
导读:重排逐渐成为了工业推荐系统必不可少的一环,今天我们来聊一聊我们在手淘信息流中优化重排收益的实践经验。我们首先会分析推荐系统中现有重排方法的局限性,指出工业推荐系统中重排的主要任务和其中存在的四个主要挑战,分别为上下文感知、排列特异性、复杂度和业务要求,分析了这四个特性和达到序列收益最优的关系。
基于上下文感知到达最优序列收益的思路,我们设计了序列检索系统,分为重排-召回和重排-排序。在重排-召回中,我们注重于从输入商品序列中快速生成候选序列集合,提出了快速序列搜索算法和生成式重排算法。在重排-排序中,我们提出了基于上下文感知模型的 LR 指标,作为从候选序列集合中挑选出最优序列的统一标准。我们在淘宝首页信息流众多核心场景落地并取得了显著的业务效果。我们有理由相信序列检索系统会成为每个工业级推荐系统的必备架构,并且根据每个场景的特异性将会有多种多样的算法沉淀到这一架构中。
背景
随着深度学习的发展,工业推荐系统在探索用户兴趣和减缓信息过载取得了持续的进步。在一个典型的工业推荐场景中(如图 1 的首页信息流、微详情页和短视频),一个经过排序的、最贴近用户兴趣的最终推荐列表被推荐给用户。一个标准的工业推荐系统通常由三个阶段依次组成:召回、排序和重排。一直以来,召回和排序得到了持续的关注和长足的发展,而重排,由于其直接决定了最终透出的商品及其展示顺序,也在逐渐受到关注并且展示出极大的潜力。
随着对重排问题及其特性理解的深入,各种各样的重排方法被提出。经过调研,工业推荐系统中现有的重排工作主要通过两种方式来提升重排的效率:
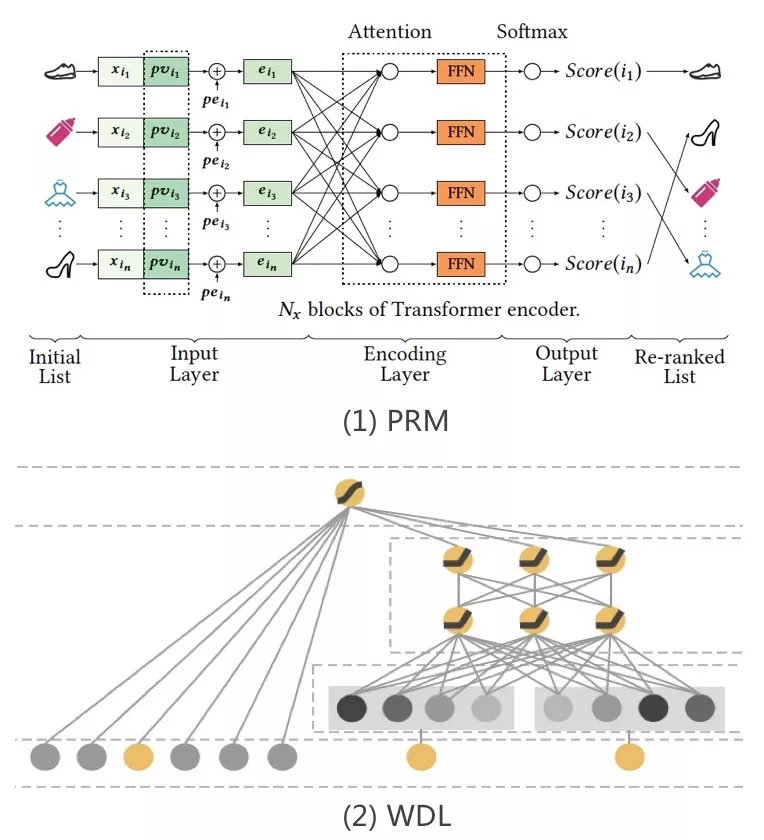
如图 2-1 PRM,通过融入输入商品列表的全局 [3, 6] 或对比 [4, 5] 信息,探讨每个商品与待打分序列之间的潜在关系和相对优势,得到一个修正过的、序列感知的预估分数;
如图 2-2 WDL,通过糅合上游预估分(CTR, CVR 和 price)和实时特征,来设计 LTR [1, 2] 模型为每个商品预估一个综合的分数,同时还能满足实时流量调控的需求。总体来说,这两种方法都是通过融入更多的信息,来修正并且得到每个商品更加准确的预估分数,并且采用基于贪婪的策略来进行排序,以期用户能够尽早地与他更感兴趣的商品进行交互。
然而,现有的基于贪婪的策略的重排方法忽略了最终推荐列表之间的上下文关系,因此不能保证其达到序列最优。如图 3,这三个商品按照预估分贪婪排序整体预期的预期点击收益为 0.62,然而,如果将灰色衣服排到第一位,虽然它自身的预期点击收益降了,但是导致蓝色衣服预期点击收益的提升,从序列整体收益的角度来看,探讨了上下文感知的重排算法是序列最优的。因此,我们认为基于贪婪的策略忽略了这种上下文关系,即商品被用户交互的概率不仅仅由商品和用户本身决定,还极大地被环境中的上下文关系所影响,并不是最优的重排策略。

理想很美好,但是建模并利用好这种上下文关系存在着诸多挑战。根据我们的实践经验,总结了以下几点:
上下文感知:重排的任务设定是从上游给定的输入商品列表选择固定个数并排好序的最终推荐列表。我们把这个任务视为由多次决策顺序组成,其中每次决策是从输入商品列表中挑选一个商品放到当前位置。为了真正地形成一个上下文感知的最终推荐列表,在每次决策时,我们应当考虑到两方面的影响:
上文。当前决策应该考虑到上文对此次决策影响来做出最合理的决策。如上文推荐了一个大概率会交互的商品,是否应该出异类目的商品来缓解他对前序类目及推荐结果的疲劳度,还是让他接着浏览他感兴趣的同类目商品。
下文。当前决策应当考虑到对下文产生的深远影响。如当前决策推荐了一个他不感兴趣的商品,应该考虑到他可能因为此次决策而降低用户体验甚至停止继续浏览带来的收益损失。
因此,只有做到了上下文感知的重排,才能带来更多的效率收益和更好的用户体验。
排列特异性:基于上下文感知的考虑,即使是两条由同样商品集合组成的最终推荐列表,由于其排列方式导致的序列整体收益的差异我们称为排列特异性。找到最优的排列需要考虑到这种特性,然而,基于贪婪的策略陷入了无限循环的问题:上下文感知的模型为输入商品列表列表中的每个商品预估交互概率,然后基于这个分数贪婪排序得到一个新的排列,又由于排列特异性导致新的排列中每个商品的预期交互概率改变而又需要重新进行预估。无法证明这样一个循环能达到最优排列,因而破除排列特异性成为了转化上下文感知模型为生产力的关键。
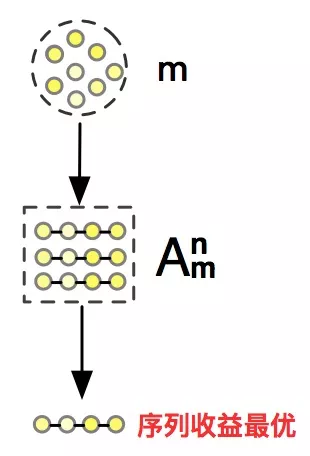
