
一位来自遥远星系的旅行外星人是 Instagram 的狂热用户。她的Instagram订阅推送(Feed)主要包括:
朋友和家人的帖子
一些太空旅行杂志
一些常规新闻账户
许多科幻博客
她登录后轻轻地滚动浏览自己的推送动态信息——与朋友和家人保持联系,关注银河系的常规新闻,有时还会花点时间来看一个有趣的科幻短篇故事。
追完之后,她会切换到“探索”选项卡。她也喜欢这个选项卡。这对她来说是惊喜与喜悦的完美结合。她花了相当多的时间来参与内容互动。但是,每隔一段时间,她偶尔会有一个“啊哈”令人惊叹的时刻。她找到了一个她真正想要关注的账户。今天,她找到了一本她希望每天都能更新的小众太空旅行杂志。这种关注行为增加了她动态信息中的内容量,并且由于这些内容更加个性化,她觉得它们更有价值。
这个以及许多其他此类典型的用户故事启发我们提出如下的问题:
用户花费大量的时间来为自己打造完美的主页信息流。我们如何为他们做一些工作,让他们觉得这些建议是他们自己制定的?
有趣的是,那些沉浸其中的用户会不断地寻找新的兴趣源。我们可以在这种渐进式的个性化行为中提供一些帮助吗?
主页信息流排名系统(Home Feed Ranking System)根据用户粘性、相关性和新鲜度等因素对来自你关注源的帖子进行排名。探索排名系统(Explore Ranking System)是另一个极端,它为你打开了许多其他与你相关且吸引你的公开帖子。我们是否可以找到一个中间点,设计一个排名系统,让你看到那些不是你关注的账号的帖子,同时又觉得这些帖子是你自己制作的呢?
2020 年 8 月,我们在 Instagram 上推出了 Suggested Posts 来实现这一目标,目前这些帖子显示在你的订阅信息流的末尾。下文将介绍我们是如何设计这种熟悉与探索相关结合系统的。
设计原则
在我们深入研究机器学习系统的细节之前,有必要说明一下设计原则,这些原则将像北极星一样指引着我们前进。“感觉像主页一样。”(“Feels Like Home”)这意味着,滚动到推荐末尾的感觉应该像是滚动到 Instagram Home Feed 的延续一样。
