
简介
近年来游戏产业迅猛发展,光是 2020 年第一季度,中国游戏市场的销售收入就突破了 700 亿元,而游戏做为承接互联网公司流量并进行商业化变现最有效的渠道之一,各大互联网公司也都在积极布局。AI 作为在多个行业被证实可以提高生产力的技术,在游戏领域的应用空间也是巨大的。AI 与游戏的结合其实早就已经出现了,从深蓝到 AlphaGo,AI 迅速在各个游戏里超越人类。
当大家对 AI 和游戏关系的普遍认知还停留在“与玩家对抗”的时候,我们已经注意到其实 AI 可以给游戏的研发,推广,运营等多个环节进行赋能,本文主要介绍快手将 AI 技术应用于游戏业务各个环节的探索和落地情况。这些工作由快手 AI 平台部,游戏技术中台和快游工作室合作完成。
AI 辅助研发
在推关类游戏中,关卡数量随着游戏运营时间递增,一个成熟的推关类游戏,比如消消乐,关卡数量成千上万。而合理的设置关卡难度是提升用户心流体验的关键要素。好的关卡设计可以有效根据用户当前水平调动用户游戏兴趣,而难度不稳定的关卡设计会对用户的游戏体验造成极大的干扰。
在以上背景下,根据业务和场景的诉求产出合适难度的关卡就变得非常必要了。在传统的推关类游戏开发中,测试关卡难度往往是通过测试人员做大量重复的测试。这种传统的方式有两个主要缺陷:一是需要消耗大量人力和工时;二是这种测试往往带有测试人员的个体误差导致关卡的难度估计存在系统性偏差。
为了系统性的解决这两个问题,我们用 AI 能力在游戏关卡方面做出了一些尝试。由于游戏机制问题,这里有两种业务诉求,其一为通过 AI 来评估给定关卡的难度,其二为自动生成指定难度的关卡。快手在以上两种场景下均有对应解决方案,并已经成功落地到点消和斗地主等游戏中。
智能关卡难度测试
点消游戏特点是 action 比较单一,游戏关卡盘面由最多 9*9 个格子组成,action 只有点击。但是其状态空间非常巨大,每个格子上附带的大量属性:元素种类(方块、阻碍元素、道具、暂时空格、永久空格、是否有传送门)和元素属性(颜色、层数、状态、朝向等)。

