
作为下一代对象存储还不够,取代 HDFS 才是 Ozone 的目标。Ozone 是当前 Apache Hadoop 生态圈的一款新的对象存储系统,Ozone 与 HDFS 有着很深的关系,在设计上,很多地方也参考了 HDFS,并对 HDFS 存在的不足做了很多改进。很多公司看重的不仅仅是 Ozone 的对象存储能力,更是 Ozone 标榜自己是 HDFS 的下一代的目标。我们抓住了这一点,并做出了比开源社区 Ozone Filesystem 方案更彻底的 HDFS on Ozone 架构设计和实现,取得了阶段性成绩。本文将为大家介绍如何让 Ozone 成为 HDFS 的下一代分布式存储系统,主要内容包括:
Ozone 介绍
NameNode on HDDS
腾讯的贡献
Ozone 的未来
Ozone 介绍
首先,我们一起简单了解下 Ozone;然后,重点介绍一下我们正在做的一个跨时代的事情 NameNode on HDDS。
1. HDFS 的组织架构
在介绍 Apache Ozone 之前,我们先一起回顾一下 HDFS,看看 HDFS 发生了什么事情,在大数据生态里,这么多年不变的分布式存储系统为什么要被取代?它到底有什么问题?我们先来了解 HDFS 的组成架构,可以看下边这张图。
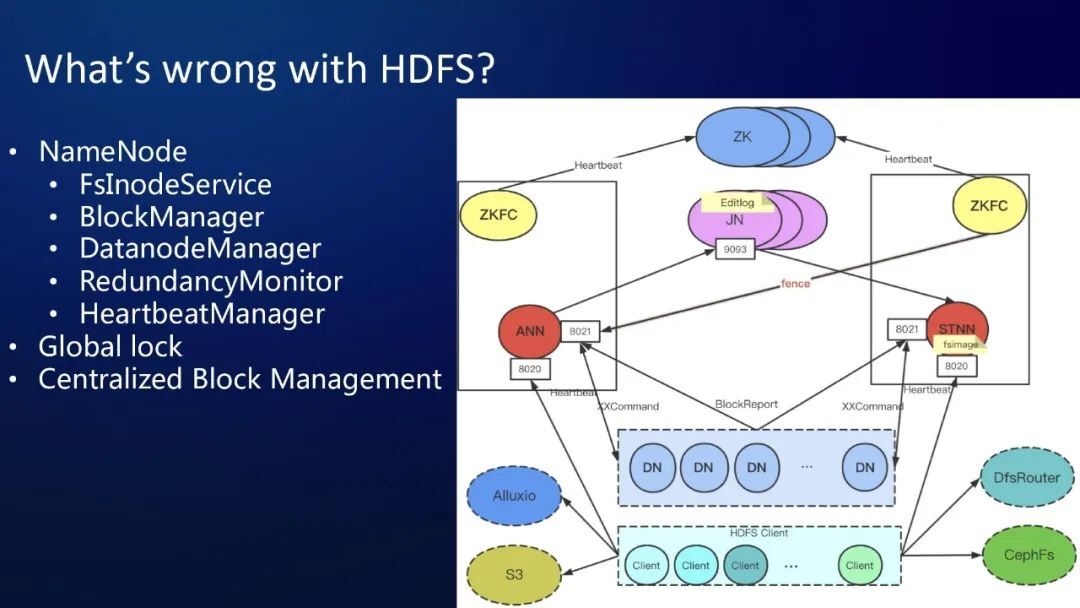
HDFS 采用的 Master/Slave 架构,并且 master 节点也就是 NameNode 节点,统一管理文件系统命名空间中的元数据,对外提供文件系统元数据服务、数据块管理服务、节点管理、冗余存储管理、心跳管理等众多服务于一身的一个高度中心化的 Master 服务。此外 NameNode 的内部还有全局的 FSlock 以及 DirLock,这些都是全局锁。这些设计都让 HDFS NameNode 架构变得极其简单,这是它的一些优点,这些设计是个双刃剑,既成就了 HDFS 也限制 HDFS。
而且 NameNode 的 HA ( 高可用性 High Availability ) 也显得特别复杂,至少要引入三个 zookeeper 节点,三个 JournalNode 节点,两个 ZKFC 节点,部署维护都显得比较复杂。文件系统的 inode 信息和 block 信息以及 block 的 location 信息全部在 NameNode 的内存中维护,这使得 NameNode 对内存的要求非常高,需要定制大内存的机器才能承载更大的元数据量。
京东的 NameNode 内存是 512GB,还有某厂的 NameNode 的机器是 1TB 的内存。此外 NameNode 堆分配巨大,京东的 NameNode 需要 360G 的堆,因此对 GC 的要求是特别高,在不断的调优和改动的情况下,京东定制的 JDK11 以及 JDK G1 GC 发挥着不错的性能。但是一般小规模的公司是不具备维护 JDK 的能力的,方案不具备普遍性。字节跳动把 NameNode 修改成 C++ 版本,这样分配内存和释放内存都由程序控制,也达到了不错的性能,这个方案仍然不具有普遍性,因为开发和维护这样一个 C++ 版本的 NameNode 实现也需要不小规模的团队。不管怎么样,元数据的 scalability ( 扩展性 ) 受限于物理内存大小是一个致命的缺点。
大家都耳闻 HDFS 对小文件不友好,但是为什么呢?其实从根本上不是因为这个文件小,而是因为产生了很多小文件和小 block,致使在同样的数据存储容量的情况下,NameNode 中产生更多的内存对象,这些内存对象都要被 NameNode 管理起来,这就会导致数据存储量还不是很大的时候,元数据量就很大了。即便没有小文件问题,当数据量达到几百个 PB,NameNode 由于启动时,需要接受绝大多数 FullBlockReport 才可以退出 safemode ( 安全模式 ),因此启动时间会达数个小时。
集群常规的 FullBlockReport、Decommision datanode、balancer block,也都会对集群元数据服务性能造成影响,这些根本原因都是因为 DataNode 需要把所有 block report 给 NameNode,以及几乎所有的操作都要获取全局锁。