系统概述
典型的信息检索系统设计分两步:候选生成和候选选择。在第一步的候选生成中,根据用户的显式或隐式兴趣,我们提取用户可能感兴趣的所有候选项。这是一个重召回的阶段。在第二阶段的候选选择中,通常使用权重更重的排序算法来对这些候选项进行排序,并选择最终显示给用户的最佳子集。在实际系统中,这两个阶段又可以分为许多子系统,以便更好地进行设计和控制。基于这种理解,我们准备深入研究 Suggested Posts 排名系统的设计。
下面的流程图显示了连接推荐系统与未连接推荐系统之间的主要区别。在连接推荐系统中,如 Instagram Home Feed 或一些流行的基于订阅的新闻阅读器,源是由最终用户明确定义的。排名系统会挑选这些源提供最佳帖子,并根据用户粘性、相关性、用户兴趣、内容质量和新鲜度等因素对其进行排名。在未连接的系统中(如 Suggested Posts),源是基于用户在 Instagram 上的活动隐式推导出来的,然后再根据类似因素进行排名。

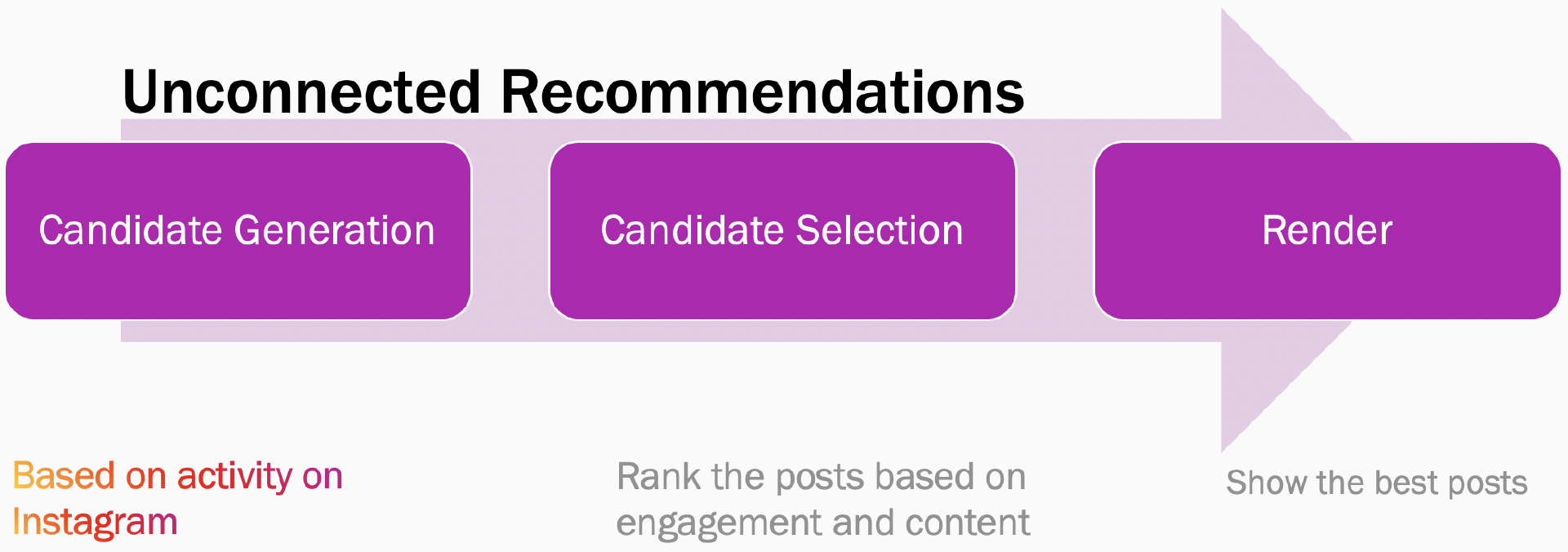
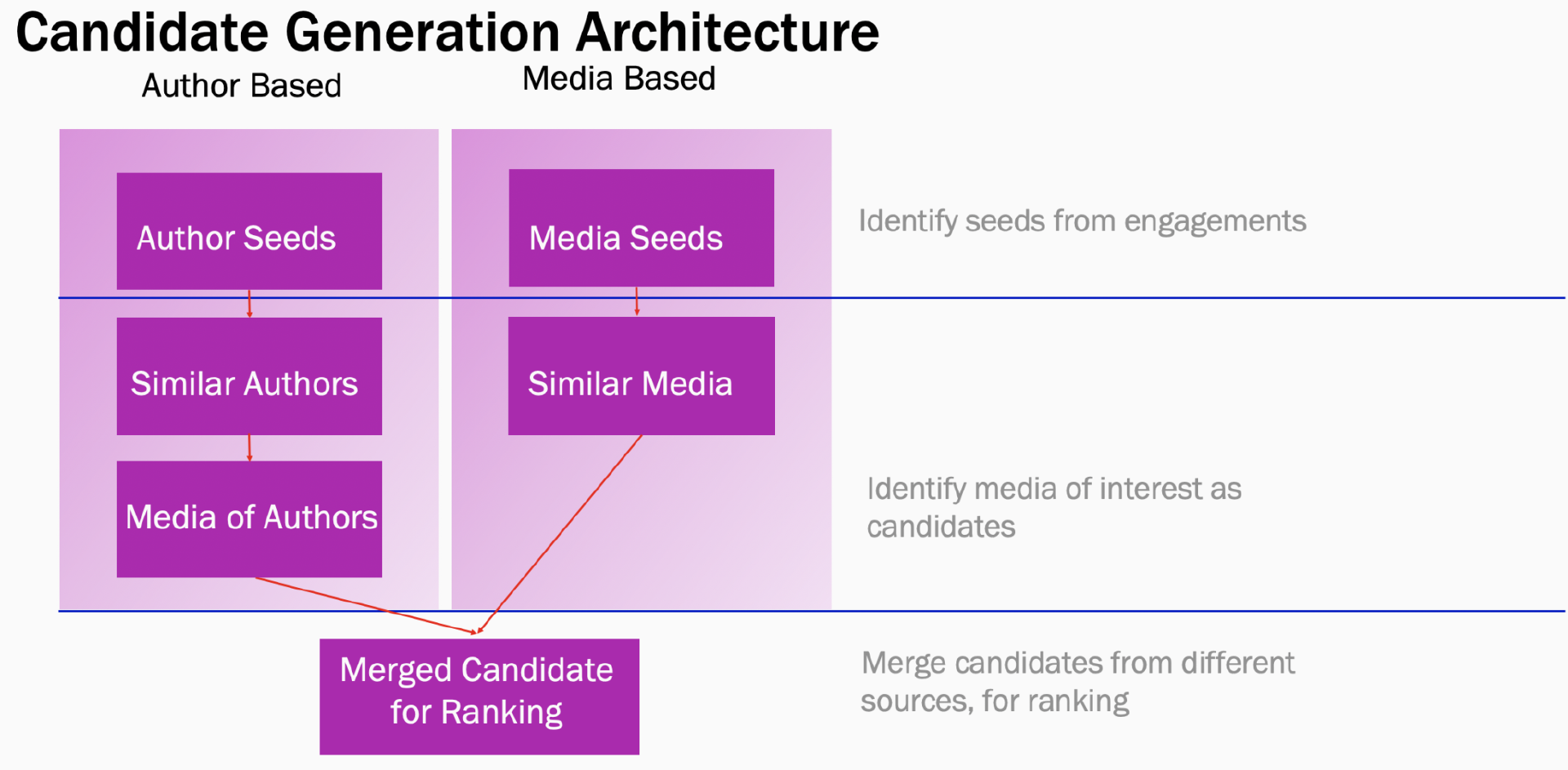
候选生成
假设我们的旅行外星人关注了一本科技杂志,该杂志专注于宇宙飞船的设计。她经常点赞他们的内容和评论。这就给我们提供了一个暗示信息,她可能对该类型的科技杂志感兴趣。按照这一思路,我们可以根据用户粘性和相关性通过算法来枚举所有此类兴趣候选项。
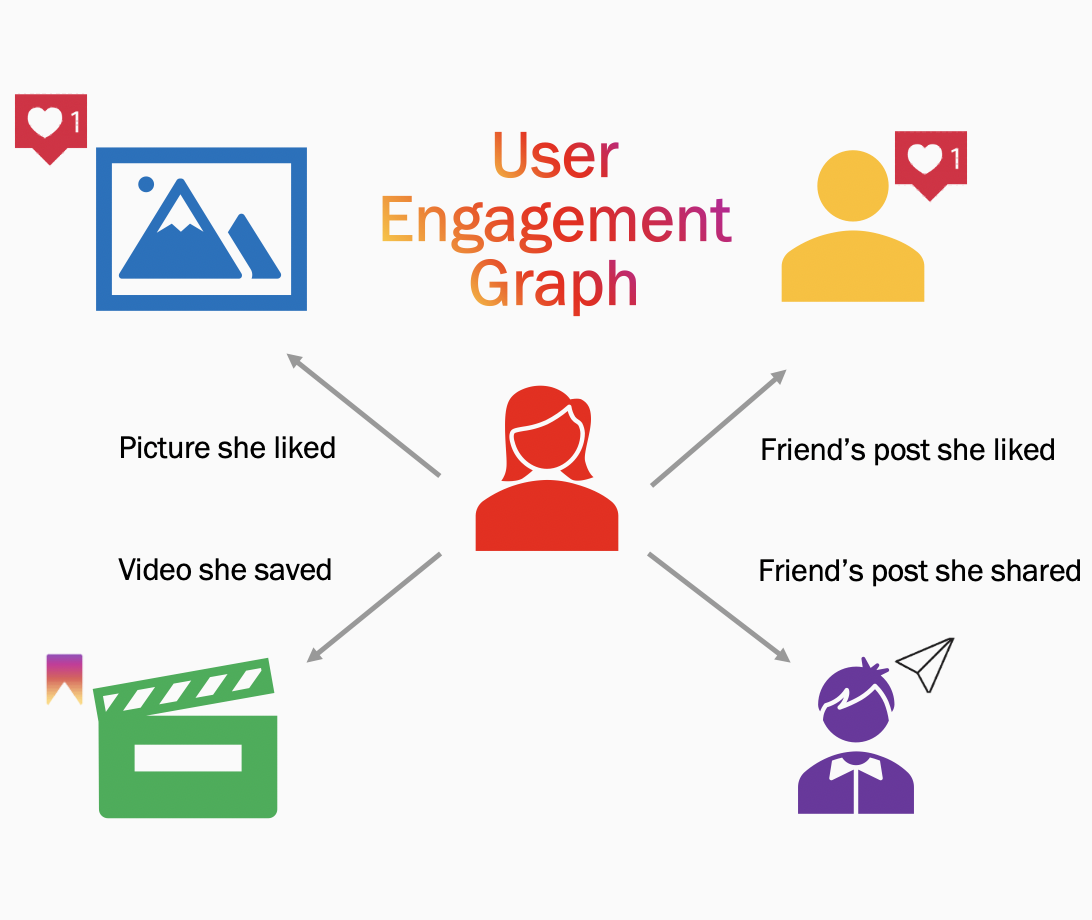
让我们更深入地钻研下。用户在 Instagram 上的活动可以帮助我们构建他们的虚拟兴趣图,如下图所示。在该图中的每个节点现在都可以是一颗潜在的“种子”。“种子”是指一个人对某个作者或媒体已经表现出的明确兴趣。现在,每个种子都可以用作 K-最近邻(K-nearest neighbor,KNN)管道的输入,这些管道会输出相似的媒体或相似的作者。这些 KNN 管道是基于以下两个经典的 ML 原则的:
基于 Embeddings 的相似性:我们使用用户粘性数据来构建账户嵌入。这有助于我们找到在主题和话题上彼此相似的账户。我们像学习词嵌入(Word Embeddings)那样学习了账户嵌入。词嵌入是一个单词的向量表示,通过从单词出现的上下文中以及跨语料库的句子中学习而来。类似地,通过将用户与之交互的各种帐户/媒体视为句子中的一系列单词来学习帐户嵌入,比如,假设某个用户点赞了他们最好的朋友(BFF)的自拍。然后,我们可以通过在向量空间中找到最近的帐户来找到这个与种子最相似的帐户。
基于 Co-occurrence 的相似性:这种相似性方法是基于频繁模式挖掘(Frequent Pattern Mining)思想的。首先,我们通过使用用户媒体交互数据生成共现媒体列表(例如:我们的旅行外星人点赞了科幻和宇宙飞船的帖子)。然后,我们计算媒体对的共现频率(例如:宇宙飞船的帖子和科幻小说的帖子共现)。最后,我们聚合、排序并获取共同出现的前 N 个媒体,作为我们对给定种子的推荐。
我们在 Instagram 上开发了一种查询语言,用于快速原型搜索查询(参考请看这里)。这导致在设计和测试新的高质量源时能进行高速迭代。下面是一个示例查询:
user.let(seed_id=user_id).liked(max_num_to_retrieve=30).account_nn(embedding_config=default).posted_media(max_media_per_account=10).filter(non_recommendable_model_threshold=0.2).rank(ranking_model=default).diversify_by(seed_id, method=round_robin)
冷启动问题
