
一、前言
随着整个互联网流量红利进入末期,各大厂在着力吸引新客的同时,在既有客户群体的运营上也是煞费苦心,各种提高客户体验、个性化服务的场景层出不穷。
携程机票大数据部门在实践过程中需要同步数据、选型引擎来存储处理数据,利用接口将模型结果开放给生产环境调用,因此我们的数据存储修炼之旅会涉及到接口现状、接口大道之旅、安装部署、同步数据、生产应用以及未来的趋势-如何实现容器化。这当中,我们遇到了很多问题,也解决了很多问题,本文将分享机票大数据平台在数据存储这一块的实践经验。
二、机票大数据接口现状
携程机票大数据平台接口组碰到的问题:
如何存储
如何查询
如何维护
2.1 如何存储
机票大数据基础架构团队接口组在 2018 年之前,数据的存储方案基本是:hive、mysql、redis。以下是我们现有的存储选型:
这就造成了机票大数据部门的 redis 集群内存需求暴涨,目前我们统计 redis 使用的数据:挂在机票大数据部门的 redis 集群数量有几十个,内存达到了十几个 T。当然接口的性能也达到了前所未有的快速和高效,基本都是 10ms 左右。
2.2 如何查询
Redis 的查询方式比较单一:通过唯一 key 去查询 value。这种查询方式在简单的唯一值查询中比较有效,但是当遇到,同一个数据源多关键字查询的时候,就得维护多份数据源。举例:在价格趋势的接口中,我们提供了多种价格趋势组合:国内、国际、单程、往返、航线、航班。如果使用 redis 存储,需要维护同一份数据多种 key 的存储方式,极大地浪费了存储空间。
Redis 还有一个问题是时间范围的筛选,还是在上面的价格趋势接口中,需要按照查询时间返回历史同期在一定起飞时间范围的价格数据,所以我们需要存储多个时间日期的数据(当然也可以用 set 等结构,但是会面临如何删除过期数据的问题),同时在查询的时候需要循环取一定时间范围的价格。
2.3 如何维护
1)接口维护
大数据基础平台团队一共维护了几百个接口,其中 1/3 的接口是提供数据给调用方的,这当中又有一些接口只是提供简单的查询操作,但就是这些简单的查询,需要我们提供海量的数据存储、快速精准的查询。每个接口的上线需要经过项目资源申请(包括机器资源、人员资源)、数据同步、开发、测试流程,最后才能上线。一整套流程走下来,耗费 2-3 天/人,而且基本上都是是重复性的工作。如何解放这些人力和机器资源,就变得很迫切了。
2)数据同步
提供给外部使用的数据大部分都是存储在 hive 中,在不使用 presto api 的方式访问时,我们需要将 hive 数据导入到 redis 或者 mysql 中,供接口访问。在 zeus 平台上,我们建立了各种导数据的流程,如何将这些简单、重复度高的流程自动化呢?
整个接口的架构图如下:
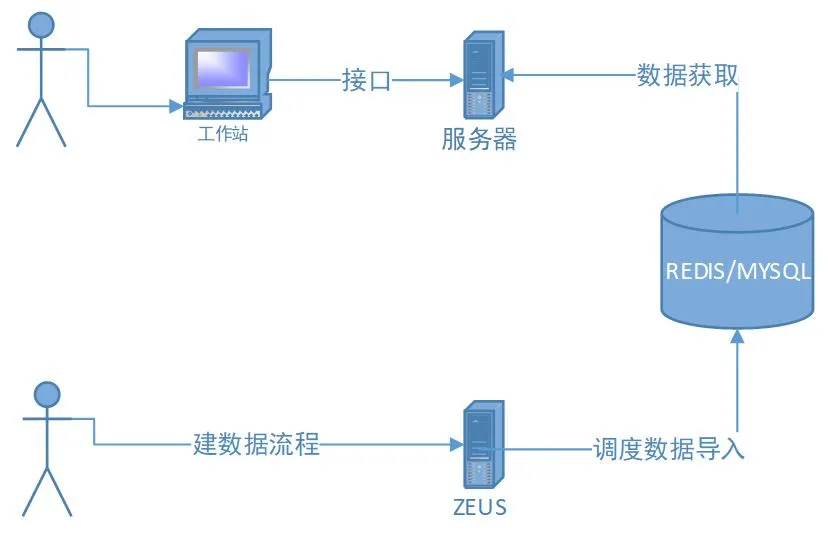
图 1 redis/mysql 作为主要存储的架构图
三、机票大数据接口的大道之旅