我们设计了基于强化学习(利用 CNN+A2C)和蒙特卡洛树搜索(MCTS)的算法来解决这个问题。其中一个难点是并行 MCTS 算法。因为有多个 worker 在同时执行选择(selection)->扩展(expansion)->仿真(simulation)->反向传播过程(backpropagation),某一个 worker 在进行选择的时候,其他 worker 未结束的仿真结果是无法获取的,这导致大量 worker 只能看到过时且类似的信息,严重影响了搜索树选择节点的好坏,破坏了串行状态下的探索 - 利用平衡(exploration-exploitation balance)。
为解决这一问题,我们提出了 WU-UCT 算法(Watch the Unobserved in UCT)。这个算法借用了异步并行算法的思想,其核心在于维护一个额外的统计量用于记录每个节点上有多少个正在对其进行仿真的 worker,并用其对选择算法进行调整。此外,我们使用了主 - 从工作模式的系统。由主进程维护一个完整的搜索树,并进行选择和反向传播操作。同时,主进程负责将扩展和仿真的任务分配给对应的子进程,由子进程完成后将结果返还主进程。这样做的好处在于很好地保证了统计信息对于每次选择都是完整的,同时避免了进程间共享内存和访问冲突等问题。
最终,我们用以上方法训练的 AI,对超过 1000 关进行自动难度验证,以用户实测的通关率为标准,我们的 AI 难度评估系统的误差在 8.6% 以内。在 WU-UCT 的帮助下,我们的系统可以准确地预测某一关卡上线后玩家的预期通关率,为关卡设计师提供了很好的指导,达到了不需要人工测试即可得到反馈,大幅降低了开发成本,也改变游戏制作方式。另外,我们也把这项工作总结成论文发表在 ICLR2020[1] 并被大会选为 Oral 报告论文。
自动关卡生成
当我们通过 AI 解决了给定关卡难度自动评测的问题后,一个自然的需求是能否连关卡生成也自动化?于是我们在快手自研的《爱游斗地主》上的残局玩法做开始了新的尝试。
棋牌类的残局关卡的设计非常困难,对设计人员要求非常高,即便是该游戏的专家也往往难于设计出有价值的残局。我们首先利用强化学习和 minimax 搜索设计出了一个破解斗地主残局的 AI,然后用该 AI 为基准对随机生成的牌局做筛选,同时利用实际测试的用户体验数据来学习筛选规则。除了已经上线的二人残局关卡,还能生成三人残局(因难度太高暂时没在游戏内开放)。另外为了避免生成相似的残局,我们对牌面信息做了标准化变换,让相似的牌面信息在标准化空间内成为相同的牌面。我们最终自动生成的残局达到 30-40% 的通过率(开发人员测试),大大提升了开发效率。目前该方案已经上线《爱游斗地主》残局玩法。