一般情况下,当 5000 台规模 HDFS 集群,在 200PB 左右,大概会有 4 亿左右元数据,按 2 亿文件,2 亿块来说,这些文件和 block 的信息,都会维护在 NameNode 的 heap 上,占用了昂贵的内存,也给 GC 造成了压力。此外,这么大的数据量,在启动、以及后续的 FullBlockReport 期间,会减少总体集群的可用时间,限制了 HDFS 集群的吞吐量。
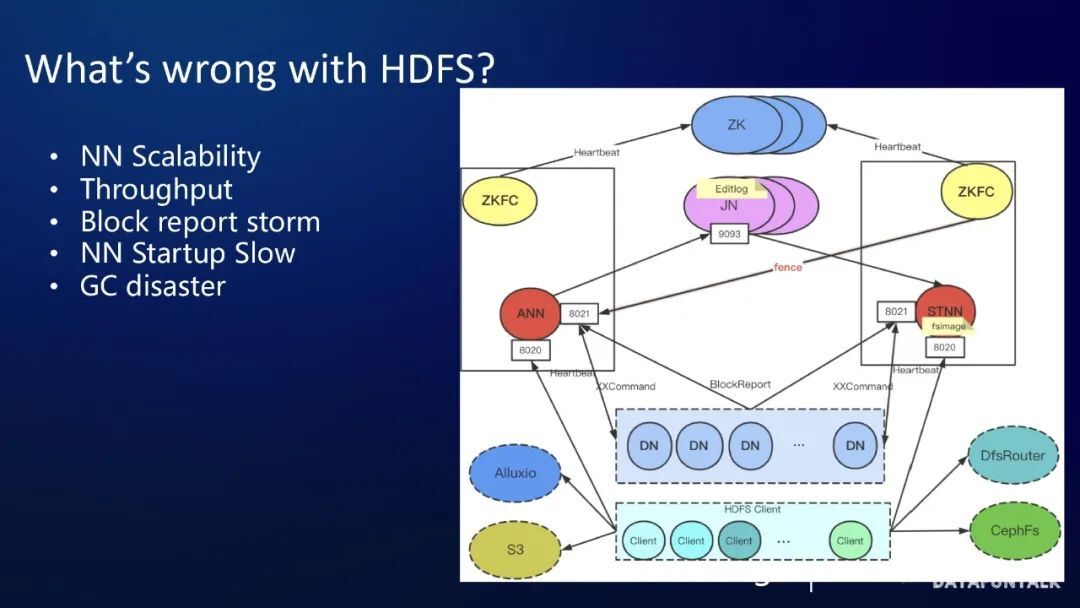
总结一下,HDFS 的问题是,元数据都在内存中,造成的 NameNode scalability 受物理内存限制的问题 和 GC 灾难问题。以及 全局锁和块汇报风暴,导致的吞吐差和 NameNode 启动慢的问题。
Ozone

近些年 Ozone 在众多新兴的开源分布式存储系统里边脱颖而出,由于 Ozone 同样是 Apache 开源基金会出品,也是许多 HDFS 社区的 PMC 和 Committer 共同设计的,因此在架构设计上既避免了 HDFS 诸多设计上的缺陷,同时也借鉴参考了 HDFS 多年历经时间考验的优秀设计功能,因此 Ozone 力求成为 HDFS 的下一代分布式存储系统。目前使用 Ozone 和参与 Ozone 开发的公司有很多,我知道的,包括腾讯、京东、思科、Cloudera、谷歌、360,还有一些其他的公司。
其中腾讯是重度的参与开发,也有很多公司在观望,希望等成熟以后再应用到公司内部,这可能是有一些偏运维的团队对于开发新系统的激情还没那么强烈,希望大家不要再观望了。中国有很多的 Ozone 的 Committer,希望大家能够踊跃的加入 Ozone 社区,一起把 Ozone 向前推。从社区活跃度来讲,Ozone 和 Ratis 的活跃度比 HDFS 的活跃度要高很多,可以从 slack 的 hdfs channel 和 ozone channel 的成员数做对比,HDFS 有 111 个成员数,Ozone 已经有 124 个成员了,还有 Ratis 是 Ozone 下面的一个就是写数据必备的依赖项目也是有 100 多人,加起来就有 200 多人了。从整个 Hadoop 项目上一个月的 Pull Request 数量对比,就可以看出来活跃度已经相差很大了,可能有些误差,因为有一些 Hadoop 的 patch 还是通过 JIRA 的 patch 的方式提交的。大家可以参与一下 Ozone 社区的代码贡献,比较一下,Ozone 的社区的基本设施还是非常完备的,比如集成了 checkstyle、findbug、Test Coverage、UT、Integrity Test,以及在 docker 内的一些测试,基础设施建设的比较好,开发者的入门门槛也会比较低。
不用编译安装 Protocol Buffers,也不用担心 Protocol 中的一些消息定义会向前不兼容 Ozone 使用的 maven 插件自动帮你去下载你对应版本的 protoc 工具,也会自动检查 Protocol 消息定义向前兼容。Ozone 社区大佬服务也很周到,百忙之中还给大家录制了系列的视频教程放到 YouTube,还写了一键在 intellij idea 里运行 Ozone 的脚本,一键 docker 里运行 Ozone 脚本,一键 kubernete 中启动 Ozone 的脚本。每周五的中午还有 Ozone 社区的同步会议,每个人都可以参加。我觉得这些都是 Ozone 能成为下一代分布式存储系统的关键点之一。
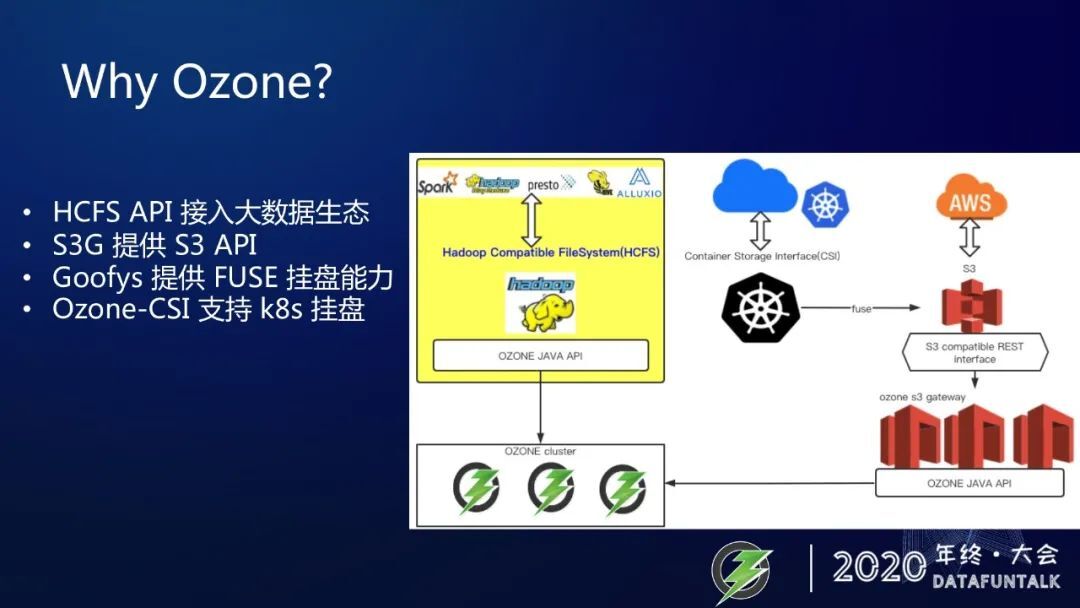
虽然 HDFS 有些问题,虽然 Ozone 社区比较活跃和 open,凭什么 Ozone 就会成为下一代分布式存储?有很多原因,先从 Ozone 的访问接口方面来说,Ozone 提供了很多 API,可以让各种应用使用各种主流的 API 来访问到 Ozone。比如 Ozone 实现了 hadoop 兼容文件系统 API,这使得 spark、presto、MapReduce,Hive、Alluxio 等这些大数据生态中的系统可以访问到 Ozone。此外,我们还向 Alluxio 贡献了 Ozone 底层存储模块,这使得 Alluxio 原生支持 Ozone 作为 Alluxio 的底层存储。
Ozone 还提供了 S3 gateway 服务,使得 Ozone 可以适用于 S3 的场景。
