开源,依托鹏城云脑Ⅱ对外开放,积极联合“产学研协”各方,充分挖掘 AI 大模型的赋能能力。
目前,百度文心通过百度飞桨平台陆续对外开源开放。
瞄准 AI 规模化应用落地难题
小样本和零样本学习寻求突破,减轻数据标注依赖
在经历过热潮与风口过后,AI 行业开始渐渐回归理性,如何解决落地难题、实现规模化盈利成为 AI 公司最为关注的问题,这也是广为外界所关切问题。
但 AI 商业化这条路并不好走,在 AI 落地的过程中,无论在技术上还是产业应用端,都面临着不小的挑战。
技术方面,机器学习依赖大量的已标注数据,AI 技术在全场景的落地以及大数据时代的到来产生了海量、指数级别的数据,数据获取也相对变得容易,然而,想要获得大量的已标注数据却并不容易,往往需要付出很大的人力、物力、财力成本。
小样本学习被认为是解决这一问题的关键,也被认为是解决 AI 落地难题的“速效药”。这几年很多人工智能公司纷纷在小样本学习领域发力,采用小样本学习可以减少数据标注的工作量,降低模型训练的成本和周期,从而解决人工智能在项目落地中对于大量标注数据的依赖。
鹏城-百度·文心模型也在小样本学习方面做出了许多技术突破。据悉,该模型在 30 余项小样本和零样本任务上均取得了最优成绩,能够实现各类 AI 应用场景效果的提升,希望解决 AI 产业化规模应用的问题。
目前,鹏城-百度·文心模型已在机器阅读理解、文本分类、语义相似度计算等 60 多项任务中取得最好效果。
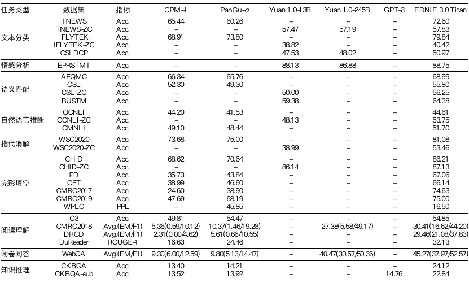
鹏城-百度·文心小样本学习效果
鹏城-百度·文心零样本学习效果
降低模型应用成本,首创大模型在线蒸馏技术
另一个技术挑战是,大模型训练、推理所消耗的资源极其昂贵和密集。
尽管 Paddle Serving 已提供了超大模型的高速推理方案,但为了进一步打造大模型的绿色落地方案,降低大模型应用成本,研究团队提出了大模型在线蒸馏技术。
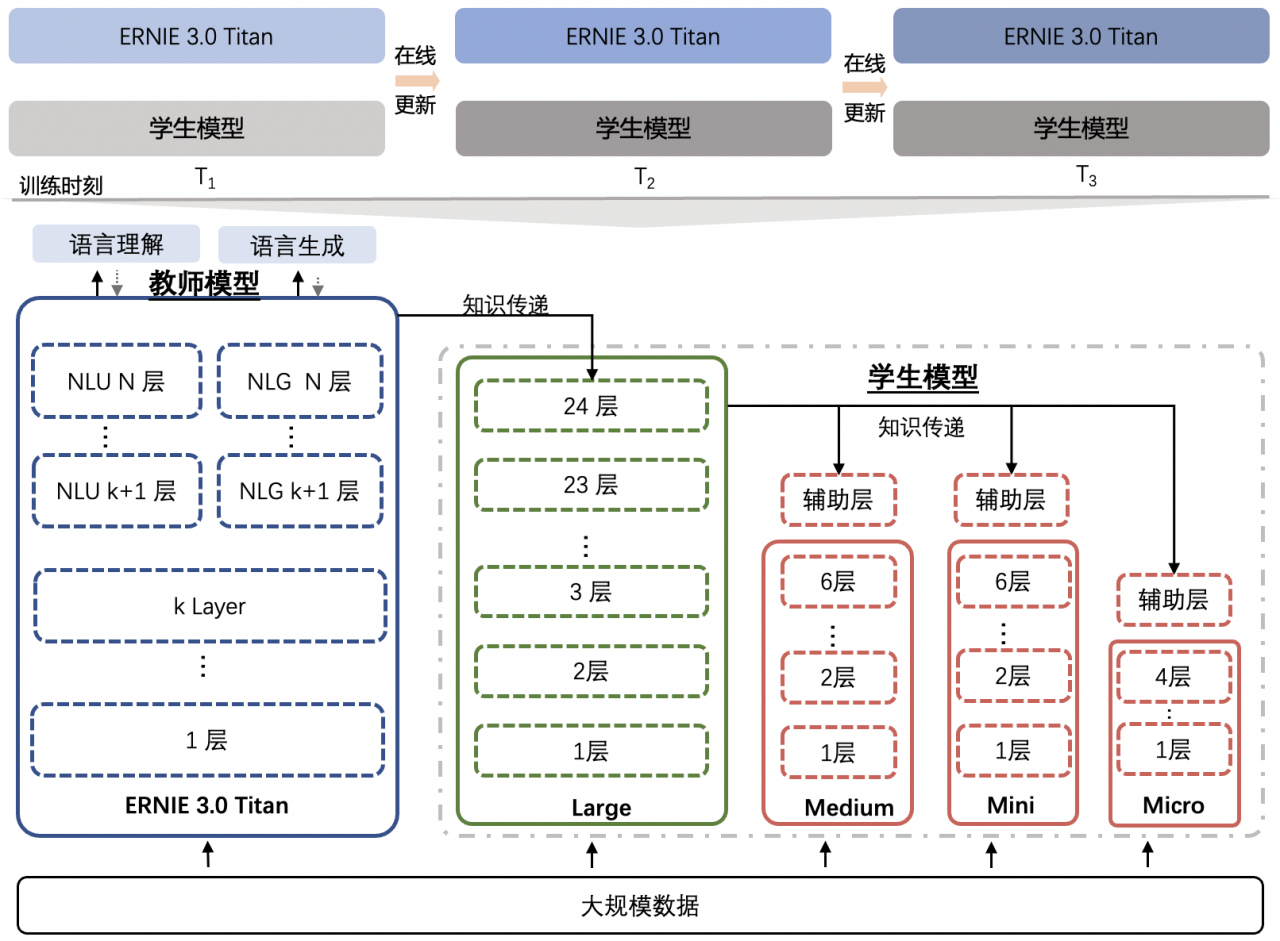