许多新用户(以及一些经验丰富的用户)可能最近在 Instagram 上的粘性不够,无法为他们生成足够大的候选列表。这将我们带到了处理推荐系统冷启动问题的熟悉状况中。我们用以下两种方法来解决这个问题。
回退图探索(Fallback graph exploration):对于即时粘性图相对稀疏的用户,我们通过评估他们的单跳和双跳连接来为他们生成候选项。示例:如果用户 A 没有点赞很多其他帐户,我们可能会评估 A 点赞的帐户所关注的帐户,并考虑将其用作种子。A→ A 点赞的帐户→A 点赞的帐户所关注的账号(种子账户)。下图形象化了这一思路。
大众媒体:对于非常新的用户,我们通常让他们从大众媒体项开始,然后根据他们的初始响应调整我们的参数。
候选选择
我们根据用户粘性和厌恶的许多因素对给定的帖子进行排名,这些因素在我们的排名管道中起着标签的作用。这些因素包括积极的用户粘性因素,如点赞、评论和收藏;以及负面的因素,如不感兴趣和很少看此类帖子。我们将学习到的这些标签的概率组合应用在用户价值模型中,该模型是如下形式的对数线性模型。
Value(Post) = (probability_like)^weight_like * (1- probability_not_interested)^weight_see_less
权重通过 a)用户会话的离线回放和 b)在线贝叶斯优化来进行调整。随着系统的发展,我们会经常调整这些因素和权重。
就模型类的选择而言,我们使用逐点分类算法来最小化交叉熵的损失:
MTML(Multi Task Multi Label Sparse Neural Nets,多任务多标签稀疏神经网络):多个标签是用户粘性行为,如点赞、收藏。
GBDT(Gradient Boosted Decision Trees,梯度提升决策树)
我们还使用基于列表会话的算法,如 LambdaRank,它可以直接最小化NDCG的损失。
在训练、离线回放和在线 A/B 实验期间,经常会调整整体架构和超参。此外,根据任务,我们还会在必要时试验多级排序和蒸馏模型。
我们使用了大量的特征来使我们的模型变得越来越智能和高效。下面列出了其中的一些:
用户粘性特征
基于作者-观众交互的特征
基于作者和媒体的计数器或趋势的特征
基于内容质量的特征
基于图像或视频理解的特征
基于知识的特征
派生功能特征
基于内容理解的特征
用户嵌入
内容聚合嵌入
基于内容分类的特征
上面的列表只是一个快照,既不完整也不全面。我们使用适当的选择机制和 A/B 实验来根据需要添加或删除更多的特征。我们通过频繁地将模型校准为正态分布来确保模型输出的分布鲁棒性。
感觉像主页一样
现在,我们将注意力转向我们的主要产品原则的实施:“感觉像主页一样”(“Feels Like Home”)。以下是我们采取的一些步骤,以确保建议帖子感觉像是 Home Feed 的延续一样。
Instagram 有许多推荐界面(Home-主页、Explore-探索、Reels-卷轴、Shopping-购物等),我们可以在所有界面上找到用户的种子帐户。我们将从主页中收到的种子帐户表示为 H,从其他界面收到的种子账户表示为 R。将从任何其他备份机制(如个性化图形探索)收到的种子账号表示为 F。为了确保我们的推荐感觉与 Home Feed 中的帖子相似,我们将对与用户在主页中遇到的账户相似的账户进行优先排序。最终合并顺序如下:H>>R>F。我们还使用作者嵌入来衡量和调优推荐帐户和主页帐户的相似性。
在训练和评估排名模型的候选选择这一步中,我们确保整体分布不会偏离基于主页的源。
我们遵循与 Home Feed 相同的新鲜度和时间敏感性启发方法,以确保建议帖子提供与 Home Feed 其他部分类似的新鲜感。
我们还确保在主页和建议帖子中混合的媒体类型(如照片/视频/相册等)相对来说是相似的。
最后,我们从用户体验研究人员和用户调查中获得定期的定性指导。它们为我们的策略提供了信息和指导,确保在建议帖子中有主页的感觉。
原文链接:
https://engineering.fb.com/2022/08/12/web/how-instagram-suggests-new-content




