
乾象投资 Metabit Trading 成立于 2018 年,是一家以人工智能为核心的科技型量化投资公司。核心成员毕业于 Stanford、CMU、清北等高校。目前,管理规模已突破 30 亿元人民币。
Metabit 非常重视基础平台的建设,有一支强大的 Research Infrastructure 团队。团队试图打破在单机上进行研发的壁垒,利用云计算进行更高效、安全的工具链研发。
01 量化的研究都在做什么
作为一家成立时间不久的量化投资机构,我们在对基础存储平台进行选型时,会受到这样两方面的因素的影响:公司成立的时间比较短,没有太多技术上的历史负担,在做技术选择时,更偏向于使用更现代的技术栈;同时,量化投资中使用到的机器学习场景中的特性也会影响到技术的选择。
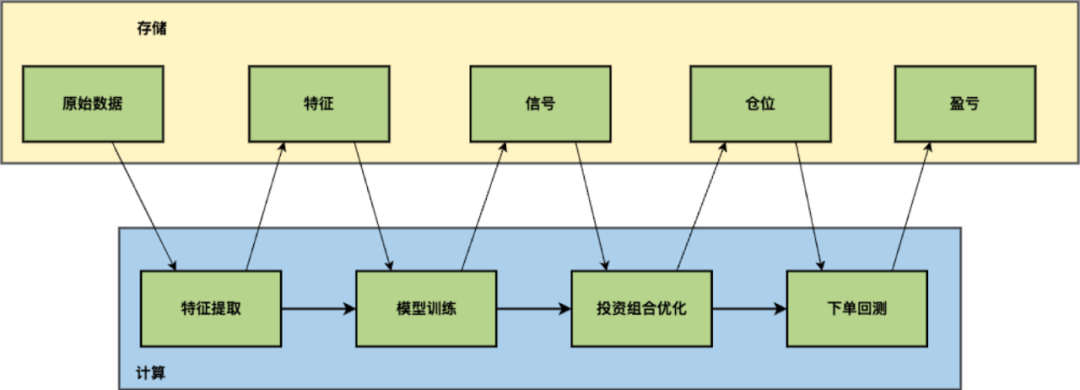
上图是我们研究场景中和机器学习关联最紧密的策略研究模式的简化示意图。首先,在模型训练之前需要对原始数据做特征提取。金融数据的信噪比特别低,如果直接使用原始的数据进行训练,得到的模型噪音会非常大。原始数据除了行情数据,即大家经常会看到的市场上的股价、交易量之类的数据,也包括一些非量价的数据,比如研报、财报、新闻、社交媒体等之类的非结构化数据,研究人员会通过一系列的变换提取出特征,再进行 AI 模型训练。
模型训练会产出模型以及信号,信号是对未来价格趋势的判断;信号的强度意味着策略导向性的强度。量化研究员会根据这些信息去优化投资组合,从而形成交易的实时仓位。这个过程中会考虑横向维度(股票)的信息来进行风险控制,例如某一行业的股票不要过度持仓。当仓位策略形成之后,量化研究员会去模拟下单,而后得到实时仓位对应的盈亏信息,从而了解到这个策略的收益表现,以上就是一个量化研究的完整流程。
量化研究业务特点
研究需求产生大量突发任务:高弹性
在策略研究的过程中,量化研究员会产生策略想法,他们会通过实验去验证自己的想法。伴随着研究人员新想法的出现,计算平台就会产生大量的突发任务,因此我们对计算的弹性伸缩能力的要求很高。
研究任务多样化:灵活性
从上面的例子可以看到,整个流程涵盖了非常多不同的计算任务,例如:
特征提取,时序数据上的计算;
模型训练,经典的机器学习的模型训练场景;
投资组合优化,会涉及到最优化问题的任务;
策略回测,读入行情的数据,再对策略的表现去做模拟撮合,得到仓位对应的表现。
整个过程任务的种类是非常多样化的,对计算的要求也很不一样。
研究内容需要保护:模块化,隔离
研究员的投研内容是公司的重要 IP(知识产权)。为了保护这些知识产权,公司的研究平台会将每个策略研究环节抽象成包含标准输入输出和评价方式的模块。例如对模型的研究,输入标准的特征值,输出预测的信号和模型。通过对模块之间进行隔离,研究平台可以有效保护 IP 的安全性。在进行存储平台建设时,需要针对模块化这个需求做相应的设计。
