
本文共分为六个部分,第一个部分是关于图匠数据公司的介绍,第二部分针对自然场景 OCR 识别技术的简介,第三部分关于深度学习 OCR 技术的简介,第四部分是深度学习超分辨率技术的简介,第五部分结合我们今年在 ECCV 会议上发表的一篇文章,plugnet,介绍关于低质文本文字识别方面的工作,第六部分是工作总结。
图匠数据公司介绍
首先是关于图匠数据公司的介绍。
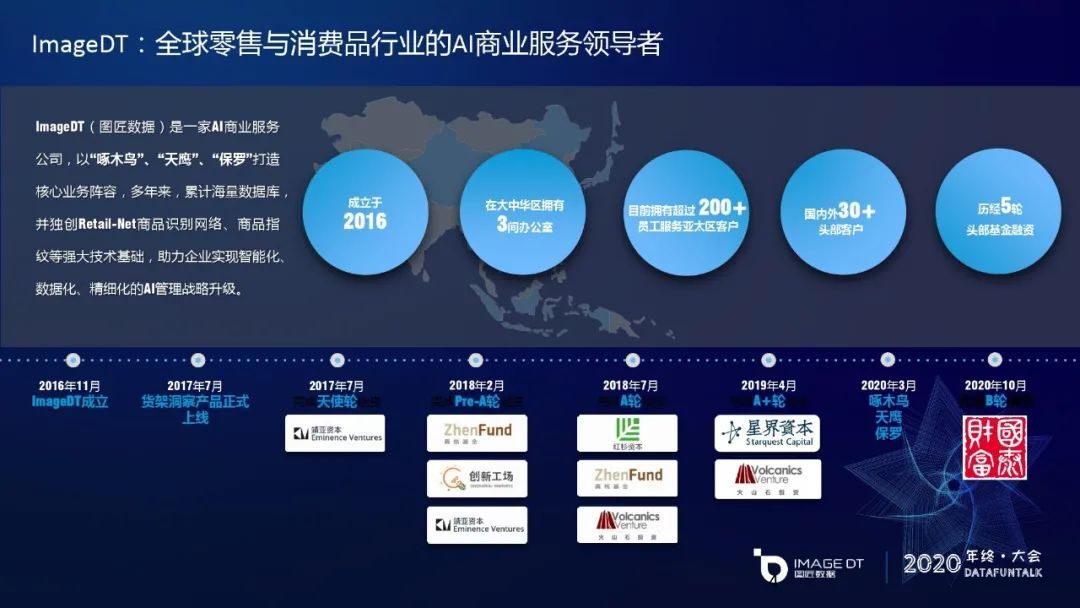
图匠数据的英文名叫 ImageDT。它是一家全球零售与消费品行业的 AI 商业服务领导者,成立于 2016 年 11 月,经过近几年的迅速发展,已经经历了五轮的头部基金融资,目前推出了啄木鸟,天鹰,保罗三款核心业务产品。
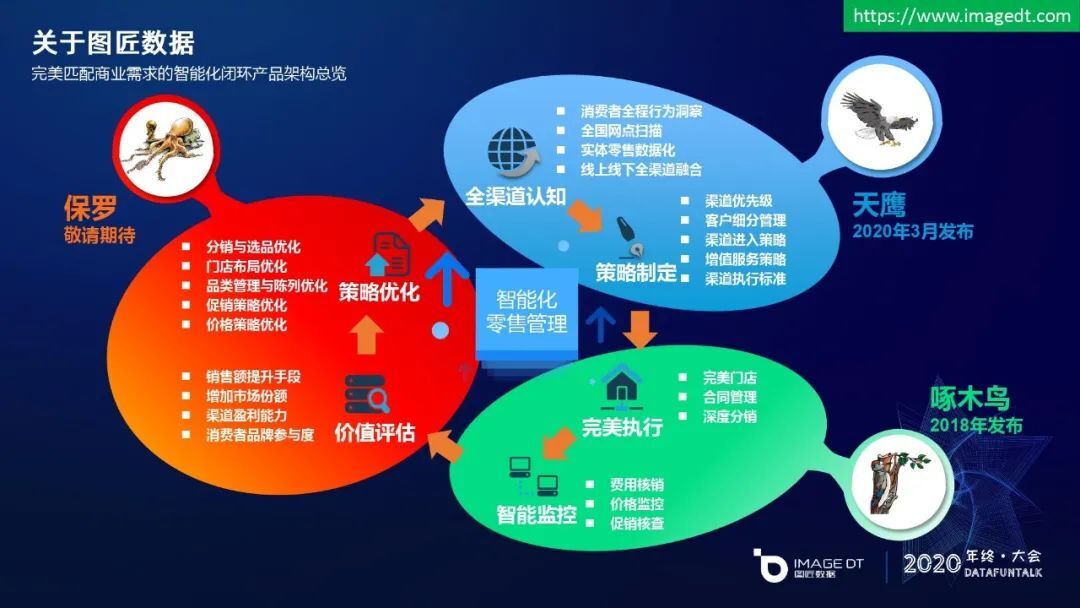
图匠数据在 18 年推出“啄木鸟”产品,针对零售门店稽查工作的完美执行,以及店内商品销售的智能监控方面,给客户提供了专业化商品识别服务。今年推出了“天鹰”产品,主要是对零售渠道全国网点的布局,以及对客户品牌方的商品投放策略,定制化方面提供参考建议。未来我们还会推出“保罗”产品,是结合天鹰和啄木鸟的数据,对市场份额还有盈利能力等方面做价值评估,帮助品牌方门店布局优化和促销策略优化等方面给出策略优化的建议。天鹰、啄木鸟和保罗是以闭环的方式,共同打造智能化零售管理的体系服务。这里做了一些简单介绍,有兴趣想进一步了解图匠数据更多的产品,以及团队详细情况的朋友,可以通过右上角的官方网址进一步了解。
自然场景 OCR 识别技术
下面主要介绍技术方面的工作。首先介绍一下自然场景 OCR 技术应用。

什么是 OCR?