AI 辅助推广
游戏研发测试完成之后的下一个重要任务是进行推广。我们这里介绍 AI 在游戏广告投放业务中的一些实践和探索工作。
智能投放
游戏工作室会在流量平台(如快手)购买流量,即用户。而作为广告主,游戏工作室会建立或者雇佣第三方投放团队来进行广告投放。投放团队用素材(短视频,图片封面,广告词)构建广告创意,然后打包并设置相应的投放参数,最终形成广告计划在广告平台提供的接口中投放。广告平台负责将广告创意在进行曝光并收取广告主的费用,用户通过观看广告并点击广告中的链接,下载游戏并激活,成为游戏用户。用户在游戏内部直接或间接消费,作为游戏工作室获得流水收入。
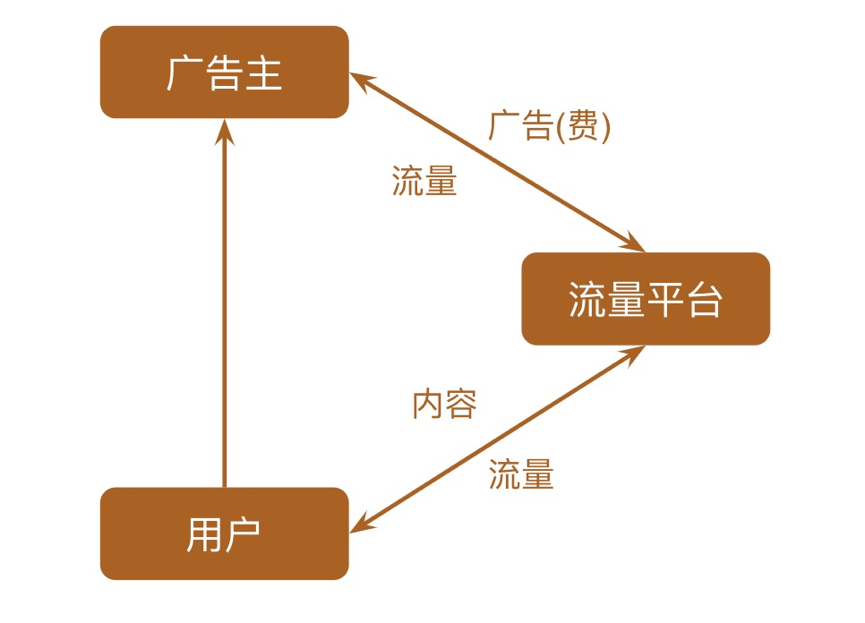
传统的广告投放以人工制作广告创意,生成广告计划为主要手段。然而,人工投放缺点明显,首先人工投放需要大量人力做一些重复性操作。其次,人工投放效果多依赖于优化师(投放人员)的直觉和经验,没有可以泛化的通用方法。
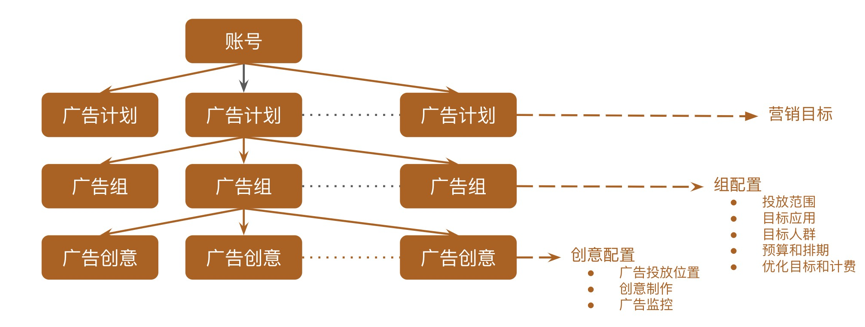
为了解决上面的问题,解放优化师的双手和部分大脑,我们搭建了智能投放系统。该系统的目标是可以形成投放的全链路闭环,不需要人工介入。这个系统是基于召回和组合排序投放策略框架。
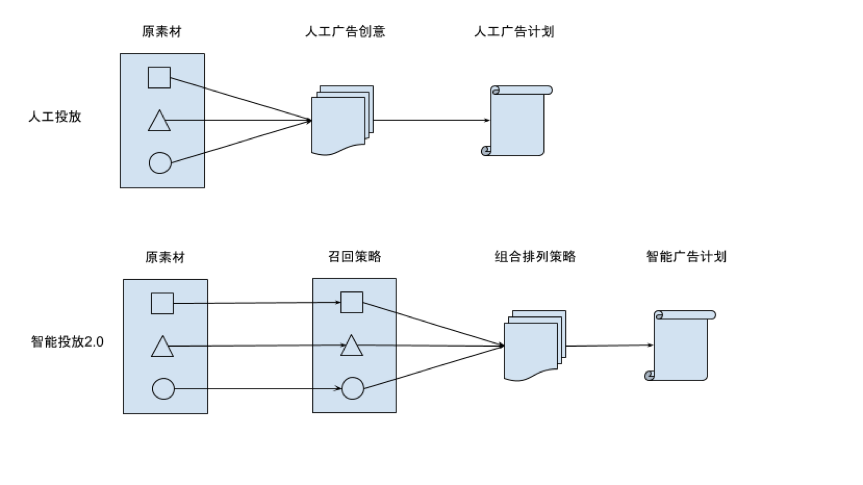
召回是指素材(短视频,封面,广告词)的召回,本质上可以理解从素材库中选取其中部分素材。召回的方法有基于规则的和基于模型的。我们召回模型多以回归和分类模型为主,如线性模型,树模型,神经网络等。我们以优化目标(ROI,激活数,激活单价等)为指标,建立监督学习模型并预测单素材表现从而优选出有潜力的素材。素材的特征,以视频为例子,包括视频重要帧的嵌入向量,视频时长,视频风格,视频类别等。另外,除了素材本身的特征,还包括过去一段时间的表现特征,如过去 24 小时的点击率,三秒完播率等。
