
整理 | 华卫
对于 ChatGPT 等聊天机器人提供支持的大型语言模型来说,最大问题之一是,永远不知道何时可以信任它们。它们可以针对任何问题生成清晰而有说服力的答案,并且提供的大部分信息都是准确而有用的,但它们也会产生幻觉。用不太礼貌的话来说,它们会胡编乱造,需要人类用户自己去发现错误。它们还会阿谀奉承,试图告诉用户他们想听的内容。
如今,OpenAI在这个问题的解决上迈出了最新的一小步:开发了一种上游工具,能够帮助训练模型的人类引导模型走向真实和准确。
6 月 27 日,OpenAI 宣布,其研究人员训练了一个用于捕捉 ChatGPT 代码输出错误的模型,名为 CriticGPT。CriticGPT 是一个基于 GPT-4 的模型,它撰写了对 ChatGPT 响应的评论,以帮助人类训练师在 RLHF 期间发现错误。
OpenAI 发现,当人们在 CriticGPT 的帮助下审阅 ChatGPT 代码时,他们在 60% 的情况下比没有 CriticGPT 帮助的人表现得更好。因此,目前 OpenAI 正在着手将类似 CriticGPT 的模型集成到其人类反馈强化学习 (RLHF) 标签管道中,为自己的人类训练师提供明确的人工智能帮助。
“这是朝着能够评估高级人工智能系统输出的目标,迈出的关键一步。如果没有更好的工具,人们很难对这些结果进行评分。”OpenAI 这样评价 CriticGPT。同时,OpenAI 发布了详细介绍 CriticGPT 背后技术的预印本论文。
CriticGPT 的纠错能力
据了解,为 ChatGPT 提供支持的 GPT-4 系列模型通过 "从人类反馈中强化学习"(RLHF)实现了帮助和互动。RLHF 的一个关键部分是收集比较信息,由被称为人工智能训练师的人员对不同的 ChatGPT 响应进行评分。
随着 OpenAI 在推理和模型行为方面的进步,ChatGPT 变得越来越精确,输出错误也变得更加微妙,可能会使人类训练师难以发现模型输出结果中的不准确之处,从而使为 RLHF 提供支持的比较任务变得更加困难。这是 RLHF 的一个基本局限,并且随着模型逐渐变得比任何可以提供反馈的人都更博学,可能会使模型之间的比对和调整变得越来越困难。
为了帮助应对这一挑战,OpenAI 对 CriticGPT 进行了训练,研究人员在有意插入错误的代码样本数据集上让其撰写批评意见,教它识别和标记各种编码错误。作为人类训练师的 AI 助手,CriticGPT 能够负责审查 ChatGPT AI 助手生成的编程代码,其基于 GPT-4 系列的 LLMS 分析代码并指出潜在的错误,使人类更容易发现可能被忽视的错误。
虽然 CriticGPT 的建议并不总是正确的,但 OpenAI 发现,与没有 AI 帮助相比,它们可以帮助人类训练师在模型编写的代码中发现更多的问题。

此外,当人类训练师使用 CriticGPT 时,人工智能会增强他们的技能,从而产生比单独工作时更全面的评论以及比模型单独工作时更少的幻觉错误。在 OpenAI 的实验中,第二位随机训练师在 60% 以上的时间里,都更喜欢来自人类+CriticGPT 团队的评论,而不是来自无辅助人员的点评。
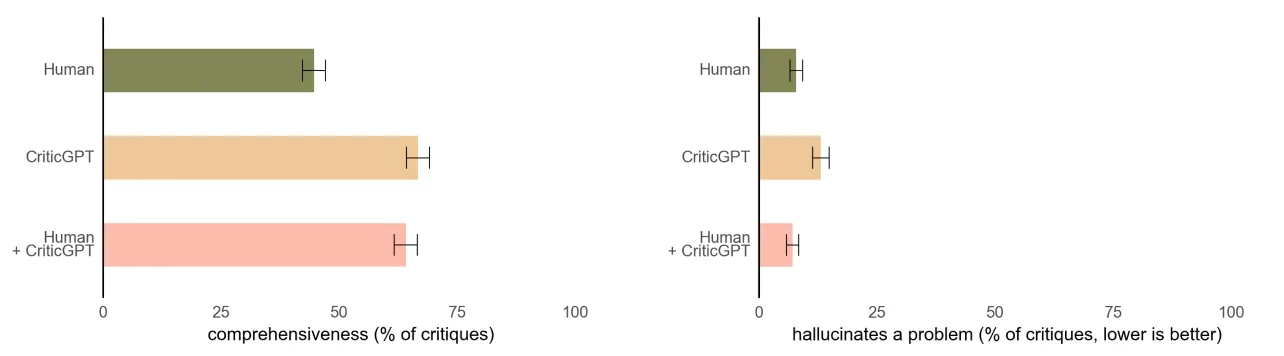
CriticGPT 帮助人类训练师写出比没有帮助更全面的评论,同时产生的幻觉比仅来自模型的批评更少。
有趣的是,OpenAI 还发现,CriticGPT 的功能不仅仅局限于代码审查。在研究人员的实验中,他们将该模型应用于 ChatGPT 训练数据的一个子集,这些数据以前被人类注释者评为完美无缺。令人惊讶的是,CriticGPT 在这些案例中发现了 24% 的错误——这些错误随后得到了人工审稿人的确认。
OpenAI 认为,这表明该模型具有推广到非代码任务的潜力和捕捉细微错误的能力,即使是仔细的人类评估也可能遗漏这些错误。
模型训练方法
与 ChatGPT 类似,CriticGPT 也使用 RLHF 进行训练。但与 ChatGPT 不同的是,CriticGPT 会看到大量包含错误的输入,然后对这些错误进行评论。
