综述
随着越来越多的组织的数据从 GB、TB 级迈向 PB 级,标志着整个社会的信息化水平正在迈入新的时代 – 大数据时代。对海量数据的处理、分析能力,日益成为组织在这个时代决胜未来的关键因素,而基于大数据的应用,也在潜移默化地渗透到社会的方方面面,影响到每一个人的日常生活,人们日常生活中看到的电视节目、浏览的网页、接收到的广告,都将是基于大数据分析之后提供的有针对性的内容。
微软在大数据领域的战略重点,在于更好地帮助客户“消费”大数据,让所有的用户都能够从几乎任何规模任何类型的任何数据当中获得可以转化为业务执行的洞察力。基于这一战略,微软发布了新一代并行数据仓库一体机 SQL Server Parallel Data Warehouse(简称 PDW),提供大规模并行处理并具备灵活线性横向扩展能力的数据仓库平台,其主要新特性主要体现在以下 3 个方面:
- 为大数据而建: 通过 Polybase 这一数据处理的突破性技术统一查询结构化、半结构划和非结构化数据,帮助用户使用最熟悉的标准 SQL 语言即可轻松实现 Hadoop 表和关系型数据库表的关联查询。同时,由于目前大部分常用的商业智能分析工具都无法直接查询 Hadoop, 而 Polybase 技术通过从数据库平台层面对 Hadoop 的集成,使用户可以采用熟悉的现有商业智能工具即可实现对大数据的灵活分析和展现。例如,用户可以利用熟悉的 Microsoft Excel 在同一表格中分析结构化和非结构化的数据。
