
Chatbot Arena 等排行榜已经反复证明,数十亿美元支撑起来的 ChatGPT 仍然是聊天机器人领域无可争辩的王者。而人们只能调用其 API ,无法私有化部署,无法自己训练调整。因此,大家现在热衷于用开源大模型来构建 AI 聊天机器人,希望能在性能层面达到甚至超越 ChatGPT 等专有模型的水平。
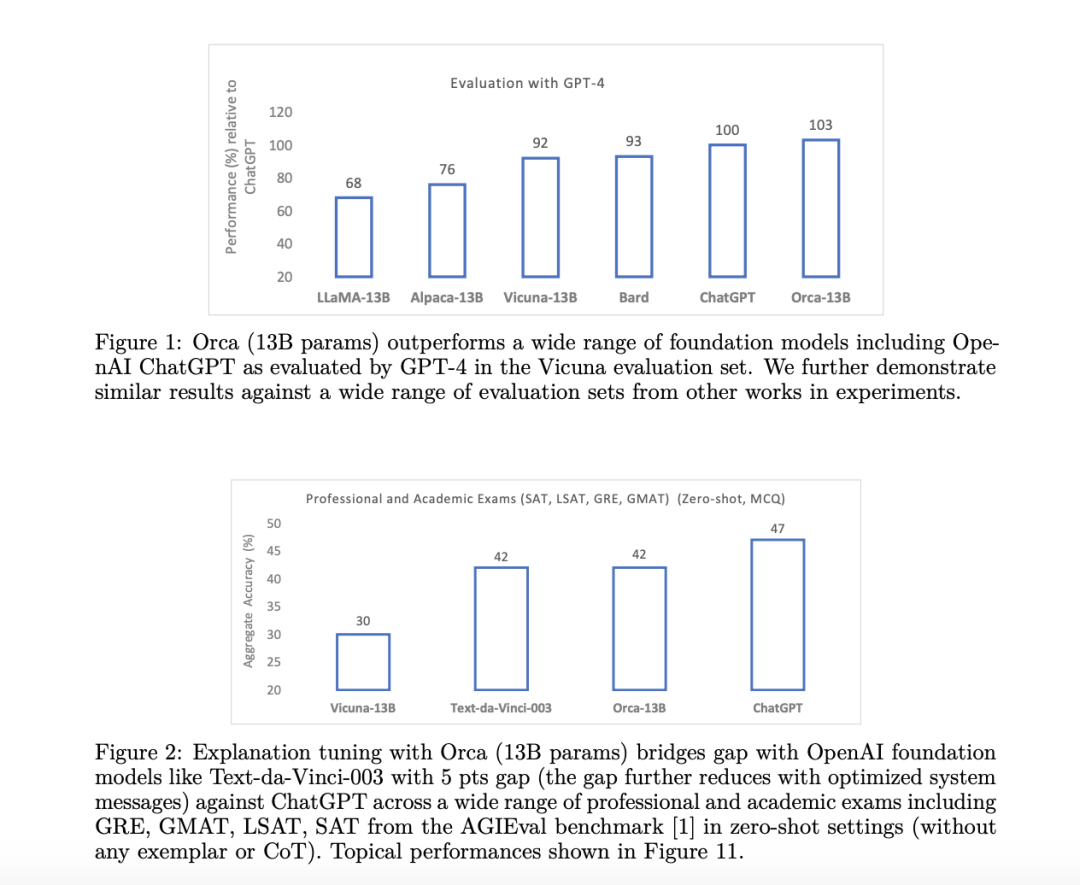
近期,微软出人意料地发布了一个只有 13 亿参数但具有大模型推理能力的开源小模型 Orca,它使用创新的训练方法,成为首位敢于同专有模型叫板的挑战者。而且,Orca 的规模仅是其竞争对手的几十分之一(甚至可能只相当于 GPT-4 的几百分之一)。令人难以置信的是,Orca 在某些场景下甚至表现更好,而且完全碾压迄今为止所谓最强开源模型 Vicuna。
论文地址:https://arxiv.org/pdf/2306.02707.pdf
那么,Orca 究竟是怎么做到的?