组合排序是将召回的原素材进行组合(笛卡尔乘积)构建广告创意并排序。根据排序结果将头部创意编排进广告计划。我们开发了多种排序模型。如张量分解模型,基于神经网络的双塔模型等。在张量分解方法中,我们可以将一个创意看成是若干类型的元组,如(短视频,图像封面,广告词)可以看做一个三阶张量。之前投放的广告创意的表现,如果 ROI 等可以看做是张量的某个元素的数值。因为,张量分解可以把创意打分看成是一个张量补全问题,然后利用低秩假设和经典的张量分解算法将创意的分数补全。
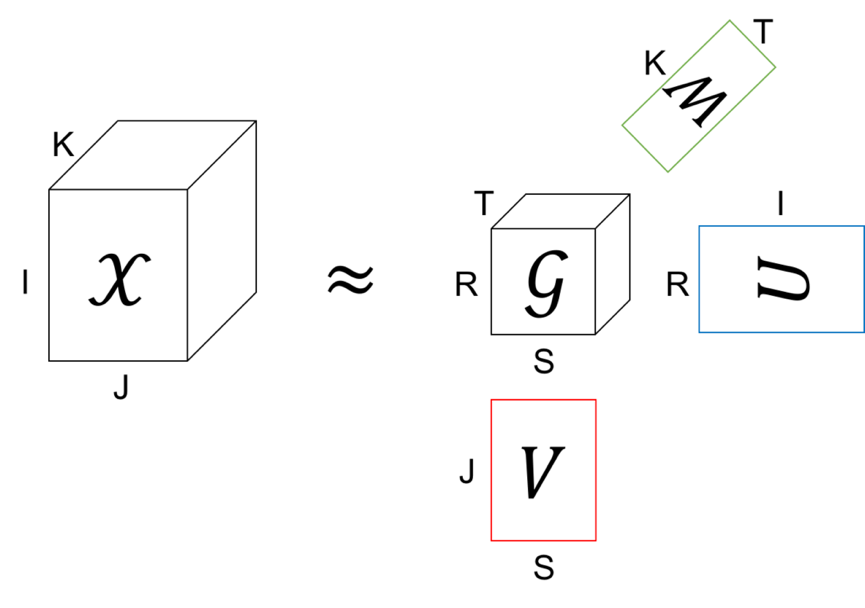
双塔模型,确切地说是多塔模型,是将各个维度的素材特征经过神经网络得到各自的抽象特征表示,然后在通过融合映射为一个分数。例如,最基本的双塔模型作用在短视频和图像封面的场景下,可以理解为给视频素材找到合适的封面。

基于召回和组合排序框架,我们就可以设计多种具体的投放策略,包括新素材冷启动、创意空间探索、智能创意制作等。除了上述投放策略,我们还开发了各种辅助策略,如素材的黑白名单策略,老素材的回收策略,关停策略等。所有这些策略配合基本已经满足我们的目前的所有场景了。目前我们已经介入 10 多款游戏,其中有 2 款游戏已经全部自动托管。目前 AI 生成的广告计划带来的花费已经是占总花费的 40% 左右。
AI 辅助运营
游戏推广之后的下一个环节是运营。在运营过程中,有许多游戏内的策略问题,游戏内的运营策略非常影响用户的体验和留存,从而影响营收。设置合适的策略通常是游戏策划的一个非常重要的工作,好的策略通常依赖于游戏策划的丰富经验和直觉。不过在某些场景下,数据可以更好指导如何生成适合用户的运营策略。另一方面,在支持运营的过程中,常常需要游戏 AI 的辅助。例如在游戏的冷启动,掉线带打等场景中,游戏 AI 发挥着重要的作用。这里我们介绍我们在快手游戏业务中,我们是如何通过数据驱动的策略和游戏 AI 去提升用户体验的。
数据驱动的游戏内策略
匹配策略
在多人竞技或者对抗游戏场景中,匹配是玩家良好体验的重要一环,对提升用户留存至关重要。用户匹配算法一般是按一定策略先粗排筛选出实力相当或满足某种规则的用户群体进行分场,然后进行局部精排分队以保证游戏平衡性,但如何从全局用户体验上进行优化得到玩家分场分队匹配还是一个 NP-hard 难题。