此外,Ozone 通过 Goofys 和 Ozone CSI 实现了 k8s 挂盘的能力。所以,想把你的应用的存储转移到 Ozone 上,非常方便。
Ozone 设计上的优势
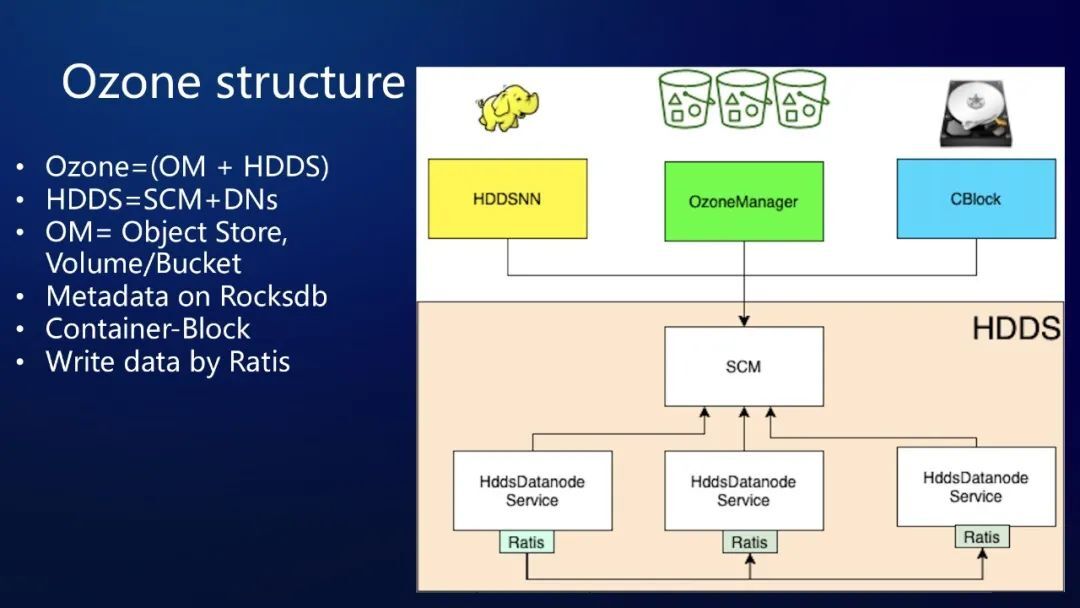
Ozone 的管理节点服务是有一些拆分的,我们可以看到 Ozone 同样采用了 Master/Slave 架构,但是有一点不同,Ozone 的 master 是有两个,一个是 OzoneManager 作为对象存储元数据服务,另一个是 StorageContainerManager,作为存储容器管理服务。相比 HDFS,Ozone 就像是把 NameNode 拆分成这两个服务。Ozone 把管理节点是拆分成 OM 和 SCM 是有很多好处的,这使得 OM 和 SCM 可以各自运行在独立的进程当中甚至可以运行在不同的机器当中,各自维护进程的生命周期,可以单独的重启、升级、维护。
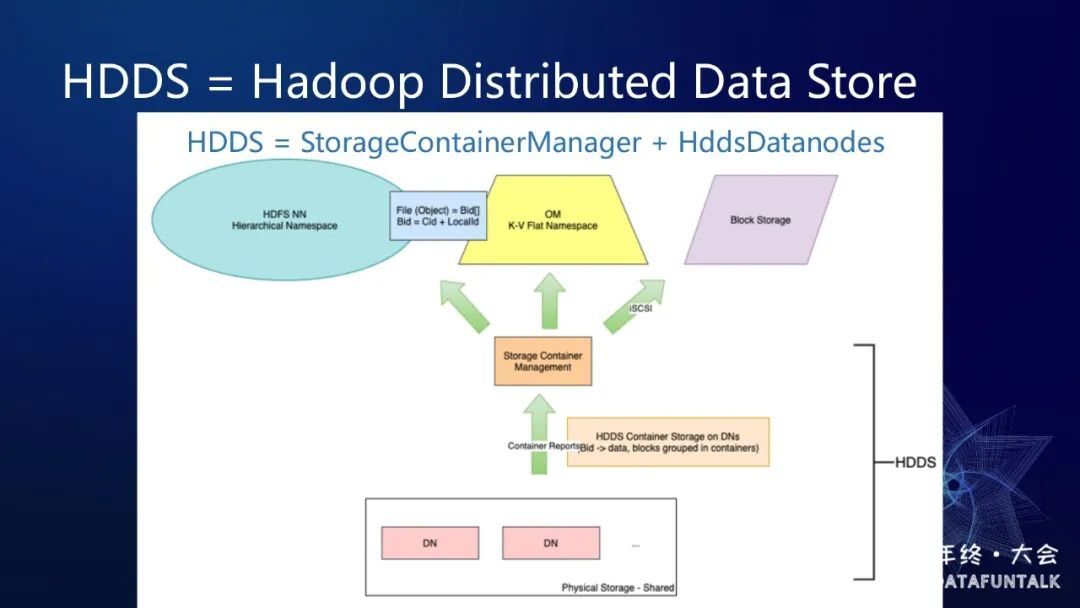
SCM 和 DataNode 组成了一个通用的存储层 HDDS,上图中浅黄色部分。HDDS 是 Hadoop Distributed Data store 的缩写。如果在 HDDS 之上加上 Ozone manager,就是 Ozone 了,Ozone manager 是对外提供的一个对象存储服务。在 HDDS 之上我们也可以去搭建一个 HDDS 的 NameNode,这样的话其实对外界来看,它就像一个 HDFS,就可以提供文件服务。如果说在 HDDS 之上,我们去启动一个 blockstorage 服务,这样的话它就可以提供一个高速挂盘的能力。Ozone 这样一个分层设计还是比较高明的。再来看看 Ozone Manager,Ozone 区别于 HDFS 的一个最大的设计上的不同,就是 Ozone 是对象存储,没有维护一个文件系统数,对象语义的操作不存在目录和文件的关系,因此可以达到很高的吞吐量,Ozone Manager 内部也可以达到 bucket 级别的并发读写。
另外一个很优秀的设计就是 OM 和 SCM 都使用 RocksDB 进行元数据管理,Ozone 的元数据不像 HDFS 的 NameNode 都放在内存里,而是放到 RocksDB 里,不管 OM 的元数据还是 SCM 中 Container 信息都维护在 RocksDB 中,不需要使用堆内的存储,理论上元数据可以无限的扩展。还有一个很高明的设计,就是引入了 Storage Container 的概念,由 DataNode 的管理 Container 中的 block,SCM 就无需管理 block 只需要管理 Container 即可。
这就好像是国家的领导只需要管理每一个城市,而城市的领导在管理城市里面的人。每个 Storage Container 都有默认 5G 的容量,其中 block 的状态是由 container 来管理,所以也极大地减少了 SCM 管理的数据量,从而提升了 SCM 的服务性能和扩展能力。无论是全量的块汇报,还是增量的块汇报,以及增删副本,和 block balance 集群,这些都不会对 SCM 的性能产生很大影响,因为块占大多数,但是 container 相对来说还是很少。
Ozone 所面临的挑战

Ozone 虽然有那么多的接入方式,也有这么多的设计上的优势,但是 HDFS 丰功伟绩引领风骚数十年,不是那么容易被取代,想要取代它需要面临很多的挑战。我们逐一来解释一下。
Ozone 不支持 Append、truncate 的操作,不过这个缺点是腾讯的两个 Ozone Committer 已经在内部实现了,并且正在 push 到开源仓库中,但是用到 hflash 的场景现在还不支持,需要我们后续再去努力。
另外 Ozone 写 key 的方式是不写完不可见,这是因为 Ozone 在写 key 的过程中不会向 OM 去提交 block,而是把所有的数据全写完之后一次性的向 OM 去提交所有 block 信息,因此在写作的过程中 key 是不可见的,这个也是我们通过后续的改动也是可以去弥补这个缺点。
Ozone 的 RPC 链路比 HDFS 的 RPC 链路长,这个也是乍一看每个人都会抱怨这个缺点,因为它把服务拆分成两个,它的一个 RPC 访问,就必然会从 client 到 OM,再从 OM 到 SCM。这个也是很正常的,但是你仔细去想一想,对于文件系统的操作,到底是元数据的耗时占得多,还是数据的耗时占得多?如果说你是想去打开一个文件去读取它的内容,或者说创建一个文件去往里边写内容,这些元数据的访问耗时比重非常小。但是有一些像 getblockLocation 等,这些就是纯元数据操作,肯定会慢。
