
作者 | 朴朴科技平台组
背景
在当今数字化时代,伴随着朴朴业务的快速增长,朴朴全面拥抱微服务、云原生和容器技术,同时,在云原生可观测性方面,朴朴几乎所有的微服务都接入了朴朴 APM 来帮助开发者快速定位、分析和诊断问题。然而随着业务复杂度和服务数量的不断增加,上报给 APM 的数据量也急剧增加。
目前,朴朴 APM 后端存储数据库使用 ClickHouse,每天上报的数据量在 1000 亿行左右,压缩后存储空间占 20TB 左右。为了降低存储成本以及提升数据信噪比,朴朴平台技术团队对 APM 链路引入了自定义采样。
用户关心的采样数据
我们仔细思考下,用户真的需要这么大的数据量吗?用户关心的是我想要的 Span 你必须给我采样到,并且链路追踪 Trace 必须是完整的。因此我们在做采样的情况下,如果能够保证 99.99% 的用户的需求,那么对用户就是无感的。
根据日常线上排查经验,我们发现业务研发主要关心以下优先级高场景:
在调用链上出现异常 Error
耗时长(阈值取决实际业务需求)
A/C 端 HTTP 接口耗时超过 「250ms」
Dubbo 接口耗时超过 「250ms」
XXL-Job 定时任务数据全保存
在调用链上出现 MySQL 耗时超过 「100ms」
在调用链上出现 Elasticsearch 耗时超过 「200ms」
在调用链上出现 Redis 耗时超过 「50ms」
Kafka 消费组耗时超过 「1s」
业务场景核心调用链。如:搜索、加购物车、下单、支付等流程。
注意:为方便后面描述,我把上面业务关心的 Span 定义为「有意义的 Span」。
常见的链路采样策略
常见的采样策略主要分为 3 种:基于头部采样、「有意义 Span」向下传播法、基于尾部采样,可以根据实际的业务情况进行结合使用。
图 1 为朴朴 APM 整体采样示意图,其中头部采样、「有意义 Span」向下传播法基于服务挂载的 Agent 插件实现,尾部采样是在 OAP (Observability Analysis Platform,观测分析平台) 链路数据处理模块进行。
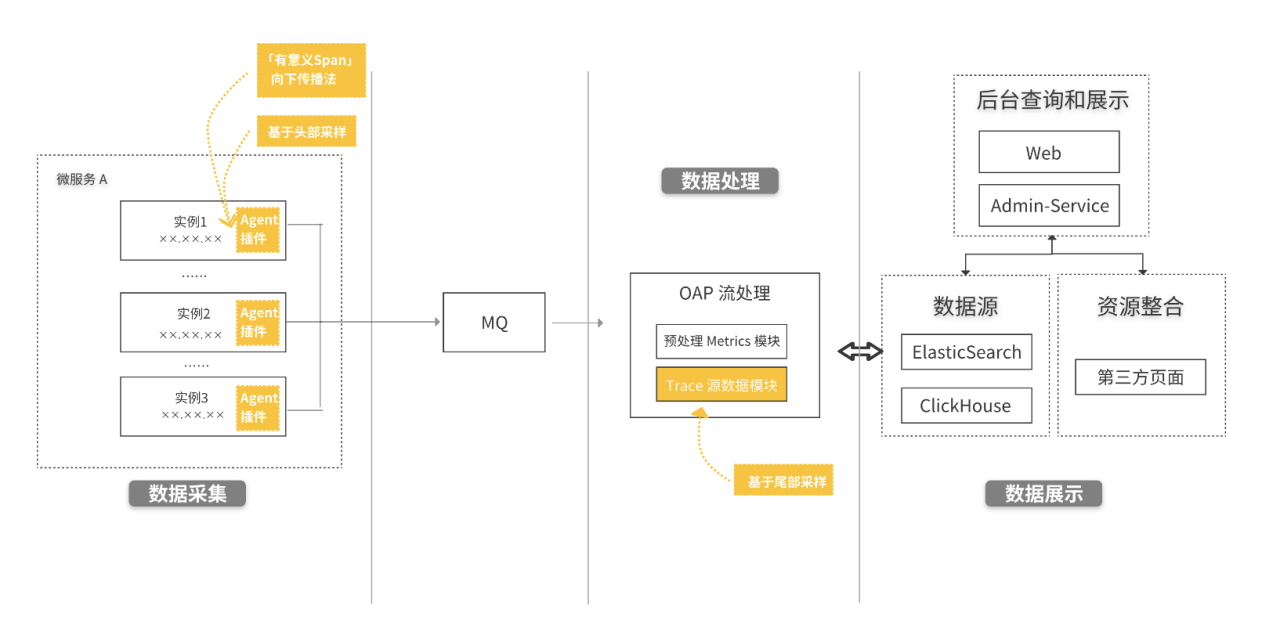
图 1:采样位置示意图(图中黄色模块重点标注)
3.1 基于头部采样头部采样
从请求一开始就做出了哪些初始节点需要采样的决定。没有做上下游链路判断逻辑,从一开始选择性采集少量数据。可以简单理解为 Agent 端上报时就已经采样了。
优点:实现简单。
