
注:原文发表于 ICMEW2021
EFFICIENT FACE ALIGNMENT NETWORK FOR MASKED FACE
摘要:2020 年新冠疫情在全球突然爆发,严重地影响了我们的正常生活。佩戴口罩成为了阻止疫情蔓延的重要方法,口罩逐渐成为了我们日常生活中的必须品。然而口罩的大量使用为那些以人脸为基础的算法(如人脸识别、视频安防等)带来了严重的挑战。
人脸对齐作为众多人脸分析任务的基础,性能也受到了严重的影响。为了提升人脸对齐模型在口罩等遮挡场景中的鲁棒性,在本文中我们提出了一种高效的口罩人脸对齐模型,命名为 MaskFAN。
在模型中我们使用了深度可分离卷积和分组卷积来构建了一个轻量化的特征提取网络。为了提升模型对遮挡数据的鲁棒性,我们设计了一种全新的 loss 函数用于辅助模型的训练。此外,我们还探索了 3D 数据增广方法来生成大量带有口罩的人脸图片。实验结果显示,我们所提出的方法在模型体积和计算量都很小的情况下,性能明显优于现有的方法。
关键词:人脸对齐、轻量化模型设计、口罩遮挡
1. 介绍
2020 年初,新型冠状肺炎在世界范围内大肆传播,口罩作为一种防止疫情扩散的有效手段,被广泛的使用。然而,大量使用的口罩为人脸相关的算法带来了严重的挑战,例如现有的人脸识别系统几乎无法正常工作。人脸对齐模型是多种人脸算法的基础,性能同样因为口罩而受到严重影响。为了解决这一问题,我们从提升模型遮挡鲁棒性的角度来增强算法的定位精度。
人脸对齐的目标是在一张输入的人脸图像中找到一些具有特殊语音信息的位置,如鼻尖、眉梢、嘴角等。人脸对齐在人证比对、3D 人脸重建、视频美颜等多个领域发挥这重要的作用;因此近年来受到了学术界和工业界广泛关注,在性能上取得了极大的突破。
随着人工智能等技术的不断发展,深度学习、卷积神经网络在计算机视觉领域中被大量使用,在效率和精度上都远优于传统的方法。与之类似,基于深度学习的方法自 DCNN 之后,也成为了人脸对齐领域中的主流方法。一些工作指出,当人脸图片未被严重遮挡时,现有的人脸对齐模型仍然能够取得较好的效果;
然而,一旦佩戴口罩,脸上的大部分区域都会被覆盖住,通用的人脸对齐方法几乎无法正常工作。一些工作试图通过使用更加复杂的特征提取模型来解决遮挡问题。但是,这些复杂的特征提取网络在运行时需要耗费大量的资源,因此很难在嵌入式设备中部署和使用。人脸对齐算法对遮挡的鲁棒性和运行效率都需要被思考和解决。