另外一个就是 Ozone 目前还没有像文件夹的这样的一个 metadata,因此他就没办法去获得文件夹的 owner、modificationTime 等信息。像我之前做过一个实验,就是把 MapReduce 的 JobHistoryServer 把它去跑在 Ozone 之上,就是有一些 yarn 的 job 可以放在 Ozone 里面,这样就可以拿它去看的时候会发现扫不出新生成的 job 的一些日志,原因我们看了一下代码 JobHistory 里面会去根据文件夹的 modificationTime 是否变化去判断是否新生成子目录。Ozone 的 modificationTime 现在永远是零,所以也就不会感觉到变化,也就扫不出新的 job 了。
Ozone 底层写数据是基于 ratis,而目前 ratis 写也只支持一副本和三副本,腾讯正在向开源社区去贡献都基于的 Strorage cluster 框架的任意副本的支持。
SCM HA 也是一个很大的问题,现在还没有,不过腾讯现在正在积极地主导 feature,正在向我们的开源社区去 push 相关的改动,预计在 Ozone 的下一个大版本的发布会包含这个功能。
Ozone 还缺少一个 container balancer 这样的功能,用它来均衡存储,使集群的存储能分布均匀。比如我们一开始有 1000 台机器,后来又新上了 10 台那是空的,这样就需要把存储均衡到使用量较低的机器上去,这块功能腾讯也在开发中。
Ozone 目前还缺少 DataNode 磁盘预留功能,Ozone 的写性能正在通过 ratis stream 的 feature 进行优化,我们目前内部测试有的 feature 的性能会提升很大,它的一个本质上的改变就是把写数据的过程中,让它提交块的元数据的一些信息的操作以及数据块内容的 stream 操作让它能够分开,可以在不同的节点上。
Ozone 的写性能,正在通过 RATIS Streaming feature 进行优化。目前我们内部测试 有了这个 Feature 性能提升巨大。
NameNode on HDDS
这么多的挑战中,其实大多数我们是可以通过后续的开发来完善这些缺失的功能,但是文件夹元数据的支持,还有提速文件夹操作的性能,这些其实都不太容易实现,而这些恰恰是大数据文件系统语义的场景以及必要的功能和性能的要求。那么怎么办?看起来如果什么都不做,只靠 Ozone 现有的组件的完善,貌似是没有办法再胜任 HDFS 文件语义的这些场景了,所以我们 HDDS 之上启动了一个基于 HDDS 的 NameNode 服务。
我们可以在 HDDS 之上创建一个 NameNode 服务让它来取代 Ozone Manager,这样对外就提供了一个文件系统服务,就可以从根本上解决 Ozone 文件语义支持不好,以及文件夹元数据缺失的问题。
1. 文件系统语义与 Ozone 的对象存储的区别
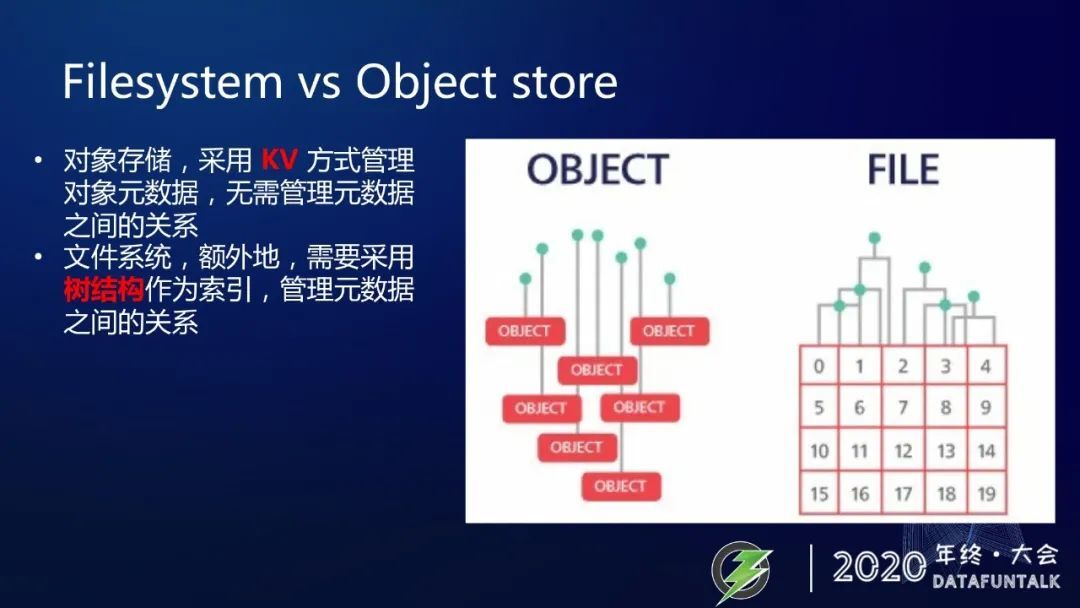
我们一直在说文件系统语义,还有 Ozone 的对象存储,它们到底有什么区别。
可以通过上面这张图简单可以看出来,对象存储就像左边种是 KV 方式去管理对象元数据,它无需管理元数据的之间的关系。文件系统就像右边,它是额外的需要采用树状的结构去作为索引去管理元数据之间的关系,这就是它的本质上区别。这些区别,使得对象存储和文件系统有着各自的优缺点和各自的适用场景。
对象存储,一个 URL 路径,就是一个 key,本身就没有文件夹的概念,只是我们非要把对象存储硬要当文件系统使用,那只能靠 key 中的正斜杠,切割出文件夹的概念来,实际没有文件夹节点,也就不会有文件夹的元数据信息。
list 慢也是因为 list 操作需要在 rocksdb 中,按前缀扫表。rename 文件夹 操作需要修改文件夹中的每一个 key,而对于文件系统,list 操作直接把文件夹的 children 返回即可,rename 文件夹,只需要修改一下文件夹节点的 name 即可。
明白了原理,我们也就确定了一点,OzoneManager 是对象存储服务,不管你怎么优化,也无法媲美 HDFS。