复杂度:长久以来,重排的复杂度被以一个单点预估的角度来看待。事实上,如图 4 所示,考虑到排列特异性,潜在的推荐列表往往在 Anm(≈mn)的量级(m、n 分别是输入商品列表和最终推荐列表的长度,如 1000、10),我们最后要挑选出的只是其中的一条序列。显然,将所有可能的候选序列都用上下文感知的模型评估是不可能的事情。如何设计快速且有效的算法和系统并兼顾上下文感知和排列特异性的特点是一个极大的挑战。
业务要求:典型业务要求的考虑,我们主要分为两部分:
打散策略。最常见的如对类目、店家等维度的打散策略,来保证最终推荐列表有较好的用户体验。因此我们需要在重排时考虑这些策略,否则即使是效率最优的最终推荐列表也不能被透出;
性能要求。云端部署的推荐系统对性能往往有很高要求,串行一个超过 10 毫秒的新链路会导致超时率上升。同时我们应该考虑,复杂的算法是否还有合适的优化方式或者链路。
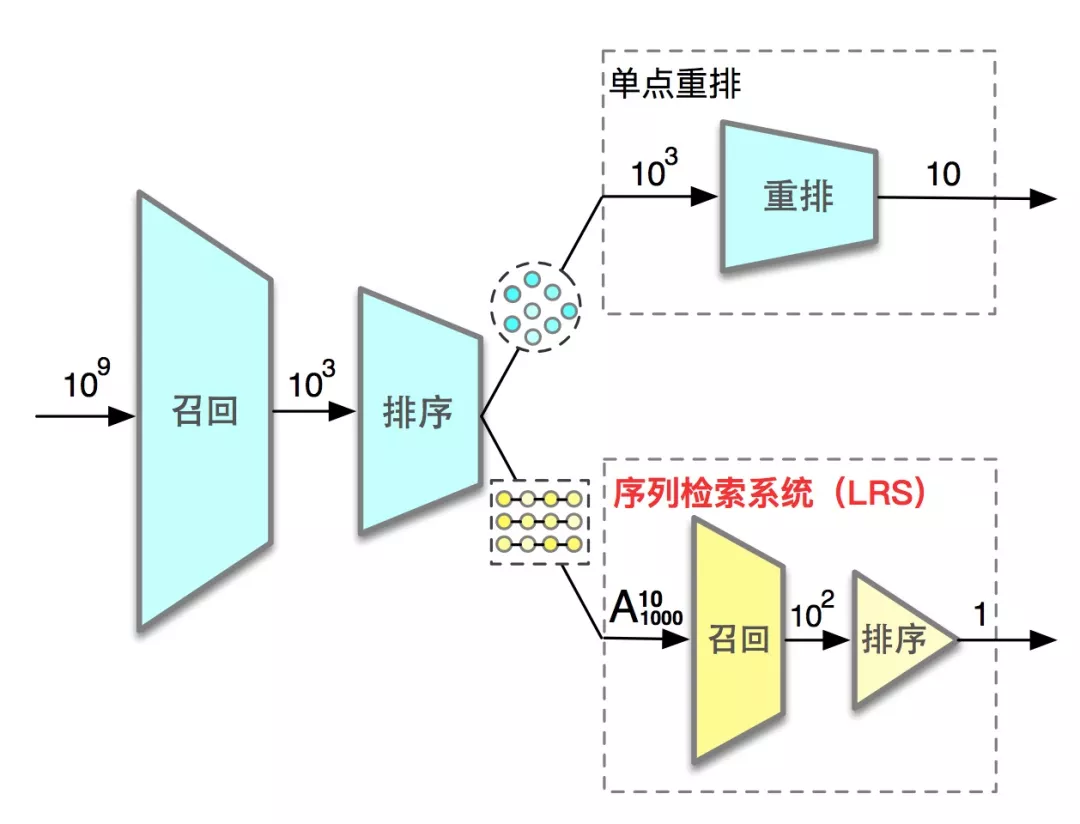
综合以上考虑,我们将现有的单点打分的重排模式升级为两段式结构,来保证既高效又准确地来选出较优的最终推荐列表,并且命名为序列检索系统(List Retrieval System,LRS)。如图 5 所示,其中分为两部分:重排-召回和重排-排序。重排-召回用来快速或准确地生成候选打分序列集合,其中我们沉淀了两套算法:基于 Beam-search 的快速序列搜索算法和基于 Policy-gradient 和 Evaluator-Generator 的生成式重排算法 (Generative Reranking Network, GRN)。在重排-排序中,我们沉淀了上下文感知的深度模型 DCWN(Deep Context-Wise Network),来修正每条序列中商品的上下文感知的预估概率,同时提出了将整体预估概率作为序列的收益的 LR (List Reward) 评价指标,以此作为标准来选出最优的一条序列。
序列检索系统在首页猜你喜欢、微详情页和短视频均已全量,并且取得了显著的业务效果。在微详情页和短视频中我们完整实现了序列检索系统的架构,分别取得了 PV + 11%,IPV + 6% 和 有效 VV + 5%,人均播放时长 + 7% 的提升。生成式重排算法在边缘计算 [7] 中落地,比上个版本的单点预估模型提升 PV + 5.1%,IPV + 6.2% 。
在接下来的章节中,我们将介绍重排方向中已发表并广泛接受的工作。之后我们用通用的方式定义重排问题,并且详细介绍了我们在序列检索系统中沉淀的三个算法实现及其实验结果。最后我们总结工作并提出了几个重排方向未来工作的优化点。
相关工作
已发表并广泛接受的重排或者 LTR 工作分为这么几类:
Point-wise 模型:和经典的 CTR 模型基本结构类似,如 DNN [8], WDL [9] 和 DeepFM [10]。和排序相比优势主要在于实时更新的模型、特征和调控权重。LTR 对于调控权重的能力还是基于单点的,没有考虑到商品之间互相的影响,因此并不能保证整个序列收益最优。随着工程能力的升级,ODL [11] 和实时特征逐渐合并到排序阶段并且取得了较大提升。
Pair-wise 模型:通过 pair-wise 损失函数来比较商品对之间的相对关系。具体来说,RankSVM [12], GBRank [13] 和 RankNet [2] 分别使用了 SVM、GBT 和 DNN。但是,pair-wise 模型忽略了列表的全局信息,而且极大地增加了模型训练和预估的复杂度。
List-wise 模型:建模商品序列的整体信息和对比信息,并通过 list-wise 损失函数来比较序列商品之间的关系。LambdaMart [14]、MIDNN [3]、DLCM[6]、PRM [5] 和 SetRank [4] 分别通过 GBT、DNN、RNN、Self-attention 和 Induced self-attention 来提取这些信息。但是由于最终还是通过贪婪策略进行排序,还是不能真正做到考虑到排列特异性的上下文感知。随着工程能力的升级,输入序列的信息和对比关系也可以在排序阶段中提取出来。
Generative 模型:主要分为两种,一种如考虑了前序信息的,如 MIRNN [3] 和 Seq2Slate [15] 都通过 RNN 来提取前序信息,再通过 DNN 或者 Pointer-network 来从输入商品列表中一步步地生成最终推荐列表。最近的组合优化工作 Exact-K [16] 注重于直接对序列整体收益进行建模,设计了两段式结构,一个用来预测整体收益以指导另一个生成最终推荐列表。通过我们的讨论,仅考虑了前序信息是不完整的,应当全面地考虑到上下文的影响。