- 新一代性能与规模:采用可更新的 xVelocity 聚集列存储技术,实现高至 50 倍的性能提升。基于大规模并行处理引擎技术,提供从几个 TB 到 PB 级数据的线性横向扩展能力。
- 最优化的软硬件价值:SQL Server 并行数据仓库一体机具备预装的硬件和软件,集成了目前微软最新一代的软件创新技术如 xVelocity 列存储、Polybase、Windows Server 2012 Hyper-V 虚拟化技术,Storage Spaces 存储技术等驱动精简高效的硬件架构,提供性价比优势。
本文将深入介绍 SQL Server 2012 Parallel Data Warehouse 的 Polybase 技术,并结合具体业务场景示例讲解 Polybase 技术如何为业务人员提供简单易用的大数据解决方案。
Polybase**** 技术
总体来讲,Polybase 技术包含以下具体功能:
- 用一个外部表来定义 Hadoop 中数据的结构。
- 通过运行 SQL 语句实现对 Hadoop 数据的查询。
- 通过 PDW 可关联查询 Hadoop 数据与关系型数据库 PDW 中的表,实现 Hadoop 与 PDW 数据的整合。
- 通过运行 SQL 命令来查询 Hadoop 并将结果集保存到 PDW 的表中,轻松实现将 Hadoop 数据导入到 PDW。
- Hadoop 也可以作为 PDW 的一个在线数据归档系统,通过运行简单 SQL 命令即可将 PDW 中的数据导出到 Hadoop,并随时通过 PDW 对归档在 Hadoop 中的数据进行在线查询。
