背景
业务线开发环境的困扰
年初的时候机票的同事向我们反馈,希望可以提供 Docker 环境帮助他们快速构建开发环境,加速功能的迭代。正好我们 OpsDev 团队也在为容器寻找试点,双方一拍即合,立即开始了前期的调研工作。
随着交流的深入,我们发现对于一个包含了几十个模块,快速迭代的系统,开发团队想要建立一个相对稳定的,能覆盖周边模块的开发和自测环境是非常困难的,除了要申请虚拟机外,还要新增 profile,创建 jenkins job,发布,服务依赖等一系列的流程。

即使解决了以上问题,运维这套环境又是个大麻烦:项目之间的依赖关系写在配置文件中,切换环境时需要手工修改;多套不同版本的环境维护起来费时费力;对于涉及面较广的联调,需要其他组的同事配合完成,更不用说这些模块间的版本如何有效的保证一致了。。
整理问题
经过多次的讨论和调研,最终双方团队确认出几个业务线最关心的功能,优先解决:
- 版本一致,即代码版本,配置版本和数据库 schema 一致,减少联调时不必要的适配和调整。
- 快速切换多套环境。
- 服务依赖,开发新人也可以轻松部署整套复杂的环境。
- 维护简单,例如新增项目时,自动加入到整套环境中。
- 低学习成本,节约时间去开发业务。
- 环境隔离,最好每个人一套完整环境,不互相影响。
暂时性解决 0 和 1 的问题
业务线的同事用 docker-compose 临时搭建了一套开发环境,但是需要手工维护版本以及 nginx 的转发,同时也暴露出了更多的问题:
- 能支撑如此多模块的 compose,只能是实体机,资源限制较大。
- 扩容模块时的端口冲突问题。
- 数据库持续集成
- 容器固定 IP
需要找到一个治标又治本的方案解决业务线的问题。
寻求解决之道
参考了现有的容器集群方案后,最终焦点集中在了 Apache Mesos(后简称 Mesos)和 Google Kubernetes 上。Kubernetes 的 pod 和 service 概念更贴近业务线的诉求,同时,Mesos 在资源管理和调度灵活性上显然经得起生产的考验。最终团队决定两者并行测试,在各自的优势方向寻找试点项目做验证。
项目试点
仔细考量后,我们选择了基于 ELK 构建的日志平台作为验证 Mesos + Docker 的切入点,积累相关的开发和运维经验。
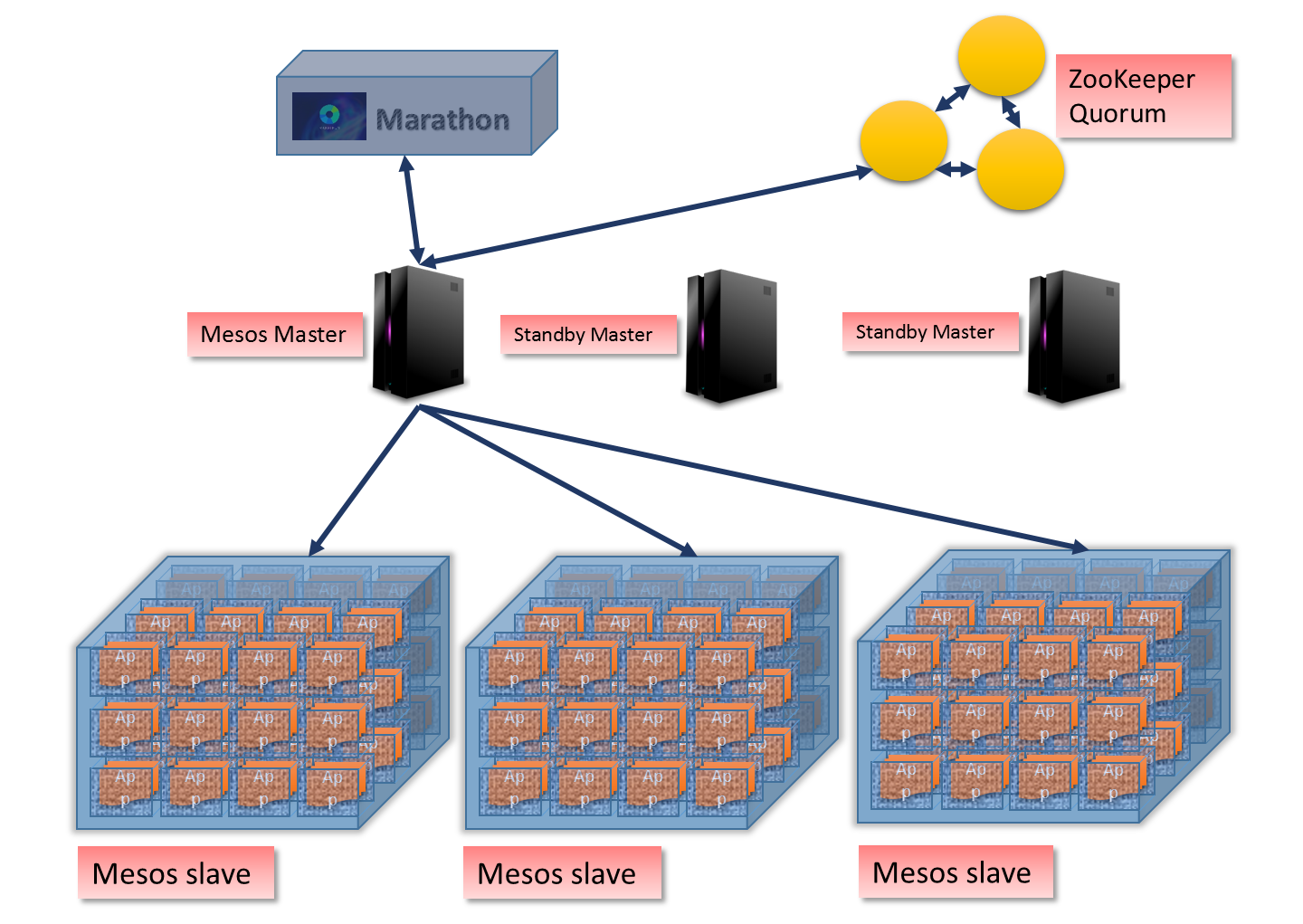
图一 典型的 Mesos + Docker 结构(source from google)
首先容器化的是 Logstash 和 Kibana,Kibana 本身作为 ElasticSearch 的数据聚合展示层,自身就是无状态化的,Logstash 对 SIGTERM 有专门的处理,docker stop 的时候可以从容处理完队列中的消息再退出。而 ElasticSearch 部署在 Mesos 集群外,主要考虑到数据持久化的问题以及资源消耗。采用 Marathon 和 Chronos 调度 Logstash 和 Kibana,以及相关的监控、统计和日志容器。
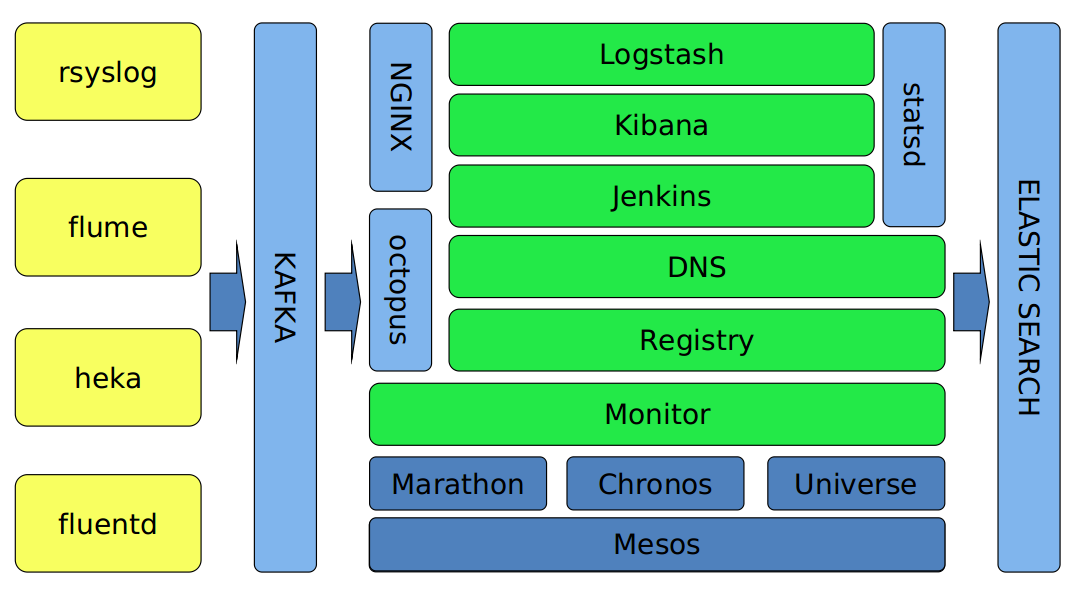
图二 日志平台的结构
数据来自多种方式,针对不同的日志类型,采取不同的发送策略。系统日志,比如 mail.log、sudo.log、dmesg 等通过 rsyslog 发送。业务日志采用 flume,容器日志则使用 heka 和 fluentd。汇总到各个机房的 Kafka 集群后,粗略的解析后汇总到中央 Kafka,再通过 Logstash 集群解析后存入 ElasticSearch。同时,监控数据通过 statsd 发送到内部的监控平台,便于后续的通知和报警。
