
之前,我写过一篇博文,用 Go 语言重写可汗学院有 10 年历史的单体 Python 2 后端系统。这篇博文带来的一些反馈是这样的“突然大规模重写会带来巨大的风险”。当然,我非常同意。本文,我要说的是我们的做法基本上和突然大规模重写相反。
联盟的 GraphQL
我们新架构的中心是基于GraphQL联盟的。基于 REST 的服务已经有了“API网关”很多年了。当你的系统是基于 GraphQL 时,联盟提供了相同的功能。这两者之间很大的区别是:
GraphQL 为后端系统能提供的所有数据提供了一个单一的类型化的模板。
REST API 网关通常知道如何将一个请求定向到单个后端服务。 GraphQL 网关生成一个查询计划,来构建一个包含来自多个后端服务的数据的响应。
从较高的层次来看,我们的系统是这样的:
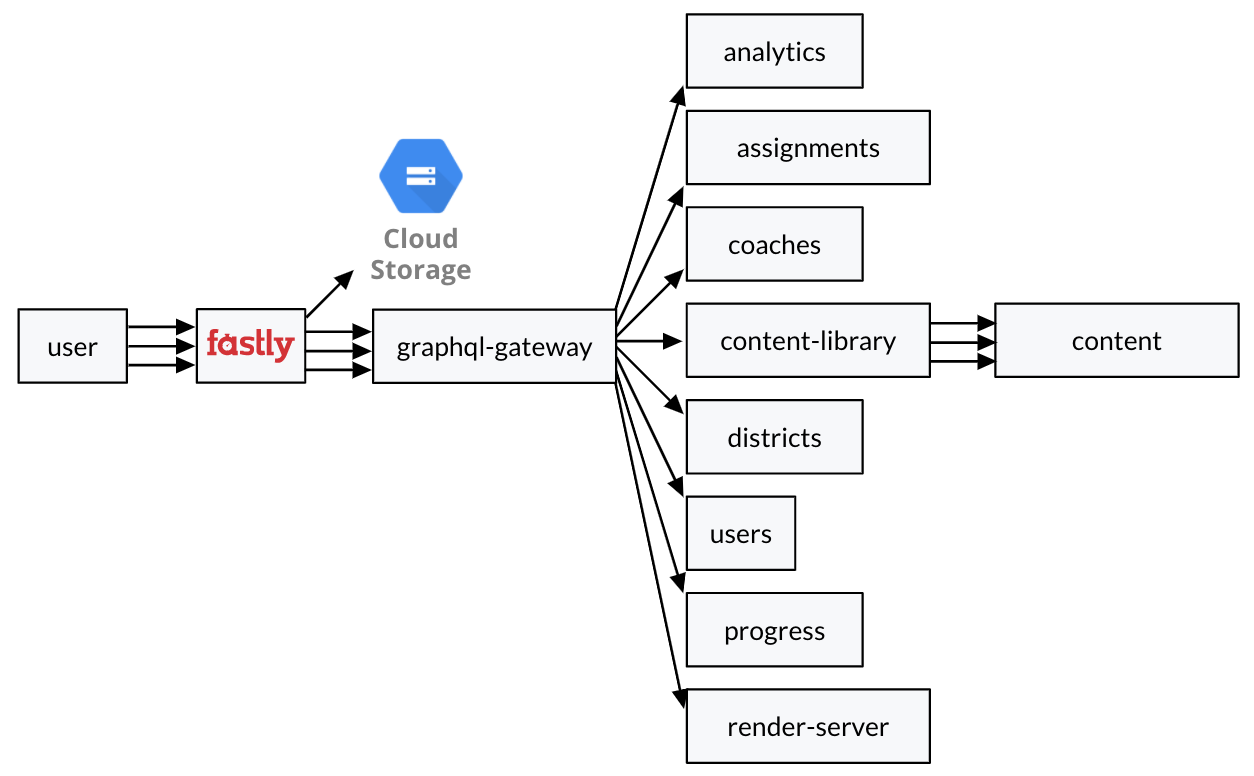
graphql-gateway 服务负责创建查询计划并向我们的其它服务(包括我们的单体应用)发出 GraphQL 请求。我们的 Go 服务有自己的 GraphQL 模板,因此我们使用gqlgen来响应请求。
我将重点介绍我们是如何定制Apollo GraphQL服务器,来使我们能够安全地从 Python2 单体应用迁移到这些新服务。
通过 GraphQL 联盟,每个服务提供了整个 GraphQL 模板的一部分,网关将所有这些单独的模板合并为一个。我们的单体应用像这个配置中的其它服务一样工作。
并行测试
GraphQL 基于各种类型。知道如何查询某一个字段的值的代码称为解析器。下面是一个简单的例子,我们将用它来讨论我们的方案:
type Assignment { createdDate: Time}在 Assignments 中涉及更多其它字段,但是我们的方案对所有字段都是相同的。
假设我们想要将这个字段从单体应用转移到我们的新 Go 服务中。我们如何能够确信新服务会返回与单体应用相同的数据?我们使用了一个类似 GitHub 的Scientist的库的方案:同时查询单体应用和新服务,比较两者结果,但是只返回其中之一。
步骤 1:控制单体应用
当一个用户请求 createdDate 字段,graphql-gateway 会向 Python 单体应用发起一个请求。
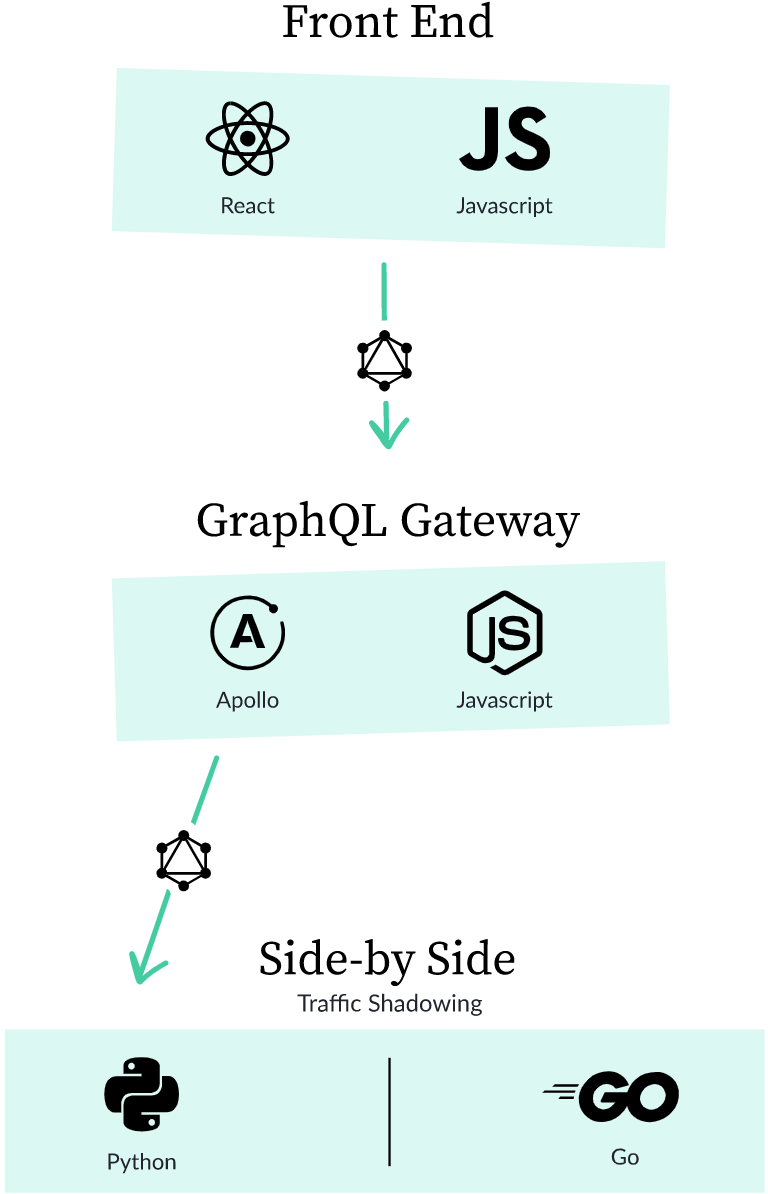
我们的第一步是进行配置,以便可以在 Go 编写的 assignments 服务中添加这个字段。这个 assignments 服务会有一个类似.graphql文件的东西:
extend type Assignment @key(fields: "id") { id: ID! @external createdDate: Time @migrate(from: "python", state: "manual")}这是使用联盟来表示,这个服务正在将 createdDate 字段添加到 Assignment 类型,而且可以使用 id 查找该字段。我们添加的秘方是 @migrate 指令。我们已经编写了能够理解这些指令的代码来构建多个模板,graphql-gateway 在决定如何路由一个查询时会使用这些模板。
在“手动”状态下,查询只会转到 Python 代码。我们在编写一个新服务时使用这个状态。我们的工程师仍然可以直接查询服务来获取 createdDate 字段,或者可以向 graphql-gateway 请求“手动”模板,但是对于该模板是否真的能正常工作是不确定的。
步骤 2:并行状态
一旦我们为 createdDate 字段构建了解析器代码,我们将这个字段切换到 side-by-side 状态。
extend type Assignment @key(fields: "id") { id: ID! @external createdDate: Time @migrate(from: "python", state: "side-by-side")}在这种状态下,graphql-gateway 将同时调用 Python 代码和新的 Go 代码。它将比较两者的结果,记录存在差异的实例,并将 Python 结果返回给用户。
这种模式实际上是建立信任迁移将正常工作的关键。我们有数百万用户和多年的数据。通过了解这些代码的实际运行效果,我们可以验证即使是奇怪的边缘情况也能得到一致且正确的处理。
下面是一份示例报告,展示了并行差异的统计数量:

我们确实会遇到这样的情况:非确定性排序的 Python 集合产生的结果与 Go 代码不同。随着时间的推移,我们学会了发现这些用户不可见类型的问题。
当在开发服务器工作时,我们还有一些工具,提供了颜色高亮的差异,让任何变化都易于发现和理解。
突变怎么处理?
你可能发现了一个难题:如果我们在 Python 和 Go 中运行相同的代码,那么更改数据而不仅仅是查询数据会怎么样?在 GraphQL 术语中,这些被称为突变。
我们的并行测试不包含突变。我们曾考虑过一些方案来实现这一点,但它们太复杂了,我们认为不值得那么做。但我们确实想到一个方案来帮助解决这个难题。
步骤 2.5:Canary
如果我们有一个字段或突变,我们认为已经准备就绪,但我们仍然想要做一些产品测试并验证结果,我们对此有一个“canary”模式。