Diversity 模型:最近有很多工作考虑最终推荐列表里的相关性和多样性达到平衡,如 [17~20]。我们的工作区别在于,我们并不会去优化多样性指标,最终推荐列表是否表现出多样性全由效率指标决定。
准备工作
一个标准的工业推荐系统通常由三个阶段依次组成:召回、排序和重排,其中重排阶段从输入商品列表挑选部分商品进入最终推荐列表并决定其展现顺序。通常地,假设有用户集合 U 和商品集合 I,我们有序列形式的交互样本 R={(u,C,V,Y,N)|u∈U,V⊂C⊂I}。其中 C 和 V 分别是长度 m 和 n (m≥n)的输入商品列表和最终推荐列表, Y 和 N 分别记录了用户 u 对 V 的交互反馈和下拉反馈,均为 0 或 1(是否点击和是否下拉)。同时每个用户和商品都会带有一些画像特征,如年龄、行为和类目,在对样本里的用户 u 和商品 v 关联这些特征并 embedding 后分别表示为 xu 和 xv。
问题定义:
重排的任务是对用户 u 和输入商品列表 c,我们通过重排来从 c 挑选并排序生成最终推荐列表 O,以期让用户进行更多的浏览(PV)和交互(IPV)。基于上面的讨论,在我们的工作中,我们将重排任务分为了两个阶段:重排-召回和重排-排序。我们在重排-召回中生成候选序列集合 L={O1,O2,...} ,在重排-排序中选出最优的最终推荐列表 O。
重排-召回
重排-召回阶段旨在通过一些策略或者模型生成效率较优的候选序列集合。和召回类似,重排-召回也面临了复杂度问题:重排-召回的的序列候选池在 Anm 的量级,如何快速高效地从输入商品列表中选出较优的序列集合是一个极大的挑战。和召回不一样的是,重排-召回需要从序列的角度去思考问题,即考虑最终推荐列表的上下文感知特性来生成序列和获取最大的序列收益。
重排-召回的整体框架如图 6 所示,在这个阶段我们可以并行地部署多个序列召回算法,然后合并成候选序列集合 L。其中,我们沉淀了两个算法:基于 Beam search 的快速序列搜索算法,在每一步的选择时,充分考虑了对前序集合和后续挑选的影响。生成式重排在 Exact-K [16] 的思路上进行了拓展,分别设计了上下文感知的 Evaluator 监督学习模型和逐个生成最终推荐序列的 Generator 模型,并通过设计带有加强上下文感知的 Advantage reward 的策略梯度优化算法来监督 Generator 学习。
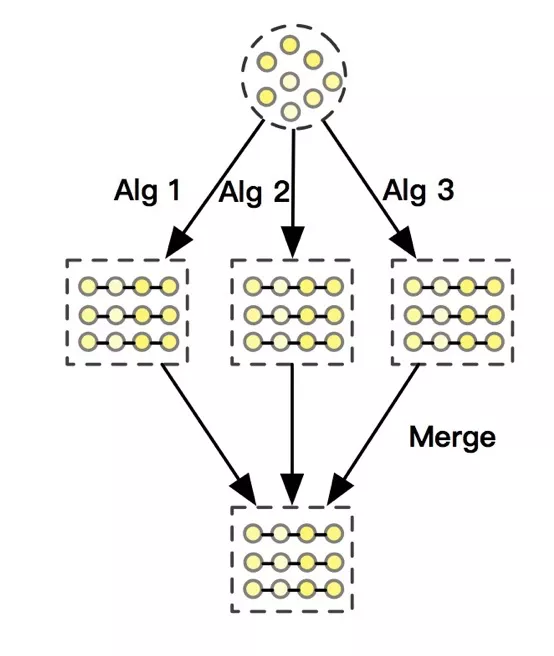
1. 快速序列搜索算法
为了让用户进行更多的浏览(PV)和交互(IPV),实际上,在生成序列的每一步时,我们要考虑两个因素:
考虑到前文商品的影响,在这一步放什么商品才能最大化整体预期的 PV 和 IPV;
在这一步选择这个商品后,会对后续的浏览造成的影响。传统的贪婪排序算法会导致用户感兴趣的商品全部集中在头部,在频繁的交互后会导致用户的疲劳度增加甚至停止浏览,缩减了推荐系统继续探索和激发用户潜在兴趣的空间。
在快速序列搜索算法中,我们将原来的 CTR、CVR 分视为商品单点的价值预估,即不会对上下文商品造成影响的预估分;我们将用户被曝光完这个商品将继续浏览的概率,即 NEXT 分,视为一种会对上下文产生影响的分数,一个有较高预估分的商品能够提高后续商品的点击和转化收益。我们将 CTR、CVR 分作为用户交互概率的抓手,与 NEXT 分共同影响,相互作用,来让每次的展示结果都能在浏览和交互期望上达到动态最优。
具体的算法流程见图 7。在离线阶段,我们训练了基于 u,v,Y 的点击率 point-wise 预估模型(ModelCTR)和基于 u,v,N 的下拉概率 point-wise 预估模型(ModelNEXT),并且在排序阶段并行部署为 c 进行打分。具体来说,对 c 每个商品 ci 有两个额外的概率估计 PciCTR 和 PciNEXT,分别表示了用户对商品 ci 的交互概率和继续浏览的概率。