认真研究了接口调用方本身的性能,我们发现调用方在调用第三方提供的接口时,基本都是异步进行的。如果把调用方调用的所有第三方接口当成一个木桶,机票大数据基础架构团队的接口就是其中的一块木板,只要不是最短的木板,就可以在保证性能的情况下降低整个接口的响应时间(当然这不是技术上的退步,而是选择合适的方案)。通过上面的存储选型对比之后,发现在 100ms-500ms 这个性能段里面没有一个合适的存储方案能够提供。
我们调研了几种 NOSQL 数据库方案,综合存储、查询等指标发现 CrateDB 比较符合现实需求。将几种存储做了一个对比,如下:
3.1 CrateDB 介绍
CrateDB 是构建在 NoSQL(ElasticSearch)基础之上的分布式 SQL 数据库,它结合了 SQL 的通晓程度和 NoSQL 的可扩展性和数据灵活性:
a、使用 SQL 处理结构化或非结构化的任何类型的数据
b、以实时速度执行 SQL 查询,甚至 JOIN 和聚合
c、简单缩放
3.2 CrateDB 与接口存储
CrateDB 很好地解决了 100ms-500ms 性能段的短板,并且使用磁盘+内存的方式存储数据,减少了内存的使用。目前在我们生产时间中,通过 12 台 8 核 24G 虚拟机 30%的磁盘空间覆盖了 10 亿数据(如果是 redis 至少需要 300G 的内存,如果做 slave,容量 double)。
3.3 CrateDB 与接口查询
CrateDB 提供了如 MYSQL 的表、字段等概念(底层使用 ES 存储引擎),我们可以将同一份数据源进行多维度的操作,比如上述讲到的价格趋势里面基于航线和航班的价格趋势,这两个接口可以使用同一套数据源,因为航线的价格可以基于航班数据进行聚合操作,这样就大大减少了冗余的数据。同时类 MYSQL 表的特性使得时间范围的查询变的 so easy 了。
3.4 CrateDB 与接口维护
1)与接口结合使用
因为 CrateDB 支持标准的 SQL,我们开发了机票大数据基础平台的通用性 api 系统,通过将取数逻辑 SQL 化的方式,同时利用 qconfig api 将新增的数据需求进行模板化、配置化,统一了接口代码开发的流程。配置页面如下:
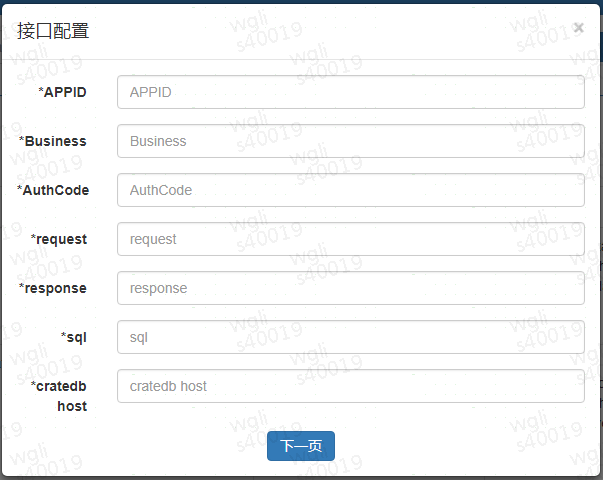
图 2 接口配置页面
2)数据同步
通过 zeus api 将同步数据流程模板化,配置页面如下图。并且在 zeus 平台上,使用 spark shell 方式将 hive 数据导入到 CrateDB 中,抛弃了以前 jar 包的方式。这种方案可以在几分钟内导入千万级的数据(取决于 CrateDB 表的数据结构,减少索引、doc_values 以及刷新间隔会都有利于导入的速度)。
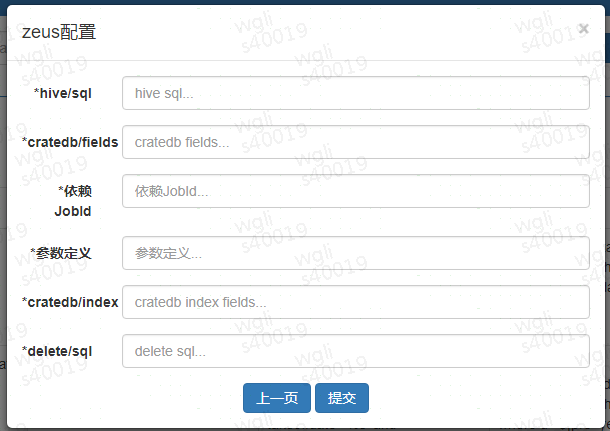
图 3 zeus 流程配置页面
3)容器化