下面我们通过一个示例来进一步说明上述 Polybase 技术的应用场景及使用方法,在这个示例当中我们将基于与美国 Sandy 飓风相关的一些数据,通过对这些数据的分析来协助决策派往美国各州救援资源的调配计划。
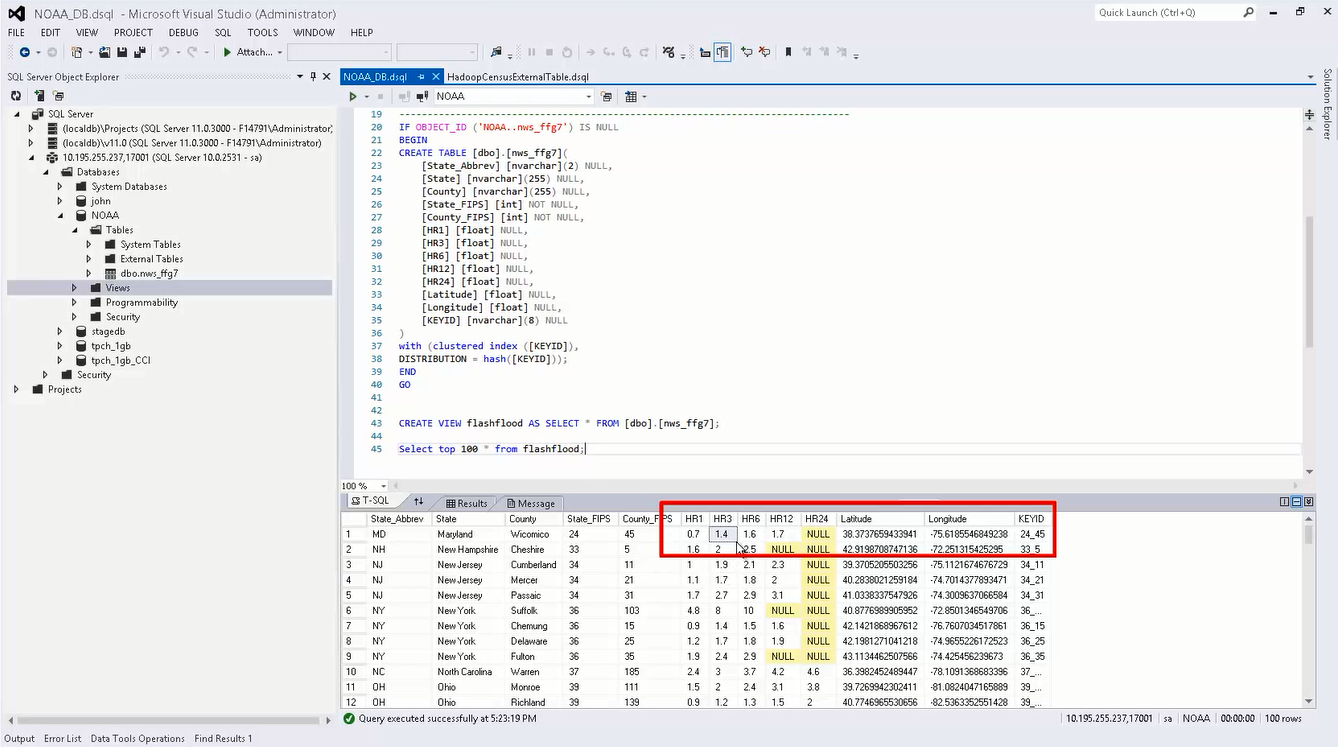
首先,在 PDW 关系型数据库中可以创建一张表 [dbo].[nws_ffg7],存储来自于美国海洋气象局 National Oceanic and Atmospheric Administration(简称 NOAA)的数据。与 SQL Server 2012 的体验相同,我们可以通过标准的 SQL Server Data Tools 工具来连接 PDW,如下图所示。基于 [dbo].[nws_ffg7] 表可以创建一个视图 CREATE VIEW flashflood AS SELECT * FROM [dbo].[nws_ffg7]。通过查询 flashflood 视图返回的结果集可以看到,这张表里面主要存储美国各个州的名称、地理属性信息如经度、纬度,以及各州在未来多个时间段的降雨量预测信息,如未来 1 小时(HR1 列)、3 小时(HR3 列)、6 小时(HR6 列)等等。
然后在 Hadoop 环境当中,我们将来自于另外一个数据源 – 美国人口调查局 US Census Bureau 的数据导入到 Hadoop 环境中,这个数据主要包括美国各州的具体人口分布信息。

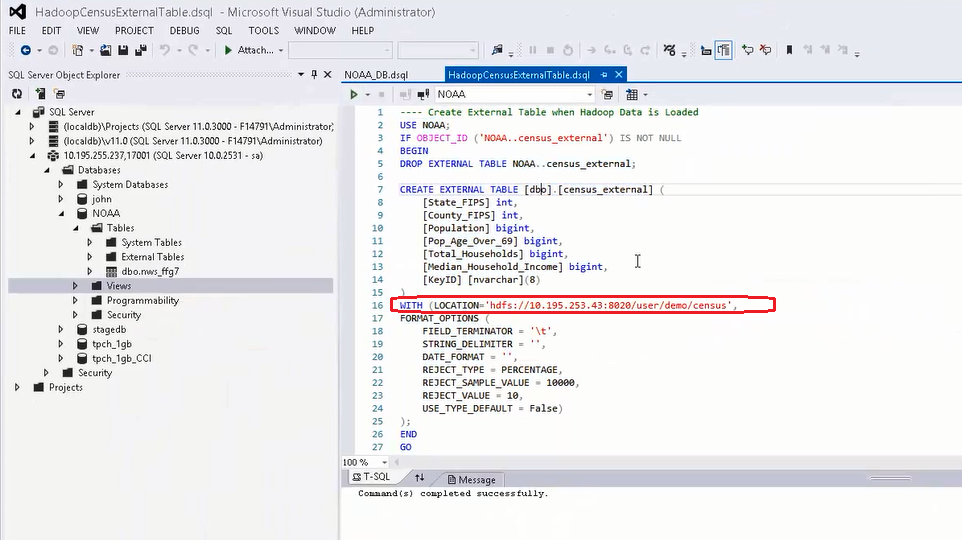