以《爱游斗地主》游戏原始基于规则的匹配策略为例,将待匹配用户构成匹配池,以用户状态(剩余金币量、胜率、段位等)为主要尺度,按规则公式计算战力系数,然后按该系数相近的用户匹配到一起。然而,这些信息并不能准确反映玩家真实水平,很难保证对局玩家状态平衡,导致用户实际体验不一致。因此需要更全面的评估玩家的真实水平,并从全局体验上优化匹配策略,以提高用户游戏时长和留存。
我们利用玩家历史游戏行为序列和画像数据,基于深度神经网络实现多维特征融合的用户匹配策略。将玩家历史游戏行为统计特征和用户画像作为模型输入,玩家历史对局的连桌数的区间分类作为标签,我们可以训练一个多分类模型。线上预测时,首先通过设计的聚类模型对用户进行粗略聚类——即粗排过程。然后将每个聚类下用户,三人一组(斗地主规则)分组,将所有分组组合输入预测模型,输出不同组合下匹配概率值,优先将概率值大的组合匹配在一起——即精排过程。
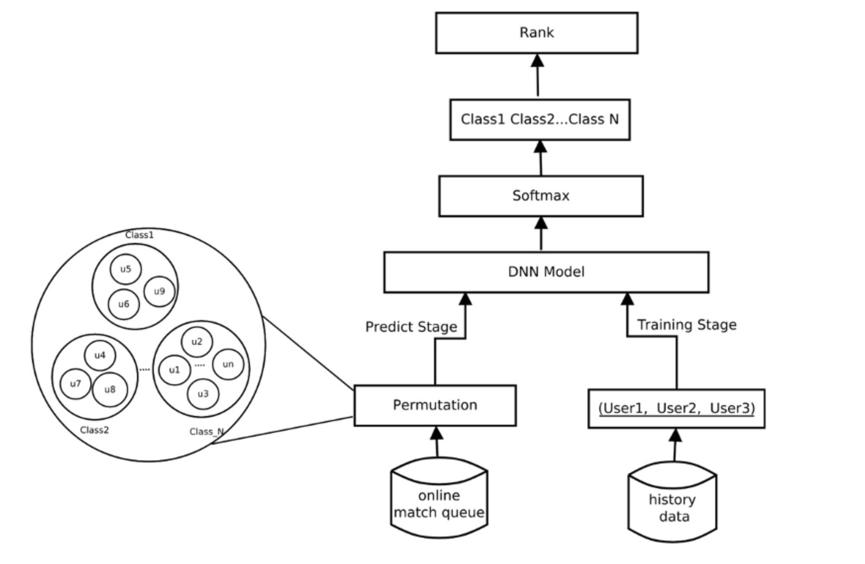
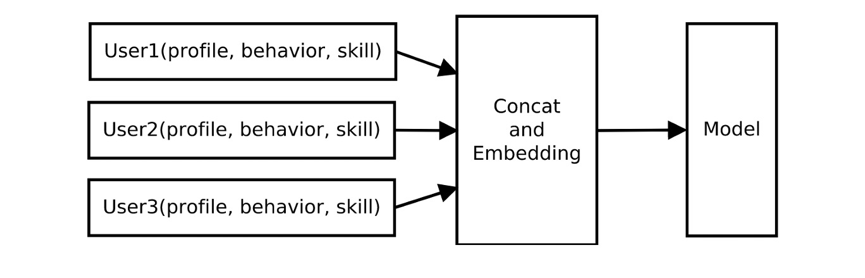
关于特征提取,我们从用户历史对局数据中,提取出用户基本特征和行为特征。此外,通过概率图模型,我们将各玩家的游戏战力看成一个随时间动态变化的高斯分布,从游戏对局结果中学习玩家的能力值 [2],以反映玩家真实游戏水平。将上述用户基本特征、行为特征和玩家能力值联合拼接后进行特征嵌入表征作为匹配模型输入特征。我们将连续对局次数(称为连桌数)作为匹配结果较好的一个正向反馈。我们构建深度神经网络作为模型,以局为单位联合三名玩家特征作为模型输入:
我们主要关注的运营指标是用户留存。该模型上线后,较传统基于规则的匹配策略,用户 7 日留存提升了约 2.4%。
发牌策略
除了匹配,发牌也是至关重要的。在斗地主游戏中,分发出去的牌组将直接影响该局游戏玩家的发挥及游戏体验。发牌完成后,系统不再对牌局进行干涉,由三位玩家自行完成游戏。因此,发牌的策略是斗地主游戏决策中至关重要的部分。传统的发配策略通常为随机发牌或者根据规则生成牌组。随机发牌的情况下,可能出现非常零散的手牌或是三家牌力非常不平衡的牌组,从而造成不公平,这些都会严重影响玩家体验。而按规则的发牌策略往往比较生硬,无法对牌力进行有效的调整。另外,以上方案都没有利用玩家的状态信息进行发牌。因此,我们开发了数据驱动的发牌策略。