缺点:无法感知链路其他节点情况,无法保证链路完整性。
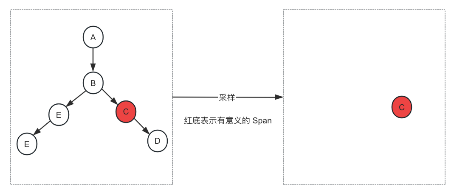
图 2:基于头部采样示例图
3.2「有意义 Span」向下传播法
当存在「有意义的 Span」,继续向下传播时,会给接下来调用的所有 Span 标记上「有意义」,在采样的时候,当看到这些标记时,则会主动采样保存下来,不会剔除掉。
优点:实现简单。
缺点:因为标记可能发生在链路中间节点,无法保证链路完整性,只保留了部分链路。
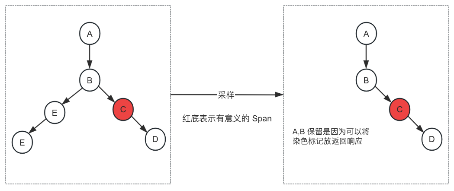
图 3:基于向下传播法采样示例图
3.3 基于尾部采样
即在消费端等待单条链路完整消费后进行采样(一般是在数据入库前进行)。业内为了保证在异常或者慢查询的链路数据完整性,基本采用这种方式。
优点:保证链路完整性
缺点:如何保证链路完整性,实现较为复杂。
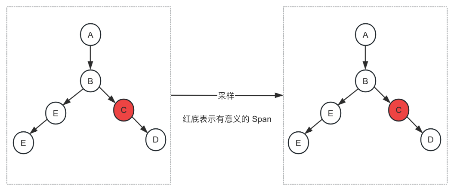
图 4:基于尾部采样示例图
朴朴 APM 基于尾部采样实践
因为基于头部采样、「有意义 Span」向下传播法实现较为简单,不进行过多描述,本文章主要讲解如何基于尾部采样,支持多种方案设计供用户选择适合自己的场景。
4.1 延迟消费方案
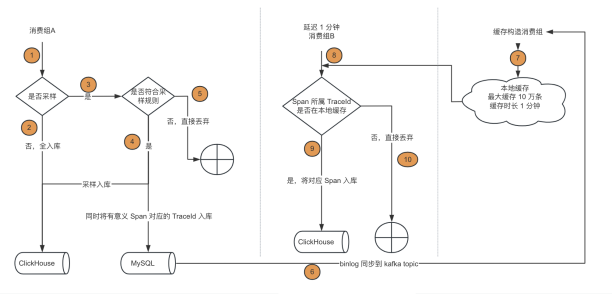
图 5:延迟消费方案
根据业务特性,我们发现 1 条完整的链路耗时基本不会大于 1 分钟,我们可以认为 1 分钟后这条链路已经都上报到 Kafka 了。因此只要先判断要保留的 TraceId,然后延迟 1 分钟再次消费进行比对就能保证将整条链路完整保留。
消费者 A:实时消费链路数据,判断是否是「有意义 Span」,将「有意义 Span TraceId 保存(因为这条链路所有 Span TraceId 是一致的)。
消费者 B:延迟 1 分钟消费链路数据,获取有 TraceId 存放到本地缓存,判断链路数据是否在本地缓存里,在的话就进行保留。
适合的场景
采样策略完全符合用户的预期,可以对全部数据都进行采样。
方案优缺点
优点:可以在保留链路完整性的前提下实现全采样,不仅节省了 ClickHouse 的入库带宽和存储成本,而且提高了查询效率。
缺点:1. 需要延迟 1 分钟用户才能看到完整的链路(取决于业务特点,我们这是保证链路查询延迟不高于 5 分钟即可)。2. 需要对链路数据重复消费,增加了机器成本和带宽成本。
如何实现消费延迟?
