
实时数据采集(又称为“变化数据捕获”Change Data Capture,下文又称 CDC、实时抽数)在实时计算、跨库实时同步等领域具有极高的应用价值。相较于其他数据库,Oracle 由于其闭源特性,目前缺乏免费且好用的解决方案。尽管 Oracle 提供了 LogMiner 接口且被以 Debezium 为代表的优秀开源方案所使用,但应用于生产实践时,Debezium 相较于 Oracle 官方付费工具 OGG,具有如下硬伤:
只能对主库 CDC,无法用于 ADG 备库(参见DBZ-3866)。由于 LogMiner 的设计初衷为对 Redo logs 的诊断工具而非专门的 CDC 工具,故并未对持续运行进行任何效率、开销等优化,直接运用于主库势必会对主库业务正常运行造成影响。这对于应用 Oracle 的典型企业(银行、电信等要求高可靠性的公司)实则不可接受。
抽取性能受限。按照Oracle官方的说法,在每秒钟几百个事务时就会遇到较大的延迟和内存问题。Debezium 框架由于其实现,实际解析速度比这个数值更低。
为此,笔者通过深入研究 LogMiner 原理和 Debezium 源码,在其基础上进行改进,使其真正可用于生产实践。
说明:笔者的实验环境为 Oracle 11g 和 Debezium 1.5.4。但通过核对 Oracle 最新官方文档(21c)和 Debezium 最新源码(截至 2022 年 6 月 21 日最新版 1.9.4),本文所涉及的方案对 11g-21c 的 Oracle,以及 Debezium1.5.4 以上版本均适用(文中涉及到的 Debezium 源码均为 1.5.4 版本,非 1.5.4 版本的具体代码细节需根据文中原理自行定位)。限于篇幅本文对 Debezium 基础使用不做介绍,读者可参考官方文档了解其基本配置和用法。
一、LogMiner 抽数的基本过程
限于篇幅仅简要介绍其五个基本步骤,详细说明可参阅Oracle官方文档:
1)构造字典文件:EXEC DBMS_LOGMNR_D.BUILD(OPTIONS=> DBMS_LOGMNR_D.STORE_IN_REDO_LOGS);
2)添加 Redo Logs:EXEC DBMS_LOGMNR.ADD_LOGFILE(LOGFILENAME => '/oracle/logs/log2.f', OPTIONS=> DBMS_LOGMNR.ADDFILE);
3)开启 LogMiner:EXEC DBMS_LOGMNR.START_LOGMNR(startScn => '..', endScn => '..');
4)查询 V$LOGMNR_CONTENTS 视图获取 Redo 信息并处理
5)查询当前的活跃 Online Redo Log 是否有变化,如果无变化则跳转到第 3)步,如果有变化则关闭 LogMiner(EXEC SYS.DBMS_LOGMNR.END_LOGMNR)并跳转回第 1)步。
二、ADG 备库抽数原理
为了介绍从 ADG 备库 CDC 方案,在此先对Oracle对Redo Logs的管理和ADG的原理简介如下:
Online Redo Logs 记录 Oracle 中的一切变化信息,由至少 2 个(组)预分配的文件构成。LGWR(LoG WriteR)进程循环写入这些文件,每次仅往其中一个(组)Online Redo Log 写入变化信息,每一条信息对应一个单调递增的 SCN(System Change Number)。当该 Online Redo Log 写满,或者被显式调用 ALTER SYSTEM SWITCH LOGFILE(强制切换 Online Redo Log),或者写入时间超过 ARCHIVE_LAG_TARGET 参数值,则 LGWR 切换到下一个(组)Online Redo Log 写入变化信息。同时,上一个(组)Online Redo Log 会由归档进程 ARCn 将其内容写入新的 Archived Redo Log。
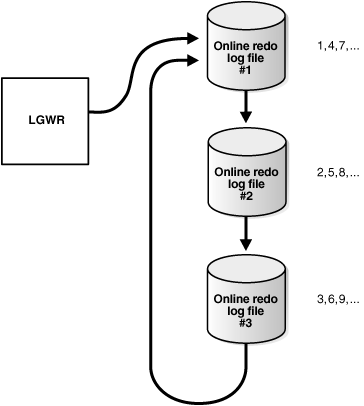
图源:Oracle 官方文档
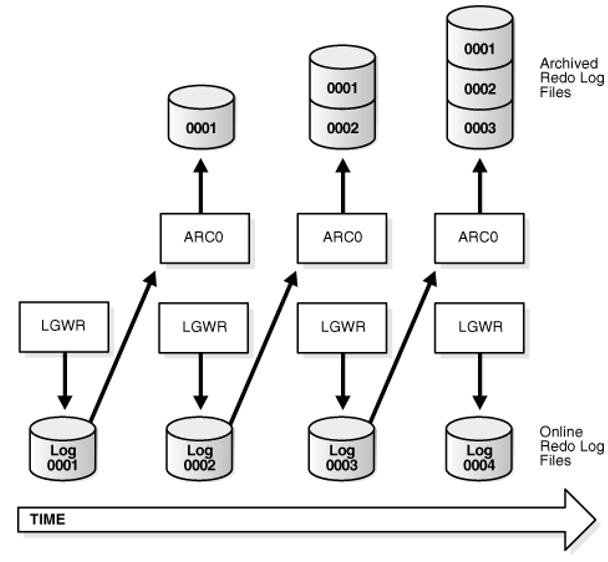