量化研究数据特点
大量任务的输入来自于相同的数据,比如上文提到的回测,量化研究员需要对历史策略去做大量的回测,同样的仓位使用不同的参数去测试,观察它们表现;或者特征提取,经常有一些基础特征和新特征的组合,其中大量的数据是来自于相同的数据源。
以 A 股的股票为例:A 股市场十年的分钟 K 线历史行情,5000/2 股票 240 分钟 250 天 10 年 8 字节*20 列=240GB,整体 10 年的数据量大约是 240G。
如果使用更细力度的数据,数据量就会更大,一般来说原始数据不会超过 100TB 的范围。在大数据时代这算不上是特别大的数据量,但是当大量的计算任务去同时去访问这些数据,这种场景就对数据存储的有一些要求。
另外,量化投研过程中伴随着大量的突发任务,研究团队希望能将这些任务的结果存储起来,因此会产生大量 archive 数据,但这些数据的访问频率很低。
量化研究计算任务特点
基于以上特点,如果以传统的机房方式,是很难去满足我们的计算需求,因此把计算搬到云计算平台对我们来讲是一个相对合适的技术选择。
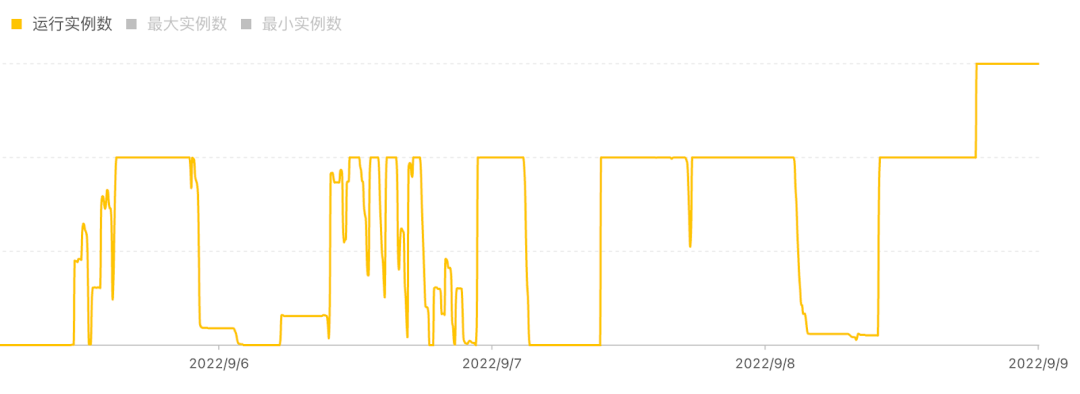
第一,突发任务多,弹性非常大。上图是我们某个集群近期的运行实例数据。可以看到在多个时间段里,整个集群实例都是被打满的状态,但是同时整个计算集群的规模也会有 scale 到 0 的时候。量化机构的计算任务和研究员的研发的进度是有很大关联的,波峰波谷的差距会非常大,这也是离线研究任务的特点。
第二,“技术爆炸”,很难准确预估何时会产生算力需求。“技术爆炸”是科幻小说《三体》的概念,对应到我们这就是我们的研究模式和算力的需求会发生飞跃式进步,我们很难准确预估算力需求的变化。我们在 2020 年年初的时候,研究的实际用量和预估用量都非常小,但是当研究团队提出的一些新的研究方法思路之后,会在某个瞬间突然对算力产生非常大的需求。而容量规划是在建设传统机房的规划时候非常重要的一件事情。
第三,现代 AI 生态,几乎是搭载在云原生平台上的。我们做了很多创新的技术尝试,包括现在非常流行的 MLOps,将整套 pipeline 串联起来,再去做机器学习训练的流水线;现在很多的分布式的训练任务的支持,都是面向云原生去做了很多的开发工作,这也使得我们把整个计算任务放到云上成为一个很自然的选择。
02 量化平台存储需求
根据上面业务和计算的需求,可以比较容易的去推导出来我们对存储平台的需求。
计算与存储不均衡。上文提到计算任务会有很大的突增,计算量会很容易会达到非常高的水平。而热数据的增长量并没有那么快,这就意味着我们需要去做存算分离。
