
如果各位朋友还没试过 Rust,这里建议您——赶紧去试!还没用过 Rust cat、grep 和 find?不开玩笑,“一试倾心”说的就是 Rust。
太忙了,没时间?不行,这事特别重要,一定要用 Rust 把原有代码资产重写一遍!
一次重写,终身受益。你的系统将更快、更安全!
上面的描述是不是感觉有些熟悉?没错,最近一段时间,“用 Rust 重写”正在以传销般的方式席卷整个开发领域。据说当前因内存缺陷引发的浏览器和内核漏洞占比高达 60% 到 70%,于是系统开发者们越来越倾向选择内存安全语言,更具体地讲,转向 Rust。
这是因为 Rust 承诺又快又安全,能针对低级系统实现必要的抽象类型,包括与操作系统的交互、底层内存管理和并发性等。这些天然优势再辅以生态工具支持,共同让 Rust 发展壮大,成为亚马逊和谷歌等科技大厂的宠儿。
诚然,Rust 有不少独特优势,但它的类型也着实令人头痛。一旦搞错,我们就得被迫退回到 C,反而失去了重写想要追求的结果。
用 Rust 重写的问题
很多朋友并不清楚,单纯用内存安全语言重写大型 C/C++ 系统组件只会引入额外的攻击面:新组件和现有代码间的外部函数接口(FFI)。实际上,与 Rust 交互会让情况变得更糟。这里考虑以下 C 函数代码:
1 void add_twice(int *a, int *b) {2 *a += *b;3 *a += *b;4 }这部分有点奇怪,它会对整型指针就地执行算术运算,所以我们才希望把它重写为更安全的 Rust 形式:
#[no_mangle]pub extern "C"fn add_twice(a: &mut i32, b: &i32) {4 *a += *b;5 *a += *b;6 }但遗憾的是,Rust 和 C 对于其中的 a 和 b 分别做出了不同假设,而且从 C 调用 add_twice(&bar, &bar) 会导致未定义行为。这是因为 Rust 编译器会将 add_twice 优化成 a += 2*b。(在 Rust 中,a 和 b 不允许存在别名)。另外,这种优化会引入新的内存不安全错误。如果 C 程序使用 add_twice 来更新内存相关数据(例如将缓冲区的大小加倍 2 次),则“安全”Rust 函数其实比原本的“不安全”C 函数更糟糕。
这个例子之所以值得关注,是因为原始 C 代码和 Rust 代码都通过了各自的编译器,没有任何报错。然而,C 和 Rust 代码联合体静默调用了未定义的行为,结合具体的架构、Rust 版本和 LLVM 版本,这有可能引发内存安全问题。
在实践当中,这个问题不涉及人为因素,而且很难加以预防。
从本质上讲,Rust 和 C/C++ 是不能直接交互的——它们在类型、内存管理和控制流方面都采取了截然不同的方法。结果就是,如果手动编写“胶水”代码,就很可能打破隐式假设(例如调用约定和数据表示)、关键不变量(例如内存和类型安全、同步和资源处理协议),并跨过语言边界引入未定义的行为错误,例如展开恐慌(unwinding panics)、整型表示错误、为枚举和标记的联合体类型静默创建无效值等。