2. Ozone 的存储分层设计
所以怎么办?我们来回顾一下 Ozone 的存储分层的设计。Ozone 起初设计为一个对象存储,但是经过抽象出来的 HDDS 层使得存储层和元数据层是可以分离的,就像 Ozone 就是把 Ozone Manager 以及下面的 HDDS 是可以做分离,这样就可以在 HDDS 层之上,增加 HDDS NameNode 或者 Block Storage。或者除此之外,我们也可以在 HDDS 之上去创建一个新的其它的对象存储,可能你的系统里面需要这样的一个定制化的对象存储,你也可以实现一个其它的类似于 Ozone Manager 这样的一个节点。我们重点就是要介绍基于 Ozone 分层存储的设计,我们就可以在 HDDS 层之上去实现一个 HDFS NameNode 去承接大数据场景文件系统语义的 workload。

事情说清楚了,现在真要干起来,其实很重要的一点就是要分阶段去迭代,不能直接朝着终态目标,埋头苦干,中间没有输出成果。那样,对于老板,看不到你的进展。对于项目成员,也没有办法持续兴奋起来,所以,我们把事情分为几个阶段做。
Base 就是我们的基础了,我们不是从 0 实现的,我们基于 HDSF client 和 Namenode 以及 Ozone 的 HDDS 开始我们的开发工作。
Basic 的目标,是实现一个 HddsClient 和 HddsNameNode,加上未经修改的 HDDS 集群。可以实现 一个基于 HDDS 的 Filesystem,我们称之为 OZONE-DFS。这就实现了与 HDFS 几乎等同的文件系统服务了,可以接入大数据 workload 了。
第二阶段,我们要优于 HDFS,提升吞吐和性能,因此,我们在 OZONE-DFS ( HDDSFS ) 的 NameNode 上大刀阔斧做 HDFS 多年没有做的事情,锁优化,也叫细粒度锁改造。我们借鉴了美团的 NameNode 锁优化思路,也仔细剖析了 Alluxio 细粒度锁的实现。这些给力我们很大帮助。这个阶段完成,我们的 OZONE-DFS 就已经超越了 HDFS 了。
这还不够,我们要设计实现一个远远超越 HDFS 的 OZONE-DFS,所以,我们在第三阶段,对 NameNode 的元数据进行 KV 化改造,并采用两层元数据管理的方式,上层为内存,下层为 rocksdb,既实现元数据无限扩展,又最大程度上,不损失太大性能。此外,利用 Apache Ratis 实现 NameNode 的 HA,不再需要 ZK、ZKFC、JournalNode 等 HA 相关服务,3 个 HDDS NameNode 组成一个 RAFT Group 足以。
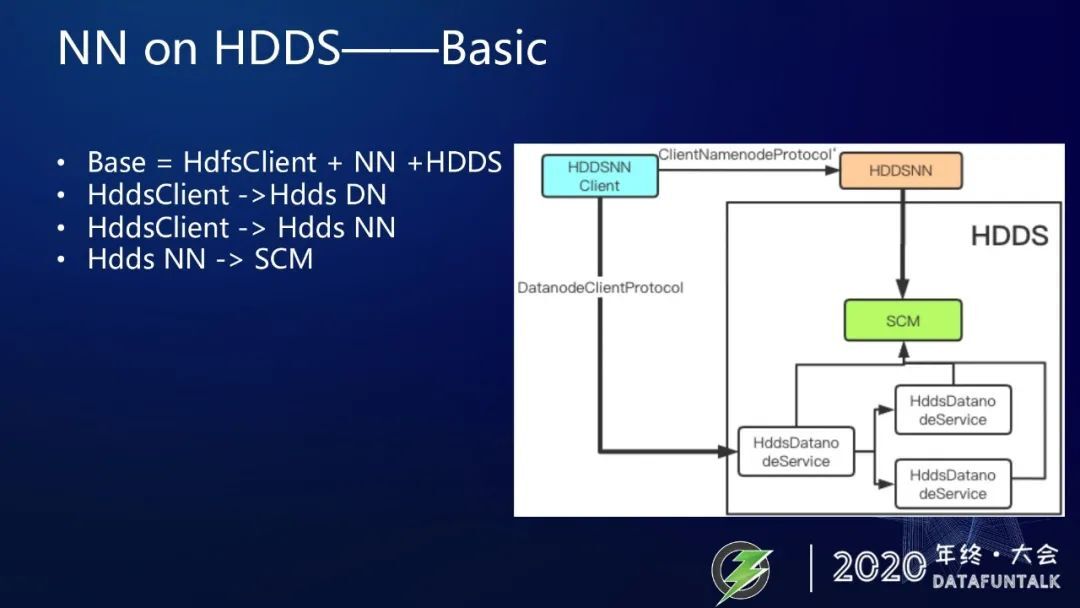
我们是基于 HDFS 源码进行二次开发:
实现了 Client 到 HDDS Datanode 的通信,这就可以进行正常的块读写了。
我们还修改了 Client 到 HDDSNN 的协议,使得 Client 可以通过 HDDS NameNode 向 SCM 申请 block 了。
对于与块无关的操作,比如 createFile,mkdir,rename 等等,都无需任何改动。
这张图,可以看出我们增加了 HDDSNN,作为文件系统元数据管理操作。HddsNN 可以与 SCM 通信,进行 block 的申请和删除操作。
还增加了 HddsNNClient 可以同时访问 HddsNN,进行文件系统元数据请求,也可以访问 HddsDataNode,进行数据块的读写。
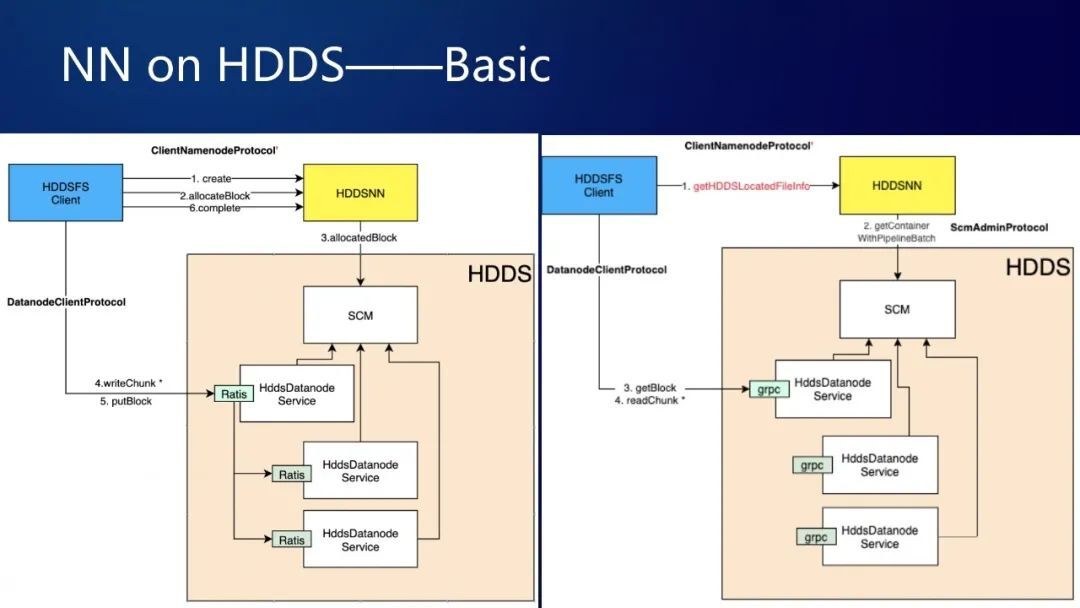
上面两张图分别展示了具体的读写流程,左边是写流程,比如说你在你想创建一个文件,你先是有一个创建文件的 RPC 请求,由 client 发到 HDDSNN,然后 HDDSNN 创建了一个元数据,接下来 HDDSFS Client 向输出流去写数据,写数据过程当中它会发现没有 Block,所以就会去向 HDDSNN 去发送 allocateBlock 请求,HDDSNN 就什么也不干,把 allocateBlock 请求发给 SCM,SCM 负责把 Block 给 allocate 出来,然后返回给 HDDSFS Client。接下来就可以执行写 block 逻辑了。Client 向 DataNode 通信,先 write 一些 chunk,最后到了一个 block 的时候就会发送一个 putBlock 请求,完成写一个 block 的流程。整个过程都完成了,最后就会发一个 complete 的 RPC 请求,HDFSNN 收到 RPC 请求就会把文件标记成完成。这样一个写流程就完成了。读流程大致类似,不再赘述。