上个世纪 90 年代就已经有一些 OCR 的成熟技术,它的中文名叫光学字符识别。当时的识别技术能对扫描文档进行文字处理,识别简单的文字信息。而自然场景 OCR,是对自然环境图片中的信息进行识别,场景比较复杂,目前用深度学习的方法比较多。
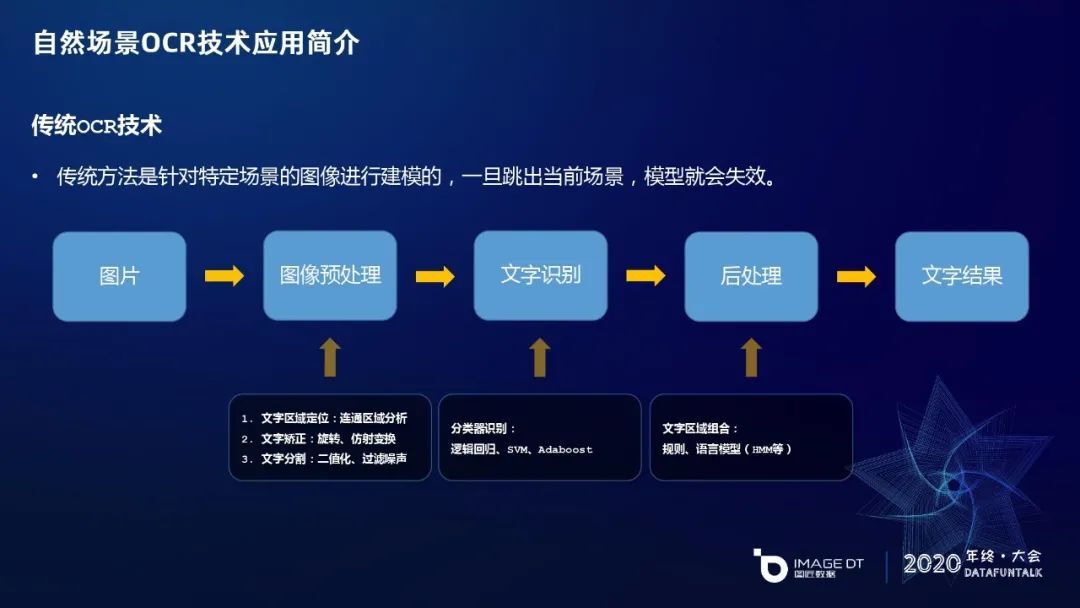
回顾传统 OCR 技术的处理流程,具体技术细节主要分为三个步骤,第一步先对图片的文字区域进行定位,这一阶段会用到连通区域分析方面的技术,然后对定位出来的文字区域进行矫正,如旋转、仿射变换等,最后是文字分割,把图片中的单字分割出来。第二步文字识别主要应用到文字分类技术,主要用逻辑回归、SVM 等传统分类方法,输出结果是单字识别结果,之后进入第三步骤进一步后处理,比如处理文字区域的组合,把单字合成一个词语,把词语合成一个句子,甚至是段落,最后给出识别结果。传统方法是针对特定场景进行图像建模,一旦跳出当前场景,模型就会失效。

自然场景 OCR 相对于传统 OCR 识别,有以下几方面的识别难点,右方图片的左半部分是传统 OCR 的识别场景,右半部分属于自然场景 OCR 的例子,这里给出的是零售场景的文字识别需求,比如图上货架商品上的文字识别。根据图片例子可知,自然场景文字的背景相对复杂,并且文字本身可能有颜色、字体、大小等差异,多样性比较复杂。此外,由于图片是拍照得来的,有出现曝光、遮挡、模糊、低分辨率的低质图片的识别问题。最后在不同应用方向时,拍照场景也具有多样性,比如自动驾驶场景会出现路面路牌文字的识别需求,以及其他汽车外观上的文字识别需求;而零售场景会出现店面或者零售店内的商品文字识别需求,以及促销信息等方面的文字识别需求。这两种场景的文字识别难度差异也比较大。

以零售场景的 OCR 技术应用为例,比如有零售门店门牌照的文字识别,店内货架上 SKU 的文字识别,以及直接影响业务逻辑的价格牌价格数字的识别,整体来说图像特征因素变化多段,传统 OCR 技术很难识别正确。
深度学习 OCR 技术