为了解决上述提到的问题,我们从两个角度对现有的人脸对齐方法进行了优化。首先,为了提升算法对遮挡(口罩)的鲁棒性,我们设计了一种全新的 loss 函数和数据增广策略。其次,我们使用了深度可分离卷积和分组卷积设计了一种轻量化且适用于人脸对齐的特征提取网络。
2. 方法
在这一部分中,我们将详细的介绍 MaskFAN 的设计思路和训练过程。一般来说,人脸对齐模型通常使用 RGB 图像作为输入,然后输出一组特征,其中 H 和 W 分别表示输入图像的高和宽,N 代表模型所需预测点的个数。图 1 是算法的总体流程图。
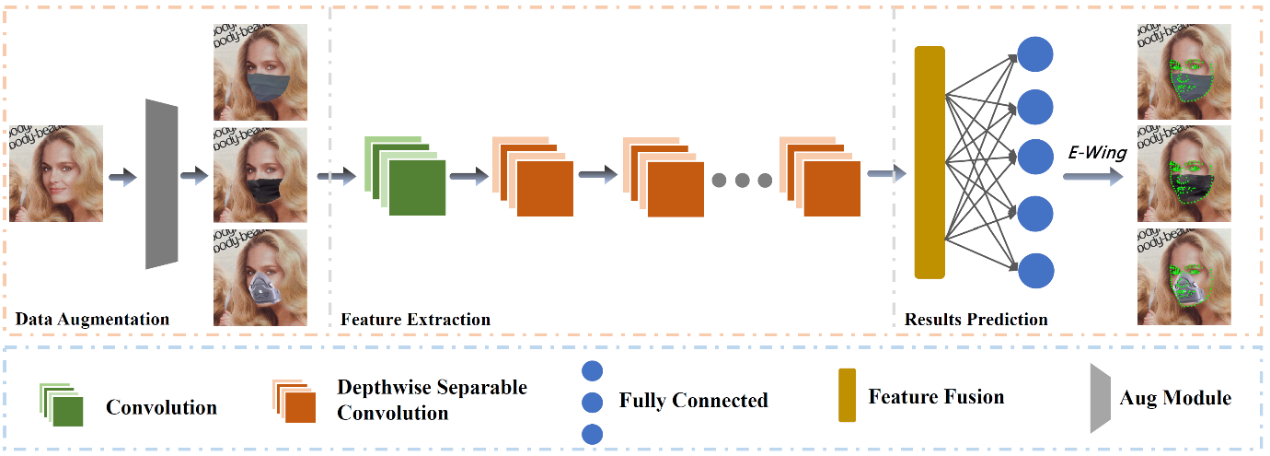
图 1 算法总体流程图
2.1 轻量化模型设计
设计合适的特征提取网络,一直是深度学习领域中的一项核心问题;针对不同的任务和应用场景,我们需要对模型的结构进行一系类调整。当模型部署到云端和大型服务器上时,我们更应该关注模型的预测精度,因此可以使用那些相对复杂的模型,如 ResNet、VGG、DenseNet 等。
然而,当算法需要部署到嵌入式设备(智能手机、机器人、摄像头等)时,我们更加关注模型的运行效率问题,因此需要在保证精度符合项目需求的情况下,尽量压缩模型参数量和计算量。
经过研究发现,常用的高精度人脸对齐模型都使用了十分复杂的特征提取网络如 HRNet 等,这些复杂的模型包含了大量的重复 block 和 channel,导致模型的体积和计算量非常庞大,无法在嵌入式设备中运行。但是口罩人脸对齐模型需要部署到小型的智能终端设备中,因此模型的参数量和计算量必须受被严格的控制。
受到 MobileNet 和 ShuffleNet 等轻量化模型的启发,我们认为在人脸对齐领域中也可以设计一种精度高、速度快、体积小的特征提取模型。深度可分离卷积是一种常用的降低模型参数量和计算量的卷积操作,在模型轻量化设计中被广泛使用。分组卷积起源于 AlexNet,用来将深度学习模型拆分,并使其可以在多个 GPUs 中训练;目前分组卷积主要用来降低模型的参数量。
因此,我们使用深度可分离卷积和分组卷积来构建一个适用于遮挡场景、高效的特征提取结构。在我们设计的模型中,将分组卷积的 Group 数设定为模型的 Channel 数。
此外我们还将 Receptive Field Block 模块引入到设计的特征提取结构中来增强模型的信息建模能力。模型结构如表 1 所示。