随着业务线日志的逐步接入,这个平台已经增长成为单日处理 60 亿条日志 /6TB 数据的庞大平台。
问题和经验总结
1. Daemon OOM
最初我们使用的 Docker 版本是 1.6,docker attach 接口存在内存泄露,容器的 stdout 输出较多日志时,比较容易造成 daemon 的 OOM。
{code}
fatal error: runtime: out of memory
runtime stack:
runtime.SysMap(0xc2c9760000, 0x7f310000, 0x7f453c96b000, 0x13624f8)
/usr/local/go/src/runtime/mem_linux.c:149 +0x98
runtime.MHeap_SysAlloc(0x1367be0, 0x7f310000, 0x43b8f2)
/usr/local/go/src/runtime/malloc.c:284 +0x124
runtime.MHeap_Alloc(0x1367be0, 0x3f986, 0x10100000000, 0x0)
/usr/local/go/src/runtime/mheap.c:240 +0x66
......
{code}
这个问题是比较严重的,daemon 挂掉后容器跟着都宕机了,虽说上层的 Marathon 会重新部署应用,但是频率较高的话容易造成集群不稳定。
首先想到的办法就是用 runsv 启动 daemon,保证进程宕掉后可以重新被拉起。其次,参考了 Kubernetes 的做法,在 daemon 启动后修改 oom_adj 的值为 -15,防止 daemon 被最先 kill 掉。
最治标的办法还是升级 Docker 的版本,或者自己 patch 这个 bug( https://github.com/docker/docker/issues/9139)。
2. Heka 的 DockerEventInput 不释放 socket
DockerEventInput 使用的 go-dockerclient 有 bug,heka 异常推出后不会关闭 socket,容易导致文件句柄泄露,最终导致 daemon 不再接受任何命令,这个 BUG 在 v0.10.0b1 仍然还存在。
{code}
time="2015-09-30T15:25:00.254779538+08:00" level=error msg="attach: stdout: write unix @: broken pipe"
time="2015-09-30T15:25:00.254883039+08:00" level=error msg="attach: stdout: write unix @: broken pipe"
time="2015-09-30T15:25:00.256959458+08:00" level=error msg="attach: stdout: write unix @: broken pipe"
{code}
相关问题: https://github.com/fsouza/go-dockerclient/issues/202。
3. 对新加入集群的 slave“预热”