在线蒸馏技术
具体来说,该技术在鹏城-百度·文心学习的过程中,周期性地将知识信号传递给若干个学生模型同时训练,从而在蒸馏阶段一次性产出多种尺寸的学生模型。
相对传统蒸馏技术,该技术极大节省了因大模型额外蒸馏计算以及多个学生的重复知识传递带来的算力消耗。
这种新颖的蒸馏方式利用了鹏城-百度·文心规模优势,在蒸馏完成后保证了学生模型的效果和尺寸丰富性,方便不同性能需求的应用场景使用。
此外,研究团队还发现,鹏城-百度·文心与学生模型尺寸差距千倍以上,模型蒸馏难度极大甚至失效。
针对这个问题,研究团队引入了助教模型进行蒸馏的技术,利用助教作为知识传递的桥梁以缩短学生模型和鹏城-百度·文心 表达空间相距过大的问题,从而促进蒸馏效率的提升。
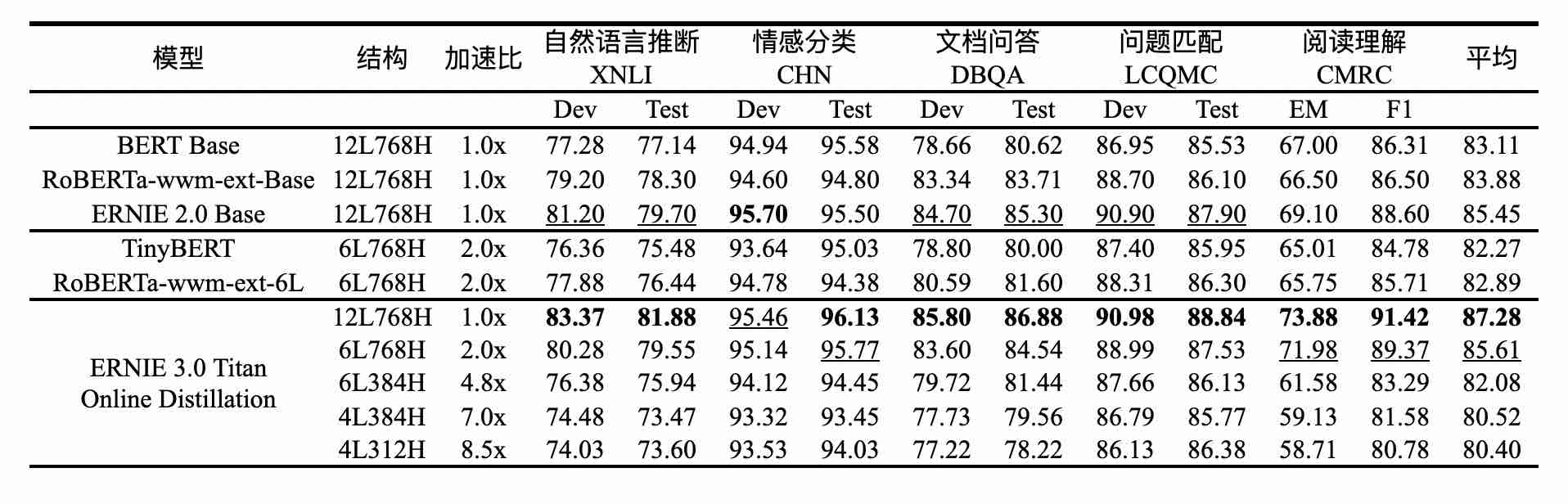
鹏城-百度·文心压缩版模型效果
数据显示,鹏城-百度·文心在线蒸馏方案的效果显著,模型参数压缩率可达 99.98%。压缩版模型仅保留 0.02%参数规模就能与原有模型效果相当。
相比直接训练参数规模是自身 2 倍的 BERT Base 模型,鹏城-百度·文心在 5 项任务准确率上绝对提升了 2.5%,而相对于同等规模的 RoBERTa Base,准确率则绝对提升了 3.4%,验证了鹏城-百度·文心在线蒸馏方案的有效性。
已在金融、工业等各行业应用
目前,百度文心已大规模已应用于百度搜索、信息流、智能音箱等互联网产品,同时通过百度智能云赋能工业、能源、金融、通信、媒体、教育等各行各业。
如在金融领域,基于百度文心实现合同智能解析,能在 1 分钟内完成对相关合同条款文本的解析识别,速度是之前的几十倍,有效提升工作效率。文心还帮助百度智能云提升了其智能客服的服务准确性,具体在运营商、银行等企业的场景中应用。
百度表示,接下来,鹏城-百度·文心将进一步解决 AI 技术在应用中缺乏领域和场景化数据等关键难题,降低门槛,加快人工智能大规模产业应用。