随着深度学习技术在近几年的普及,深度学习 OCR 技术方向得到了很大的发展,出现了很多相关研究。

深度学习 OCR 技术主要分为两大研究方向。第一个方面,是把文字区域检测和识别分开作为两个独立的识别任务。首先,文字区域检测相比于 FasterRCNN 系列、或者 YOLO 系列等常规物体检测技术有一些差异,比如文字的文本行的长宽比例、文本的方向性带来的差异比较明显,而艺术字体使用弯曲的文本行,会加大了边框回归的难度。对文字区域检测,近几年有一些针对性的成熟的网络,比如 EAST、CTPN、SegLink 等,做了很多优化,技术相对成熟;对文字识别,由最初的单字分类,即 CNN 直接加 Softmax,通过交叉熵损失函数分类,后来演变成针对文字区域单行文本的识别,比如把 CNN 和 RNN 加在 attention 或 CTC 模块对文本进行学习,现在也有结合 STN 这种文本矫正模块去优化倾斜文本或不太规则的弯曲文本的识别性能。这是文字识别的发展现状,典型的网络有 CRNN、RARE 等。

另一个方面,深度学习 OCR 技术把检测和识别做成一个端到端的模型。相比两个模型的优势是节约了计算时间和资源,相对于识别模块由单行文本识别变成将整体图片作为模型输入,图像特征更多,卷积可视野更大。它的缺点是把两个模块的任务融合到一块,计算复杂度也会变大;旋转的文本和弯曲的文本会进一步加大问题复杂度。目前有一些解决思路,比如引入旋转角度偏差计算,添加 STN 这种文本矫正模块,另一个用的比较多的是 Mask TextSpotter,对单个文字进行分割,再整体识别。TextSpotter 已经迭代到第三个版本,相对来说是比较好用、比较成熟的技术。

