
背景
西瓜在 feed、详情页、个人主页有一块功能区,包括了点赞、收藏、关注等功能。这些功能长久以来都是孤立的:多个场景下点赞、收藏、关注等状态或数量不一致。在以往的业务迭代中,都是业务 A 有了需求,就加个点赞的请求,把自己业务模块的 UI 更新下就完事了,业务 B 也自己搞一下。当西瓜开始从切面发力互动业务的时候,这些问题就凸显出来了。线上出现了很多在页面 A 点赞/收藏完一个视频到页面 B 点赞/收藏状态或者点赞/收藏数不对的 case。
例如:
问题拆解
在分析这块业务时,梳理出几种问题:
业务上场景太分散,体现到代码上就是在 activity、scene、viewholder、自定义 view 等各种个样的容器,多个业务模块、多个端(web、flutter)上都有很相似的操作,代码跨度很大。
存量的代码中有些场景是处理过同步问题的,但是处理的又不彻底,方案也不一样,比如有的情况用了全局注册 callback,来通知所有对结果敏感的场景;有的情况用了 Eventbus;有的情况是更新内存,但是却只是个别几个模块通用。
一部分问题是原来的业务逻辑,比如,使用更新后的内存变量在多个页面或者模块传递引用,由于层次比较深引用值被中间的流程篡改。
一部分问题是服务端数据逻辑问题。
其中 3、4 点问题更像是逻辑 bug。
多个端的数据同步可以通过跨端事件,每个端收到事件后更新自己就行。所以最复杂最难搞的问题就是端内多场景下的数据状态同步问题。
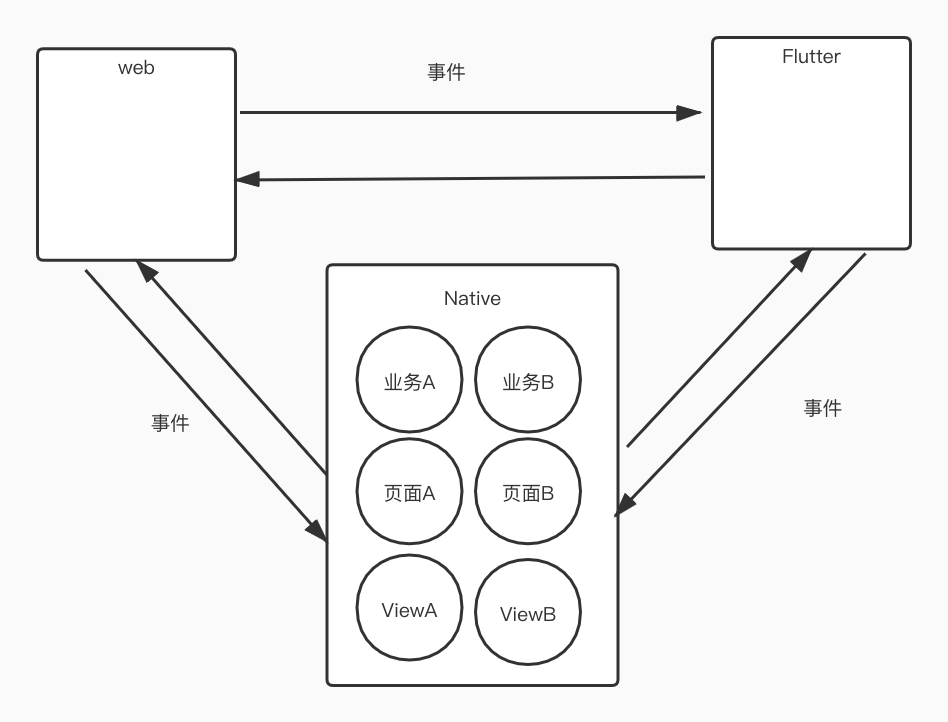
端内问题聚焦在几个 case:
case1:普通页面,如 Activity or Fragment 上的状态同步;
case2:feed 卡片的状态同步;
case3:feed 卡片内多个复杂层级之间的状态同步;
case4:以上的组合。
目标
数据状态同步,是要保证两个一致性:数据一致性、UI 一致性;
方案要使用简单,理解简单;
尽可能减少性能开销。
方案调研
EventBus
这个方案的本质是:监听者收到事件->更新 UI/更新数据 Model
对于 case1:如果是 A 页面发起,B 页面被动接收,只需要在 B 页面接收事件,更新 B 页面的 Model 对象+UI 即可。但是在收到事件之后,一定要把当前页面的 model 对象更新,不然会有不一致的问题。
对于 case2:
eventbus 注册在 ViewHolder 上:由于 ViewHolder 的复用,ViewHolder 的数量是少于“ListData”的,那么意味着,只在 ViewHolder 上监听,会出现那些没有和 ViewHolder 建立联系的数据无法被更新到。如果使用黏性事件,该事件会一直在内存中,粘性事件的膨胀不可控,很可能会造成严重的内存问题。
eventbus 注册在 Activity or 其它页面上,收到事件后,遍历数据列表,更新,然后通过 RecyclerView 的 onDataItemChanged 方法局部更新。但是在很多场景,比如西瓜 feed,feed 框架之下的 view 层次非常深。很多时候 Rd 只关注某类卡片下的某个 UI 组件,Feed 框架和顶层页面容器离的很远,修改成本高,容易出错,对 feed 框架或者顶层容器的侵入比较大。另外,onDataItemChanged 的局部更新是 ViewHolder 对应的 itemView 的,这个维度比较大,并不能刷新单独的一个点赞按钮。
基于 k-v 的监听、通知
以对象 id 为 key,某个属性值如点赞数为 value。事件发生时,将修改值写入 k-v 列表,监听者全部监听这个变化。当新进入一个场景时,查询 k-v 列表作为最新值。这个方案和 Eventbus 粘性事件很像。
k-v 粒度太细,一直在内存中,非常容易膨胀,没有合适的释放时机,导致内存浪费;一旦移除,就可能概率的数据同步失效。
k-v 列表内的状态要使用者在合适的时机同步到业务层数据 Model。
全局共享数据 Model 实例
同一个数据 Model 对象,比如一个卡片 Model,每次更新都是全局可见的。但是很明显,
对数据 Model 的要求很高。一个业务层数据 Model 类型,要全局统一,比如,一个视频卡片业务层的类型是“ModelA”,那么全局场景不能有“ModelB”表示卡片。在很多场景下,业务层会对原始数据 Model 进行包装适配;
内存占用很大;可能要缓存很多个列表。
基于注解的对象映射方案 VM-Mapping
特点
以命名空间+指定字段值 为 key,匹配相同注解名的字段的映射,打平了 Model 类型的不同、层级嵌套的约束;
直接更新结果到数据 model(如 article),与数据 model 视角的同步;
打平了多个页面、复杂 view 层级嵌套的差异;
自动处理更新,使用者仅需要关心怎么更新 UI,不需要考虑数据 Model 的一致性;
任意场景的支持。
思考
数据状态同步,到底同步的是什么?
上述的方案中大致有几个角色:事件、监听者、数据 Model、UI。到底谁应该是主导者?
基于事件的方案都需要把状态同步给数据 Model,能简化吗?