extend type Assignment @key(fields: "id") { id: ID! @external createdDate: Time @migrate(from: "python", state: "canary")}“canary”状态下的字段和突变会以运行时可配置的用户百分比发送到 Go 服务。另外,可汗学院的内部用户将得到 canary 模式。这为我们提供了一种相当低风险的方法来测试更加复杂的变化,因为如果某些部分工作不正常,我们可以快速关闭 canary 模式。
为提高效率,只有一个 canary 模式。实际上,任何时候都不会有太多字段或突变处于 canary 状态,因此这应该不是个问题。这是一个很好的折中方案,因为这个模板非常大(超过 5000 个字段),而且网关实例需要将 primary、manual、canary 状态的模板保存在内存中。
步骤 3:已迁移
下一步是将 createdDate 字段改变成“migrated”状态:
extend type Assignment @key(fields: "id") { id: ID! @external createdDate: Time @migrate(from: "python", state: "migrated")}在这种状态下,网关只会将流量发送到 Go 服务。Python 代码仍然存在,准备好响应。这使得分阶段进行我们的部署并在出问题时进行回滚更容易。
步骤 4:移除 Python 代码
最后,我们完成了 Python 代码的迁移,可以完全删除 @migrate 指令:
extend type Assignment @key(fields: "id") { id: ID! @external createdDate: Time}在这时,Assignment.createdDate 字段只有网关知道来自 assignments Go 服务。
进展如何?
今年,我们建立了并行测试基础设施,它允许我们安全地一步步地迁移大量代码到 Go。过去一年中,流量显著增长且通过对后端、web 前端和移动端应用程序进行大量改动,我们保持了高可用性。截至本文撰写时,大约 40%的我们的 GraphQL 字段现在由 Go 服务提供,因此这项技术在这次迁移中得到了验证。
即使在 Goliath 项目完成之后,我们仍然可以继续使用这项技术来保护我们的前端,使其免受随着时间的推移而对后端服务进行的不可避免的改动的影响。
原文链接:
https://blog.khanacademy.org/incremental-rewrites-with-graphql/