我们首先制作了牌库,其中包括大量的牌组。而入选牌库的标准则是根据玩家的反馈。玩家的反馈有很多,例如一局之后,超过一个玩家点击“再来一局”就可以认为是一个正向反馈。如果没人点击“再来一局”可以认为是负向反馈。我们收集多种反馈,从而标记一个牌组的“好坏”,并利用这些样本数据训练二分类模型。之后我们随机或者按规则生成牌组,并通过以上模型来过滤出相对好的牌组进入牌库。当然,不同场次的玩家偏好不一样,从而反馈也不一致。因而我们根据不同场次分别组建牌库。另外,在同一牌库中,我们根据其中牌组的特征进行了聚类,这些聚类标签也可以在后续的牌组选择中应用。我们的牌库模型和牌库本身也会根据数据的积累,定期更新。
接着,我们提出一种基于强化学习的牌组选择与牌位分配的方法。我们从玩家的历史游戏信息以及近期的胜负信息中,提取玩家的基本特征、行为特征、状态特征等。同时,我们从牌局提取相应的牌组特征。我们将玩家特征视为 state,牌组特征视为 action,一局游戏的 reward 定义为玩家是否继续游戏的,从而建立 RL 学习框架。我们利用 Q-Learning 算法对最佳发牌策略进行学习。
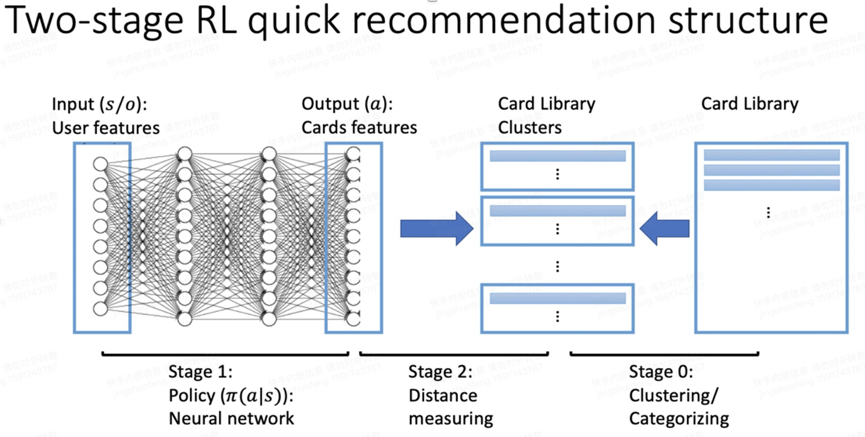
在线上发牌阶段,将三名玩家的信息进行特征提取得到用户特征。另外,计算不同子库分别能达到的收益值,取能最大化收益的子库。再根据模型,从子库从中选取最优牌组。
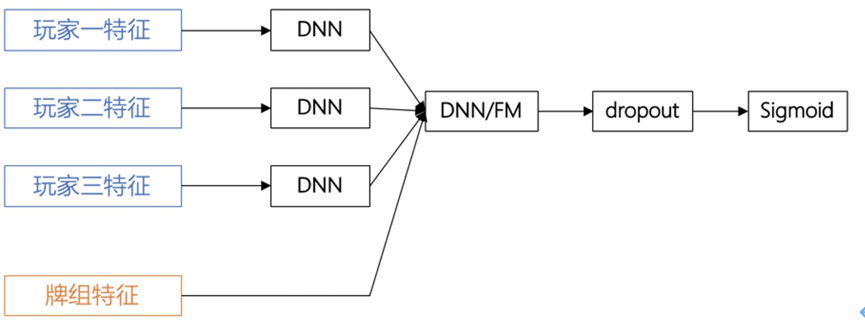
该策略上线后显著提升了活跃度,综合 7 日留存提升了 3.6%,日平均局数提升了 11.7%。另外,我们还针对不同的场次分别提供了个性化的模型和牌库,目前该策略已经推全到《爱游斗地主》的所有场次。另外我们还提供专门用于比赛和直播的牌库。
游戏 AI
在游戏运营过程中,我们有多个场景需要游戏 AI 的支持,例如出牌提示和掉线代打等。游戏 AI 技术对游戏的支持,主要体现在《兜来玩麻将》业务中的落地以及在斗地主业务中推广。《兜来斗地主》包括 6 种麻将玩法,例如四川麻将 - 血流成河,四川麻将 - 血战到底,大众麻将,二人麻将等。在游戏刚上线的业务冷启动阶段,由于玩家数量较少,需要将游戏 AI 投入到匹配池来提升体验。