现实的自然场景拍照除了文本的多样性,图片质量也可能会有一些问题。比如拍照设备发生抖动,或者被拍的目标对象在运动会有一些抖动模糊,还有文本质量低下、比较陈旧,或者是有一些泥土也容易引起噪音,设备有一些椒盐噪音,拍摄的光线出现曝光、晚上光线昏暗等问题。如果客户拍照技能较差比如忘记对焦导致产生失焦模糊,或是拍照设备的性能比较低,拍出来的图片的质量低下等等都会导致低质文本的产生。右边这部分是价格牌的低质文本的例子,比如 24.80 这个图片有一些抖动模糊,31.90 这个图片它的 3 和 1 中间有一些小数点是一些噪音点,现有方法可能会识别成 3.1.90 这种错误结果。右半部分在驾驶场景下路边路牌的例子,像 Exit 有一些上下抖动,还有最后这张图片可能是晚上拍摄的,文字区域的特征很模糊。在深度学习 OCR 技术中,研究低质文本文字识别的技术相对来说比较少,很容易引起误识别的问题。
深度学习超分辨率技术
现有深度学习技术应用研究领域中,有一个超分辨率技术可以提升低质图像的质量。这种技术通过超分辨化提升图片的质量的方式,提升低质量文本图像的清晰程度,并且可以对低质文本 OCR 识别起到一些辅助作用。

超分辨率技术的思想,是采用信号处理的方法,从给定的低频图像中恢复出高频信息,从而在不改变硬件设备的前提下,获得高于成像系统分辨率的图片。在应用领域主要有建筑设备、卫星遥感、医疗领域显微成像;有不同的研究方向,比如对于单幅图像的分辨率进行提升,或从多帧连续图像中重建单帧的超分辨率,如输入一个视频,只对其中的关键帧进行超分辨率,第三方面是对整体视频进行操作,频率是每一帧超分辨率重建的方式。学习方式目前比较成熟的是监督式 SR,无监督式 SR 等两个方式,无监督 SR 发展还不是很好。
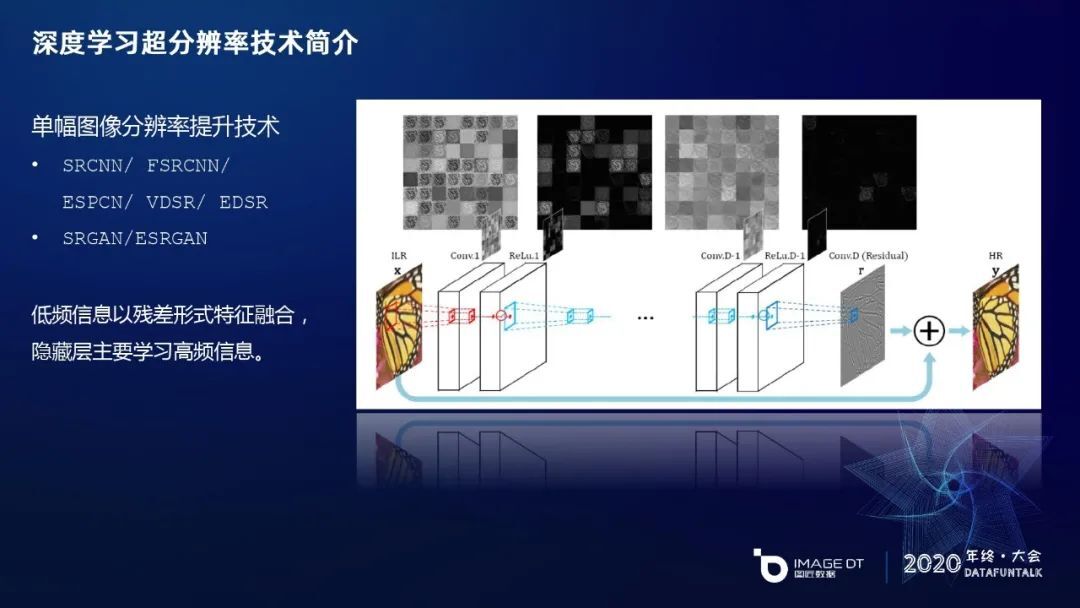
单幅图像分辨率提升的技术目前相对来说是最成熟、用的最多的,应用也比较多,比如像 SRCNN 到最后的 EDSR,还有最近两年结合 GAN,SRGAN 和 ESRGAN 做的工作比较多。这些超分辨率网络有一个研究趋势,是把 LR(低分辨率的)图片生成 HR(高分辨率的)图片时,会用残差的方式,把低分辨率的低频信息直接残差链接过来,让神经网络的潜藏层去学习高频信息的特征,降低低频信息的学习负担,从整体上提升识别效果。这些是超分辨率学习的发展现状。