图源:Oracle 官方文档
ADG 为了保证同步效率,选择了仅仅同步恢复 Oracle 事务所需的信息(即 Redo 记录)。为了免受磁盘 I/O 状态影响,Redo 记录在尚未落地至主库 Online Redo Log 文件时,即直接从内存中实时传送至备库,备库收到这些 Redo 信息后便将其实际应用于物理库中。备库中 RFS(Remote File Server)进程负责将收到的 Redo 信息同步写入 Standby Redo Logs。当主库发生 Online Redo Log 切换时,RFS 进程同步进行 Standby Redo Log 切换,将新的 Redo 信息写入下一个(组)Standby Redo Log,并由归档进程 ARCn 将上一个(组)Standby Redo Log 内容写入 Archived Redo Log。
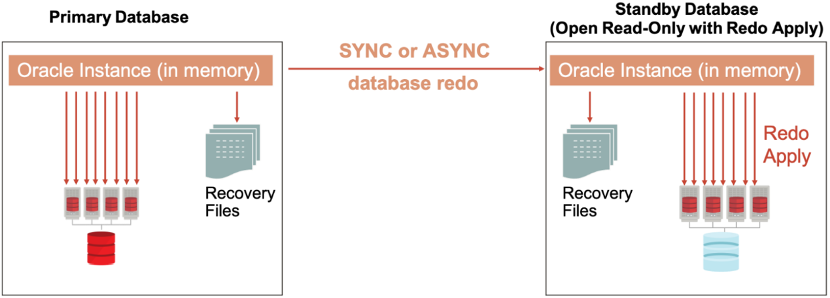
图源:《Oracle Active Data Guard versus Storage Remote Mirroring》
由上可知:
数据抽取时 Online Redo Logs 和 Archived Redo Logs 缺一不可。前者用于获取最新的实时数据,后者用于在抽取速度跟不上数据库变化速度时,保证能够无遗漏地获取所有变化数据。
ADG 备库中,Standby Redo Logs + Archived Redo Logs,具有和主库 Online Redo Logs + Archived Redo Logs 相同的内容。
三、ADG 备库抽数实践
根据上述原理,我们可对 LogMiner 抽数步骤进行调整如下:
1. 备库新建单独 Oracle 实例
使用 DBCA 工具(推荐)或者 CREATE DATABASE 语句(参数复杂,不推荐)在 ADG 备库所在物理机新建单独的 Oracle 实例。假设新建的数据库服务名为 logmnr,原备库的服务名为 datadg。(后文将详述为什么需要新建 logmnr 库进行抽数而不是直接在 datadg 上抽数,以及为什么要在备库所在物理机上新建 logmnr 库)。后续的过程需关注每一步是在 datadg 实例上做,还是在 logmnr 实例上做。
2. 创建平面(Flat)字典文件
在 datadg 实例上,使用 DBMS_LOGMNR_D.BUILD 命令创建字典文件:
EXECUTE DBMS_LOGMNR_D.BUILD(DICTIONARY_LOCATION=>'/home/oracle/logmnr', DICTIONARY_FILENAME=>'dictionary.ora',OPTIONS=> DBMS_LOGMNR_D.STORE_IN_FLAT_FILE);
注意自 Oracle 12c 起往后的版本,dictionary_location 需替换为目录对象,具体参见官方文档说明。
3. 筛选 Standby Redo Logs 和 Archived Redo Logs。
在 datadg 实例上筛选。Archived Redo Logs 的筛选逻辑和 Debezium 框架内置实现相同,读者可直接参考 io.debezium.connector.oracle.logminer.SqlUtils 类中 archiveLogsQuery 方法实现。Standby Redo Logs 的筛选逻辑如下(可参考V$STANDBY_LOG的字段说明理解下述逻辑):
SELECT MIN(F.MEMBER) AS FILE_NAME, L.LAST_CHANGE# AS LAST_CHANGE, F.GROUP#, L.FIRST_CHANGE# AS FIRST_CHANGE, 'CURRENT' as STATUS FROM V$STANDBY_LOG L, V$LOGFILE F WHERE F.GROUP# = L.GROUP# AND (L.ARCHIVED='NO' or L.STATUS='ACTIVE') GROUP BY F.GROUP#, L.LAST_CHANGE#, L.FIRST_CHANGE#, L.STATUS ORDER BY 3;