因此,需要支持 6 种以上麻将玩法的 AI 并支持分级。然而,通用的麻将 AI 研究是一个学术界尚未解决的非对称博弈难题。MSRA 在日本麻将上做出了超越人类水平 AI[3],然而其算法框架强烈依赖于专家级别用户的训练数据且针对日本麻将的规则做了定制化,不适合应用于我们支持多种玩法的业务需求和大规模扩展。
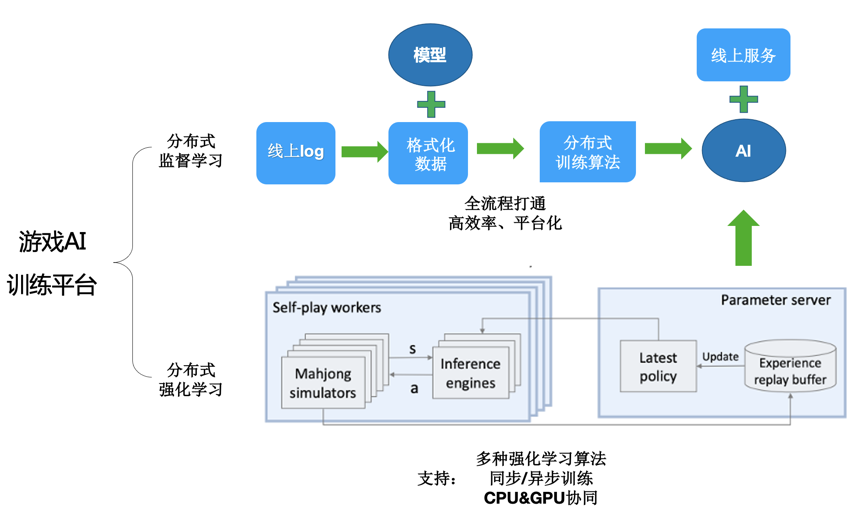
我们基于深度强化学习进行创新性的研究,解决了缺乏专家级数据等技术难点,沉淀出一套扩展性极强的的算法框架,成功在多种规则麻将中使 AI 达到人类顶尖水平,不仅满足了业务需求,也达到了业内领先的成就。我们还推广该框架至其他游戏,例如斗地主。
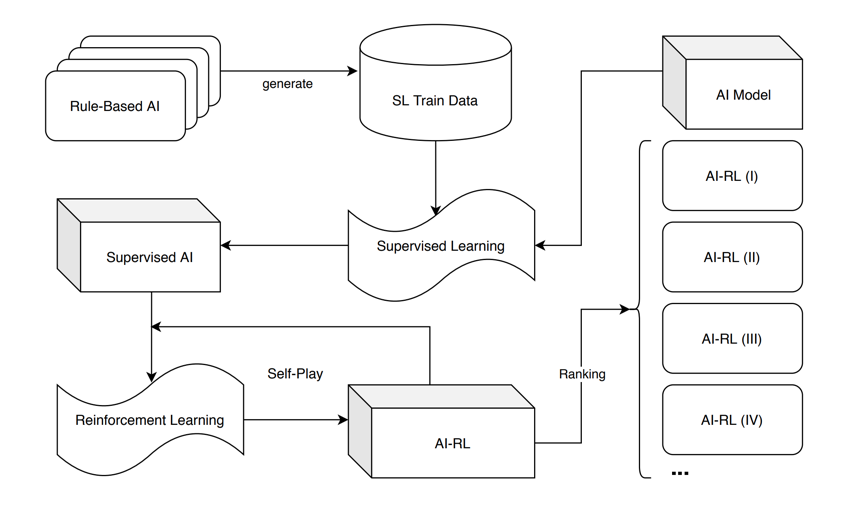
首先我们解决了缺少高质量数据的问题。该方法是先使用简单的基于规则的 AI 互相对战生成训练数据,并用这个数据进行监督学习得到一个初始化模型,然后从这样一个初始化模型出发自对弈进行强化学习。我们称这个方法为 RuleBase Initialization (RBI)。RBI 方法得到的 AI 水平远高于从零开始训练的 AI,并且这套流程可以适用于不同的麻将规则,可扩展性强,并可以满足 AI 分级的要求。
其次,我们设计了平滑的奖励来解决初期训练困难和奖励方差过大的问题。在训练初期,AI 水平比较低,直接用游戏的真实奖励随机性太大,容易使梯度方向偏离正确方向。我们通过加入一些人为设计的听牌、和牌的奖励使得奖励更符合对于新手的引导。在训练过程中,我们逐渐降低人为设计奖励的权重,使奖励平滑地回归游戏的真实奖励。同时,我们采取了 reward clipping 方法来防止梯度过大。
麻将的规则十分多样,不同规则麻将在流程、可行动作域、记分方式等方面有区别。为了高效支持大量不同规则的麻将 AI,我们的算法框架必须具有比较强的通用性和可扩展性。为了提高可扩展性,我们尝试了区别于传统 Decision Flow 的全新结构:将所有可能的 action(包括出牌)排成一个向量作为模型输出的概率分布,这样用一个模型就能处理所有打牌阶段决策。我们对这个单模型 AI 使用 RBI 方法进行强化学习训练,得到了很好的效果。此外,这种算法可扩展性极强,每种玩法只需要重新训练一个模型,代码改动量也很小。我们用这个框架快速拓展,目前已经支持了血流、血战、大众、二人、北方推倒胡,国标麻将等规则。