为热数据,比如行情的数据,提供高吞吐的访问。上百个任务同时访问数据,对它吞吐要求非常高。
为冷数据提供低成本存储。量化研究需要大量 archive 数据,也要为这些数据提供相对低成本的存储。
文件类型/需求多样性即 POSIX 兼容性。我们有很多不同的计算任务,这些计算任务对文件的类型的需求是非常多样的,例如 CSV、Parquet 等,有一些研究场景还有更灵活的定制开发的需求,这就意味着在选型的时候不能够对文件存储方式做严格限制,因此 POSIX 的兼容性对于存储平台选型是一个很关键的考量因素。
IP 保护:数据共享与数据隔离。我们 IP 保护的需求,不仅是计算任务上需要做这样的隔离,在数据上也是需要支持这样的隔离能力;同时对行情数据这类相对公开的数据,还需要支持研究员的获取方式是便捷的。
AI 生态,在云的平台上去做各种任务的调度。这也是较为基础的一个使用需求,因此存储上也是需要对 Kubernetes 做很好的支持。
模块化即中间结果存储/传输。计算任务模块化的场景,导致我们会对中间结果的存储跟传输也有需求。举个简单的例子,在特征计算过程中会生成比较大量的特征数据,这些数据会立刻用于被训练的节点上,我们需要一个中间存储介质去做缓存。
03 存储方案选型
非 POSIX 兼容方案
最初,我们尝试了很多对象存储的方案,也就是非 POSIX 的方案。对象存储有很强的扩容能力,而且成本非常的低,但是对象存储的问题也很明显。最大的问题就是没有 POSIX 兼容性。对象存储的使用方式跟文件系统有比较大的区别,如果把对象存储直接作为接口面向研究员,对他们来讲使用有很大的难度,便利性也有很大的限制。
除此之外,很多云厂商的对象存储有请求限制。例如,阿里云会对整个帐号的 OSS 带宽做限制。对于普通的业务场景这通常是可以接受的,但是突发性任务会在瞬时产生非常大的带宽需求,仅仅使用对象存储很难去支撑这类场景。
另一个方案是 HDFS ,我们在 HDFS 上面并没有做太多测试。首先,我们所采用的技术栈对 Hadoop 没有太强的依赖;同时, HDFS 对 AI 训练的产品的支持并没有特别突出,而且 HDFS 没有完整的 POSIX 兼容性,这对我们的使用场景会有一些限制。

云上 POSIX 兼容方案
上文中提到的业务特点决定了我们对 POSIX 兼容性有很强的需求,而且技术平台是基于公有云来进行的,因而我们将存储选型的范围确定为:云上兼容 POSIX。
云厂商会提供一些方案,比如像阿里云的 NAS,AWS EFS 之类;另外一类是像阿里云的 CPFS 方案,AWS 的 FSx 方案。这两类文件系统的吞吐是与容量强绑定的,当容量越大的时候,吞吐会越大,跟 NAS 的存储性质是直接相关的。这样的方案,在面对小量的热数据的时候不太友好,需要额外的优化才能达到比较好的表现。另外 CPFS 或者阿里云上的极速型 NAS,对低延时的读取很友好,但缺点是成本比较高。