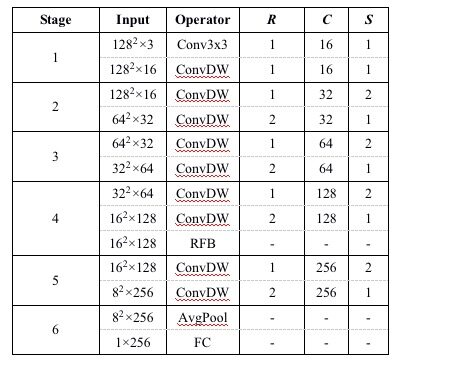
表 1 模型具体结构
2.2 增强型 WingLoss 函数(E-Wing)
Loss 函数的设计也是深度学习领域中的一项重要的研究课题。因此,设计一个恰当的 loss 函数可以极大的增强模型的性能。研究发现,基于深度学习的人脸对齐模型在训练时,基本都采用 L1 或 L2 Loss。
在口罩人脸对齐问题中,由于部分面部区域被遮挡,使得大量需要检测的面部关键点无法被准确的定位。在这种情况下,继续基于 L1 或 L2 Loss 进行训练,将会使模型更多的关注于那些被遮挡的区域,导致算法无法收敛。
受到 WingLoss 的启发,在遮挡人脸对齐领域中,我们需要使模型更加关注于那些未被遮挡的区域。WingLoss 虽然取得了较好的检测性能,但是在训练过程中有可能出现梯度为零的情况,影响模型稳定性和收敛速度。
为了解决上述的问题,我们提出了一种增强型的 WingLoss (E-Wing)。该方法在误差较小地位置扩大梯度,在误差较大地位置使用固定梯度。因此,可以迫使模型将更多地关注那些小误差点。E-Wing 定义如公式 1 所示。
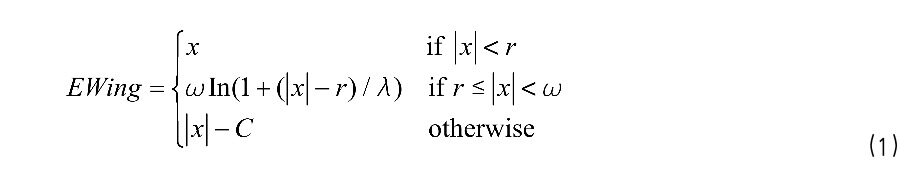
其中 r 是一个固定地常数,被用来限制算法地曲率,是一个常数,用来衔接 E-Wing 的线性和非线性部分。
2.3 数据增强模块
训练数据是深度学习任务中最重要的一部分,训练数据的数量和质量将对模型的性能产生决定性的影响。在口罩人脸对齐任务中,我们很难获取大量的标注数据;如果自行构建数据集则需要耗费大量的人力和财力。
为了解决这一问题,我们基于 3DMM 和生成对抗网络提出了一种数据增强模模块,该模块可以保证人脸相对位置不发生任何改变的情况下,生成大量带有口罩的图片。部分结果如图 2 所示。
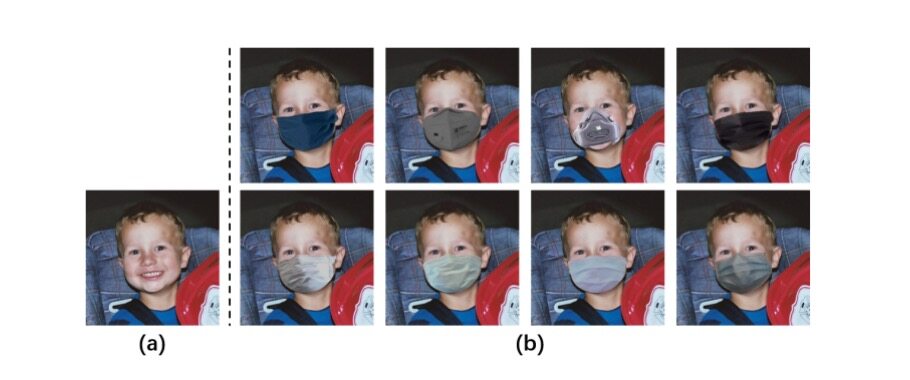
图 2 数据增强结果;(a)输入图片,(b)模块生成结果
在人脸对齐领域中,正面的人脸图片的数量远多于测量图像的数量。因此,这种数据不平衡问题有可能会导致模型对正面人脸严重过拟合。
为了缓解这一现象,我们使用了一种数据平衡策略;该策略首先计算出人脸朝向的一组欧拉角(patch、yaw、roll),然后根据角度的分布对那些数量较少的图片进行旋转、镜像等多种增广。
