
大数据计算的兴起,源于 Google 的 MapReduce 论文,MapReduce 的原理很简单,其流程核心则是 Map 和 Reduce 两阶段数据交换,也即 Shuffle。
Shuffle 对大数据计算影响很大,从公开的资料:Facebook[1]、LinkedIn[2]、阿里[3] 等公司的数据看,Shuffle 影响的任务和任务计算时间上都有较高占比。从 OPPO 的线上任务看,68%的 Spark 任务都有 Shuffle 计算。
大数据计算引擎的技术演进,一直离不开对 Shuffle 的优化,无论是从执行计划方面优化,尽量避免 Shuffle 算子还是各种 Shuffle 机制的演进,都是为了尽量缩短 Shuffle 的耗时。
Shuffle 不仅影响作业运行效率,对计算稳定性也有较大影响,大数据开发的同学一般都有这样的经历:莫名的 Shuffle Fetch Fail 错误,甚至任务会因此频繁失败,不得不优化任务计算逻辑。
背景
Shuffle 成为大数据计算效率和稳定性的关键因素的原因是什么?
我们认为主要有两点:
1、磁盘的碎片读写,Spill 多次写磁盘和 Reduce 只拉取部分 Partition 数据,影响效率。
2、Reduce 读取 Map 端本地数据,需要 MxR 次远程网络读,影响稳定性。
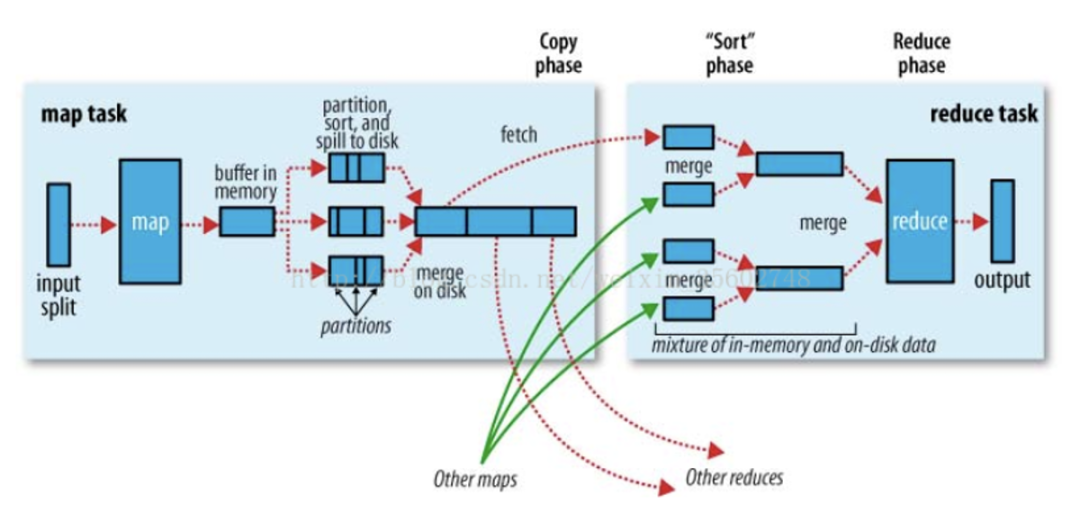
MapReduce shuffle 示意图[4]
Shuffle 技术演进,主线也是沿着解决上面两个问题推进。比较有里程碑意义的有两个方向:
ESS:External Shuffle Service,ESS 原理是 Map 任务在计算节点本地将相同 Partition 数据合并到一起;
RSS:Remote Shuffle Service,RSS 原理是 Map 任务将相同 Partition 数据 Push 到远端的 RSS,RSS 将同一 Partition 的数据合并。
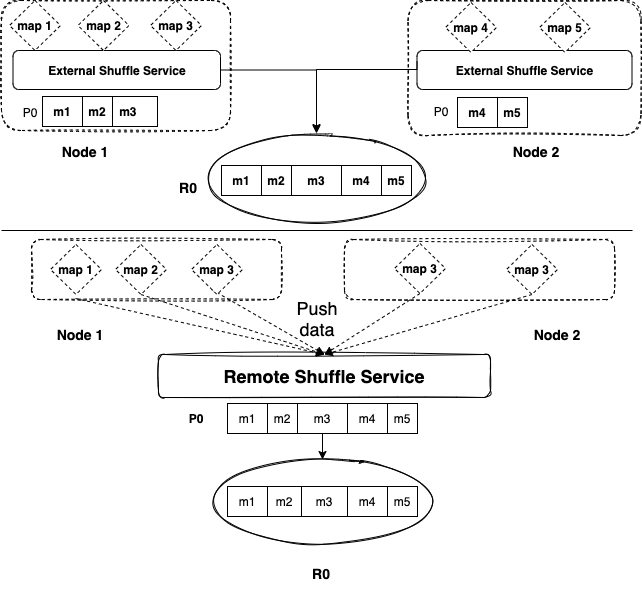
ESS vs RSS 示意图
ESS 和 RSS 都是为了解决前面我们提到的碎片读写和 RPC 连接过多的问题,ESS 是缓解了这种情况,没有 RSS 解决的彻底。
Spark 社区提供了 Remote Shuffle Service 的接口,各家公司可以自己实现自己的 RSS。所以,近两年在 Spark 平台的 RSS 技术方案如雨后春笋,纷纷公开亮相。