Kafka 本身是不支持消费延迟的,常见的延迟消费方案也是消费时判断是否到期然后再发送到另外的 topic,但是这种方案的成本是不可接受的,因为 topic 数据量很大,会导致 Kafka 的带宽与存储成本翻倍,因此我们采取了一种取巧的方式来实现。
Kafka 本身支持手动上报 offset 进行消费,那么如果一直上传相同的 offset 不就可以变相实现暂停消费效果。
Java 代码实现如下:

朴朴在线业务研发同学希望能保留最近 24 小时的全量数据,方便进行最细致的排查。延迟消费方案可以实现(双消费 1 个采样 1 个保留全量),但是这会导致消费者服务与带宽成本都翻倍,整体成本反而没有节省多少,因此最终决定采取数据库空闲时间采样方案。
4.2 空闲时间采样方案
经过观察,我们发现链路上报与用户使用的高峰期是早上 9 点到晚上 8 点,其他时间段的流量还不到高峰期的 20%,且数据库的机器负载一直在低水位(CPU10%,可用内存 50G),因此可以利用数据库空闲时间的资源进行采样。
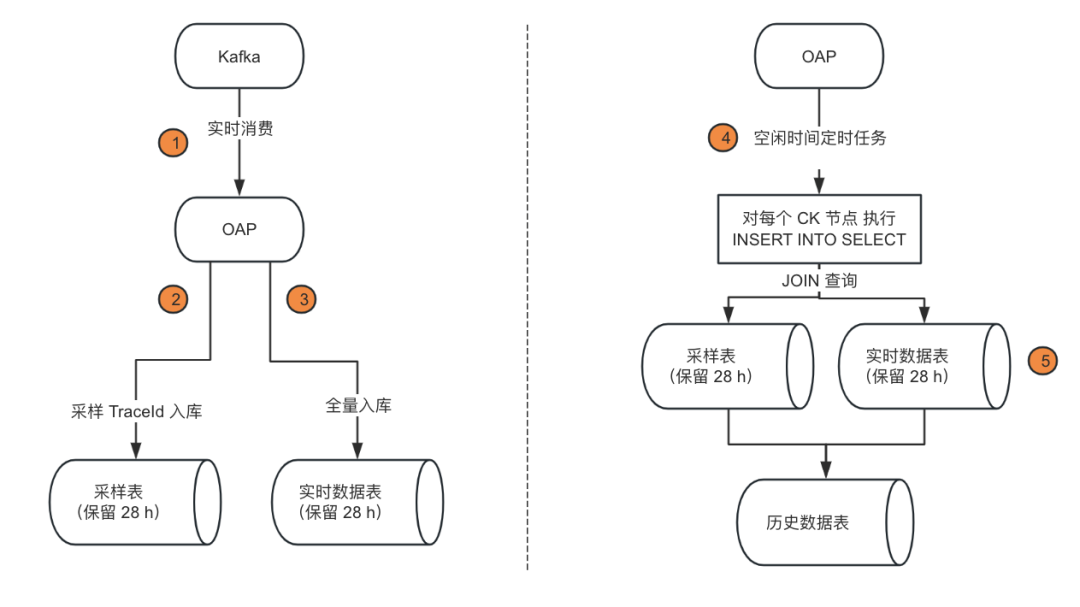
图 6:空闲时间采样方案
实时消费逻辑:增加满足采样规则的 TraceId 入库逻辑,经过分析,有意义的 TraceId 只占全量的 0.14%,对原有资源负载基本无压力。
定时任务逻辑:空闲时间开启定时任务,比如凌晨 0-4 点执行任务,将昨天的链路完整数据与采样 TraceId 表进行关联然后插入历史数据表。
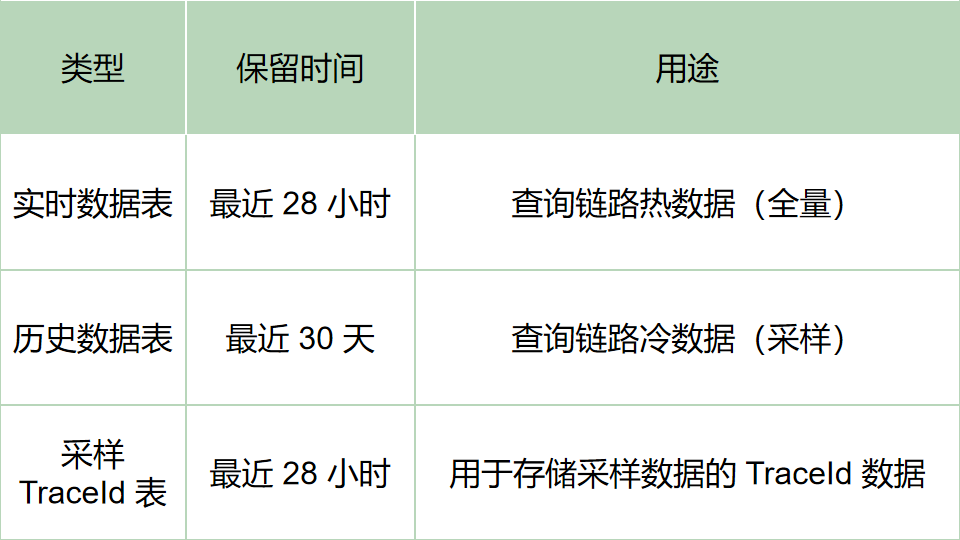
采样表和实时数据表保留 28 小时,是为了预留 4 小时的冗余容错时间,防止采样失败可重试。
适合的场景
用户需要保留 24 小时全量数据 + 30 天采样数据。
方案优缺点
优点:利用已有资源空闲时间,没有增加额外的成本(凌晨耗费 CPU 50% 内存 10G)。