在线上阶段,我们实现了每一步浏览和交互期望的 beam search 逻辑。在算法伪代码的 1~17 行,我们将最终要生成目标个数(n)的序列任务拆分成一步步的序列动态期望最优的问题。每一步中,对于候选序列集合 L 中的每一条序列,我们将填充 c 中没被该条序列选中的商品,并且计算预期的序列收益。同时这里我们还考虑了业务要求的限制,如打散规则,去除了和前两个商品的类目相同的商品,来保证不会生成不符合业务规则的候选序列。基于算法效率的考虑,我们只保留了预期序列收益最高的 k 条序列。在 18~28 行,我们计算了任一序列 O 的预期 PV 收益 rPV 和 IPV 收益 rIPV,最后通过可调整的权重动态加成最终预期收益 r。其中最关键的是传递的曝光概率 pExpose,它由序列 O 中的商品依次累乘,并且影响了计算预期 PV 和 IPV 收益。直觉上来说,某一步的商品下滑概率极低,降低了后续商品的 PV 和 IPV 收益,那么即使他的 CTR 极高,从预期序列收益的角度来看,也是较差的选择。通过这种方式,我们为每个序列提供了可比较的序列收益,为 beam search 的每一步提供了选取的依据。在算法结束后,我们得到了一个可排序的候选序列集合 L,可以选择根据收益 r 最大的 top 1 序列直接透出,也可以接着在重排-排序中再次打分选取 top 1。

2. 生成式重排 (Generative Reranking Network, GRN)
如上文提到的,在重排阶段达到序列收益最优的核心要素是达到最终推荐列表中的上下文感知。 现有的工作,要么 [3, 4, 5, 6, 8, 9, 10] 默认最终推荐列表中的商品相互独立并通过贪婪策略来重排,要么 [3, 15] 只考虑了每一步的前序信息来选取每一步的最优解。这两类工作都忽略了最终推荐列表的上下文信息,都无法都达到序列收益最优。事实上,最终推荐列表中的每一步选择,需要全面考虑对前序和后序信息的影响。然而,由于排列特异性的存在,最终推荐列表在重排阶段是一个穿越信息:因为无法知道最终推荐列表是什么,达到上下文感知便无从谈起。
受到 Exact-k [16] 和 Actor-critic [21~23] 的启发,我们选择了在上下文感知的模型的指导下,学习一个最优序列重排策略。具体地,我们利用记录下来的最终推荐列表及其用户反馈,训练了一个上下文感知的模型 (Evaluator),通过考虑到最终推荐列表的上下文来更准确地预估每个商品被交互的概率。接着,我们设计了一个基于深度模型的交互策略(Generator),一步步的从输入商品列表挑选商品并生成最终推荐列表。最终,我们设计了两段式的训练过程:通过监督学习去训练 Evaluator,再通过基于 Advantage reward 的策略梯度方法来训练 Generator。
① Evaluator
如上文讨论的,在推荐场景中,用户对最终推荐列表中的商品是否会产生交互除了跟用户和商品本身的信息有关外,还极大地受到上下文环境的影响。这里,我们主要考虑这两种影响:
用户意图在浏览过程中的双向变化。一般的,在某一页的浏览中,除了顺序地浏览商品时发生的意图变化,后续的推荐结果也会对用户的意图产生影响,尤其是在双列信息流的情况中;
商品之间的协同关系。这种与位置关系无关影响有助于提取更加长期的商品关系依赖。
在这里,我们认为只有捕捉了最终推荐列表的上下文环境产生的影响,才能真正达到上下文感知。
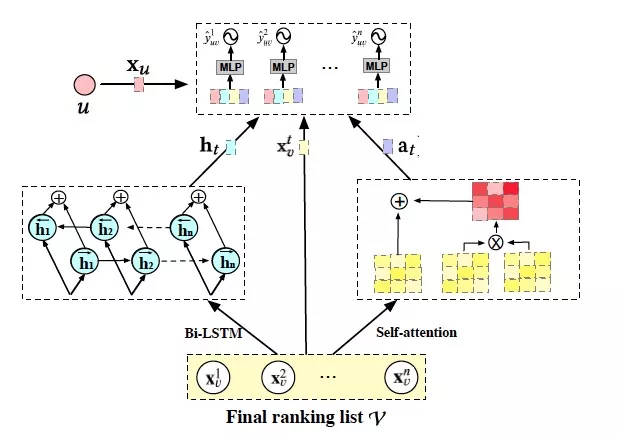
如图 8 所示,为了建模上下文环境,我们设计了 Evaluator:
具体来说,我们分别通过 Bi-LSTM 和 Self-attention 来建模用户意图和商品协同关系:
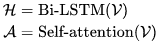
接着,我们拼接上用户特征 xu 和 xvt,送入 MLP 中进行预估:
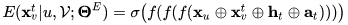
其中 t 代表了 V 中的第 t 个索引,ht 和 at 分别表示了 H 和 A 中的第 t 个表达。最终,我们通过交叉熵来优化参数ΘE:
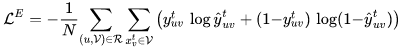
② Generator
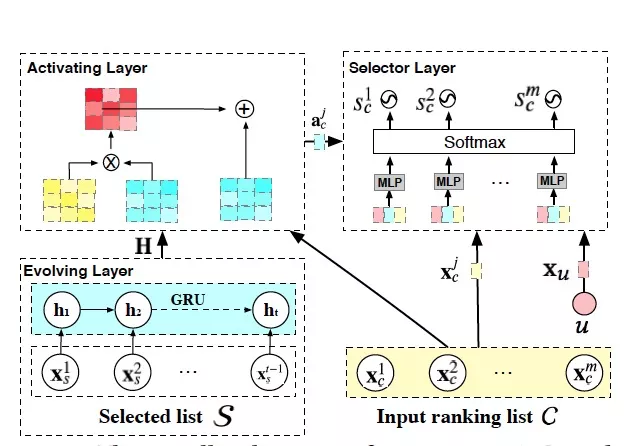
如图 9 所示,我们通过设计 Generator:G(u,C;ΘG) 来学习一个上下文感知的重排策略。准确来说,我们将重排策略看成是一个槽填充的任务:从输入商品列表依次进行多次挑选来生成最终推荐列表。在第 t 步时,我们为这个策略达到最优提供了两方面的信息:已经挑选出的商品序列 S 和输入商品列表 C,并通过不同的模型结构来建模这些信息。首先,我们通过 GRU 和 Attention 结构来建模挑选出的商品序列之间的内在联系和与输入商品列表的潜在关系:

接着,我们通过 Pointer-network 对输入商品列表进行比较,在排除掉已选出和不符合业务要求的商品后,输出这一步最合适的商品:
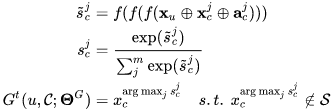
其中 j 表示 S 中第 j 个索引,acj 即 A 中第 j 个表达。通过重复 Generator 固定次数后,我们可以得到最终推荐列表 O。实际上,我们会在每一步选择更多商品以得到一个候选序列集合 L={O1,O2,...},将每条列表每一步的选择概率累乘,作为整条列表的选择概率。
我们选择通过策略梯度的方式,让 Evaluator 来监督 Generator 学习并收敛至一个较优的上下文感知的重排策略。其中,为了全面的评价最终推荐列表中 O 每个商品 xot 的真实价值,我们设计了 Adavantage reward,由以下两部分组成:
Self reward:考虑到最终推荐列表中上下文的影响,我们用 Evaluator 预估出的交互概率作为每个商品在列表中的实际价值:
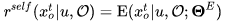
Differential reward:对最终推荐列表中的每个商品,除了自身的价值外,还应当考虑到对列表中其他商品的影响。比如,挑选一个用户不喜欢的商品通常不是一个好的选择,但是如果能够显著地提升其他商品的交互概率也是不错的。具体计算方式如下:
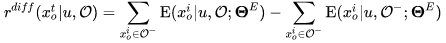
Adavantage reward 融合了 Self reward 和 Differential reward,计算如下:
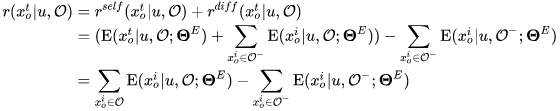
其中 O- 是从 O 中去除 xot 的序列。最终,我们定义了 Generator 的损失函数:
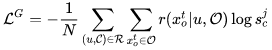
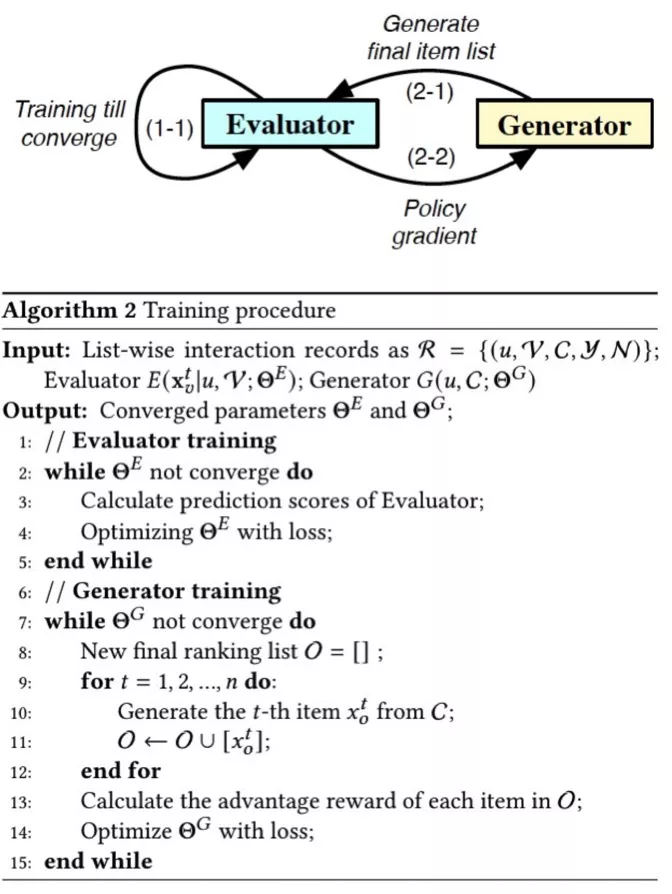
③ Training
如图 10 所示,我们通过两个阶段的优化流程来依次训练 Evaluator 和 Generator。如图所示,首先,我们通过真实的交互样本 R 来训练 Evaluator。接着,我们固定参数ΘE,先通过 Generator 生存最终推荐列表 O,再用基于 Evaluator 计算的 Adavantage reward 的策略梯度优化ΘG。
重排-排序
如我们在重排-召回中的快速序列搜索算法和生成式重排所示,这两种算法都通过考虑最终推荐列表的上下文关系生成了候选序列集合 L,并且提供了内部可比的评价指标。简单的,每种算法都可以根据自己的直接透出 Top 1 的最终推荐列表,也能取得不错的效果。然而,每种算法都不是序列收益的最优解,因为都或多或少的对上下文信息考虑不够完全,如快速序列搜索算法中仅仅依靠传递曝光概率而无视了商品的具体信息,缺少了泛化性;生成式重排中,Generator 也不能预知后面的商品信息,只能依靠 Evaluator 将知识转移到参数中。同时,每种算法之间的评价指标也不可比,导致每个序列候选集合可能是互斥的、非此即彼的状态,很明显,这不符合我们兼听则明的原则。
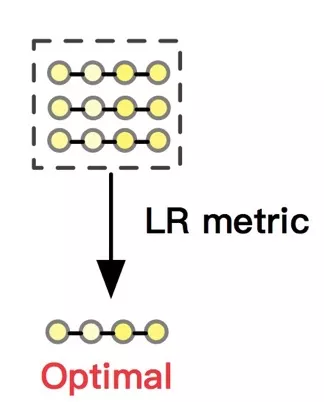
如图 11 所示,我们设计了重排-排序阶段,合并了多种算法的序列候选集合,并从候选序列集合选出一个最优解。因此,我们需要一种统一的、泛化性强的并且真正上下文感知的评价标准。很明显的,我们在生成式重排已经实现了这个模型,即 Evaluator,同时我们也可以叫做是上下文感知的深度模型 DCWN(Deep Context-Wise Network)。在这里,我们通过 DCWN 将候选序列集合中的每条候选序列进行打分,将序列中每个商品的预估交互概率相加作为整条序列 O 的预期序列收益 LR(List Reward),如下:
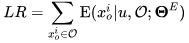
根据这个分数,我们既考虑了序列的上下文感知,又统一了候选序列的评价标准,并从中选出 top 1 作为最优结果透出,为我们扩充多样的、不同角度的重排-召回算法提供了广阔的空间。
实验