同在局域网内,第一次下载镜像也是比较慢的,推荐在 slave 部署完毕后,主动 pull 一批常用的镜像,减少第一次启动的时间。这个工作我们放在 salt、ansible 脚本里自动部署。另外,对于基础监控类的容器,Marathon 目前还未支持自动 scale,需要自己实现。
相关讨论: https://github.com/mesosphere/marathon/issues/846
4. Distribution 引起的 daemon 宕机
升级 1.7.1 后发现的问题,起因是一个手误导致 Marathon 的配置没有带上自己的 registry,daemon 去 pull 了官方的镜像。这个坑幸好发生在我们的 registry 准备迁移 V2 的之前,相关的代码还没有 patch 到我们自己的 docker 上,暂时还是使用 V1。
相关问题: https://github.com/docker/docker/issues/15724
(点击放大图像)

5. Mesos 的资源抢占
资源抢占是在 Mesos 0.23.0 版本引入的,官方还不建议在生产环境使用,如何有效的抢占资源一直是我们在使用过程中比较关注的。
Mesos 的资源是直接映射到 role 上的,我们以此为切入点,提前划分多个 role,每个 role 分配静态资源。比如,ops 的 role 运行基础服务,每个 slave 上最多占用 4 个 CPU,logstash 则在每台机器上可以占用 32 个 CPU,以这种方式变相超售 CPU 资源。
MESOS_resources="cpus(logstash):32;"
MESOS_resources="${MESOS_resources}cpus(common):4;"
MESOS_resources="${MESOS_resources}cpus(kibana):4;"
MESOS_resources="${MESOS_resources}cpus(ops):4;"
MESOS_resources="${MESOS_resources}cpus(spark):16;"
MESOS_resources="${MESOS_resources}cpus(storm):16;"
MESOS_resources="${MESOS_resources}cpus(rebuild):32;"
MESOS_resources="${MESOS_resources}cpus(mysos):16;"
MESOS_resources="${MESOS_resources}cpus(others):16;"
MESOS_resources="${MESOS_resources}cpus(universe):1;"
MESOS_resources="${MESOS_resources}cpus(test):8;"
MESOS_resources="${MESOS_resources}mem(*):126976;ports(*):[8000-32000]"
在使用时,不再根据容器的资源使用情况动态调整实例数量,而是交替发布任务抢占 CPU。比如凌晨 2 点至 6 点是业务低峰,日志量少,许多 logstash 容器并未满负荷工作,正适合发布 Spark 的 job。这种调度方式实现简单,基于时间调度,更容易监控。
缺点也是显而易见的,需要提前规划 role,尽量对每种资源消耗大户都分配到一个对应的 role,扩展性较差,适合上层应用较稳定的系统。等 MESOS-3791 合并后,就可以动态的管理 role,那么 Mesos 的资源的管理就会更加灵活了。
6. 版本升级