4. DBMS_LOGMNR 添加 Redo Logs
在 logmnr 实例上,使用 DBMS_LOGMNR.ADD_LOGFILE 添加第 3)步所筛选出的 Redo Logs。(注意:我们第 1 步中选择在 ADG 备库所在的物理机上创建新的 Oracle 实例,就是为了能使该实例能正常读取这些 Redo Logs)
5. DBMS_LOGMNR 开启 LogMiner
在 logmnr 实例上,使用 DBMS_LOGMNR.START_LOGMNR 开启 LogMiner,并查询 V$LOGMNR_CONTENTS 视图获取 Redo 信息并处理。
6. 判断跳转步骤
在 datadg 实例上,查询当前的活跃 Standby Redo Logs 是否有变化。无变化则循环执行第 5 步,否则关闭 LogMiner(EXEC SYS.DBMS_LOGMNR.END_LOGMNR)并跳转到第 2 步。
四、ADG 备库抽数相关问题
1. 为什么需要新建单独的 Oracle 实例 logmnr 进行抽数?
笔者尝试过直接在 datadg 上进行抽数(即上一章节的所有步骤均在 datadg 上执行),在执行到查询 V$LOGMNR_CONTENTS 步骤时,发现查询会卡死无法继续。
为此,笔者按照如下步骤开启 Oracle 10046 Trace(SQL_TRACE):
alter session set tracefile_identifier='10046';
alter session set timed_statistics = true;
alter session set statistics_level=all;
alter session set max_dump_file_size = unlimited;
alter session set events '10046 trace name context forever,level 12';
并重新将所有步骤在 datadg 中执行,执行到查询 V$LOGMNR_CONTENTS 步骤时,观察在 Trace 目录下(select value from v$diag_info where name='Diag Trace'),10046 文件中会持续输出以下内容:
*** 2022-06-27 15:06:04.528
WAIT #139654617260408: nam='enq: WL - contention' ela= 30000095 name|mode=1464598531 log # / thread id #=2001421497 sequence #=972043434 obj#=-1 tim=1656313564528578
WAIT #139654617260408: nam='ARCH wait for archivelog lock' ela= 140 p1=0 p2=0 p3=0 obj#=-1 tim=1656313564528712
*** 2022-06-27 15:06:34.537
WAIT #139654617260408: nam='enq: WL - contention' ela= 30008500 name|mode=1464598531 log # / thread id #=2001421497 sequence #=972043434 obj#=-1 tim=1656313594537263
WAIT #139654617260408: nam='ARCH wait for archivelog lock' ela= 149 p1=0 p2=0 p3=0 obj#=-1 tim=1656313594537402
由于 ADG 备库中的相关进程对这些 Redo Logs 文件加锁处理,使得 LogMiner 进程无法同时对其进行操作。但由于这种加锁仅限于这些进程所在的 Oracle 实例(即 datadg)而非该实例所在的操作系统(物理机),故在同一物理机上创建新的 Oracle 实例可解决该问题。
2. 字典文件是做什么用的?为什么需要采用 Flat File?