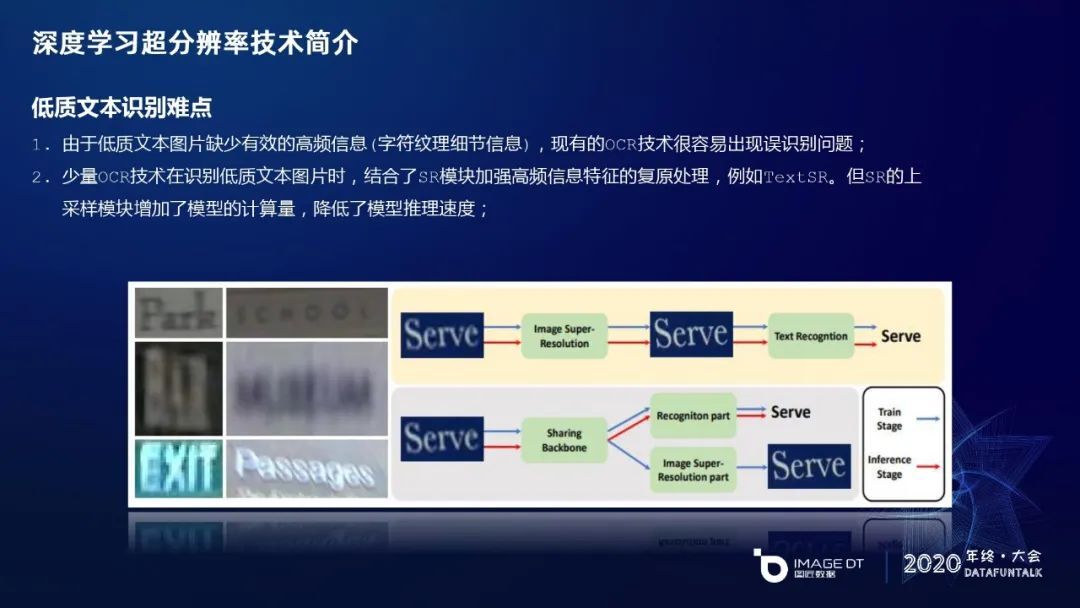
OCR 识别目前应用单帧图像的超分辨率技术较少,其中已有的技术 TextSR 会结合 SR 模块增强低质文本的识别。看下面这张图的上半部分,把 SR 直接嵌入到 OCR 的识别分支中,熟悉 SR 模块的朋友都知道,SR 里面有一个叫上采样的模块,如果把 SR 直接融入到 OCR 的网络中,采样模块会增加显存的计算,在能耗上不够友好。我们针对这些问题提出了新的尝试,让 SR 和 OCR 在互相影响时能互相促进学习,通过这种分支的方法,基于 Sharing Backbone 的共同卷积来促进 OCR 的识别分支。具体来说,蓝色的箭头在训练阶段参与工作流程,在 inference(推理)时只会部署红色箭头的分支,把 SR 分支去掉,来降低终端部署的便利性。
plugnet 介绍
下面详细介绍一下 plugnet 的低质文本的解决思路。
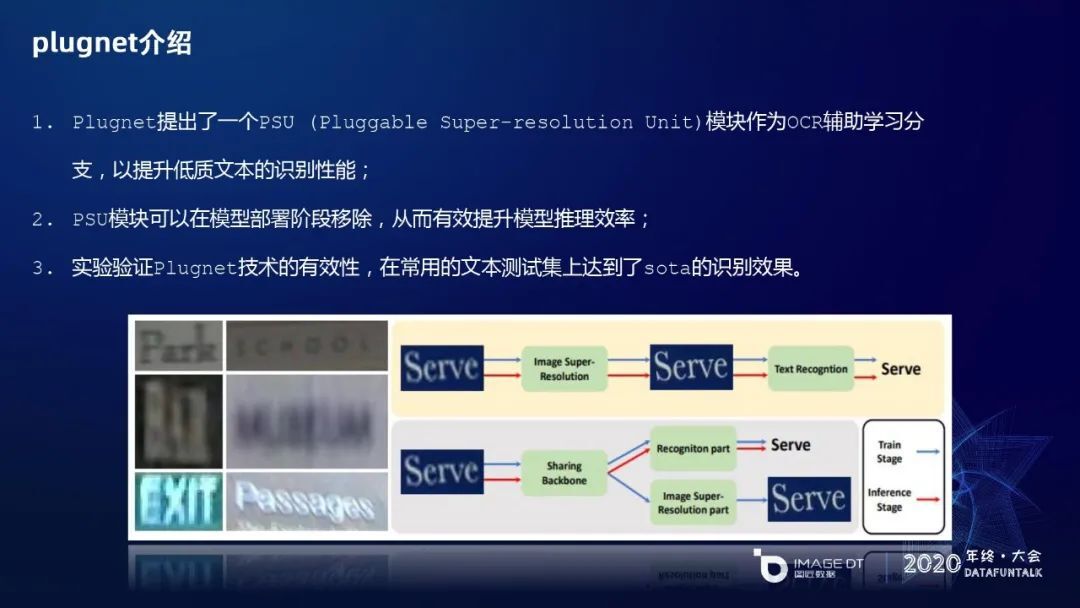
plugnet 提出 PSU,即可插拔的超分辨率学习单元,作为 OCR 辅助学习分支,来提升低质文本的识别性能。PSU 模块可以在模型部署阶段移除,从而有效提升模型的推理效率。对 plugnet 的技术有效性进行验证,它在常用的文本测试集上达到了 sota 的识别效果。
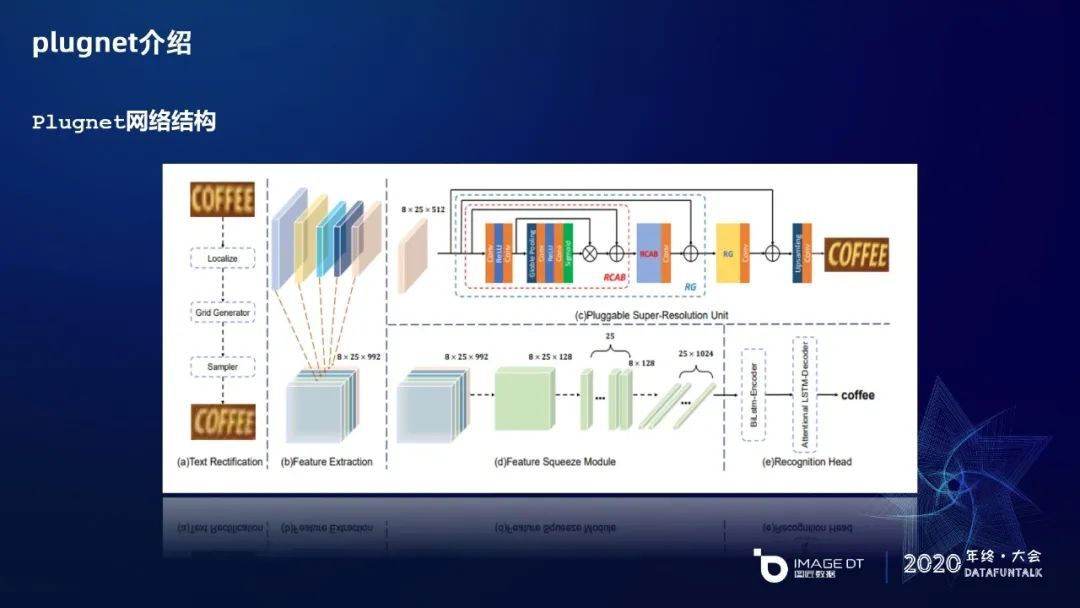
这是 plugnet 的整体网络流程图,主要分为五个部分。第一部分是对文本进行矫正,类似于 STN 的思路,给倾斜文本进行矫正,这样文字信息方便后面序列化的识别。第二部分是共享卷积,基于 SR 的分支和 OCR 的分支进行共享权重的学习。第三部分是一个可插拔的一个 SR 学习单元。最后是 OCR 的分支,分为两个部分,一个是对特征进行序列化,另一个是采用双向 LSTM 进行编码和识别,并结合 attention 的机制。