主要是 Mesos、Docker 的版本升级,由于众所周知的原因,Docker 的升级是比较痛苦的,需要停止所有的容器后再升级 daemon。我们的线上环境经历了 Mesos 0.22.0 到 0.25.0,Docker 1.4.1 到 1.7.1 的演进,总结出了一套比较有效的升级策略,上层服务无感知。首先 Mesos 要开启白名单(–whitelist)功能:
1) 先将要升级的机器踢出白名单,这一步保证了上层的 Framework 在收到 statusUpdate 不会调度到这台机器上;
2) 然后逐个 stop 容器,容器内的应用建议处理 SIGTERM 信号做清理工作;
3) 接着停止 docker daemon 和 mesos slave;
4) 升级 docker 和 mesos 版本;
5) 重启 docker 和 mesos 并将机器重新加入到白名单。
开发环境快速 rebuild
有了日志平台的经验,我们的工作中心开始向实际需求倾斜,尽快满足业务线的环境要求。共经历了三次比较大的变更,主要从兼容性,公司内的发布流程和开发人员易用性的角度考量,逐步演进:
1) OpenStack + nova-docker + VLAN
2) Mesos + Marathon + Docker(–net=host) + 随机端口
3) Mesos + Marathon + Docker + Calico
第一阶段:容器当作虚拟机用
容器的使用和行为尽量模拟虚拟机是我们第一阶段考虑的重点,同时还要考虑到发布系统改造的成本,OpenStack 提供的 nova-docker 自然成了首选。再此基础上,为容器提供外部可访问的独立 IP(VLAN)。nova-docker 和 nova-network 已经提供了大部分功能,整合的速度也比较快。
容器启动后会有多个进程,比如 salt-minion 和 sshd,这样使用者可以 ssh 到容器内 debug,而部署的工作则交给 salt 统一管理。
第二阶段:以服务为核心
逐渐强化以服务为核心的应用发布和管理流程,向统一的服务树靠拢。在第一阶段的成果的基础上,完善服务树的结构和规则,为后面打通监控树,应用树等模块做好充分的准备。
(点击放大图像)

同时,容器开始从 OpenStack + nova-docker 的结构向 Mesos + Marathon + Docker 迁移,整套环境的发布压缩到了 7~9 分钟,其中还包含了 healthcheck 的时间,还有深入优化的空间。
- 依赖放在 QAECI 中维护,发布时根据拓扑排序后的结果选择自动切换并行,串行发布。
- 代码和配置在容器启动后再拉取,减少维护镜像的成本,方便升级运行环境,比如升级 JDK 或 Tomcat。
- 服务端口全部随机生成,并通过环境变量注入到依赖的容器中并替换配置,这样就解决了–net=host 模式下端口分配的问题。dubbo 服务注册的是宿主机的 IP 和 PORT,如果是 bridge 模式的话,记得要注册宿主机的 IP 和映射的 PORT。
- 适当缓存编译后的代码,减少重复构建的时间浪费。
- Openresty + lua 脚本动态 proxy_pass 到集群内的 Tomcat,外部即可通过泛域名的方式访问 Marathon 发布的应用,例如 app1.marathon.corp.qunar.com 即可访问到 app1 对应的 WEB 服务。