相关工作
我们先看一下各家的解决方案,目前公开资料和源码的方案主要有:
Uber 的 RSS [5]:2020 年开源,底层存储基于本地磁盘,Shuffle Server 提供读写数据功能,对性能有一定的影响,另外,开源时间比较早,但维护较少。
腾讯的 FireStorm [6]:2021 年 11 月开源,底层存储使用 HDFS,对稳定性以及性能优化设计考虑较少。
阿里云 EMR-RSS [7]:2022 年 1 月开源,底层存储基于本地磁盘,对本地 IO 做了深入的优化,不过这种基于本地存储的 Shuffle Service,有着天然的限制。
LinkedIn MagNet [2]:MagNet 严格来说不算真正意义的 RSS,只能算是 Push Based 的 Shuffle。MagNet 在 Spark 原生 Shuffle 数据落盘的同时把数据 Push 到远端 NodeManager 的 ESS 上,同一份数据,会落盘两次,这样其实会增加集群的 IO 压力。不过,MagNet 已经合入到 Spark3.2 版本,鉴于此,MagNet 的 Shuffle 才做了这样的设计。
OPPO 解决方案-Shuttle
整体架构
首先,介绍一下 Shuttle 的整体架构:
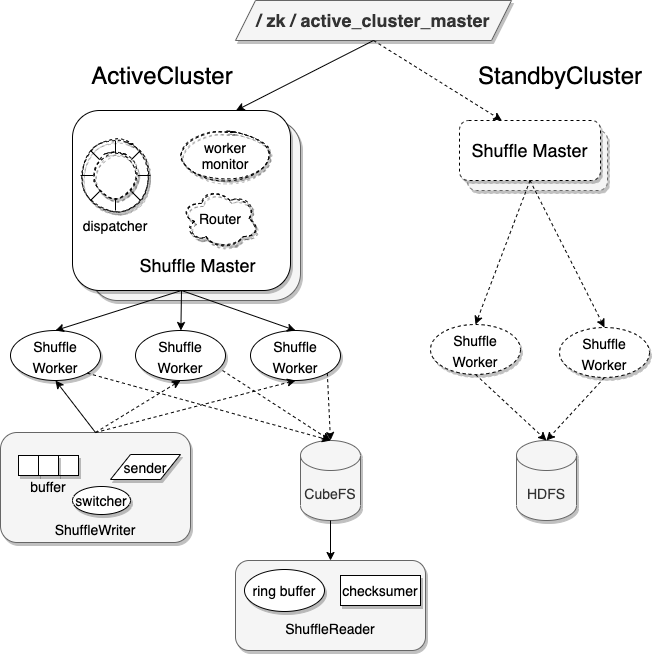
Shuttle 架构图
Shuttle 主要由两个角色组成,ShuffleMaster 和 ShuffleWorker。
ShuffleMaster 负责管理 ShuffleWorker 的状态,向任务分发可用的 ShuffleWorker。
ShuffleWorker 负责接收 ShuffleWriter 发送的数据,并将同一 Partition 的数据聚合,写入分布式存储。
为保障 Master 高可用,一个集群有两个 Master,一个 Active 和一个 Backup Master。
如图所示,ActiveCluster 和 StandbyCluster 分别有两个 Master。
为什么会有 Active 和 Standby 两个 Cluster ?这也是为了服务的稳定性考虑,主要用于热升级,下面会详细介绍。
架构设计考量
我们在设计一个分布式的 Shuffle Service 系统的时候,从下面几个方面考虑:
1.数据正确性
数据正确性是生命线,Shuffle 数据在 Remote Shuffle Service 系统走一圈,能否保障数据不出问题?