缺点:由于要保留 24 小时全量数据,因此只节省了历史数据的存储成本,没有减少入库带宽的成本。
定时任务 SQL 语句

定时任务注意事项
避开整点:任务只能在 00:10 - 00:50 执行,因为 ClickHouse 冷热分离是基于整点,会在整点时刻进行数据迁移,要避免资源冲突。
分批处理:60 分钟一批,防止 ClickHouse 内存与 CPU 负载过大。
使用本地表:insert into select 语句里面涉及的表都要使用本地表,如果使用分布式表会导致数据转发到各节点,浪费资源且耗时很长。
4.3 采样策略优化
采样的规则不是一成不变的,而是要结合公司本身业务特性持续动态调整的。朴朴 APM 最初按上文【2. 用户关心什么样的 Span】规则整体采样保留率为 8%,观察图 7 会发现有很多服务保留率过高,因此要具体情况具体分析,进一步优化采样的策略。
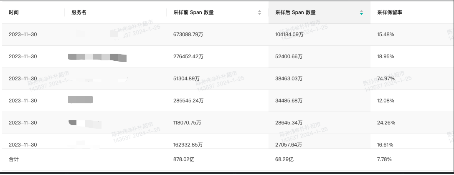
图 7:初版规则采样保留率
这里列举几点常见的优化策略:
预期异常采样优化采样保留规则有 1 条是保留完整的错误链路,但是经过分析采样保留数据,发现有部分异常属于预期异常:
业务预期参数异常:com.pupu.exceptions.ArgumentException: 登录已失效,请重新登录
Redisson cluster 模式下 eval 命令预期异常:org.redisson.client.RedisMovedException
HTTP 状态码 401 。
这些异常属于频发且无需链路排查,直接查看日志就可知道问题原因,占比整体错误 50% 以上。因此我们采取在 OAP 数据处理模块中自定义规则将这部分链路正常保留,但是异常状态位改为正常。这有助于采样优化和用户更加准确的分析服务异常原因(没排查这些预期异常前,服务异常率可能为 10%,但是实际真正的异常率应该是 1%)。