在 OpenAI 的实验中,他们研究了 CriticGPT 能否捕捉到插入的错误,以及之前的训练师捕捉到的 "自然发生的 "ChatGPT 错误。他们要求人类训练师在 ChatGPT 编写的代码中手动插入这些错误,然后写出反馈示例,就好像他们抓住了刚刚插入的错误一样。然后,同一个人对修改后的代码进行多次评论比较,这样他们就能很容易地分辨出评论何时抓住了他们插入的错误。
其发现,在 63% 的自然出现的错误案例中,训练师更喜欢 CriticGPT 批评而不是 ChatGPT 批评,部分原因是新批评者提出的“吹毛求疵”(无益的小抱怨)更少,产生幻觉问题的频率也更低。
此外,OpenAI 还发现,通过对批评奖励模型使用额外的测试时搜索,可以生成更长、更全面的批评。通过这种搜索过程,他们可以平衡在代码中查找问题的积极程度,并在幻觉和检测到的错误数量之间进行精确召回权衡。这意味着,他们可以生成对 RLHF 尽可能有帮助的评论。
在 CriticGPT 的开发中,OpenAI 研究人员还创造了一种新技术,他们称之为力采样光束搜索(FSBS)。这种方法可以帮助 CriticGPT 编写更详细的代码评论,让研究人员可以调整 CriticGPT 在寻找问题方面的彻底程度,同时还可以控制它编造并不真正存在的问题的频率。他们可以根据不同 AI 训练任务的需求来调整这种平衡。
局限性
尽管与所有 AI 模型一样,CriticGPT 取得了令人鼓舞的结果,但它也存在局限之处,包括以下几方面:
目前,OpenAI 用 ChatGPT 的简短答案来训练 CriticGPT。为了监督未来的代理,他们需要开发能帮助训练员理解冗长复杂任务的方法。
CriticGPT 模型仍然会产生幻觉,有时人类训练师在看到这些幻觉后会犯下标记错误。
有时真实世界中的错误会分散在输出答案的多个部分,而 CriticGPT 的工作重点是可以在一个地方指出错误,但将来也需要解决分散的错误。
CriticGPT 所能提供的帮助有限,如果一项任务或响应极其复杂,即使是有模型帮助的专家也可能无法正确评估。
关于 OpenAI 提到的使用 CriticGPT 来捕捉文本错误的方面,实际上也很棘手,因为文本中的错误并不总是像代码那样明显。更重要的是,RLHF 经常被用来确保模型在回答问题时不会出现有害偏见,并在有争议的问题上提供可接受的答案。对此,OpenAI 研究员 Nat McAleese 也表示,在这种情况下,CriticGPT 不太可能起到帮助作用, "这种方法不够有力"。
可以确定的是,为了调整日益复杂的人工智能系统,未来需要更好的纠错工具。由于在对 CriticGPT 的研究中,OpenAI 发现将 RLHF 应用于 GPT-4 有希望帮助人类为 GPT-4 生成更好的 RLHF 数据,他们正计划进一步扩大这项工作的规模,并将其付诸实践。
结语
一位与 OpenAI 无关的 AI 研究人员表示,CriticGPT 这项工作在概念上并不新鲜,但它在方法论上做出了有用的贡献。麻省理工学院博士生、2023 年一篇关于 RLHF 局限性的预印本论文的主要作者之一 Stephen Casper 表示:“RLHF 的一些主要挑战源于人类认知速度、注意力和对细节的关注的限制。“从这个角度来看,使用 LLM 辅助的人工注释器是改善反馈过程的自然方法,是朝着更有效地训练对齐模型迈出的重要一步。
但 Casper 也指出,将人类和人工智能系统的努力结合起来“可能会产生全新的问题”。例如,“这种方法增加了人类敷衍参与的风险,并可能允许在反馈过程中注入微妙的人工智能偏见。
2023 年 7 月,OpenAI 曾宣布将其 20% 的计算资源用于对齐研究。但目前 OpenAI 已经解散了其对齐团队,并将剩余的团队成员分配给其他研究小组。此次 OpenAI 发布的研究成果表明,至少他们仍在开展可信和开创性的对齐研究。
参考链接:
https://openai.com/index/finding-gpt4s-mistakes-with-gpt-4/
https://spectrum.ieee.org/openai-rlhf