其实这个问题不仅困扰 Rust,FFI 是出了名的棘手且极易引发错误,即使 Rust 也难以将其“驯服”。这种不安全性其实不可避免,而且开发者目前缺乏编写安全 FFI 的基础性技术和工具,因此贸然使用 Rust 重写代码可能会引入新的错误和漏洞。
下面,我们将着眼于现实场景下用 Rust 重写大型 C/C++ 系统组件的案例,并聊聊开发者在编写 FFI 代码时可能引入哪些新的类型错误和问题。
Rust 和 C 间的不匹配,往往导致 FFI 边界处出现大量不安全代码——这令开发者很难安全将组件移植为 Rust 形式。更要命的是,哪怕是精通 Rust 和 Modula 3 系统架构的开发者,也几乎无法回避这些麻烦。
当然,Rust 绝不是不能用,也有像𝑅³这类细化类型系统扩展 Rust FFI 的边界,两者相结合足以消除验证工具所带来的各种规范和证明负担,同时几乎解决了 FFI 错误,真正让 Rust 发挥其内存安全优势。
具体有哪些安全问题
在本节中,我们将具体探讨在实际场景下将 C/C++ 组件移植至 Rust 所引发的安全漏洞。因为我们主要关注 FFI 层的 bug,所以暂不讨论 C/C++ 代码中那些不影响移植代码的原始 bug。换言之,我们假定原始代码本身符合内存安全要求,只考虑两段代码间 FFI 层处可能出现的内存不安全和未定义行为。
我们假定开发者是出于善意而移植代码,只是因移植 bug 而将格式错误或 bug 传递给了 FFI,例如指针和缓冲区长度的不正确值。由于 C/C++ 程序和 Rust 库之间会共享内存,所以对于来自 Rust 库的此类输入的任何不正确处理,都可能在整个程序中引发内存安全错误。
我们分析了两个网络协议库的 Rust 实现,分别为 TLS 库 rusTLS 和 HTTP 库 Hyper,以及二者的 FFI。这些库及其 C 绑定都处于活跃开发状态,目前已被集成在 Curl 当中,完全可以作为 C-Rust FFI 的理想研究案例。我们还考虑了其他一些项目:Encoding_C,一个编码标准的 Rust 实现,用于取代 Firefox 中的 C++ 实现;Ockam,一个安全的端到端通信库;Artichoke,Ruby 语言的 Rust 实现;以及 Rust 语言团队发现的其他一些核心挑战。
我们将本节内的问题划分成以下几类:首先是内存时空安全;其次是异常问题中的一类常见错误——跨 FFI 边界展开堆栈属于未定义行为,因此可能构成难以察觉的严重故障;第三是类型安全和 Rust 关键不变量相关的错误,包括别名、指针安全假设和引用可变性。最后,我们还将讨论其他几类未定义行为。
时空安全问题
Rust、C 和 C++ 采用的内存管理方法存在着本质区别。Rust 的类型系统会静态跟踪对象的生命周期和所有权,C 语言要求程序员手动管理内存,而 C++ 虽然提供内存安全抽象,但也允许自由将其与原始指针加以混合。
更重要的是,在将 C/C++ 系统迁移至 Rust 时,开发者必须通过 FFI 层来协调这些差异,其困难程度可见一斑。例如,跨 FFI 边界共享指针会引发跨语言内存管理问题,其中一种语言分配的指针会被另一种语言所释放。而当 C 和 Rust 代码试图共享内存所有权时,情况将变得更为复杂。