为了便于进一步深入分析各州的降雨量预测与人口分布情况的关联,我们需要将 Hadoop 中的数据与 PDW 的数据进行联合查询及分析。如下图所示,我们首先需要在 PDW 中创建一个外部表 External Table,将这个外部表的数据源地址指向 Hadoop 集群中存放人口分布数据文件的路径,并定义一些相关的元数据信息。外部表在 PDW 中只存储关于 Hadoop 中数据的一些元数据信息,并不会物理保存 Hadoop 的数据。
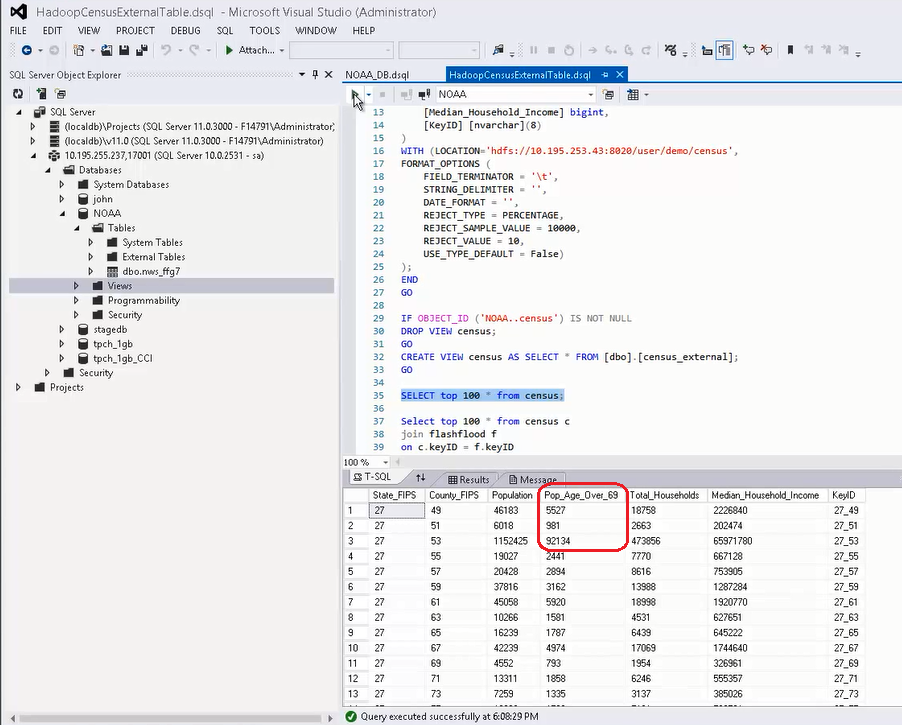
外部表创建完毕后,为了方便后续查询,我们可以基于这个外部表创建一个视图 Create View census AS SELECT * FROM [dbo].[census_external]。通过直接运行标准的 SELECT 语句即可查询 Hadoop 中的人口分布数据信息,如下图所示。我们从返回的结果集可以看到,Hadoop 中的数据包括美国各州的人口数量、家庭数量、以及超过 69 岁以上的人口(Pop_Age_Over_69 列)等信息,如下图红色圈出。
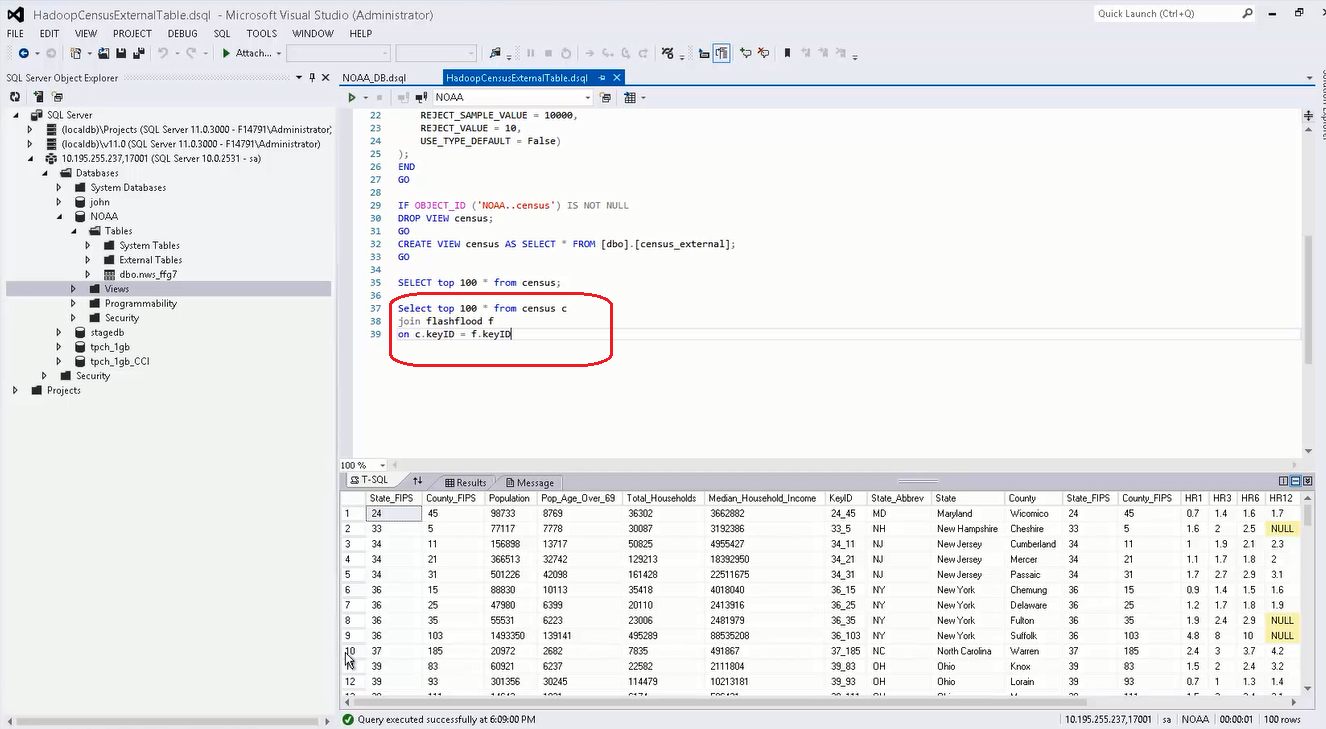
我们也可以运行标准的 SQL 语句将指向 Hadoop 数据的外部表与 PDW 本身存储的数据表做关联查询,如把 census 视图和 flashflood 视图用 keyID 键关联起来,查询的结果集由 PDW 引擎统一返回给客户端。