就各自官网展示的价格,我们做了个对比。各类高性能 NAS 产品的成本大概是 1500-2000 元/TB/月,JuiceFS 整体的成本会低很多,因为 JuiceFS 的底层存储是对象存储 。JuiceFS 的成本分成这样几个部分:对象存储的存储费用;JuiceFS 云服务的费用;以及 SSD 缓存产生的成本。综合来看,JuiceFS 的整体成本远低于 NAS 和其他方案的成本。
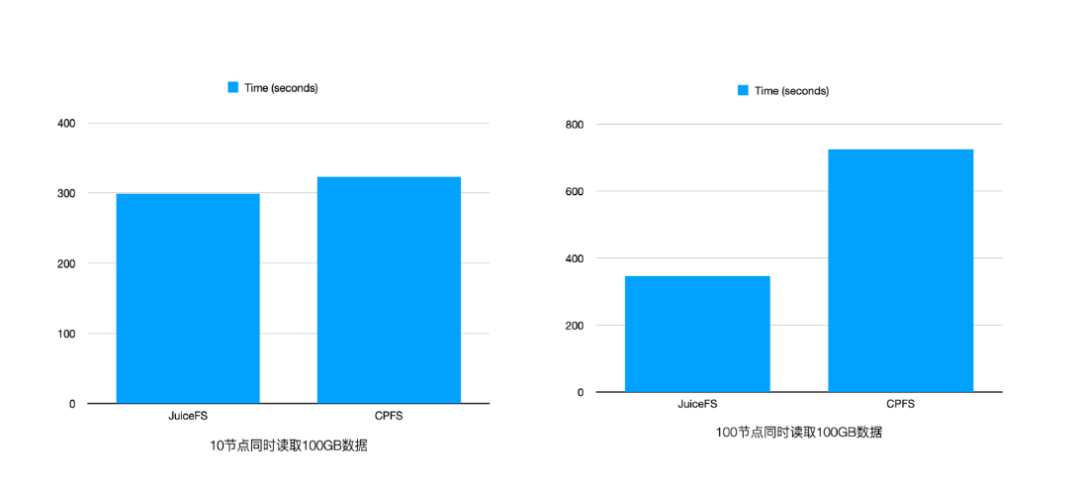
在吞吐方面,早期做了一些测试,当节点数量比较少的时候,直接用 CPFS 跟做 JuiceF 对比,同时读取性能不会有很大的差异。但是当节点数变大之后,因为 NAS 类文件系统有带宽限制,读取时间整体都拉长了,而 JuiceFS 只要做好缓存集群的部署,可以非常轻松的支撑下来,并且没有太大的开销,下图场景是部署了总带宽约为 300Gb 左右的集群。
除了成本和吞吐以外,在技术选型时, JuiceFS 对上文提到的功能 Full POSIX、权限控制、Qos、Kubernetes 都能够比较好的支持;
值得一提的是JuiceFS 的缓存集群能力,它能够实现灵活的缓存加速。最开始时,我们使用计算节点做本地缓存,这是一个挺常见的做法。存算分离之后,希望计算节点有一些数据可以本地化,JuiceFS 这方面功能的支持是比较完善的,对于空间的占用、百分比的限制等都做得很完善。我们部署了独立的缓存集群去服务一些热数据,只要在使用之前去做缓存预热就可以了。在使用过程中,我们发现不同的计算集群资源的利用率差别很大,集群中有一些大带宽的机器,大部分时候都是用来做单节点的计算,这也就意味着机器的网络的资源基本上是没有怎么用到,而且还有一些闲置的磁盘,因此就在这些机器上去部署了缓存节点,把闲置的网络带宽给利用了起来。最终使得我们在同一个集群中,实现了一个带宽非常大的缓存集群。
目前 ,JuiceFS 被用在了以下生产场景:
计算任务的文件系统,应用于热数据输入;
日志/ artifact 输出;
Pipeline 数据中转:数据特征生成之后,需要中转到模型训练中,训练过程中也会有数据中转的需求,Fluid+ JuiceFS Runtime 作为中间的缓存集群来使用。
未来,我们将继续探索云原生、AI 技术,用以进行更高效、安全的工具链研发和基础技术平台建设。
作者简介:
李健弘, Metabit Trading- Engineering manager of Research infra,专注于在量化研究领域搭建机器学习平台和高性能计算平台。在加入 Metabit Trading 之前,曾在 Facebook 担任高级工程师。