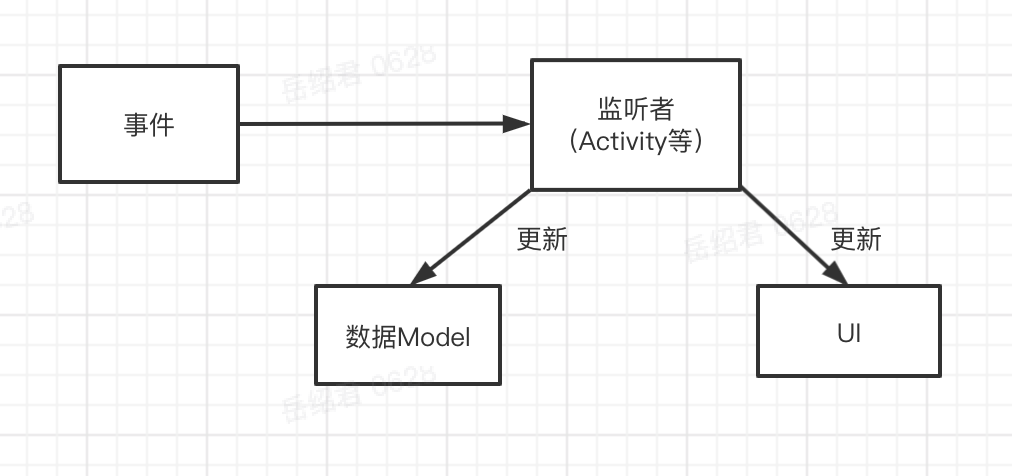
这个过程中有四个角色,三个操作。
突破 View 层级的限制
从 MVVM 说起。
MVVM 是一种软件设计典范,用一种业务逻辑、数据、界面显示分离的方法组织代码。

MVVM 本质上是一种数据驱动 UI 的理念。从这个理念看,数据状态同步,同步的是数据 Model,UI 的变更是由数据的变更引起的,真正关注的点应该在数据本身上。
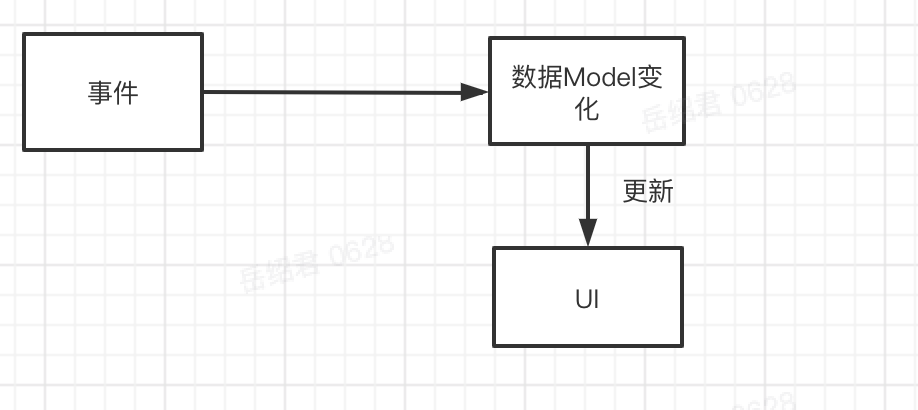
这样,就不再需要额外一个接受事件的“容器”,来控制数据和 UI 了。到现在,只有三个角色,两个操作了。
再回过头看,为什么跨页面、跨多 View 层级很难找到一个通用方案,是因为总在找一个“容器”来承载事件的接受,然后再做双份(数据和 View)的同步。而且这个“容器”通常本身就是一个页面,或者其它不同层级上的 view,本身就存在很多样化,为这种多样化适配,就会让事情变得复杂。
假如不再找额外的“容器”,直接把监听绑定在数据上,那么 View 层级的限制也就不存在了。因为不管在什么场景,什么层级,真正的逻辑中心都是数据,View 也是通过数据渲染出来的,View 不关心自己在什么层级,只关心数据的变化。
突破类型的限制
这里有几个类型的限制:
数据 Model 的类型是否只能一成不变,假如网络请求的原始数据是 A 类型,在场景 1 直接用了 A 类型,在场景 2 为了适配 UI 对 A 做了包装:
class A{ val diggStatus : Int}class B { val a : A val showTipEnable : Boolean}虽然类型不同,但是对 A、B 来说,都是要更新 diggStatus 的;
在 Android,数据 Model 的类型是强类型,是从网络由二进制流反序列化出来的,那么同一个二进流,既可以反序列化成 A 类型,又可以反序列化成 B 类型,只要满足反序列化规则就行。但是事实上,他们的业务本质还是一个东西。
class A{ val diggStatus : Int}class B{ val digg_status : Int}事件本身也是一个数据,只是它是用户操作发起的,表象看和数据 Model 无关,但是一个事件既然能更新某个数据 Model,那他们一定存在着对应关系。
这个问题的本质是,类型约束是语言特性,但是和业务属性无关,只要他们能确认是一个业务含义,不管他们怎么换“马甲”,他们总是能匹配上的。
这样就演变成了:
怎么确定两个类型是一个业务含义;
怎么确定属性的对应关系(字段匹配)。
第一个好说,主要能有唯一的业务标识,就能确定是一个业务含义;怎么确定属性的对应关系呢?