序列检索系统在首页猜你喜欢、微详情页和短视频均已全量,并且取得了显著的业务效果。在微详情页和短视频中我们完整实现了序列检索系统的架构,其中重排-召回中的快速序列搜索算法取得了 PV + 11% 和 有效 VV + 5%,人均播放时长 + 7% 的提升,只给链路耗时增加了 1 ms。重排-排序在微详情页中进一步取得了 IPV + 6% 的提升,给链路耗时增加了 6 ms。生成式重排算法在边缘计算 [7] 中落地,比上个版本的单点预估模型提升 PV + 5.1% 和 IPV + 6.2%。接下来我们聊聊在实现中遇到的问题和有趣的发现。
1. 快速序列搜索算法
minidetail 是今年对用户兴趣收束和探索的全新场景。相比于传统的推荐场景如首猜信息流,minidetail 的推荐受到主宝贝的影响,限制了可推荐的商品的类目宽度;相比于搜索场景,用户的意图不像搜索词一样明确。因此在这个场景里,与主宝贝同类目的商品点击率一定高,但是这并不意味着能够激发用户向下看的欲望。算法优化陷入了一种怪圈:CTR 模型的 AUC 越高,线上的 CTR 确实提升了,但是导致浏览深度和 PV 下降,整体的 IPV 反而降了。这意味着,即使主宝贝明确,也不意味着应该一直推同类目的商品,在其中穿插一些近邻类目的商品能缓解用户的疲劳度、有效激发用户的新兴趣。
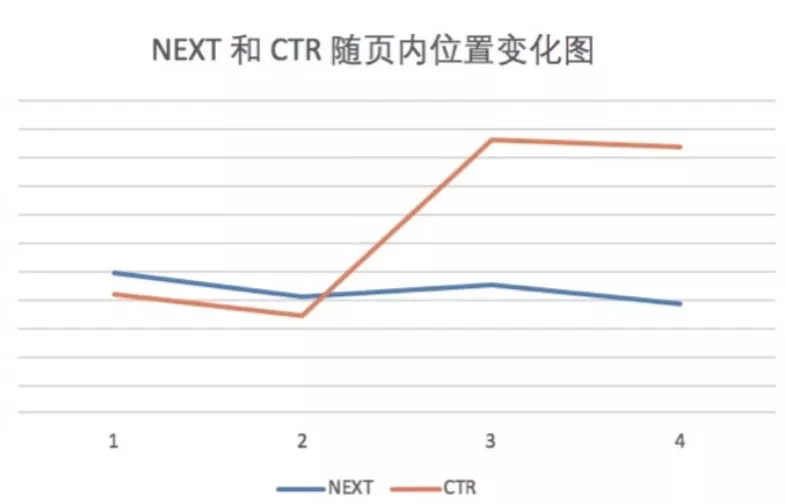
基于这个考虑,我们做了一个下拉模型,来预测用户在浏览商品时下拉持续浏览的概率。一开始,我们选择了将 NEXT 分和 CTR 分加权相乘的方式,但是并没有什么提升。其实这两分相乘并没有什么实际的物理意义,最终推荐序列可能会显得调性一样。在这之后我们从序列的整体角度去考虑这个问题,把 NEXT 分作为浏览中的传递曝光概率,希望能在 PV 和 IPV 之间取得一个平衡,并且通过系数去调节整体的预期序列收益。如图 12 所示,我们统计了线上全量方案每 4 个一分页的相对坑位和平均 NEXT 分和 CTR 分的趋势(为了量纲一致 CTR 分乘以了放大系数)。我们可以发现,这两分数的趋势都不是单调的,NEXT 分呈一个山行结构,CTR 分反而在后两坑更高。因此,让用户产生更多浏览的秘诀可能就在于让他有层次感的浏览体验,而不是一味地满足他的需求(这一点跟搜索有点类似,满足了他的需求用户就离开)。这样既能让用户产生交互的同时缓解疲劳,也留给算法足够的空间去探索用户潜在的兴趣点。
2. 生成式重排
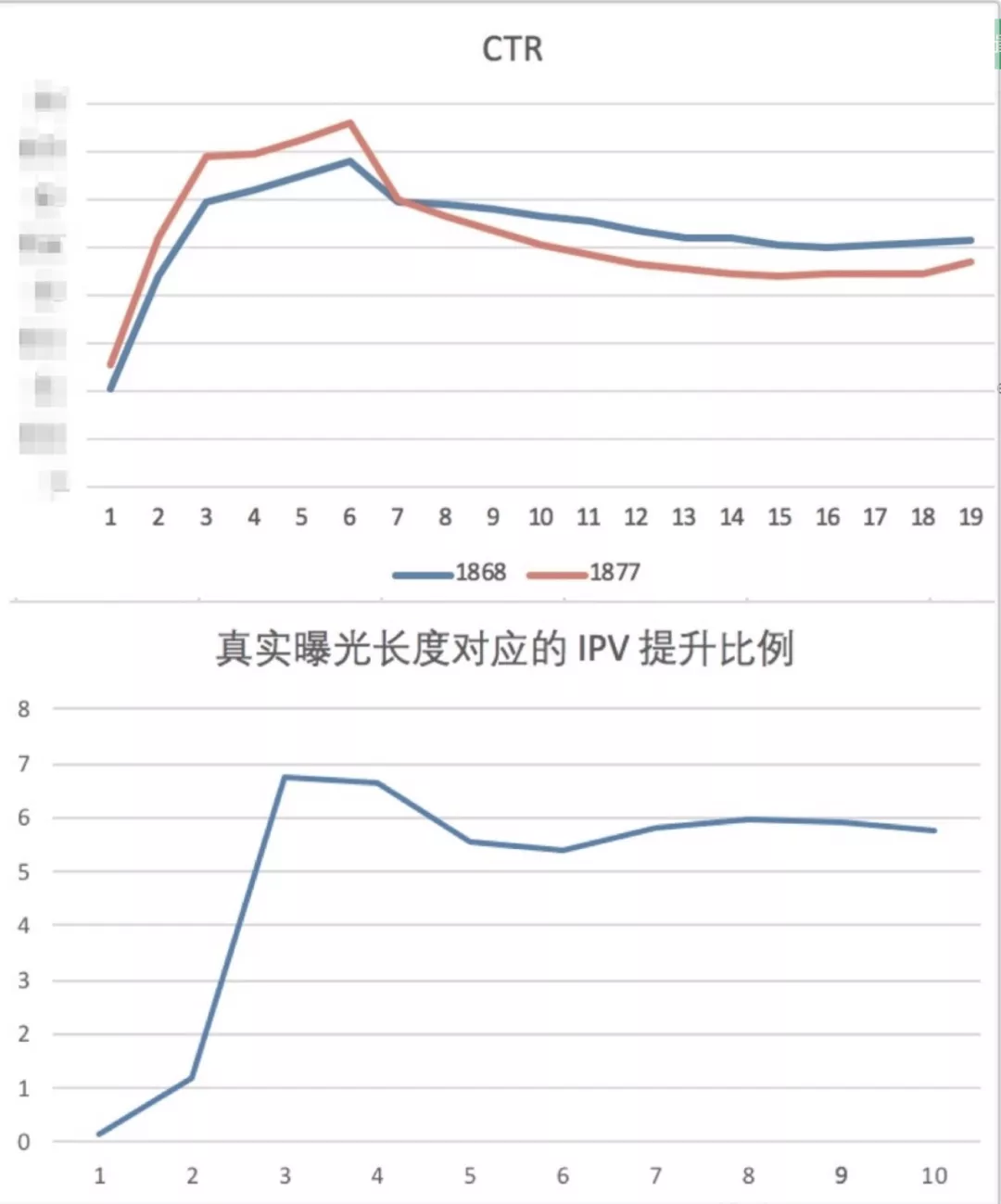
生成式重排是基于 Exact-K [16] 的延伸和落地工作,其最大的区别在于预估模型的升级:从预估整体收益到探索上下文关系。和 Exact-K 的目标场景不同,常规的推荐场景的一次推荐结果中用户很有可能会发生多次交互。在我们的实践里发现,直接预估整体收益是一件很困难的事情,拟合一个多值的结果会导致模型训练过程极不稳定。因此才有了现在的 Evaluator,利用上下文信息来预估每个位置的收益,合并起来作为序列的整体收益;还有一个困扰我们的问题是,我们的样本里,用户实际浏览的序列(真实曝光)往往是不定长的,这种长度其实也是个穿越信息,因为在线上的实际 inference 的时候,我们并不能知道用户将最终会看几个。第一版,我们筛选出最终推荐序列长度为 10 的样本,离线指标 (LR)提升接近 16%,但是线上结果反而降了不少。如图 13 所示(橘色的是 base 桶),随着最终推荐序列长度逐渐提升,算法效果也逐渐提升,说明模型过于考虑了整体收益,反而导致了前面出的太差用户直接退出了。后来我们使用了全量的样本训练,并且加入了真实推荐序列长度的 mask,在训练和评价过程中使用才取得了不错的效果。如图 7 下所示,真实曝光长度较短时(1、2)提升不明显,此时上下文感知较弱,是否重排影响不大。当真实曝光长度提升时,IPV 提升幅度稳定在 6% 左右。
GRN 算法最大的问题在于如何上线。Generator 是一个依赖前序结果的多轮打分的算法,势必会造成高昂的通信成本(如果预估至少 5 ms 每次,线上 10 次打分整体将会消耗 50 ms)。基于这个问题,我们选择了在端计算中上线,相比于传统的云端架构,边缘计算支持更加复杂的模型结构和直接在内存进行计算交互的模式。通信成本的降低,同时我们实现了超时弥补的策略,才使得生成式重排最终成功落地。
3. 重排-排序