3. 实验
3.1 数据集
为了证明本位所提出方法的性能,我们在 FLL2021 数据集上进行了对比实验。FLL2021 是一个最近发布的口罩人脸对齐的数据集,该数据集共包含 24,386 张图片,每张图片中均表述了 106 个关键点;数据集覆盖了大姿态、夸张表情等多中不同场景。我们选择其中的 18,384 张图片作为训练集,2,038 张图像作为测试集。
3.2 测试指标
Normalized Mean Error (NME):NME 是一中在人脸对齐任务中广泛使用的评测指标,具体定义如公式 2 所示。
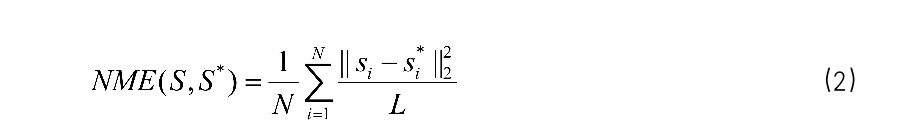
其中 N 是索取检测点的数量;L 是归一会距离,在该任务中我们使用图像的对角线长度作来对结果进行归一化。
Failure Rate (FR):FR 于 NME 类似,用来表征算法的性能,我们将 FR 的阈值设定为 0.08。
3.3 实验结果
将所提出的 MaskFAN 于常用的人脸对齐模型在 FLL2021 数据集上进行实验,并分析结果。由于不同方法的输入图像的分辨率不同,为了公平对比,我们展示了两组对比结果,表 2 中我们使用 256x256 的图像作为输入;表 3 中我们使用 128x128 的图像作为输入。
表 2 人脸对齐结果对比,使用 256x256 的图像作为输入
表 3 人脸对齐结果对比,使用 128x128 的图像作为输入
从结果中我们可以得出,本文所提出的算法在模型参数量非常小的情况下,取得了和现有算法相似的精度,证明了我们所设计模块的性能。部分可视化结果如图 3 所示。
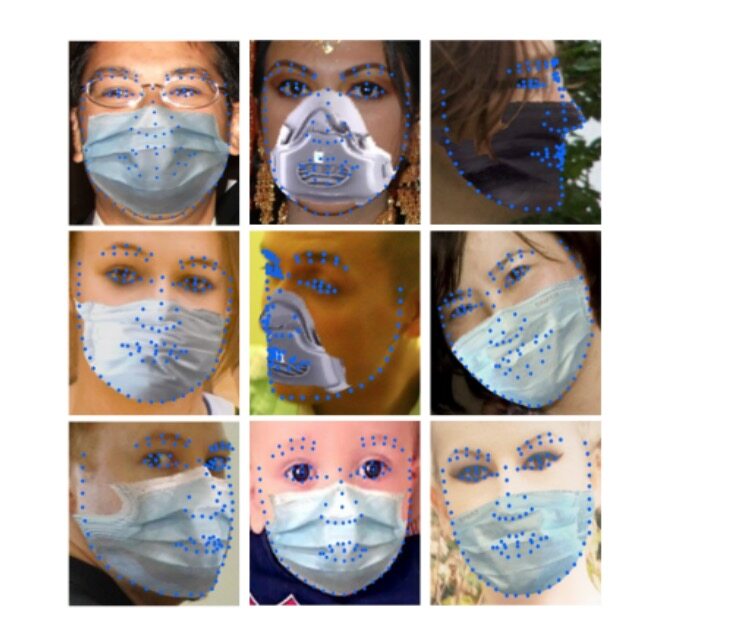
图 3 可视化结果展示
4. 结论
在本文中,我们系统性的研究了口罩人脸对齐领域中的一些核心问题,如模型轻量化设计、遮挡鲁棒性、Loss 函数优化等。为了解决口罩遮挡带来的挑战,我们提出了一种高性能的口罩人脸对齐模型 MaskFAN。
为了提升该模型的性能,我们在模型设计时引入了深度可分离卷积和分组卷积;此外还提出了 E-Wing 用来增强模型对遮挡的鲁棒性。实验结果显示,我们的方法在参数量极小的情况下,取得了优于现有方法的精度。
作者介绍
沙宇洋,中科院计算所工程师,北京邮电大学硕士,目前主要从事人脸识别以及无人驾驶等相关方向的研究和实际产品开发。