下面我们基于常用的 Microsoft Excel 作为商业智能分析客户端,利用 Excel 的 PowerPivot 和 PowerView 功能来进行一些数据分析和决策支持。首先可以打开 Excel 2013 的 PowerPivot 管理界面,选择从 SQL Server 数据源导入数据。
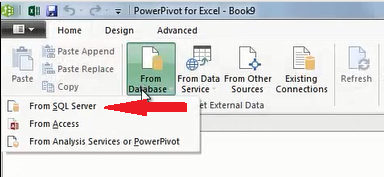
在弹出的窗口中填入 PDW 数据库的连接信息,选择导入刚才创建的两个视图的数据。
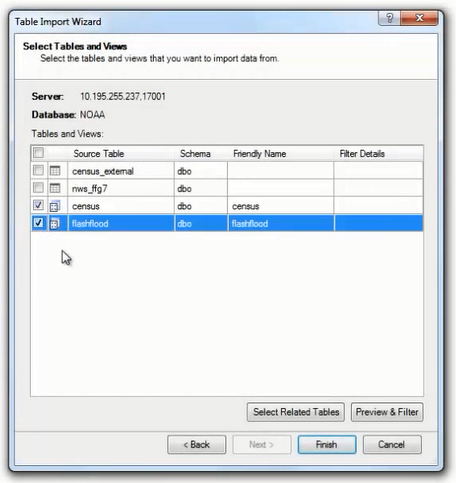
当数据分析业务人员在美国 Sandy 飓风来袭之前分析这些数据时,就可能需要基于美国各州的预测降雨量并结合人口分布情况,来计划派往各州的救援部队资源的调配。例如,人口年龄大于 69 岁以上分布较多的州就可能需要调配更多的救援来协助当地人口的撤离工作。
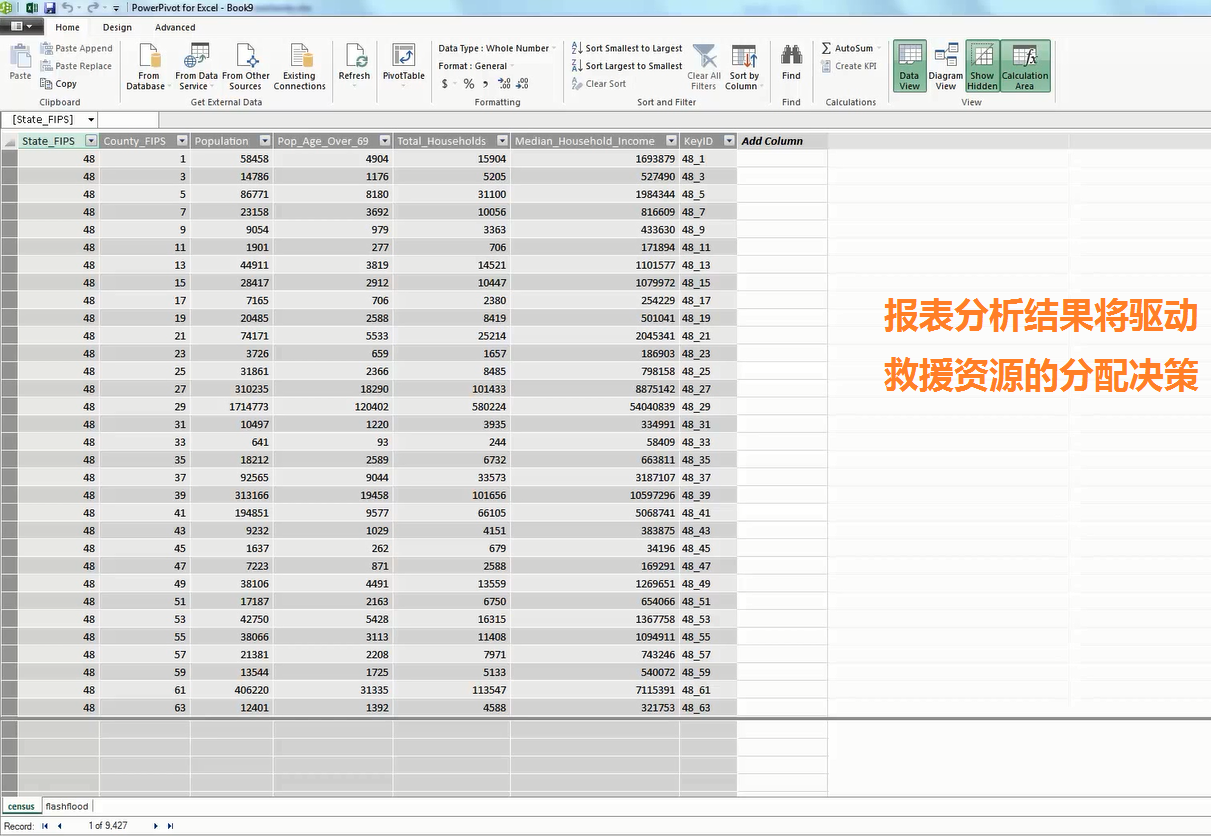
下图是一张业务人员通过 Excel 2013 的 PowerView 制作的报表,报表中集成了 Hadoop 中的人口分布数据与 PDW 中的各州降雨量预测数据,以图形化的方式清晰展现出 Sandy 飓风即将袭击范围内各州超过 69 岁的人口分布状况并结合未来 6 小时的降雨量预测。
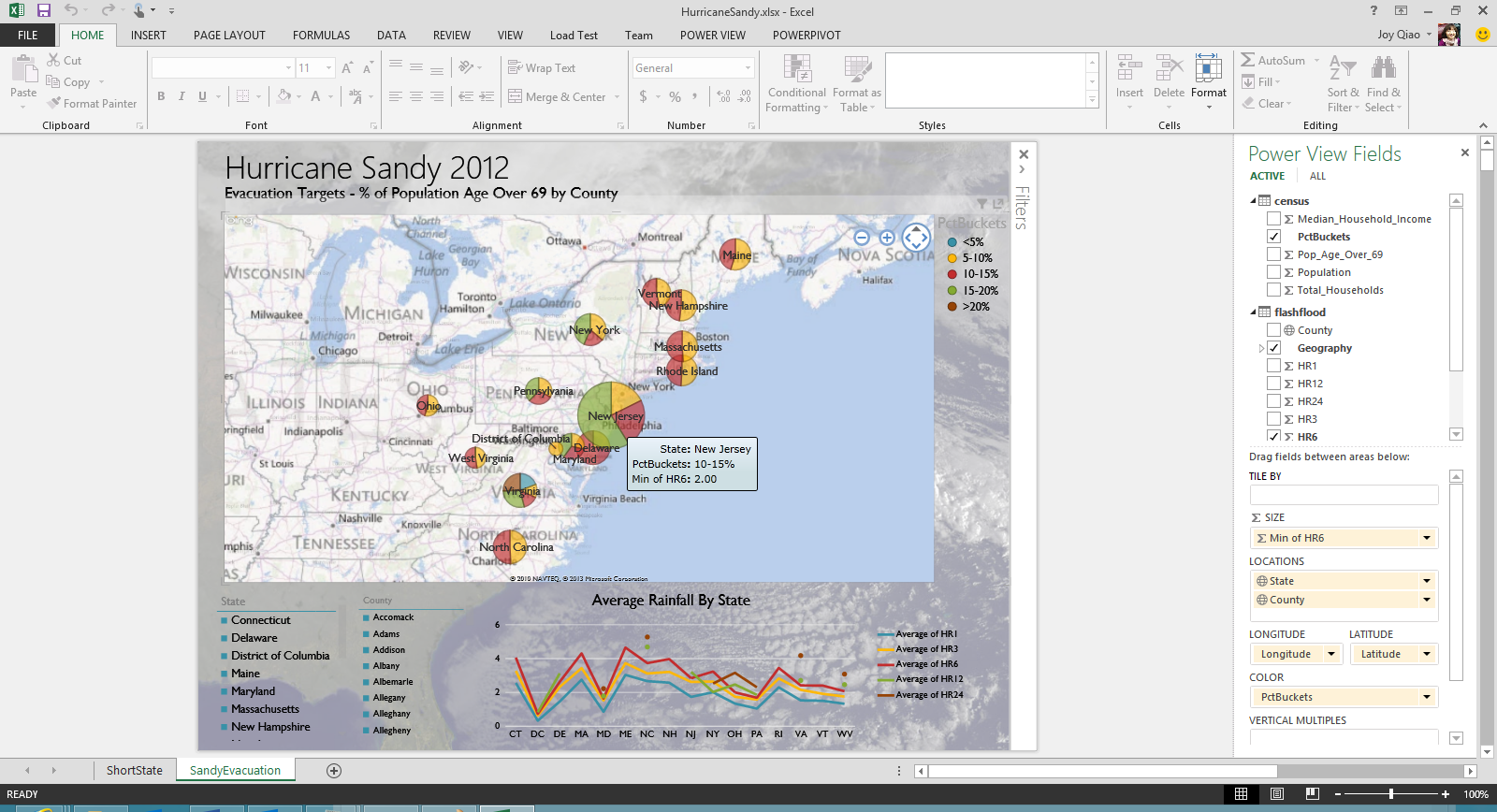
通过点击其中某个州,还可以进一步下钻分析各州内部的具体人口分布情况及降雨量。
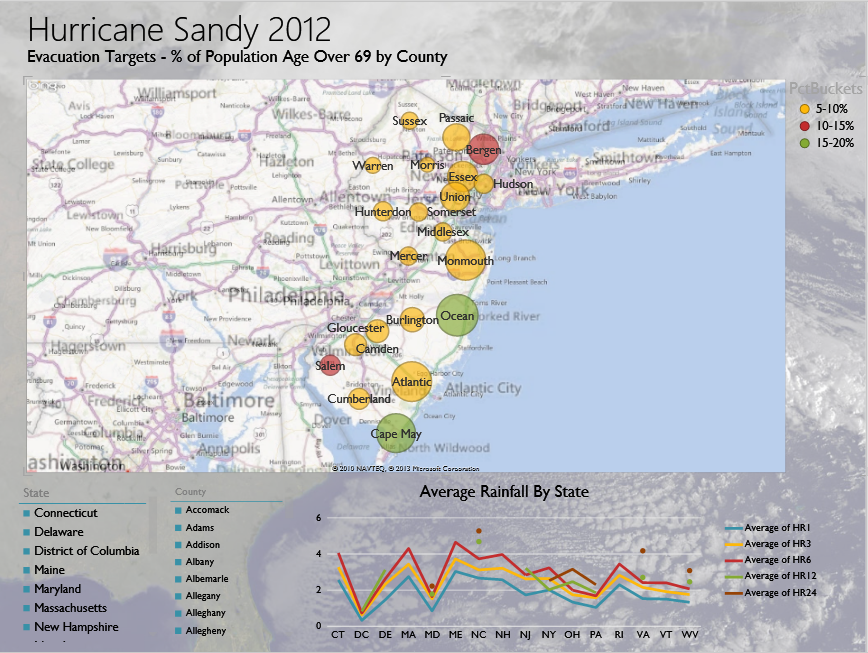
作为业务人员可以迅速通过以上报表直观化的数据分析来支持派往各州救援部队的资源分配计划。