现有的技术体系里就有可以借鉴的思想:数据库的使用。像 jetpack 的 Room 组件:
@Entity(tableName = "users")data class User( @PrimaryKey(autoGenerate = true) var userId: Long, @ColumnInfo(name = "user_name")var userName: String, @ColumnInfo(defaultValue = "china") var address: String)可以看到,我们只要要在应用层这么定义一个数据 Model 叫 User,为它加上注解,就可以把数据库中的字段和我们的数据对应上。那么方案呼之欲出,注解是可以完成属性匹配的。
于是乎整个流程就简化成了:
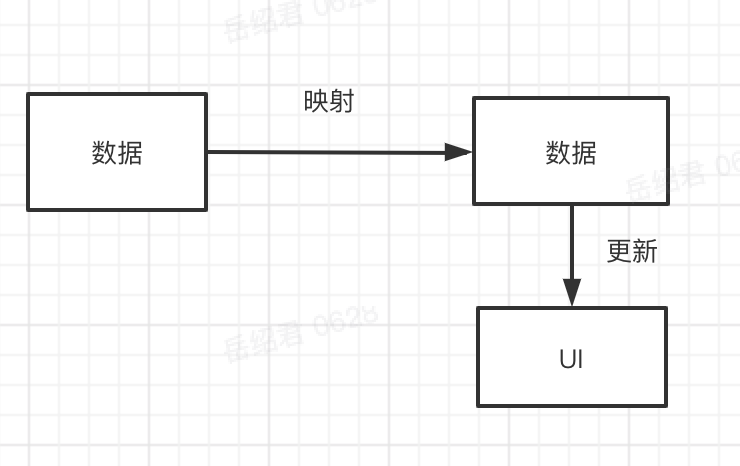
这个流程可以看到,只剩下了两个角色,和两个操作了。
所谓数据更新 UI,就是 View-Model;数据映射数据,就是 Data-Mapping,于是这个方案的名称就是 VM-Mapping。
详细设计
需要对上述抽象流程做实现。
映射
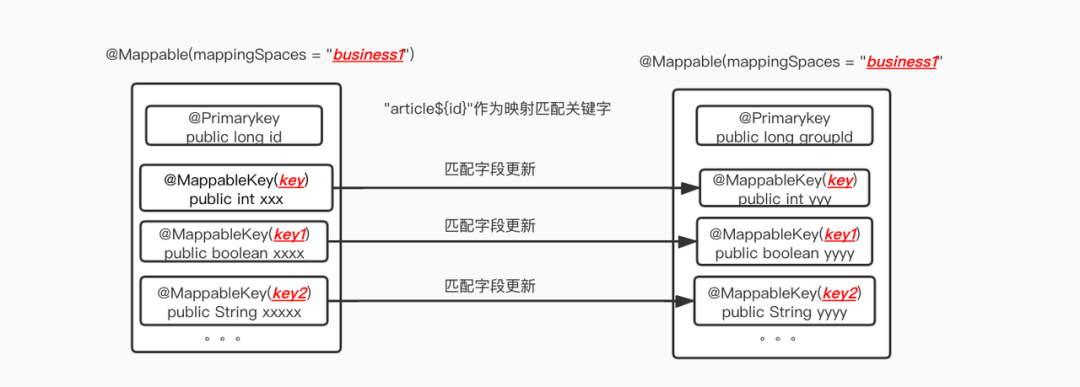
前面说到,映射关系由注解维护,一个有三个注解:
Mappable 注解 :
标注在 class 上,用来识别这个类是不是可以被处理。
annotation class Mappable(val mappingSpaces: Arrary<String>)其中 mappingSpace 是命名空间,表示是“一类”数据,可以和数据库表名对比理解,mappingSpace 就是 tableName。
PrimaryKey 注解:
标记在字段上,被标记的字段作为 Model 对象的唯一标识。
mappingSpace+PrimaryKey 的值,就是在映射关系中的唯一业务标识。