- 修改 logback 和 tomcat 的配置,所有日志都输出到 stdout 和 stderr,并附带文件名前缀做区分。并通过 heka,配合 fields_from_env 区分是哪一个 Mesos task 的日志,统一发向日志平台汇总和监控。
第三阶段
为容器分配固定 IP,打通集群内外的服务通信,让开发人员无障碍的访问容器。为此我们引入了 Calico 作为解决方案。Calico 整合 Mesos 比较简单,通过 Mesos slave 启动时指定–modules 和 -isolation 即可使用:
{code}
./bin/mesos-slave.sh --master=master_ip:port --namespaces='network' \ --modules=file://path/to/slave_gssapi.json \ --isolation="com_mesosphere_mesos_MetaswitchNetworkIsolator" \
--executor_environment_variables={“DOCKER_HOST”: “localhost:2377”}
{ "libraries": [ { "file": "/path/to/libmetaswitch_network_isolator.so "modules": [ { "name": "com_mesosphere_mesos_MetaswitchNetworkIsolator", "parameters": [ { "key": "initialization_command", "value": "python /path/to/initialization_script.py arg1 arg2" }, { "key": "cleanup_command", "value": "python /path/to/cleanup_script.py arg1 arg2" } ] } ] } ] }
{code}
这样 Mesos 在执行 Docker 命令的时候,所有的请求都被 calico 容器劫持并转发给 docker daemon,同时给容器分配 IP,上层的 Marathon 只需要额外添加两个 env 配置:
- CALICO_IP=auto|ip
- CALICO_PROFILE=test
结合我们自身的网络结构,我们在交换机上预留了一个 IP 段,全部指向了 calico 的两台 gateway,转发到 Mesos 集群内部:
(点击放大图像)

同时整合公司内的DNSDB 服务,将容器的名称和IP 自动注册到DNSDB 内,这样全公司的人都可以访问到这个容器,打通集群内外的通信。对于一些有特殊要求的情况,如开发机的名称必须符合一定命名规则,通过传入–hostname 就可以模拟一台开发机。
总结
经过近1 年来的使用和运维,在Docker 和Mesos 上踩了不少的坑,多亏了社区的贡献者们,积累了许多经验。Mesos 表现出的稳定性、可用性和扩展性足够担当生产环境的资源管理者,美中不足的是调度策略略显单一,依赖上层Framework 的二次调度。
后续我们将考虑在第四阶段调研Swarm on Mesos,利用Docker 公司原生的集群方案配合Mesos 的资源管理,为业务线提供更加稳定,便利的容器环境。
感谢郭蕾对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入 InfoQ 读者交流群 (已满),InfoQ 读者交流群(#2))。
(已满),InfoQ 读者交流群(#2))。