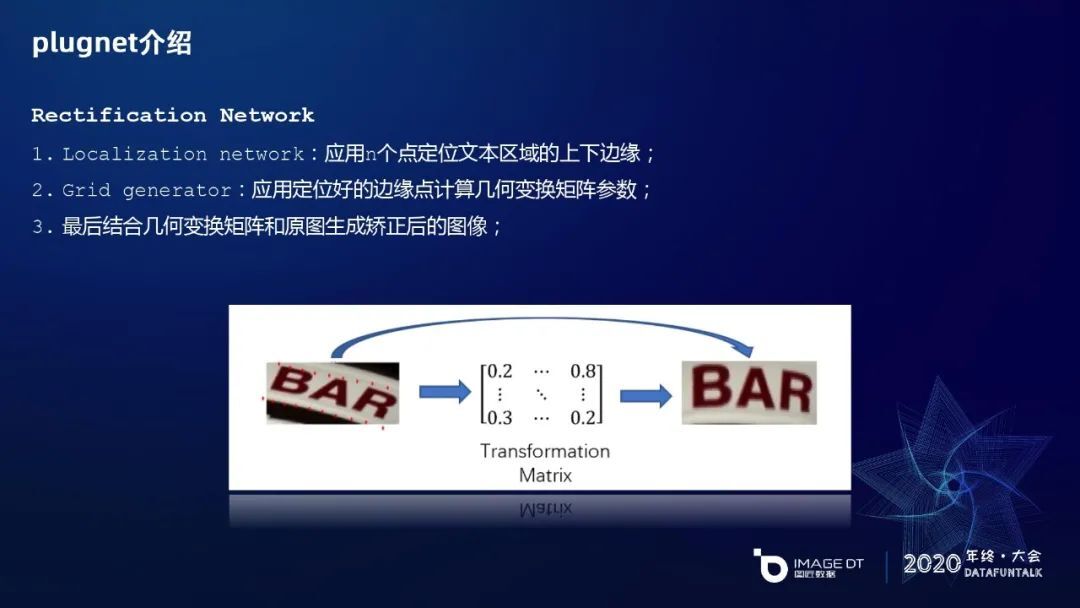
首先是矫正网络,借鉴了 STN 的思路分为三个步骤,第一是用 N 个点,比如我们实验里用了 20 个点,上面 10 个点和下面 10 个点,来定位文本区域的上下边缘,然后通过网格的形式来学习出一个变换矩阵,再结合变换矩阵和具体的网格信息做一个几何变换,生成一个矫正后的图片。像右边 BAR 这个图片就得到了比较好的矫正。

针对特征提取(Feature Extraction)模块,就是共享权重模块,采用残差结构的思路,一共有六个 block,后面五个 block 的内部都有三个 1×1 和 3×3 的模块,每两个模块之间会一个跳级的残差连接,后面四个 block 的输出形式都是 8×25 的特征维度,也有一些残差。另外,在识别时它把 32×100 会一直降维到 1×25,再送入到序列识别去学习。这里我们做了一些改进,就是把 32×100 的维度下降到 8×25,以保留一些高度信息,通过实验验证它会有识别结果的优化。

对于特征序列化模块,把 8×25 的维度进行转化成一个时间序列,把高度信息和 channel 特征融合成 1024 的特征向量,图片 25 个分辨率的宽度信息作为 LSTM 的时间维度信息,送入到 LSTM 去学习,然后解码成具体的文字信息。

这是 PSU 的一个超分辨率学习单元。它由两个残差组合,每一个残差组合由两个叫残差通道,注意力模块共同组成。在每一个 RCAB 残差通道注意力模块里,首先卷积跟 RELU,它输出后放入到 Global Pooling 的机制,然后经过 Sigmoid 进行激活,Attention 激活因子在 Channel 的维度上对特征进行操作,在外部对 RCAP 的输入进行残差。它是一个注意力机制的成长模块。在 RCAB 外部在 RG 模块也有一个残差连接,通过残差增强特征的提取。最后的这个残差,是让 SR 的低分辨率信息传输过来,让整个隐藏层去学习高分辨率的信息,降低它对低分辨率学习的负担。值得一提的是,模型部署阶段可以将 PSU 分支移除,提升模型推理的效率,降低能耗。