DCWN 模型利用了列表内的排列上下文信息,比原来的单点 CTR 预估模型预估地更加准确,基于该模型的 LR 指标能够直接对序列进行排序挑选。事实上,原来的 CTR 贪婪排序逻辑默认序列的收益为 Sum(CTR),LR 指标相当于利用上下文信息将整体收益预估地更加准确。如图 14 所示,我们计算了真实样本环境下两种预期收益和序列整体 IPV (Ground-truth)的皮尔逊系数,可以发现 LR 指标通过利用上下文信息,比 Sum(CTR) 与 Ground-truth 之间的相关性更大,说明其可以作为一个更加准确的序列排序指标使用。
引用
[1] Cao, Zhe, et al. "Learning to rank: from pairwise approach to listwise approach." Proceedings of the 24th international conference on Machine learning. 2007.[2] Burges, Chris, et al. "Learning to rank using gradient descent." Proceedings of the 22nd international conference on Machine learning. 2005.[3] Ai, Qingyao, et al. "Learning a deep listwise context model for ranking refinement." The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. 2018.[4] Pang, Liang, et al. "Setrank: Learning a permutation-invariant ranking model for information retrieval." Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. 2020.[5] Pei, Changhua, et al. "Personalized re-ranking for recommendation." Proceedings of the 13th ACM Conference on Recommender Systems. 2019.[6] Zhuang, Tao, Wenwu Ou, and Zhirong Wang. "Globally optimized mutual influence aware ranking in e-commerce search." arXiv preprint arXiv:1805.08524 (2018).[7] Gong, Yu, et al. "EdgeRec: Recommender System on Edge in Mobile Taobao." Proceedings of the 29th ACM International Conference on Information & Knowledge Management. 2020.[8] Covington, Paul, Jay Adams, and Emre Sargin. "Deep neural networks for youtube recommendations." Proceedings of the 10th ACM conference on recommender systems. 2016.[9] Cheng, Heng-Tze, et al. "Wide & deep learning for recommender systems." Proceedings of the 1st workshop on deep learning for recommender systems. 2016.[10] Guo, Huifeng, et al. "DeepFM: a factorization-machine based neural network for CTR prediction." arXiv preprint arXiv:1703.04247 (2017).[11] Sahoo, Doyen, et al. "Online deep learning: Learning deep neural networks on the fly." arXiv preprint arXiv:1711.03705 (2017).