rusTLS 允许客户端创建证书验证器,并在服务器配置间共享这些验证器。为了实现共享,rusTLS 会使用原子引用计数器(Arc)来表示这些验证器,以便在不再引用验证器时自动回收相应的内存。
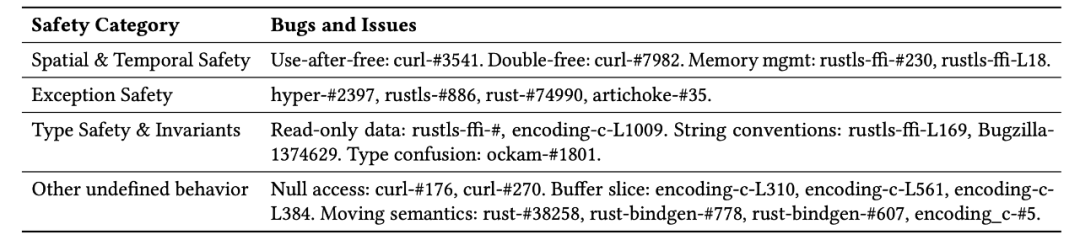
C/C++ 与 Rust 交互时可能引发的几种内存安问题类型
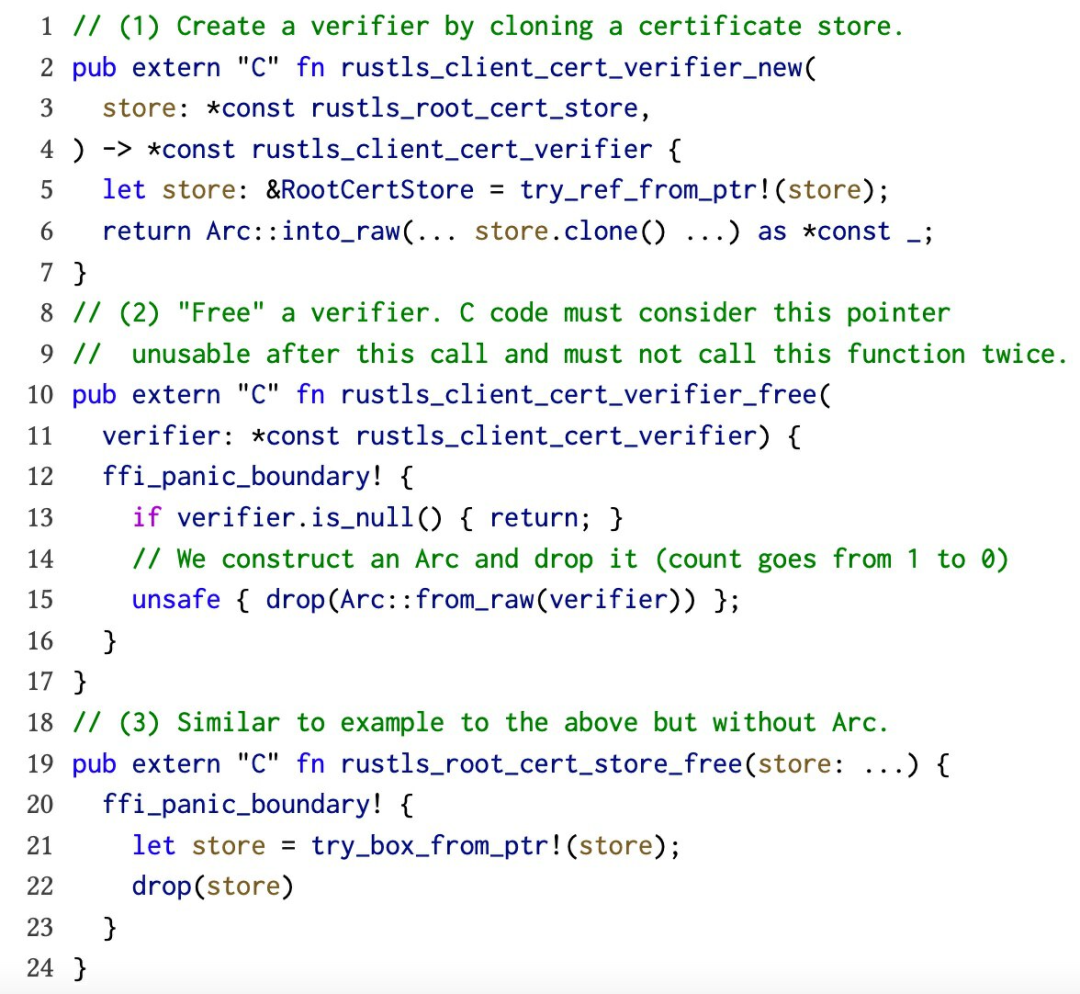
图一:rusTLS FFI 函数中的安全问题示例。异常安全:(1)如果克隆操作耗尽内存,则可引发跨 FFI 边界展开。时间安全:(2)和(3)可能因不正确的函数参数或重复函数调用而导致 use-after-free 和 double-fee 错误。
因为 rusTLS 会通过其 FFI 公开指向这些对象的指针,所以需要过图一中的 rustls_client_cert_verifier_free 函数将其显式弃用。该函数会以不安全方式从原始指针重建 Arc 引用并立即将其删除,从而减少引用计数。更重要的是,这个函数的期望计数为 1(即调用方的副本),所以如果使用得当,这个函数应该会同时删除指针引用的对象。但调用方可能会滥用该函数,例如两次释放同一指针或重新使用释放过的指针,因此导致引用计数错误,最终在 rusTLS 本应“安全”的部分引入 double-free 和 use-after-free 漏洞。
目前 rusTLS 还无法检测到 double-free:读取“freed”Arc 引用的计数会首先触发未定义行为 [rustls-#32]。此外,TLS 库的 C 实现不一定会依靠特定 API 来释放这些对象(及其引用的对象),而可能仅要求客户端使用标准的 free 函数。在系统直接用 rusTLS 替换此类 C 实现,很容易引发跨语言内存损坏并在系统中引入新的内存漏洞。
异常安全
Rust 会通过展开堆栈并在过程中调用析构函数(destructor)的方式来处理不可恢复的错误(通常用 panic! 宏或者任意数量的 panicing 函数调用来表示,例如 unwrap 或整数加法)。请注意,跨 FFI 边界的展示会被认定为未定义行为。
尽管目前 Rust 社区还存在争论,但 FFI 确实应明确处理恐慌(panic)以保证异常安全——理想情况下,应将故障告知调用方。但 Rust 并未为此提供任何特殊支持,因此实际效果完全取决于开发者是否在代码中强制执行安全保障。
例如,rusTLS 会通过 ffi_panic_boundary! 宏打包易出错的顶级外部(参见图一),它会捕捉一切展开的 panic 并将默认值返回给调用方。由于 Rust 中的许多基础操作都可能引发崩溃,因此极易错误必要的处理过程。至于显式 bug,请注意图一中的 rustls_client_cert_verifier_new 并不属于异常安全,因为对 RootCertStore 的克隆可能会触发未经处理的内存不足 panic 并跨 FFI 展开。
Rust 不变量与类型安全
Rust 代码往往高度依赖类型系统所保证的不变量,借此确保内存安全和代码正确性。由于 C/C++ 程序通常不遵循相同的不变量,因此 C/C++ 在与 Rust 代码交互时可能引发冲突,这类问题在重写后尤其多见。