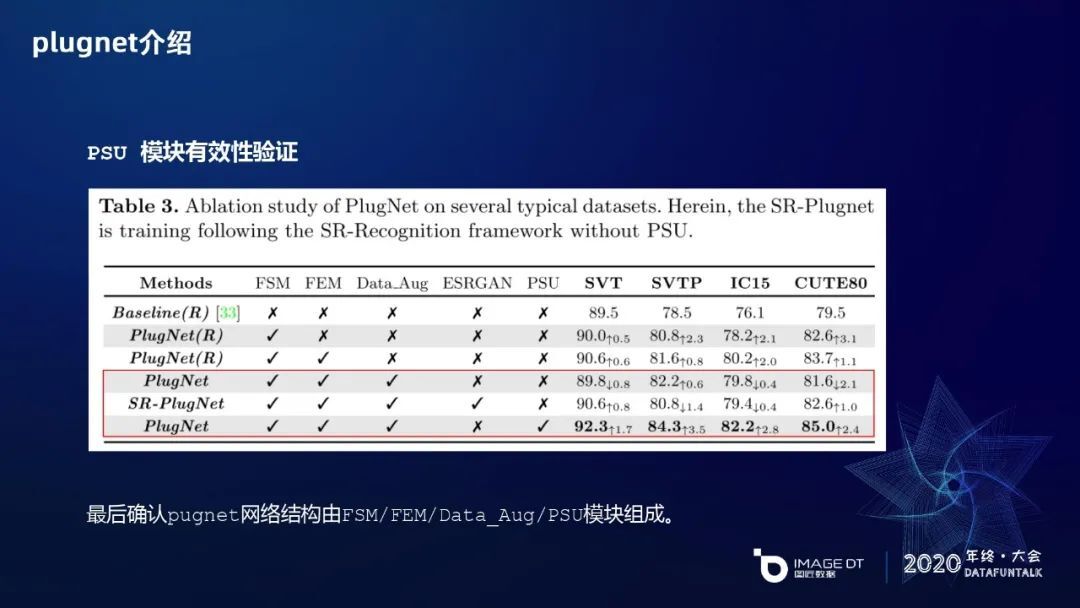
我们做了一些实验,首先是 FEM 共享卷积模块的有效性验证。最上面一行是一个 baseline,直接拿卷积通过 CNN 加 RNN(LSTM)训练识别的结果,第二行是通过 FEM 残差模块的卷积,经过一些优化,然后在数据上有了提升。FSM 和 FEM 有区别,FSM 在序列识别进行解码,FEM 通过这种残差模式。第三个模型是两个模块都有,又有一些提升。对于 PSU 模块的有效性验证,做了三组实验对比,首先通过 FSM、FEM 和 Data Augmentation 识别文字信息,然后根据 ESRGAN 那篇文章把它们融入到 GAN 里面来提升识别效果,最后是用 PSU 取代 ESRGAN 的方式。
ESRGAN 的识别效果不如 PSU,分析原因的话,第一是 GAN 训练不稳定,要么在某一个数据集上面比较高、其他数据集相对低,要么比较均衡的就都不是很好。第二在融入 ESRGAN 分支时,是直接把它的代码迁移过来,没有做太多改进,如果再做进一步的融合其实还有很大的改进空间。PSU 是经过调参的深度优化后的模块,所以它的效果比较好。
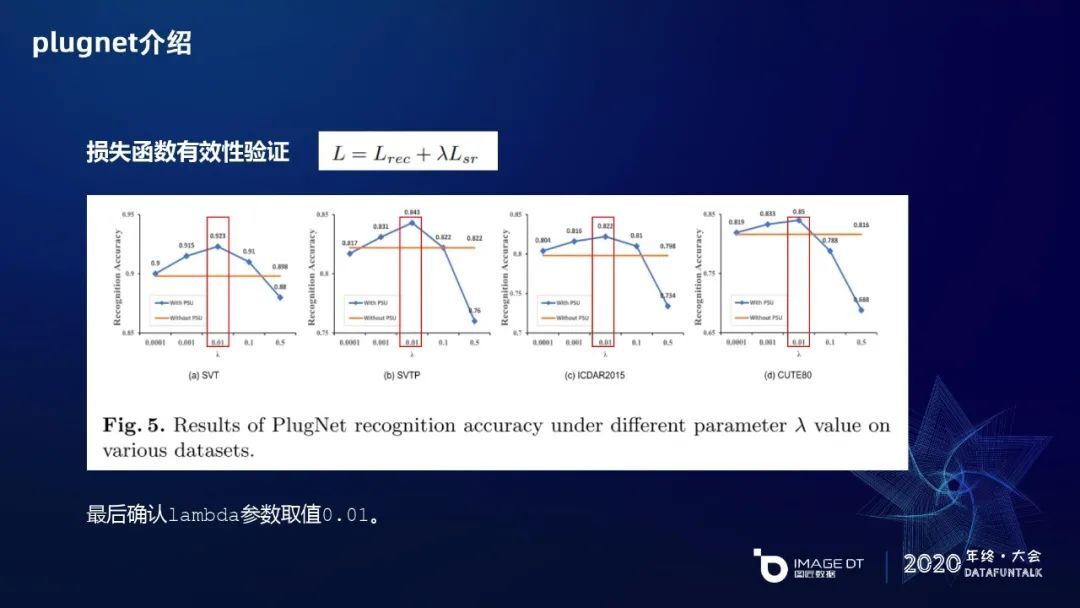
由于 plugnet 是多任务(Multi-Task)模型训练,主要由 OCR 模块和 SR 模块两个部分的 loss 组成。OCR 模块,通过 Mask 的方式,交叉熵(Cross-Entropy)可以直接分类。SR 模块用的是 L1 损失函数进行计算,对每个像素进行 L1 回归。通过 lambda 参数调整 SR 对 OCR 识别模块的影响程度,通过一些实验观察调整 lambda 后的整体 OCR 识别结果。