我们通过 Checksum 机制保障数据的正确性。每一条写入 Shuttle 的数据,都会计算一个 Checksum 值,最后读数据的时候同样对读取的每一条数据计算 Checksum,最后对比 Checksum,保证每条数据都被正确读到且只被读一次。
2.稳定性
稳定性是分布式系统的基石,在分布式系统中,出现各种问题是必然。
稳定性的保障,是一个系统性的问题,不是某一个 Feature 或者设计能解决所有稳定性问题,我们从以下几个方面讨论 Shuttle 的稳定性建设:
A、节点/任务管控
ShuffleMaster 和 ShuffleWorker 在管控方面都有自己的机制。
ShuffleMaster 对节点/任务管控的功能主要有:
节点自愈:ShuffleWorker 通过心跳向 ShuffleMaster 上报自身的“健康”信息。心跳超时或者“健康”信息异常,ShuffleMaster 会暂停向该节点分配新的任务数据流量,Worker 节点恢复“健康”后,再向改节点分配任务。
负载均衡:Spark 任务向 ShuffleMaster 请求可用的 ShuffleWorker,Master 根据集群负载决定分配哪些 ShuffleWorker;同时,分配 Worker 的算法实现是插件式的,可以定制多种不同的分配策略。
异常拦截:对于用户短时间提交的大量相同任务,ShuffleMaster 会主动拦截,避免影响集群整体稳定性。
ShuffleWorker 流控机制,当任务数据量突增场景下,流控保障 Worker 的稳定性。流控机制主要从两方面限制:
内存量:ShuffleWorker 进程使用总内存超过阈值即发生流控
连接数:同时向 ShuffleWorker 发送数据的连接数,超过阈值即发生流控
B、多机切换
Map 向 ShuffleWorker 发送数据,会有多个 ShuffleWorker 可供选择,当某个 Worker 出问题(比如 Worker 发生流控,或节点掉线),可以切换到备选 Worker 继续发送。
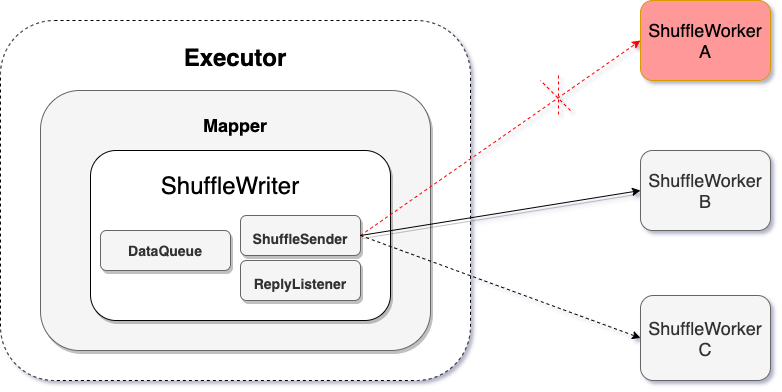
如图所示,ShuffleWriter 在向 ShuffleWorker A 发送数据的时候,A 节点出现故障,ShuffleWriter 切换到 B 节点继续发送数据。
C、分布式存储
Shuttle 采用分布式文件系统作为存储底座。
在分布式存储技术如此发达的今天,我们不需要花费过多精力优化存储。
专业的事情交给专业的“人”来做,这样的好处主要有:
1、降低 Shuttle 系统本身的复杂度,提升自身稳定性
2、分布式文件系统自身具有良好的稳定性,扩展性,负载均衡等优势
3、适配多种分布式文件存储,选择多样化,充分利用不同系统优势