如何更加有效地管理、维护 CrateDB 集群?为此我们上了 k8s,将 CrateDB 容器化。为了更好地管理这些 k8s 集群,引入了 rancher,rancher 是开源的企业级容器管理平台,通过 rancher,我们再也不必自己去从头搭建容器服务平台。同时 rancher 提供了在生产环境中使用的管理 docker 和 kubernetes 的全栈化容器部署与管理平台。将网络、磁盘虚拟化之后,资源的利用率大大提高,减少了虚拟机的使用。自动水平扩展,以及 pod 的监控等特性,都极大地提高了维护 CrateDB 的能力,我们管理的 CrateDB 集群如下:

图 4 rancher 管理 CrateDB 集群图
3.5 与接口结合的其他优势
1)存储机制多样化,底层的存储机制支持多样化的数据类型,同时支持 partition、sharding;
2)数据结构化,CrateDB 提供结构化的展示,有利于数据的可视化以及降低非技术人员的理解难度,解决了 redis 可读性差的问题;
3)存储可靠性,数据持久化存储在磁盘上,支持 replica,相比于 redis 的内存存储更加可靠(当然 redis 也可以落盘,但这就会限制 redis 的速度);
4)成熟的优化机制,针对 es 的优化我们有丰富经验的技术人员支持。举个例子:我们有 9000 万+的用户行程数据,因为数据比较详细,字段的内容比较庞大。通过去掉部分字段的索引,去掉 doc_values 等操作将数据存储大小从 90G 降到了 30G,同时也提升了搜索速度。
目前在生产上我们部署了 2 个 CrateDB 集群,其中一个集群由 12 台 8 核 24G 内存虚拟机组成。在集群中建立了 12 个数据表,存储了 20+亿条数据,经受了生产的实际考验,接口性能指标如下:
性能满足了大部分调用方的使用需求,同时系统数据上线的流程由以前的申请资源、开发代码、测试、上线,到现在的系统配置、测试、上线,释放了部分的开发资源,并且保证了数据的质量。接口上线时间由以前平均 2-3 天,缩短为 2-3 小时。新的接口架构图如下:
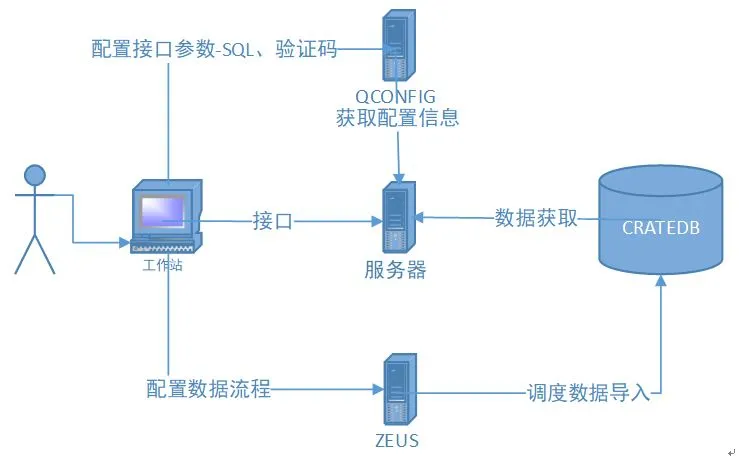
图 5 CrateDB 作为主要存储的架构图
四、安装部署
CrateDB 有官方版以及社区版,为了更好地进行自维护,我们选择了社区版(通过源码编译)。CrateDB 的部署与 ES 的部署基本一致。需要注意的是,在分配内存的时候尽量多留一些内存给系统,这将有利于数据查询速度。部署后的 webui 如下:
图 6 CrateDB webUI
五、数仓中的实现
目前在数仓中的应用主要体现在各种指标 dashboard、metrics 的展示,比如 fltinsight。与以往通过 presto 接口获取数据的方式相比,更加直接、高效。而且 CrateDB 支持各种字段的聚合、统计,是各种指标存储、展示的不二之选。当然后续数仓组也会在数据展示这一块全面推广 CrateDB 的使用。
六、小结
没有完美的存储方案,只有最适合的存储方案。通过上述机票大数据平台在数据存储这一块的实践经验,相信每个团队在面对选择存储方案的时候,结合自身需求去选择适合自己的存储技术方案,达到“大道”。
文章转载自: 携程技术(ID:ctriptech)
原文链接:CrateDb在携程机票BI的实践