[12] Lee, Ching-Pei, and Chih-Jen Lin. "Large-scale linear ranksvm." Neural computation 26.4 (2014): 781-817.[13] Zheng, Zhaohui, et al. "A regression framework for learning ranking functions using relative relevance judgments." Proceedings of the 30th annual international ACM SIGIR conference on Research and development in information retrieval. 2007.[14] Burges, Christopher JC. "From ranknet to lambdarank to lambdamart: An overview." Learning 11.23-581 (2010): 81.[15] Bello, Irwan, et al. "Seq2slate: Re-ranking and slate optimization with rnns." arXiv preprint arXiv:1810.02019 (2018).[16] Gong, Yu, et al. "Exact-k recommendation via maximal clique optimization." Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2019.[17] Chen, Laming, Guoxin Zhang, and Eric Zhou. "Fast greedy map inference for determinantal point process to improve recommendation diversity." Advances in Neural Information Processing Systems. 2018.[18] Gelada, Carles, et al. "Deepmdp: Learning continuous latent space models for representation learning." arXiv preprint arXiv:1906.02736 (2019).[19] Gogna, Anupriya, and Angshul Majumdar. "Balancing accuracy and diversity in recommendations using matrix completion framework." Knowledge-Based Systems 125 (2017): 83-95.[20] Wilhelm, Mark, et al. "Practical diversified recommendations on youtube with determinantal point processes." Proceedings of the 27th ACM International Conference on Information and Knowledge Management. 2018.[21] Mnih, Volodymyr, et al. "Asynchronous methods for deep reinforcement learning." International conference on machine learning. 2016.[22] Schulman, John, et al. "High-dimensional continuous control using generalized advantage estimation." arXiv preprint arXiv:1506.02438 (2015).[23] Schulman, John, et al. "Proximal policy optimization algorithms." arXiv preprint arXiv:1707.06347 (2017).文章转载自:DataFunTalk(ID:datafuntalk)
原文链接:序列检索系统在淘宝首页信息流重排中的实践