新的训练方式:巧劲胜于蛮力
在说起 AI 模型训练时,资金投入基本已经成为首要前提。具体来讲,谈到模型中的几十亿参数,这背后的涵义包括:
光是收集训练数据就要花上几百万美元;
基础模型的训练还要再花上几百万美元;
模型的微调也可能花费几十万美元;
更不要说人类反馈强化学习(RLHF)。如果公司单季度收入达不到数十亿美元的量级,这个环节最好碰都别碰。
所以说起“大语言模型”的竞逐,其实全世界有资格参与进来的也不过四、五家公司。
因此,为了在性能层面跟 ChatGPT 等大体量专有模型相对抗,研究人员别无选择,只能选择以巧劲破解对方的财力。而在生成式 AI 领域,所谓的“巧劲”正是“蒸馏”(distillation)。
简单来说,蒸馏就是选位优秀的同志,再把它的响应能力作为小模型的学习素材。为什么要这么干?非常简单:ChatGPT 虽然拥有数十亿个参数,但只有“少数”参数真正重要。从原理层面来讲:
我们必须先让模型拥有足够多的参数,才能保证其掌握现实世界中的种种复杂表征。
这样做的结果就是,大部分模型中的大部分参数始终处于未使用状态。
研究人员意识到这个现实问题后,得出了以下结论:假设 GPT-4 这样的先进模型未来仍须以体量增长作为必要条件,那在拥有了训练得到的大模型之后,能不能再用一个比其小得多的模型简单重现大模型的部分或者全部特性?
换句话说,在引导 AI 模型学习现实情境时,能不能先用大语言模型完成其中最繁重的“模式提取”任务,再让它们作为“老师”指导那些体量较小的模型?
答案是可以。蒸馏的过程就是这样一种 AI 学习方法,以大体量模型为模板训练小体量模型。所以开源社区的最佳 AI 聊天机器人开发流程基本可以概括为:
对大语言模型(教师)进行采样,以构建{用户指令,输出}的查询数据集。这里常见的选项当然是 ChatGPT。
接下来,选择一个较小的模型(参数量大约在 5 亿到 150 亿之间)作为“学生”。
学生的任务就是尽量减少自身输出与教师输出间的差异,学习它、模仿它。
这样,小体量模型就能够掌握教师的风格并输出类似结果,并把训练和运行成本控制在更低的水平。
这样新的先进模型就此诞生,且成本仅为大模型的百分之一。听起来不错,但现实世界显然没那么美好。
虽然这些模型能够有效学习教师的风格和语言连续性(例如 Vicuna 或 Alpaca),但却往往无法掌握对方的强大推理能力。也就是说,在对复杂任务做出评估时,其表现会远逊于自己的老师。没错,是“远远”逊于。
Orca 碾压开源模型,赶超 ChatGPT