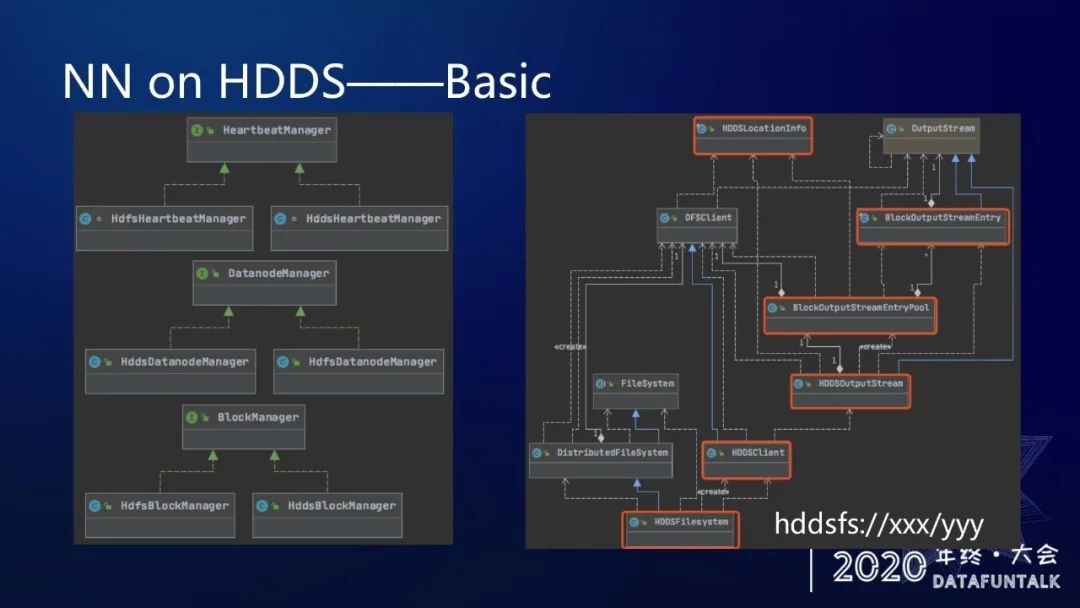
实现了功能的同时,我们还有一个更高端的目标:
一套代码,既可以启动 HDDSFS,也可以启动 HDFS,通过一个配置项进行区分。
这是因为我们抽象化了 BlockManager、DatanodeManager、heartbeatManager,分别有 HDDS 版本 和 HDFS 版本的实现。
我们也实现了 odfs schema 对应的 Hadoop 兼容文件系统实现类 —— HddsFilesystem。
这样同一个 client,就可以同时支持读写 hdfs 和 hddsfs 了。
右边的类依赖关系图,红框是我们新加的类。大部分是继承或扩展自 HDFS 现有的类。写块的具体实现细节在 HddsOutputStream 里。

我们这一阶段的目标,非常清晰明确,就是实现一个 Client 和 NameNode,可以借助 HDDS 的存储能力,提供文件系统服务。
HDDSFS 由于将块管理、节点管理、心跳管理等功能分离出去,存储相同规模元数据,节省内存 40+%。
因为 HDDSFS 避免了块汇报风暴,对于 1 千万个小文件,重启速度是 HDFS 的 4 倍。
另一方面,由于 HDDSFS 有文件语义的元数据树形结构,相比 Ozone 来说,在文件夹操作性能上有着明显的优势。
其中在 10 万子节点目录的 Rename、delete 等操作就有 100+倍性能提升。( 异步删除功能,提升更高 )
基于文件夹属性的相关操作 ( modification Time, set mode, set owner ),OzoneManager 根本上就不支持,而 HDDSFS 完美支持。

下面这一阶段,我们的目标就是通过实现细粒度锁,优化高并发吞吐,提升集群性能。
对 HDFS 的原理是有一些了解的同学,都应该知道 HDFS 是需要把 FsLock 还有 FsDirLock 都加锁之后才能做具体的操作。现在我们把 FsLock 的部分 writelog 变成了 readlock,这是因为我们把 Block Manager 功能对接到 SCM 里了。有这样的一些改动,这样就使得我们有一些操作是可以并发执行的。同时我们把 FSDirectory 里边的 lock 改成细粒度锁了,这使得集群的吞吐可以得到很大限度的提升。
我们的改动方案就是把 FSDirectory 中的 readwritelock 修改成基于 locklist 的层级锁。我们看上图右边表格来具体说明一下,比如说你要去 list 一个文件夹 /a/b,原来可能是要去加个全局读锁,然后再去做操作。现在不是加一个全局锁,而是给这样的一个根加一个读锁,a 加一个读锁 b 加一个读锁,然后才会把下面的子节点 list 出来返回回去。这样就可以看出来是一个 locklist。再举个写的例子,比如 createFile 要在 /a/b 个文件夹下面去创建一个 c.txt,要给 c 加读锁 d 加读锁,然后下面再加一个 c.txt 新创建这个文件是加了一个写锁,了解内幕的同学可能就会发现这样不对,我们现在一个 directory,下面这个是一个 Children 是一个 array list,相当于是线程不安全的数据结构。
如果几个线程同时 create 就会出现线程不安全的问题。没错,我们就踩过坑,把 children 改成线条安全的数据结构,这样的好处就是它父节点就不需要加写锁了,通过这样设计的一个细粒锁隶属于两个文件就是不同的大目录下边的文件的操作就可以相互不干扰。相比 HDFS 的删除或者 DU 某个目录的时候,整个集群的性能就会明显的下降,通过粒粒锁的优化,这个性能会有明显的提升,它的吞吐从整体上也会显著的提高。
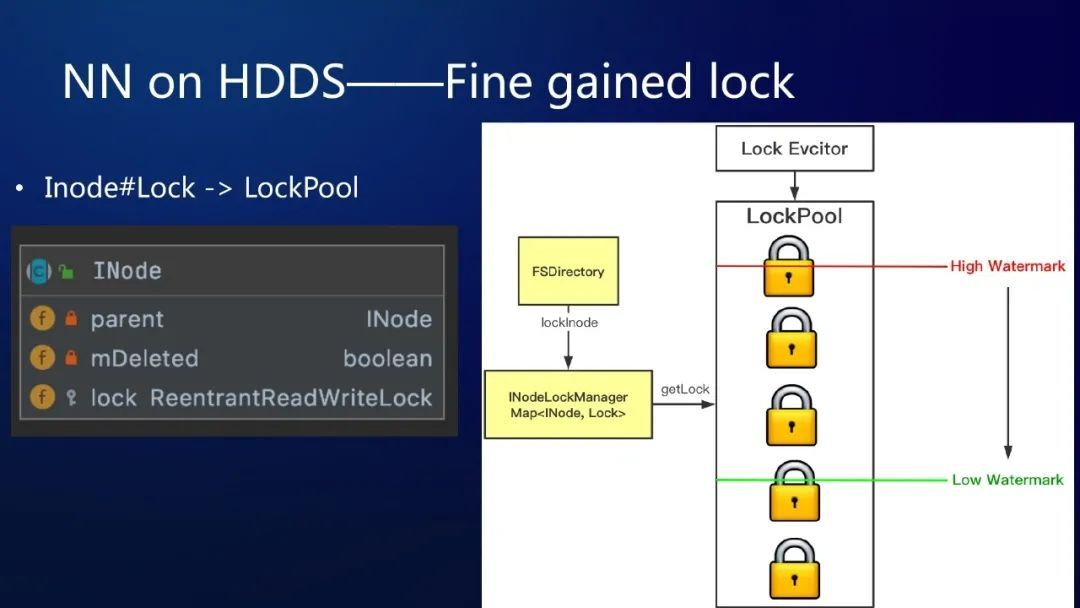
大家可以试想一下,如果一个 Inode 都关联一个 ReentrantReadWriteLock, 内存会增加多大?本来内存就很吃紧,额外增加太大的内存,肯定是无法接受的方案。