@Target(AnnotationTarget.FIELD)@Retention(AnnotationRetention.RUNTIME)annotation class PrimaryKeyMappableKey 注解:
标注在字段上,需要被映射对应的字段
Target(AnnotationTarget.FIELD)@Retention(AnnotationRetention.RUNTIME)annotation class MappableKey(val value: String)映射关系说明:
数据驱动 UI
Android 里有很多类似理念的东西,比如 LiveData,就是数据更新通知到 UI 上。本质上数据驱动 UI,就是在数据 Data<->UI 之间建一个“桥梁”。
这个不过 LiveData 并不适合用在这里,理由是:
LiveData 绑定的生命周期是 LifecycleOwner,也就是 Activity、Fragment 维度,明显我们的场景维度更细;
直接 observeForever 也可以,但是由于 View 层级的多样,调用方通常需要合适的时机移除;
LiveData 强引用了数据 Data,这个“桥梁”本身对数据 Data 的生命周期造成了影响。
VM-Mapping 做了个简单方案。用了两级 HashMap,一级 HashMap 使用业务唯一标识(mappingSpace+PrimaryKey 的值)为 KEY,二级使用 WeakHashMap,以数据 Model 实例为 KEY,XGViewModel 为 VALUE。维护数据 Data 和 UI 回调之间的关系:
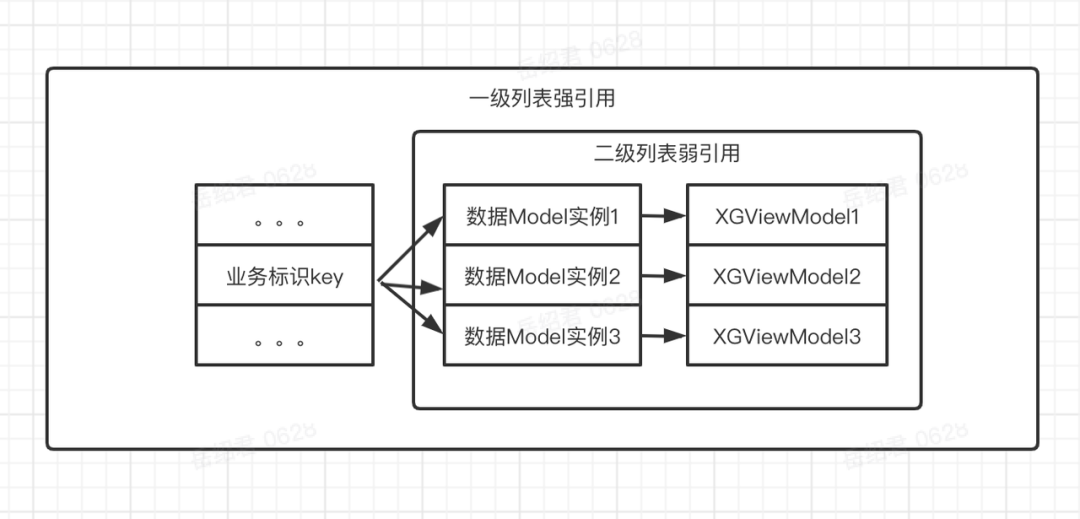
XGViewModel 维护了通知给 UI 的弱引用回调合集。一个数据 Model 实例对应了一个 XGViewModel。