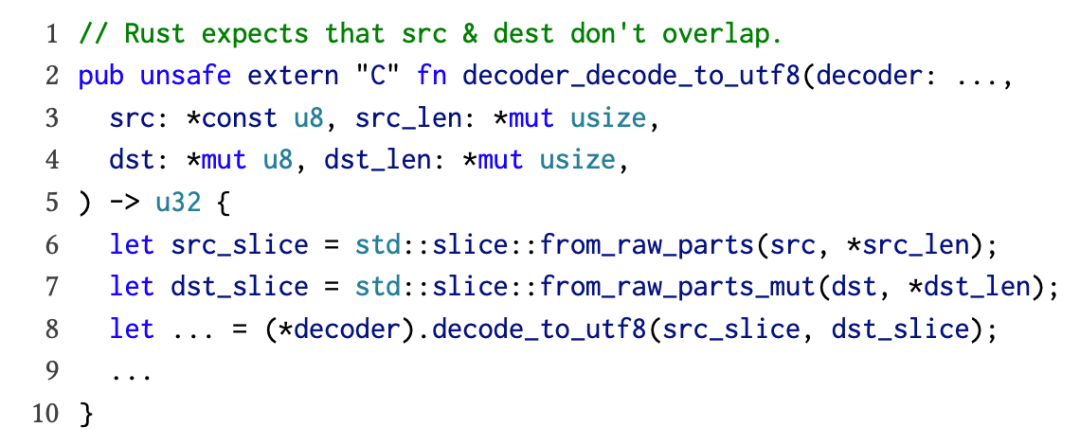
图二:来自 encoding_c 库的 FFI 函数可能受到无别名违规的影响。Rust 要求 src_slice 和 dest_slice 不能有码名,但代码本身不会对此做检查。
函数 decode_to (参见图二)将不可变切片(immutable slice)的内容解码成了可变切片(mutable slice)。Rust 别名规则将确保这些切片没有别名,从而实现编译优化。但通过不安全函数 fram_raw_parts 和 from_raw_parts_mu 重建切片时,decoder_decode_to_utf8 不会检查或保障这些条件。打包器会使用与 C 兼容的等效类型(指原始指针及其长度等效)替换缓冲区切片,从而导致类型别名。这可能引发 Rust FFI 中的未定义行为和 LLVM 的不合理优化。
其他未定义行为
还有其他一些更加“玄幻”的未定义行为,主要涉及不同语言的细节和架构 ABI(应用程序二进制接口)的特殊约定。
胶水代码。以上讨论示例中的一个常见问题,就是胶水代码需要使用不安全的 API 来重构 Rust 抽象。不安全函数的存在,导致安全责任从编译器被转移给了开发者,需要独立于应用程序之外重新设计这些接口,从而满足接口内必须包含的关键假设。然而,大多数此类假设(例如指针的生命周期、所有权和边界等)都无法在运行时上验证,Rust 也不提供检查所需的构造函数,因此 FFI 函数会以隐含方式信任调用方并假设输入有效。但这种信任明显站不住脚:FFI 代表着安全 Rust 组件同抽象 / 不受信代码间的边界。因此,调用方代码完全有可能传递无效输入并轻松击溃 Rust 的安全保障。这不仅令 Rust 重写丧失了安全保护意义,也给跨语言攻击创造了理想条件。
ABI 兼容性。ABI 级优化同样可能在 C/C++/Rust 系统中引发问题,其中各组件是使用不同编译器和可能互不兼容的优化方式进行编译的。以 64 位架构为例,编译器可能将连续的 32 位函数参数打包进同一个 64 位寄存器内,借此减少寄存器压力。然而,如果相应的编译器不是以相同的方式打包函数输入,则跨语言函数调用可能会引发未定义行为。例如,虽然 C 的 size_t 和 Rust 的 u32 类型都是 32 位,但只有 C 编译器能同时对二者打包、rustc 就不行。
结束语
总之,随着 Rust 代码的日益普及,其他语言与 Rust 之间的交互也将同时创造新的攻击面,而目前我们手动编写的 Rust FFI 代码极易引入内存安全漏洞。期待能有好的方法和工具来帮助开发人员编写出安全的 FFI 代码,真正兑现 Rust 语言做出的安全保证和承诺。
原文链接:
https://goto.ucsd.edu/~rjhala/hotos-ffi.pdf
声明:本文为 InfoQ 翻译,未经许可禁止转载。
好文推荐
连代码都没写就敢要融资:被ChatGPT带火的向量数据库,带来了一大波造富神话
《2023 大语言模型综合能力测评报告》出炉:以文心一言为代表的国内产品即将冲出重围