因此,我们借鉴了 Alluxio 2.0 引入的 LockPool 的概念。什么是 LockPool 呢?就是,有一个资源池,lock 就是资源池中的一个锁资源。每一个 Inode 不再关联一个 Lock 了,而是需要 Lock 加锁的时候,就去资源池里申请锁,同时引用计数会增加,用完了 unlock 掉的时候,引用计数会减少。
LockPool 有一个勤劳的 LockEvcitor,会在 Lock 达到 high watermark 的时候,进行 evict,直到降低到 low watermark。
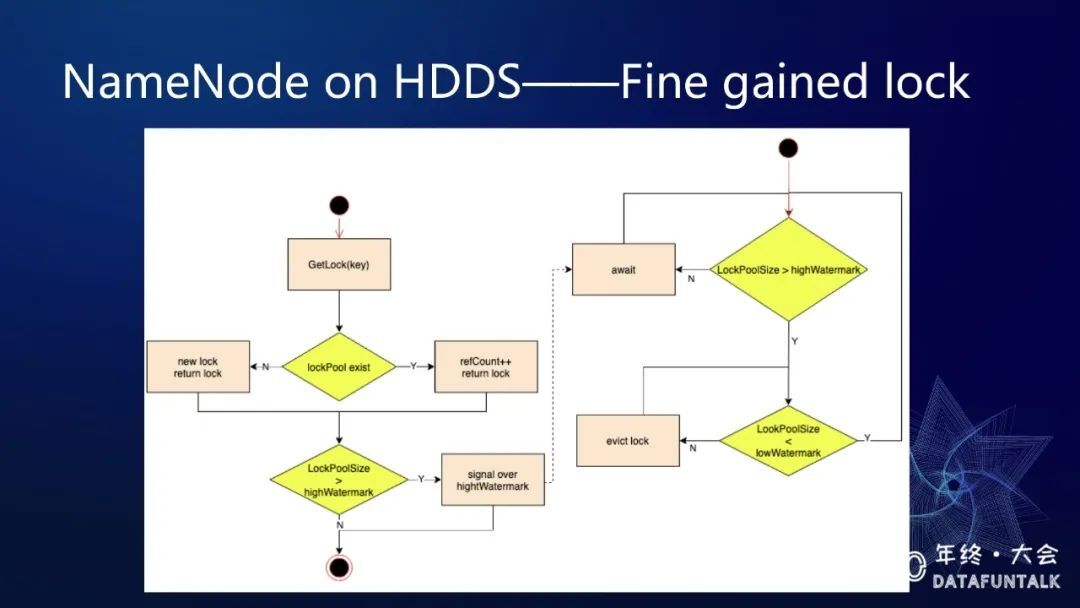
上面这一张流程图,也可以帮我们去理解 lockPool 它异步的 lock Evictor 的工作原理,上面左侧是一个线程从 lockPool 里去获取一个 key 对应的 lock 的流程,判断 key 在 lockPool 里面是否存在,这是第一步,如果不存在就会创建一个 lock,如果存在就会让它的 refCount 加一,直接就返回了。然后他会判断一下 lockPool 的 size 是否达到了高水位,如果超过了高水位就会发一个 Evictor 的信号。右侧的是一个线程,它会一直检测 lockPool 的 size 是否超过高水位,如果没超过高水位,它就会 await 等待信号来给它触发。当发现了已经超过高水位了,就会进行 Evictor 操作踢出没有引用的 lock,直到达到了低水位。关于细粒度锁,后续还可以区分具体的 创建、删除、修改等写操作,加不同的锁,从而最大限度的提升吞吐,能不锁就不锁,能用读锁不用写锁。
NN on HDDS——Lock Guard

我们做了这么大的一个根基性的改造,就难免会出一些 bug 或者意料之外的事情,所以我们也给自己留了后路,就是开发了一个 Lock Guard 这样的一个 feature,帮我们去诊断出死锁、忘放锁、常占锁等情况,采用的办法就是启动一个检测线程,检测 lock 的持有的时间是否超过了预期,这个时间预期可能有多个标准,达到不同的标准会有不同的处理,然后会有一个 metric 去来统计,超过这个时间标准的 lock 数量,当 metric 增加了,然后我们就可以收到一些报警的一些 alert,同时会向日志里边去打印一些警告日志。我们收到报警以后就可以去登录到机器上去看具体的到底是哪个 lock 出了问题以及 lock 的一些上下文信息都可以把它打出来。当然这个功能会增加一些内存的开销性性能的损耗,所以是可以动态去开关的。当收到报警信息后,就可以使用命令行工具利用拿到的锁 ID 去分析占锁的情况。
NN on HDDS——Tired Metadata Management

第三个阶段目标就是通过 RocksDB 实现元数据无限扩展。在内存空间中,我们可以很容易把文件和文件夹用一个 Tree 来进行管理,但是 RocksDB 也是一个 KV 存储。我们需要把元数据切分成两张表,第一张表是放 inode,这里 inode 包括 inodeFile 和 inodeDirectory,使用 inodeId 作为 key。第二张表是放 inode 之间的关系,key 为 parentId 和 childName 聚合的字符串,它的形式就是,””,value 就是 child 的 inodeID。
我们举个例子,比如说你要去获得 “/dir/file” 的元数据信息怎么办?首先是根不用找,根的 ID 就是 0,接下来就是找 /dir,于是去 Edge 表中查找 key 为 “0,dir” 的记录,可以找到,value 为 1,也就是说 “dir” 的 ID 是 1,接着再找 “1,file”,在 Edge 表中是可以找到,也就是说 “file” 的 ID 也是 2,最后我们在 inode table 里面去找 2 的 value,就可以找到了 “/dir” 和 “/file” 的元数据了。
NN on HDDS——Tired Metadata Management
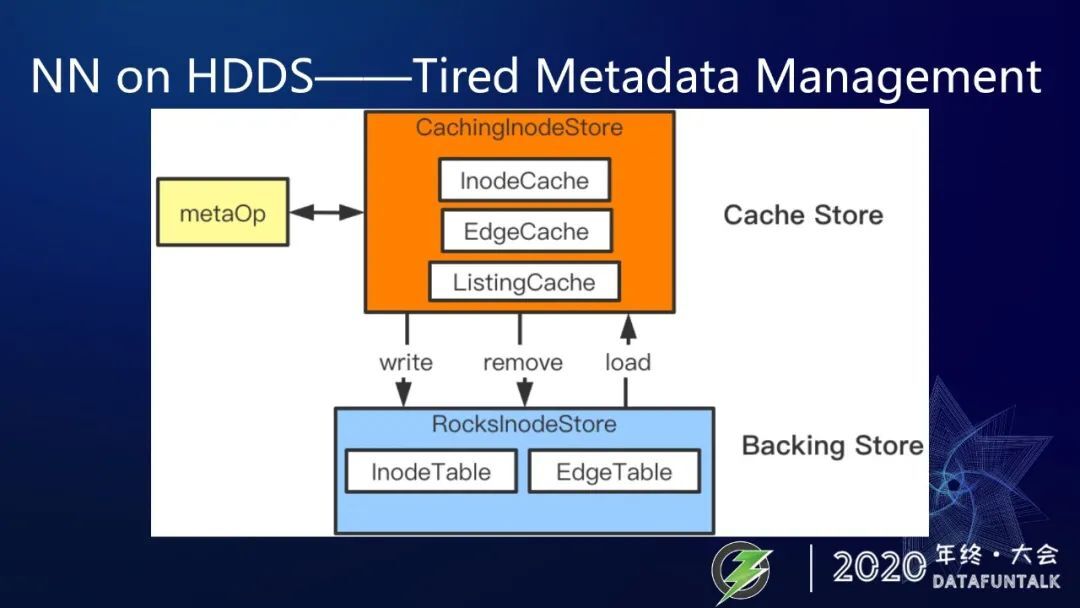
这一通操作显然是在内存里边是会比在 RocksDB 里面要快很多。因此需要进行分级元数据管理,比如说增加一个 cache layer。什么是分层级元数据管理呢? 有什么益处呢?