当映射发生时,会通过业务标识 Key,查找所有还没有被回收的数据 Model 实例,然后通过对应的 XGViewModel 通知 UI 自己的变更。
总体流程
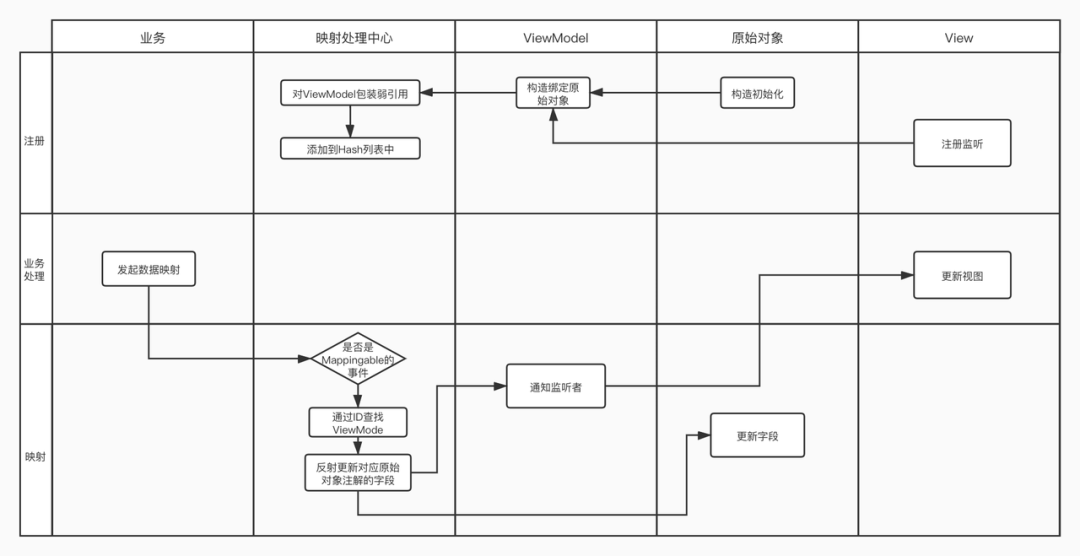
在这个流程中,业务使用只需要关心发起映射数据和更新视图。
因为存在列表,那么会有一个列表的维护者,就是所谓的映射中心。映射中心有两个核心能力:
收集需要被更新的数据 Model 列表;
查找匹配。
其它细节
因为使用了反射,为了减少性能损耗,会对收集的数据 Model 类型做 class 和相关字段的缓存。
列表存在膨胀现象,二级弱引用列表的 key 是数据 Model 实例本身,当它被虚拟机回收的时候,会把一级列表中的该项移除,当一级列表某个 key 下没有内容时,也会把该 key 移除。
移除的时机在每次添加数据 Model 到列表;
移除的条件是一级列表长度达到阈值。
但是注意,这个移除并不会影响 VM-Mapping 的能力,因为 VM-Mapping 关注的是数据本身,当数据被回收的时候,不会有任何场景会用到这个数据,自然也不用关心是不是需要通知到它。
为了避免影响主线程,和多线程竞争列表的问题,映射中心操作都在单子线程中处理。
方案对比
方案收益
西瓜在之前遗留了大量的类似问题,一直没有好的方案解决,要么存在根本性缺陷,要么实施成本高。VM-Mapping 支持了在西瓜中视频相关的核心场景快速接入,实现了线上点赞数异常问题清零。
后续计划
根据统计,由于使用运行时注解+反射,一个操作的耗时均值在 10ms 左右。仍然有可以优化的空间。可以考虑使用编译时注解维护数据映射关系。
目前订阅数据的变化,维度是数据本身,而不是变化的字段,可以考虑通过 kotlin delegate 细化监听维度。
本文转载自:字节跳动技术团队(ID:BytedanceTechBlog)