总结
在大数据日益增长的时代,越来越多的企业也在逐渐部署基于 Hadoop 框架的分布式文件系统存储来自于各方面的数据。大数据解决方案不仅只是数据存储量到达 TB/PB 级别,如何能够方便快捷的消费这些数据、将这些数据综合在一起进行及时的分析、监控、挖掘,从而发挥这些数据的价值、支持未来的决策将是大数据解决方案成功与否的一个重要方面。
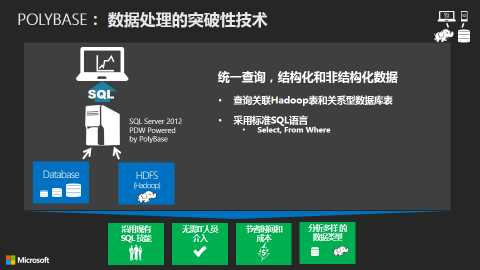
数据消费的用户大部分其实是业务人员,而并非 IT 技术人员, 能够使业务人员直接消费 Hadoop 当中的数据也就是 Polybase 技术的设计初衷。Parallel Data Warehouse 的 Polybase 技术作为关联 Hadoop 与传统关系型数据库的一个桥梁 (如下图所示),从底层平台层面使两边的数据能够互联互通,为业务人员提供了自助分析的便利,并且集成来自不同数据源包括 Hadoop 数据,业务或技术人员都无需学习编写复杂的 Map Reduce 脚本,只需要使用最熟悉的标准 SQL 语言或者是商业智能分析工具如 Excel, 即可实现对大数据的灵活分析和展现,方便快捷地响应业务需求并支持业务决策。
此外,Polybase 技术也大大提高了 IT 技术人员实现大数据解决方案的效率,降低工作量成本。在传统基于 Hadoop 的技术架构当中,IT 技术人员往往需要编写很多后台作业及脚本实现 Hadoop 与关系型数据库之间的数据导入导出,而且后台的作业还经常有可能随着前端业务需求的变化需要不断的更新,维护的人力成本也很高。