4、使得 ShuffleWorker 解耦本地存储能力,存算分离,更易于云上部署
业界主流的分布式文件系统,本身对读写性能都做了充分的优化。
另外,我们大量使用了公司存储团队自研的分布式文件系统 CubeFS[8],CubeFS 针对 Shuffle 场景做了定制化的优化,简单介绍一下 CubeFS 的优势:
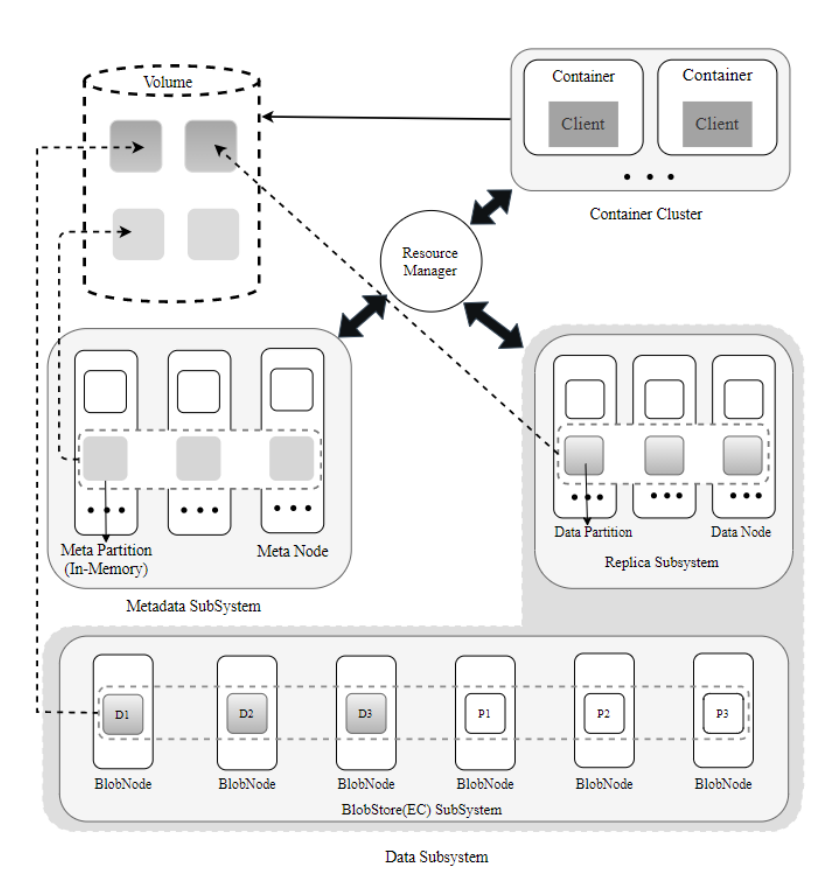
CubeFS 架构图
CubeFS 是 CNCF 新一代云原生分布式存储产品,兼容 S3、HDFS、POSIX 多种接入协议,提供多副本和纠删码两种存储引擎,支持多租户、多 AZ 部署。
CubeFS 创新性采用存算分离架构,提供可扩展的元数据服务,低成本的模式可配的纠删码引擎,自适应多级缓存特性,使得 CubeFS 在稳定性、扩展性、性能与成本、可运维性等方面均表现优秀;对多种接入协议的原生支持,与容器兼容性好,拓宽了 CubeFS 产品生态;CubeFS 已经被用于 OPPO 各个核心业务,如大数据存储,大数据 shuffle、人工智能、ElasticSearch、MySQL、数据备份等,有力支撑各类业务数据海量存储需求。
D、热升级
ShuffleService 一旦上线,会为大量任务提供 shuffle 服务,不能停服,同时,系统的升级迭代会不断需要重启服务。为此,系统必须具备热升级的能力。
Shuttle 有两种热升级模式:
1、滚动升级:通过 ShuffleMaster 逐一加黑-重启 ShuffleWorker。
这种方式针对小规模系统还可行,对于规模比较大的 ShuffleService 系统,可以考虑第二种模式。
2、集群切换:ShuffleWorker 进程绑定机器 IP 和端口,一台机器可以部署多个 Worker 进程,因此我们在线上同一批机器部署两套 ShuffleService,升级的时候可以直接整体切换服务。
上线以来,经历线上多次升级变更,无一例因为升级导致的失败 case。
3.性能优化
A、异步传输
数据传输和消息处理,均使用 Netty 异步处理机制,对比同步处理机制,性能有明显优势。同时,消息采用 Pb 格式,提升消息序列化和反序列化性能。
B、并发读写
ShuffleWriter 和 Reader 对于数据的读写均采用多线程并发处理,在 Reader 端使用 RingBuffer 作为底层存储的缓冲,读过程异步化。
C、定制线程池
ShuffleWorker 会并发处理不同的 Map 发送的数据,使用 Java 原生线程池会引入过多的同步机制,影响处理数据速度。为此,我们定制线程池,确保同一 Partition 的数据交由单一线程处理,显著降低同步操作,提升处理速度。