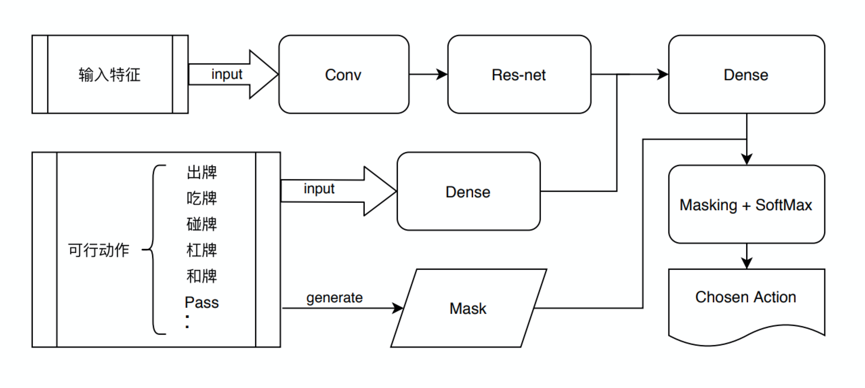
我们已经将多种玩法的 AI 在快手的《兜来玩麻将》中上线,我们最高级的 AI 水平显著强于高水平玩家。其中,我们的国标麻将 AI 参加了 2020 年 IJCAI 的国标麻将比赛,以第一名的成绩入围即将举行的决赛。在麻将 AI 的探索中,我们不但沉淀了一套麻将 AI 的能力,而且还锤炼了一套完整的游戏 AI 的训练平台和方法论,并已经将相关经验迁移到斗地主等游戏中。
规划和展望
随着 AI 能力的不断扩展,对游戏的赋能也会不断深化和拓展,相信在不远的将来 AI 能力可以更深入的触及游戏行业的各个环节,极致化用户体验,形成 AI 能力在游戏上更完美的闭环。
参考资料:
[1] Anji Liu, Jianshu Chen, Mingze Yu, Yu Zhai, Xuewen Zhou, and Ji Liu, “Watch the Unobserved: A Simple Approach to Parallelizing Monte Carlo Tree Search,” ICLR 2020 (oral 2%) (url: https://openreview.net/forum?id=BJlQtJSKDB)
[2] Minka, Thomas P., Ryan Cleven and Yordan Zaykov. “TrueSkill 2: An improved Bayesian skill rating system.” (2018).
[3] Li, Junjie, et al. "Suphx: Mastering Mahjong with Deep Reinforcement Learning." arXiv preprint arXiv:2003.13590 (2020).
团队介绍:
我们是快手 AI 平台部和游戏业务部的共建的游戏 AI 联合实验室。我们致力于用 AI 技术对游戏全链路的支持和赋能,提升玩家体验,提高业务收益,降低游戏的研发和运行成本。