Polybase 技术通过底层自动调用标准接口的方式,可以通过简单的 SQL 命令随时实现 Hadoop 与关系型数据库之间的数据导入导出,结合业界标准的前端商业智能分析及报表工具,可以帮助用户快速搭建并实现一套完整的端到端的自助式大数据解决方案。
微软并行数据仓库客户案例分享:国家审计总署
审计本质上是一个国家经济社会运行的“免疫系统”,财政资金运用到哪里,审计就跟进到哪里。……国家审计的“免疫功能”也需要持续进化和演变,走在信息化的前沿。在中国经济高速发展的过程中,随着生产自动化、电子商务的普及、网络财务软件的广泛使用、以及支付手段的多样化,审计对象越来越呈现出大数据的特征:海量规模、动态高速增长、多样复杂性。
现在的审计业务,面临的数据总量已经从以前的 MB-GB 级,上升为 TB 级,甚至 PB 级,并且数据查询分析的复杂性也不断在提高。同时,审计需求本身还具有随机性和突发性,审计人员需要根据判断进行海量数据的查询、汇总和关联分析,这就需要针对大数据的统一调度和并行访问,并需要多种计算模式和分析方法,同时满足宏观或特定审计目标。与此同时,更加无法忽视的是“时效性”的要求,审计署的处理效率受到更为严苛的挑战。
如何以更为容易部署的方式建立分布式存储和计算集群,在统一的架构下实现对各种类型和各种规模数据的管理和并行处理,并能够根据需求实现缩放和扩展?如何支持 TB/PB 级数据的高效加载,满足多源异构数据的即席查询、联合查询和复杂关联处理,对大规模审计数据进行快速、深入的分析和挖掘?
审计署选择了基于微软 SQL Server 并行数据仓库的大数据云平台方案,用于解决海量数据大规模并行分析处理、分布式存储及管理问题。
微软 PDW 平台在保持与审计署现有数据平台保持兼容的前提下,提供对数据进行全方位管理、高性能处理的能力。同时基于上述审计业务的随机性、突发性、分析多样性等特征,PDW 平台在数据存储和处理架构上面兼具了资源池共享、按需可扩展、高可用保障、统一运维监控等典型云计算平台特性。
注: 本文中所引用的 Polybase__ 示例来自于 Insight through Integration - A demonstration of integrating data from Hadoop and SQL Server Parallel Data Warehouse to visualize demographics for Hurricane Sandy, by Murshed Zama. Murshed Zaman__ 现任职微软 SQL__ 产品组 Customer Advisory Team__ 客户咨询部高级项目经理,专注于 SQL Server Parallel Data Warehouse, ColumnStore, Hadoop, Hive and IAAS__ 等技术。 12__ 年以上包含多个行业如电信、零售、网络问题、供应链管理等的数据仓库经验。
感谢马国耀对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。