不仅如此,为优化数据传输效率,我们根据网络 MTU 定制数据包大小,精益求精。
4.扩展性
A、多集群路由
ShuffleMaster 可配置任务路由规则,多个集群在线服务,随时可以切换流量。在集群出现异常,任务可以选择切换到正常的集群。
B、多存储共存
目前 Shuttle 支持 HDFS、CubeFS、Alluxio、S3 等分布式存储系统,多种存储可以同时在线提供服务,无论是云上还是自建集群,均可应对。
同时,Shuttle 设计就考虑到 Spark3.x 的 AQE 特性支持,我们线上同时运行着支持 Spark2.4 和 Spark3.1.2 版本的 Shuttle。
业界相关技术对比
针对稳定性,数据正确性保障,性能优化方面,我们跟业界相关工作做了对比。

Shuttle 在稳定性和性能优化方面做了很多考量,系统上线后一直提供稳定服务,期间多次升级,无一任务因此失败,下面会介绍一下我们的性能测试效果。
测试效果
文章[3]中,EMR-RSS 已经跟其他的开源产品做了详细的对比测试,且在性能上有明显的优势,所以,我们直接跟 EMR-RSS 对比测试。
测试环境
硬件环境:20 台物理机
机器配置:24 块 HDD,内存 384GB,cpu 48 核心。
软件配置:
Shuttle 使用 HDFS 存储,均使用默认配置
EMR-RSS 使用本地存储,配置使用所有磁盘。rss.shuffle.writer.mode 配置为 sort(默认为 hash)
测试任务:TeraSort Spark 任务
静态资源分配,Executor 800,分区数 1000,其他使用默认配置。
测试结果
EMR-RSS 1Tb TeraSort:

Shuttle 1Tb TeraSort:

EMR-RSS 5Tb TeraSort:

Shuttle 5Tb TeraSort:

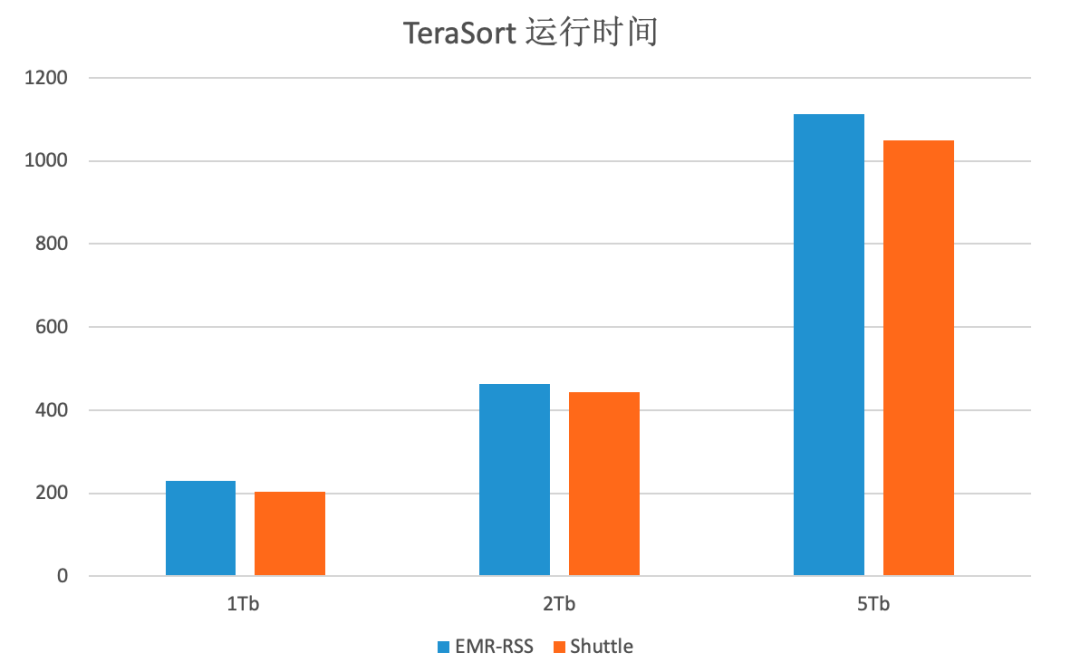
注:不同规格任务运行时间,两种技术方案分别运行 5 次求平局值对比
整体看,Shuttle 和 EMR-RSS 对比 TeraSort 任务在几个不同规模数据量上有 4%-8%的性能提升。
测试分析
Shuttle 的读数据明显快,分析原因如下:
1、Shuttle 读数据从 HDFS 读取,不占用 ShuffleWorker 进程资源;
2、Shuttle 读数据方式是异步流水线方式。
但是,我们也看到 Shuttle 在写数据要比 EMR-RSS 慢,分析原因如下:
1、Shuttle 的流控机制,在每次发送数据包会先获取一次令牌,多一次网络交互。
2、Shuttle 的 Checksum 机制,在每个分区数据发送完毕后,会多发一个 Checksum 包,且最后的 Checksum 包是同步方式通信。