每张图上橙色的线是没有加 PSU 直接训练 OCR 的精度,添加 PSU 模块后,通过调整 lambda 的值,从 10e-4 慢慢调整到 10e-1,最大直至 0.5,获得测试出的性能。最终发现在 10e-2 时效果达到峰值。有意思的是,当 lambda 调到 0.5 时,其实它是有一些逆作用在里面,可以发现其实 SR 并不是一直会对 OCR 学习的分支有增进作用,如果 lambda 调得不好它也会有一些逆作用在里面。最终选取 lambda 的值为 1e-2(0.01)。
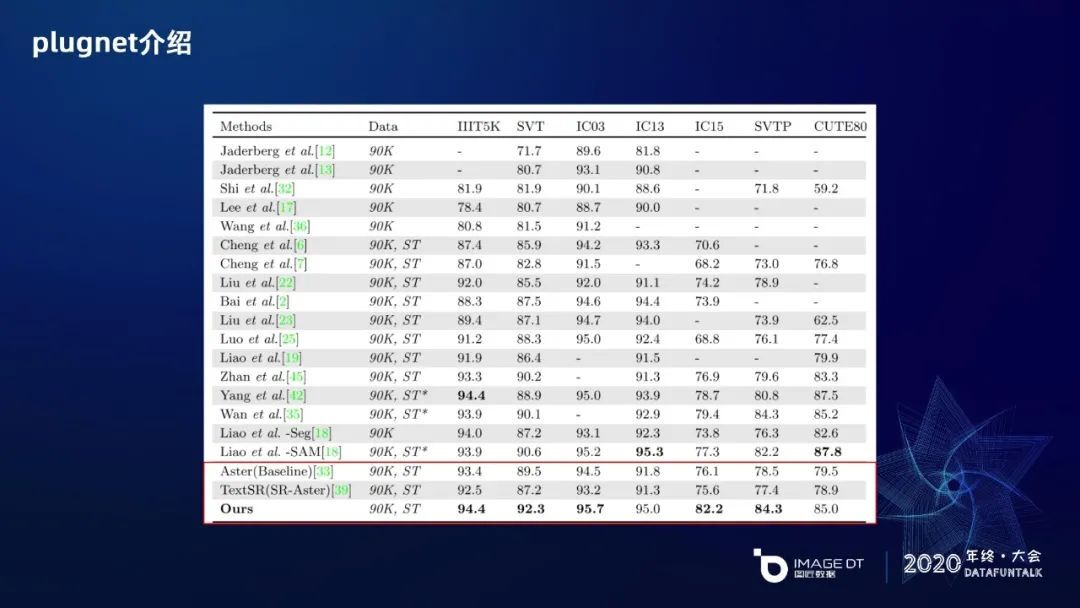
最后,这里给出了跟现有 OCR 识别的对比。首先 SR-Aster 作为模型的 baseline, 训练参数、学习率、BatchSize 等参考 Aster 的训练策略。另一个是 TextSR,也是把 SR 和 OCR 进行融合。最后是我们的识别结果,可以看到常用的七个测试集上,有五个测试集达到了最好的效果,尤其是 SVT 和 SVTP 这两个数据集,它们的低质文本比例相对更多,识别效果提升会比较多。
工作总结

最后进行工作总结。首先跟大家回顾了传统 OCR 识别技术和深度学习 OCR 技术的已有工作,发现目前深度学习 OCR 技术大部分都在攻克倾斜文本或者是弯曲文本的方面的问题。低质文本的视频方向现在研究的比较少。第二个方面 PlugNet 网络提供了一个端到端的可训练的是低质文本识别器,提出了 PSU 可插拔超分辨率单元,解决了低质文本识别问题,并方便终端部署、降低能耗。关于后期工作,第一个就是把 SR 融入到 OCR 识别分支,就是对于云端部署、不考虑节省资源消耗的时候,对于 SR 和 OCR 进一步提升低质文本识别性能的潜能到底有多大?第二个是把文本检测和识别做成端到端的可训练的模型方式,再验证 SR 对模型的影响。
今天的分享就到这里,谢谢大家。
嘉宾介绍:
杨辉,ImageDT 资深图像算法工程师。
本文转载自:DataFunTalk(ID:dataFunTalk)
原文链接:一种面向自然场景下的低质文本识别方法