特殊场景慢查询阈值调整
默认情况下慢查询的阈值是根据组件区分的,比如 HTTP 接口的慢查阈值是 250ms,但是部分服务属于特殊场景,如大数据批处理服务。每个接口的耗时基本都在秒甚至分钟级别,导致采样后认为是慢查询全部保留。因此服务要进行区分:业务服务、大数据服务、基础平台服务等。要针对不同服务类型,甚至单个服务进行对应的慢查询阈值设置。具体的阈值可以参考服务耗时的 p999 和咨询服务 owner。
生产消费消息链路拆分
初版关于消息队列的链路是同时含有生产者和消费者,链路长度基本是上万(因为包含太多消费者服务)。导致用户查看链路很难聚焦,采样也因为链路太长,只要其中 1 条发生异常或慢查询就会被保留。
经过调研发现用户基本不关心自己生产的信息是被其他服务如何消费的,也不关心消费的消息具体是怎么产生,最多只要知道是哪个服务消费或者产生的消息,不在意具体的链路。因此我们修改了插件将生产消费消息链路拆分,即生产与消费都是单独的 TraceId。为了保证特殊场景下用户真想查看完整的链路,消费者链路会有单独字段 producer.traceid 记录生产者的链路 id,需要的时候可以进行关联查询。
经过上面一系列的采样优化,采样保留率进一步降低,由 8% -> 4%。
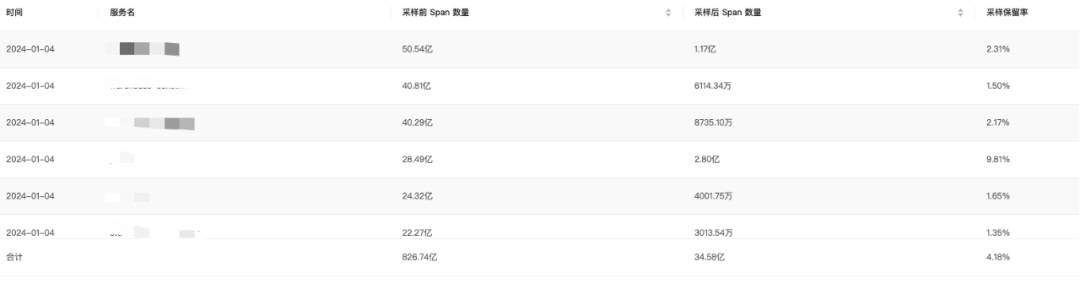
4.4 采样实践成果
通过上述的优化之后,我们对比了采样前与采样后的存储成本和查询历史数据的性能。
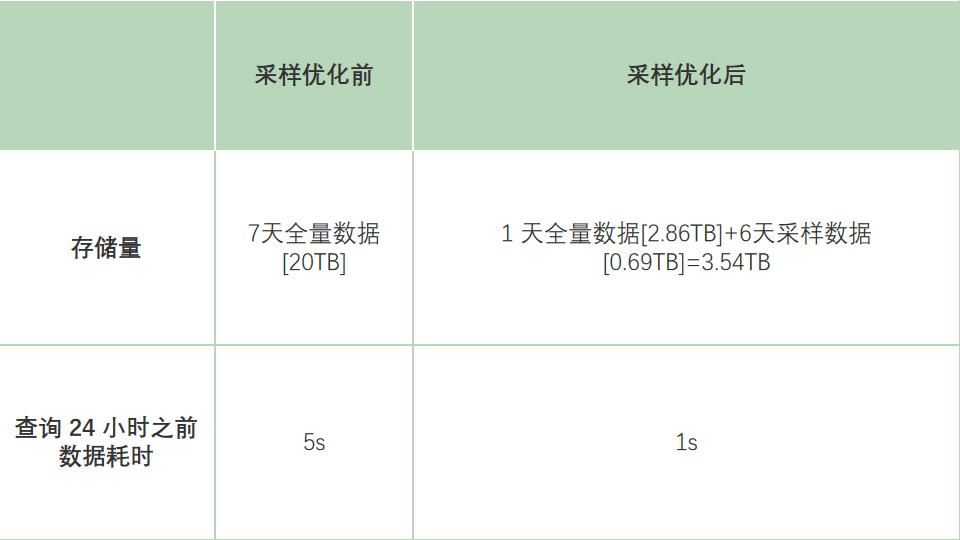
即在不影响用户使用情况下,数据存储成本降低了 80%,查询效率提升了 5 倍。
总结与展望
朴朴 APM 链路采样的成功实践,不仅降低了存储成本,还提高了历史数据的查询效率。未来,我们打算进一步扩展数据采样的维度(包括:头部采样、采样策略根据历史指标动态化等)来进一步提升 APM 的性能并降低运营成本。