由上分析,Shuttle 在保障稳定性和数据正确性上做了一些性能取舍。但是,由于读数据的 速度更快,不仅弥补了写数据导致的性能 Gap,整体性能还是有提升。
线上效果
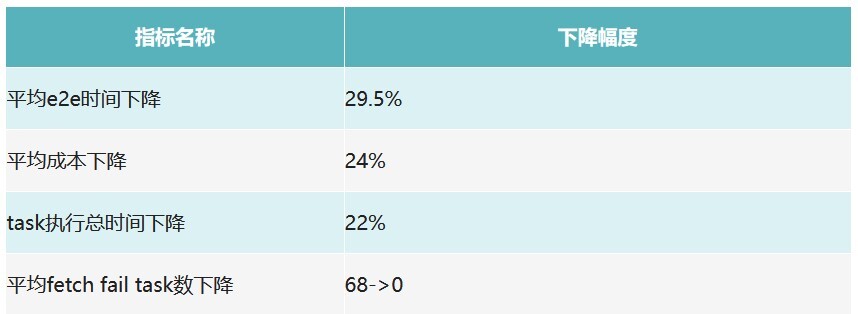
目前,OPPO 集团大数据计算任务 30%的 Shuffle 数据已经接入 Shuttle,效果最好的大任务执行效率提升 50%+;整体效果数据见下图:
未来展望
为了让 Shuttle 能够影响更多的计算,我们决定将 Shuttle 项目开源[9]。
对于技术演进方向,我们计划从三个方向进行:
1、接入更多的计算引擎,比如 Flink、Trino 等。
2、依托现有的分布式存储,优化底层存储,适应 Shuffle 场景的特殊需求。
3、提供更多的计算服务,不局限于 Remote Shuffle 服务。
关于作者:
David Fu :OPPO 大数据计算平台架构师。负责大数据计算平台技术演进设计开发,曾供职于阿里云,去哪儿网大数据平台,拥有 10 年大数据架构,开发经验。
XuEn:OPPO 高级数据平台工程师,目前就职于 OPPO 数据架构团队,主要负责 Spark 计算引擎和 Shuttle 的开发,拥有丰富大数据架构和开发经验。
附录
[1] Haoyu Zhang, Brian Cho, Ergin Seyfe. Riffle: Optimized Shuffle Service for Large-Scale Data Analytics. ACM 2018
[2] Min Shen, Ye Zhou, Chandni Singh. Magnet: Push-based Shuffle Service for Large-scale Data Processing. VLDB 2020
[3] 阿里云 EMR Remote Shuffle Service 在小米的实践。
https://mp.weixin.qq.com/s/xdBmKkKL4nW7EEFnMDxXYQ
[4] 《Hadoop 权威指南》
[5] Ubser Spark RSS: https://github.com/uber/RemoteShuffleService
[6] 腾讯 Spark RSS FireStorm:https://github.com/Tencent/Firestorm
[7] 阿里云 Spark RSS:https://github.com/alibaba/RemoteShuffleService
[8] CubeFS:https://github.com/cubeFS/cubefs
[9] Shuttle: https://github.com/oppo-bigdata/shuttle