在一个存储系统中,不光光只有它所存储的数据文件重要,它的存储系统的元数据管理同样十分的重要。因为涉及到存储系统数据访问操作时,会经过存储系统的,元数据的查询或更新操作,如果元数据这边的操作出现性能瓶颈,同样会导致用户访问数据的行为出现缓慢的情况。本文我们来聊聊存储系统一般是如何做高效的元数据管理的,这里面会涉及到多种不同的元数据管理方式。
其实,存储系统的元数据管理,是存在演变过程的。初代元数据管理,元数据存储于外部 db 中,然后 master 服务和 db 进行数据的交互。内存管理式的元数据管理,master 服务在初启动后加载外部元数据 db 文件到内存中。分区式元数据管理,将元数据按照给定规则进行 partition 的分拆,然后启动多个 master 服务来管理各自的应该维护的元数据。分层级的元数据管理 ( tiered metastore ),是一个既可以无限扩展,又可以保证活跃数据性能不下降的一种策略。最近访问的热点元数据,做内存缓存,叫做 cached layer,很久没有访问过的数据 ( 也可称作冷数据 ),做持久化保存,叫做 persisted layer。在此模式系统下,服务只 cache 当前 active 的数据,所以也就不会有内存瓶颈这样的问题。这张图是一个此模式的样例系统的元数据管理模型图。
相比较于 HDFS Namenode 将元数据全部 load 到 memory 然后以此提高快速访问能力的元数据管理方式,但内存却成为了元数据扩展上限,以及 Ozone 对所有元数据的读写都要通过 rocksdb,性能下降成为了最大的问题。因此,HDDSFS NN 需要在这点上做优化改进,只 cache 那些 active 的数据。对于那些近期没有访问过的冷数据,则保存在本地的 rocksdb 内。
在分层级的元数据管理策略中,在内存中 cache active 数据的存储层,我们叫做 cache store,底层 rocksdb 层则叫做 backing store。
这个概念以及相应的设计,我们也参考了 Alluxio 和 Ozone filesystem 的设计。
NN on HDDS——RAFT Based HA
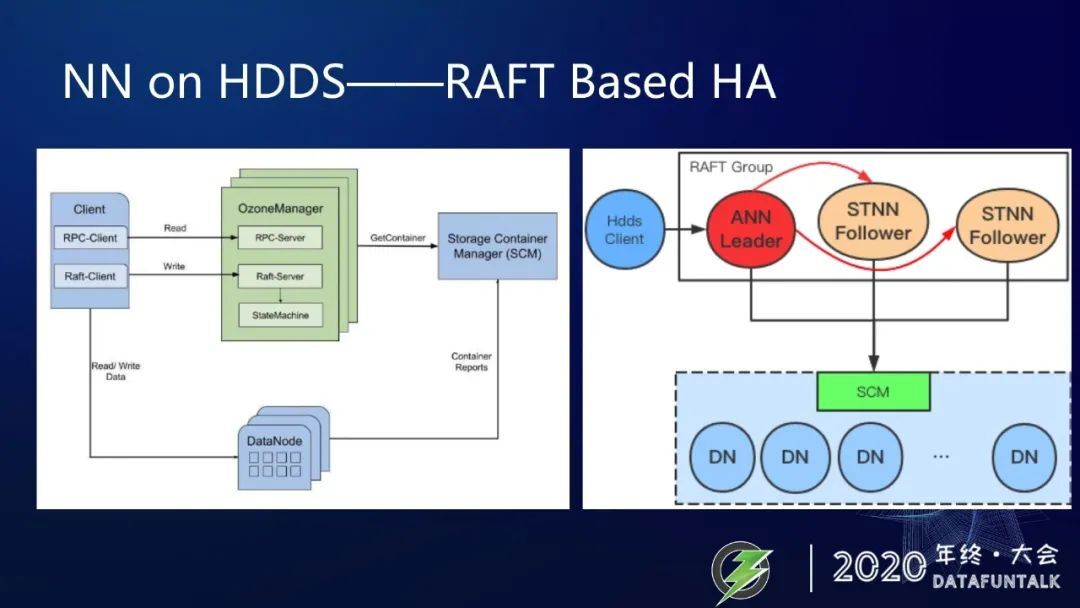
最后一个大的架构升级就是 HA 升级,只需要有 3 个 HDFS NameNode 组成的这样一个 RAFT Group 不依赖于外部的组件就可以实现 HA 功能。区别于 Ozone Manager 的 HA 实现需要 client 通过 RAFT 协议与三个 OM 组成的 RAFT Group 通信,也就是说与 leader 的 OM 通信,leader OM 把 client 的请求记成 RAFT 的 log,然后再同步给两个 follower。
我们的设计中是由三个 NameNode 组成一个 RAFT Group,但 client 采用的 follower 的方式找到 leader 的 NameNode 与之通信,leader 的 NameNode 会执行 client 的请求,然后再把写操作记录到基于操作日志 journal 里面。当 RAFT Group 的 leader 切换时,每一个 NameNode 会设置自己的 leader 状态,只有 leader 才会接受外部的请求,当 leader 切换的时候,失去 leader 状态的 NameNode 就会重置状态,并且载入到 NameNode,这样就可以达到内存状态是与 RAFT log 是一致的。
在 HDDS NameNode 的 HA 设计中,我们参考的也是 Ozone Manager 的 HA,还有 SCM 的 HA,还有 Alluxio 2.0 引入的基于 Ratis 的 HA,目前我们前两个阶段其实已经实现了,但是我们第三个阶段还在进行中,所以感兴趣的小伙伴可以加入我们一起去干这些伟大的事情。
腾讯的贡献

腾讯的贡献清单有很多,不一一介绍了。6 个 committer,其中还有 2 个 PMC,还有 1 个 Chair。这位 Chair,就是我们团队的 Sammi ( 陈怡 )。同时也作为 Ozone 1.0.0 这个非常有重大意义的版本的 Release Manager。
Ozone 的未来
1. Ozone 的未来

再看看 Ozone 的一些未来,Ozone 未来还有很多事情要做,像 SCM HA、HA 状态切换等等都需要继续去开发。在大数据的生态里边 Ozone 还是有很多对应的一些功能要去实现。Erasure Coding 功能现在 Hadoop 里边已经实现了还不错了,但是在 Ozone 里面目前还是设计阶段。HDFS 的一些 API,如果说你想替换它,肯定要把这些 API 完美的支持,像 append/truncate/hflush 都需要继续把它们提到社区里面。Datanode 的一些健康检查、动态改配置、中心化的配置管理、还有是 container 的一些 balancer 这样的一个功能,这些现在还是都需要我们补充的,就不一一介绍了,其实还有很多工作要去做。

Native Object Store
https://www.slidestalk.com/TencentCloud/TencentCloudOzone
向成熟化迈进 - 腾讯 Ozone 千台能力突破
https://cloud.tencent.com/developer/article/1667033
文件系统和对象存储区别
https://ubuntu.com/blog/what-are-the-different-types-of-storage-block-object-and-file
Ozone 开发者资源
https://docs.qq.com/doc/DZUJFSXFuZHFXRGZp
Goofys 的增量版 Goofuse
https://github.com/opendataio/goofuse
HCFSFuse
https://github.com/opendataio/hcfsfuse
这个就是我本次分享所引用的一些文章,其中标绿色的 Ozone 开发者资源,就建议收藏,它里边有很多面向开发者的一些资源,比如说本文提到的 Ozone 的一些视频,以及新开发者怎么去开发等等,建议大家去加入 Apache slack workspace,并加入 ozone channel,这里边有邀请连接,后边是两个我们开发的 Fuse 项目,HCFSFuse,以及 GooFuse,作为 Ozone 的 Fuse 实现都可以利用 Fuse,把 Ozone 挂载成本地盘。大家感兴趣也可以关注一下。
2. 总结
最后总结下,我们总体还是超前设计,但是分阶段去向前迭代,我们也制定了一些优先级,先完成高优先级的需求,在这一阶段把它产出一些成果,我们也不像某些公司做一些分包制,这个功能就包给你了,然后你自己去对他结果负责。我们不是这样,我们是高度的协作,大家一起来去面对问题。然后测试这方面也是重视质量保证的,像 TDD ( 测试驱动开发 )、CI ( 持续集成 )、Nightly build、code review。
我们借鉴了 Alluxio、HDFS、Ozone、RATIS、Ceph 等诸多开源软件的设计和源码,也参考了美团的拆锁方案。
Ozone 想成为 HDFS 的下一代的存储系统,需要切实替代 HDFS 的一些场景能力,期待下一个十年 Ozone 可以家喻户晓,成为各大技术公司中的技术栈中的底层存储。
本文转载自:DataFunTalk(ID:atafuntalk)