现在,大多数开源模型的性能其实被故意夸大了。Vicuna、Alpaca 等开源模型的出色性能,可能是研究人员精心挑选的结果。直到现在,它们在推理基准测试上的表现仍一言难尽。
例如,虽然 Vicuna 在衡量复杂任务的基准测试中,已经能在风格和语言连续性方面达到 GPT-4 的 89% 左右,可一旦面对七步逻辑推演等挑战,双方的差距就会扩大到令人尴尬的 5400%。换句话说,这时 GPT-4 的性能达到 Vicuna 的 55 倍。
Orca 的研究人员意识到了这个问题,并努力做出了改进。在 Big-Bench Hard 上使用零样本提示的性能测试中,括号内的 2900% 代表 Orca 相对 Vicuna 的改进程度。
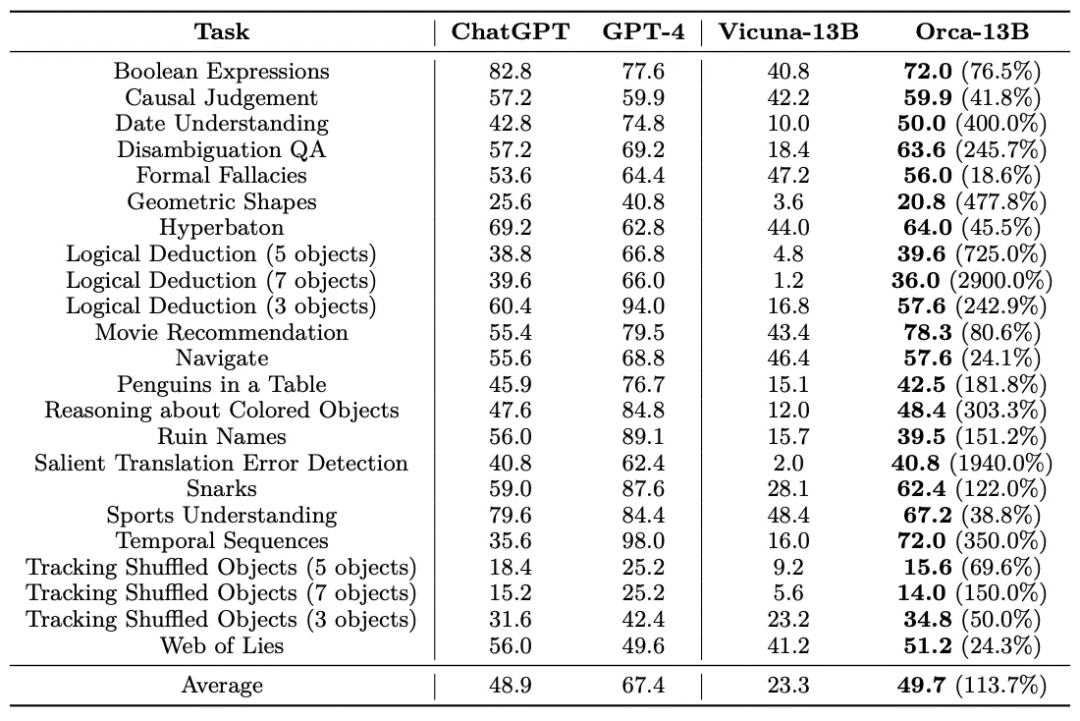
Orca 在所有任务上的综合表现略好于 ChatGPT,但明显落后于 GPT-4,比 Vicuna 高出 113%。与 AGIEval 的结果类似,Vicuna 在此基准测试的复杂推理任务上表现不佳。Orca 虽然明显优于 Vicuna 且略优于 ChatGPT,但平均性能为 49.7%,落后于 GPT-4 26%。
测试中,Orca 在时间序列(时间推理)、导航(遵循导航指令)、彩色物品(识别给定上下文的对象颜色)方面分别优于 ChatGPT 102%、3.6% 和 1.7%。Orca 在因果判断任务上表现出色,性能与 GPT-4 相当,同时超过 ChatGPT 4.7%。在检测翻译错误上,Orca 和 ChatGPT 水平差不多。Orca 在需要各种知识的任务(例如体育、艺术家、幽默等)方面表现不如 ChatGPT,但在电影推荐方面表现更好。
在 Web of Lies 测试中,Orca 甚至把 GPT-4 也斩落马下,性能比这套体量百倍于自身的明星模型还高出 3%。Vicuna 自然也不在话下,但 Orca 的得分比其高出 24.3%。

来源:Microsoft (Web of lies example)
令人印象深刻的是,在以上所有任务中,Orca 的平均性能已经超越 GPT-3.5。这不仅是开源模型的一个新里程碑,同时也稳定将性能保持在 Vicuna 的两倍以上。
虽然在大多数情况下,Orca 仍落后于无可争议的王者 GPT-4,但这种以小搏大、碾压其他开源同侪并偶尔超越老大哥的表现,究竟是怎么实现的?
Orca 研究人员做了什么
当前小模型通过指令微调来模仿大模型的方式主要存在以下问题:
指令简单且缺乏多样性。
收集的数据规模小,任务缺乏多样性。
模仿信号有限,只能通过老师模型生成的
进行模仿学习。 评估标准较弱。用大模型对小模型进行指令调优后的结果一般依靠 GPT-4 进行自动评估,例如使用 GPT-4 响应的结果进行指令调优后的模型倾向于生成更长的文本,同时 GPT-4 在候选响应的顺序上有偏差。
Orca 的研究人员主要采取了以下两项重要创新举措:
解释性训练
在 Orca 之前,Vicuna 和 Alpaca 等模型只能从 GPT-4 等模型中采样简单的{用户指令,回答}查询来进行蒸馏,借此训练新模型模仿自己的老师:
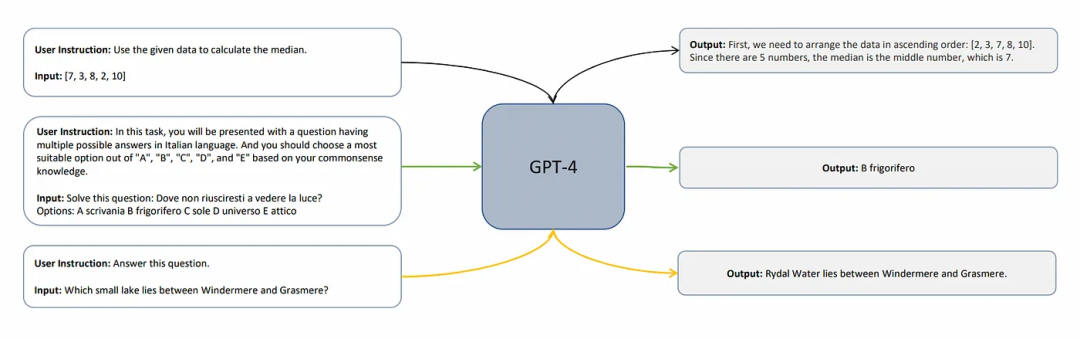
但在 Orca 这边,研发思路发生了巨大转变。
研究人员没有像之前那样简单提取查询,而是引入了第三项约束条件,即系统指令。也就是说,除了用户指令和模型答案之外,微软研究人员又额外添加了一系列指令,旨在对学生模型的行为和思考过程进行建模,如下图所示:
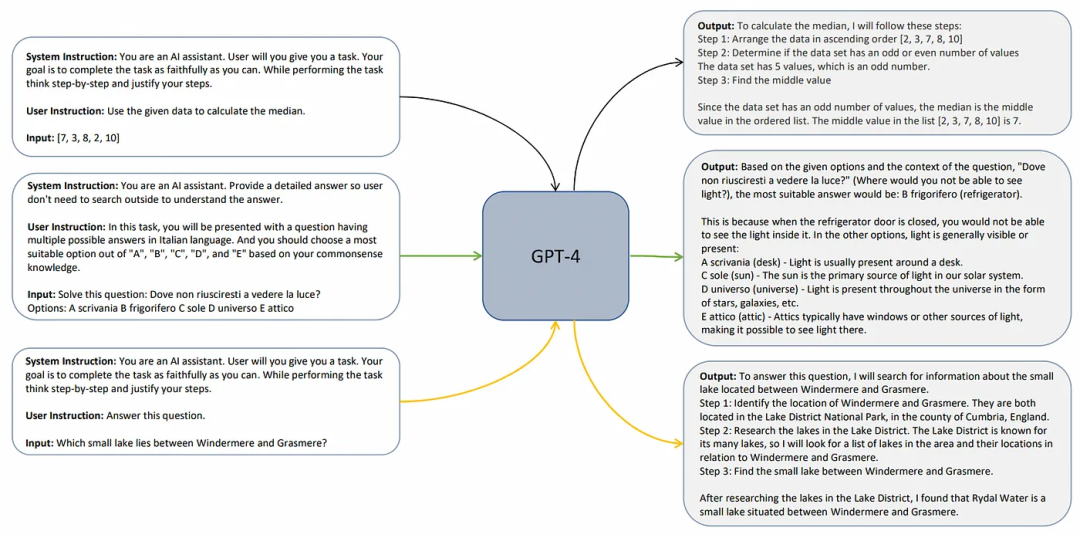
这并不难理解:学生不仅需要模仿 GPT-4 的输出质量,还需要模仿老师的思维过程,从而掌握类似的推理能力。
通过中间教学实现渐进式学习
截至目前,大多数开源模型只使用一对{学生,教师}素材。但在 Orca 却有两个老师。首先自然是 ChatGPT。作为第一位老师,它负责指导学生模型解决那些不太复杂的查询。之后再经由 GPT-4 提供更复杂的查询指引,让学生根据之前掌握的知识做进一步学习。
这个过程跟人类的学习方式非常相似。我们在学习乘除法之前,先得掌握加减法的诀窍,循序渐进突破一道道难关。而且与单纯使用 GPT-4 的训练方法比较,渐进式学习的效果确实更胜一筹。
结束语
目前越来越大、耗能越来越高的发展模式是否将很快走向终点,还有待验证,但如今每周几乎都会出现突破现有游戏规则和技术边界的新成果,大家都在效率方面做了很多努力。
从 Orca 凭借一点小技巧就能碾压众多开源模型来看,我们对于 AI 技术只能说还知之甚少。而作为已经凭借 ChatGPT 在市场上占据绝对优势的王者,微软率先出手,再将开源模型升级到新的维度。开源模型或将开启属于自己的新时代。
参考链接:
https://medium.com/@ignacio.de.gregorio.noblejas/orca-microsoft-7c78ca03c803