字典文件用于将表名、字段名等元信息的物理表示转换为逻辑表示。如果在 DBMS_LOGMNR.START_LOGMNR 步骤中不指定字典文件,则得到的 Redo SQL 将会类似于下面这样:
update "UNKNOWN"."OBJ# 1456235" set "COL 64" = HEXTORAW('3330383339') where "COL 1" = HEXTORAW('313330323230313038333835383436') and ...... and ROWID = 'AAFjhrAA6AANcSoAAF';
Oracle 提供了三种访问字典文件的方式:直接使用 online catalog,将字典文件导出至 Redo Log,将字典文件导出至 Flat File(即单独的字典文件)。由于我们选择在单独的 Oracle 实例中抽数,无法获取 online catalog,故只能选择第二种或第三种方式。尽管 Oracle 官方不推荐第三种方式(所以 Debezium 中并未内置支持),但该方式的效率实测比第二种高出不少(经笔者实测,采用第二种方法会将数据延迟由几秒钟放大至 3-5 分钟),且在我们的生产实践中并未观察到 Oracle 官方声称的不一致现象(因为生产系统鲜少有对存量表和字段的删除、插入等 DDL 操作),故推荐将字典文件存储于 Flat File。
五、提升 Debezium 框架抽数速度
按照上文的原理和基本步骤,笔者对 Debezium 框架进行了修改,成功实现了对 Oracle ADG 备库的数据抽取。但又出现了新的问题:
抽取速度过低,实际发送至 Kafka 的速度仅为约 60 条/秒。
对于大事务(譬如一个更新了几十万条记录的 update 语句)会报内存溢出,无法继续抽数。
形成该问题的原因有二:
l LogMiner 的设计初衷为对 Redo logs 的诊断工具而非专门的 CDC 工具,故对抽取效率并未做优化。
l Debezium 框架仅考虑到功能的正确实现,并未考虑到对抽取效率的调优。
据此,笔者通过排查程序运行堵点,采用分发器模式对源代码进行重构,并对部分逻辑进行优化,最终使大事务时的解析速度从原先的 60 条/秒提升至 3000 条/秒以上。
1. Debezium 解析 V$LOGMNR_CONTENTS 的过程
V$LOGMNR_CONTENTS 中记录了按照 SCN 顺序排列的变化信息。需要注意的是,对于 DML 类操作,变化信息是基于行的(譬如一个 UPDATE 语句更新了 100 条记录,那么 LGWR 进程会实际上往 Redo Log 中写入 100 条 UPDATE 语句,每条语句仅更新一行,V$LOGMNR_CONTENTS 中也会实际上存储 100 条 DML 记录)。
Debezium 在调用完毕 DBMS_LOGMNR.START_LOGMNR 后,依次进行如下操作:(详见 io.debezium.connector.oracle.logminer 包下 LogMinerStreamingChangeEventSource 和 LogMinerQueryResultProcessor 类):
1)读取 V$LOGMNR_CONTENTS 并将结果记于 ResultSet。
2)若 ResultSet 中仍有内容,读取新的记录并判断类型。
3)如果是 DML 操作,那么将操作内容暂存于 Transaction 中;如果是 COMMIT 操作,那么将 Transaction 暂存内容组装为 Kafka Connect 支持的格式并发送;如果是 ROLLBACK 操作,那么将 Transaction 暂存内容丢弃。
4)跳回第 2)步继续执行,直到 ResultSet 全部内容读取结束。
需要注意的是,在 Debezium 中,以上过程全部为主线程串行执行。这种方式具有如下问题:
所有的操作均为单线程顺序执行,一方面单线程执行没有充分挖掘并发效率,另一方面,顺序执行将本地 CPU 密集操作(步骤 2)-3))和数据库密集操作(步骤 1))分开,造成资源的严重浪费。
所有 Redo 记录顺序处理,无法预知当前处理的 DML 操作所对应的 Transaction 将要被 COMMIT 还是 ROLLBACK,故无法将 Redo 信息直接发送至 Kafka Connect,需多一步组装暂存的过程,不仅耗时还可能出现如下文所说的内存溢出的问题。
2. 架构优化
根据上节分析,笔者采用分发器模式,对 Debezium 整体框架进行了优化,下图为架构设计:
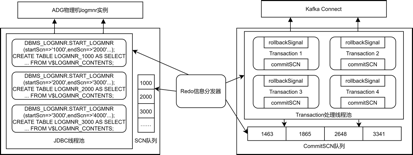
对该架构说明如下:
1)Oracle 对 LogMiner 做了非常严格的资源限制,每个 Logminer 进程资源消耗都不能超过 1 个 CPU 核心。因而当我们开启多个 LogMiner 进程同时挖掘时,可以观察到挖掘速度会有明显提升。但为了保证开启多进程后不影响 Redo 信息的处理顺序,我们需要维护一个 SCN 队列,代表每个 START_LOGMNR 操作的起始 SCN。Redo 信息分发器需要按照该顺序进行 Redo 信息分发。
每个 LogMiner 进程需要将查询 V$LOGMNR_CONTENTS 结果进行存储的原因,一是查询该视图的时间开销较大,不能直接让 Redo 信息分发器查询;二是暂存后 LogMiner 进程可以继续向后挖掘,不需要等待 Redo 信息分发器的后续处理。
2)Redo 信息分发器按照 SCN 顺序,对每一条 Redo 信息,拿到 Transaction ID 后直接将其派发到 Transaction 处理线程池的对应 Transaction 线程。特别地,如果这条 Redo 信息操作类型为 COMMIT,那么将对应 Transaction 线程的 commitSCN 置为该条信息的 SCN,并且将该 SCN 加入 CommitSCN 队列;如果这条 Redo 信息操作类型为 ROLLBACK,那么将对应 Transaction 线程的 rollbackSignal 置为 1。
每个 Transaction 线程在处理信息时,如果 rollbackSignal 为 1,那么直接结束处理过程;如果 CommitSCN 不为空且等于 CommitSCN 队头元素,则将当前解析完毕的信息直接发送至 Kafka Connect,否则通过对象流方式暂存,稍后再实际发送。
3. 需要关注的问题(一)——通过对象流暂存解析后 Redo 信息
Debezium 截至目前最新版本,均在内存中暂存操作类型为 DML 的 Redo 解析信息(具体可见 Io.debezium.connector.oracle.logminer.TransactionalBuffer 类中的内部类 Transaction,其使用 List
解决方式是使用对象流方式,将待提交信息序列化存储于文件中。需要注意:
为了防止内存泄露,不要将所有待提交事务转储于同一个文件中,可以譬如每 1000 条记录切换一个文件。
对象流读取/写入需要 I/O 开销,在处理 DML 记录和 COMMIT 事件阶段,应分别启动专门的写入线程和读取线程,并采用生产者/消费者模式,构造缓冲区队列,对待写入或已读取的 DmlEvent 进行管理。
4. 需要关注的问题(二)——修正 Debezium 中过于繁冗的解析
Io.debezium.relational.RelationalChangeRecordEmitter 类中的 emitCreateRecord/emitReadRecord/emitUpdateRecord/emitDeleteRecord 中,均执行了 tableSchema.valueFromColumnData 方法。在笔者的排查中,该方法是除 LogMiner 本身执行效率外,实际发送至 Kafka 的速度过慢的最大性能瓶颈。
该方法所做的是将 LogMiner 解析后的记录转换为 Kafka Connect 能够识别的记录。通过阅读 LogMiner 的解析器 io.debezium.connector.oracle.logminer.parser.LogMinerDmlParser 源码可知,该解析器事实上将所有字段都转换成了 String 类型。由于 String 类型一定可被 Kafka Connect 正确识别,笔者选择了在 RelationalChangeRecordEmitter 的子类 io.debezium.connector.oracle.logminer.LogMinerChangeRecordEmitter 中,对相关的方法进行重写,省去调用 tableSchema.valueFromColumnData 的过程,直接将已解析的字段传递给 Kafka Connect。
六、结束语
本文阐述了针对 Debezium 做适应性优化和改造的方法,使其能够对主库无影响的情况下针对 Oracle 备库进行抽数,并将抽取速度提升至生产实际可用的程度。对于一般应用系统可作为替代 Oracle OGG 的“免费”且“好用”的方案选择。
作者介绍:
丁杨,现任职于中国农业银行研发中心,在大数据领域具有多年研发经验,现主要负责流批一体化计算在银行业务领域的应用研究。




