—他们都说学生医就业难,真是鬼扯。
—就是嘛,你看各行各业都有学生医的。
命运从回答开发者社区的问题时开始改变
2013 年一月的某天,我在网上回答一个关于贝塔分布的问题来消磨时间。那个问题是在Cross Validated 上发布的,而Cross Validated 是Stack Overflow 开发者问答平台的姊妹网站。那时候,我已经是Stack Overflow 上一个活跃了大概一年时间的答主了,在Cross Validated 倒是没那么活跃。
那时候我有一个非常有趣的想法,可以用棒球运动的统计数据来解释贝塔分布。

那次回答对我个人职业生涯的影响而言,是一件最让我感到幸福的事。
在Stack Overflow 的一年
6 月 16 日是我在 Stack Overflow 担任“数据科学家”的一周年纪念日。
在获得博士学位的大约一个月之前,我加入了 Stack Overflow。对我来说,加入一个科技公司可是个相当大的变化。就在那早前几个月,我还打算留在学术研究界,专门研究计算生物学。我都已经开始申请博士后奖学金了,从来没想过要去应聘一个“行业”职位。
是什么让我改变了主意?一切都要从 Jason Punyon 找到了我关于贝塔分布的回答开始说起,那时这个回答都发布两年了。
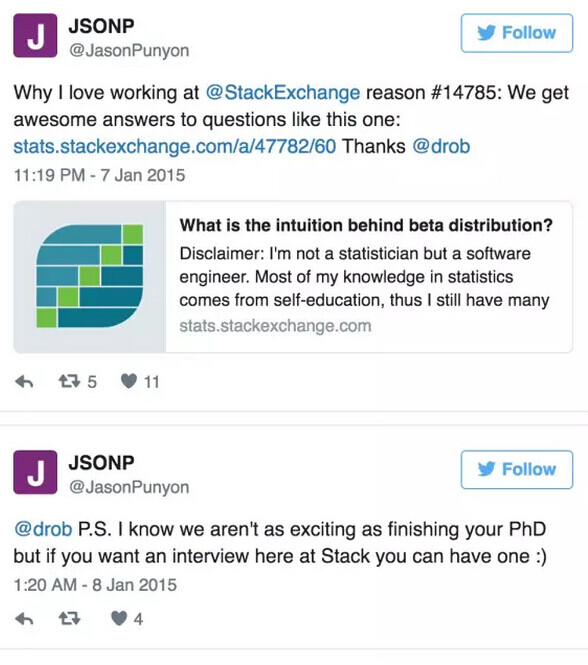
当时我非常确信自己会进入学术界,但我也不想错过拜访 Stack Exchange 办公室的机会,认识一些这个产品背后人们。我只去了一次他们的办公室,就改变了自己之前的想法,又过了几周的面试后,我得到了这份工作并签了合同。
作为数据科学家所做的事情
人们了解网络开发者的工作,但是“数据科学家”是做什么的呢?(我可不是唯一一个被这么问的人。)
下面这些并不是我做的全部项目,但它们应该可以解释我整天在忙的事儿。
设计、开发和测试机器学习功能
我们的产品中最有代表性的使用了机器学习的例子就是 Providence,它是一个把用户和他们感兴趣的工作机会匹配到一起的系统。(举例来说,如果你在 Stack Overflow 上浏览的大部分问题都和 Python、JavaScript 有关,你将会收到 Python 网络开发工作的广告。)
我在数据团队里和工程师们一起工作(包括 Kevin Montrose,Jason Punyon 和 Nick Larsen),设计、改进和执行机器学习算法。比如,我们在努力平衡工作机会的地理位置和用户在技术上的匹配度,确保用户能看到多样化的工作机会,而不是反复看到同样的工作。
这项工作主要包括设计和分析 A/B 测试,尤其是优化我们的目标算法、广告设计和其他促进点击率(CTR)的因素。它在统计方面的乐趣远超我的预期,有些情况下,我还能找到做生物实验时使用方法论的新用法,还有些情况下,它能鼓励我去学习新的统计工具。事实上,我那个把贝叶斯方法应用到棒球击球量统计数据的系列论述,就是我之后用来分析广告点击率方法的简化版本。
一些很酷的工作
我已经不是个学术科学家了,但这并不意味着我对由数据勾勒出结论这件事不感兴趣。Stack Overflow 能够鸟瞰整个软件开发生态系统——几百万计的问题、用户和日访问量。我们能从这些数据中学到些什么呢?
对初学者来说,光是看看那些“标签”如何同时使用,我们就能发现技术的天然集群:
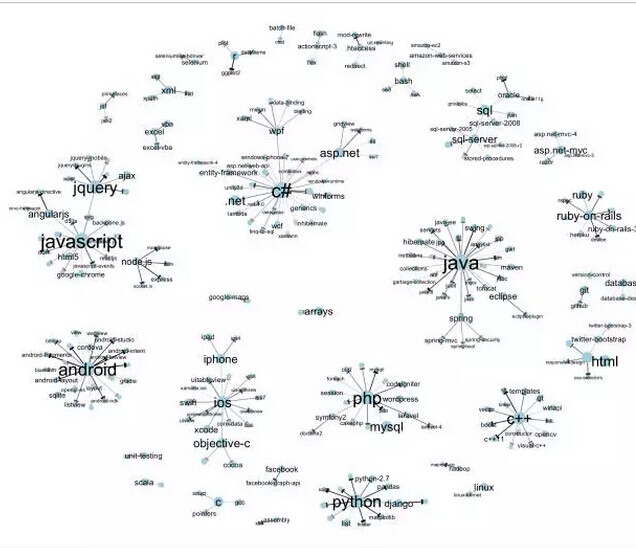
这能让我们自动把框架和软件包分类到它们所属的上一层级语言和集群中,完全不用手动注释。
然而,它只是向我们展示了标签如何在特定的编程问题中同时出现,并不是它们如何在同一项目中被使用。(举个例子,C#和 SQL Server 可能不总是同时出现在一个提问里,但它们经常会被用于同一技术堆栈的某部分。)鉴于此,我大概就会观察一下另一个数据源,Stack Overflow Careers 的数据图表,看看哪些技术倾向于被同一批开发者使用。
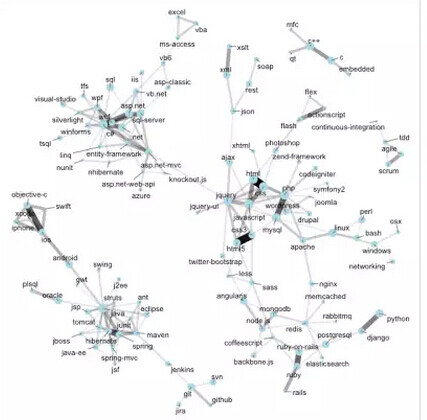
标签不是仅仅严格被类别所划分,而是被“技术生态系统”所划分的,我喜欢这个过程。这种理解模式也不局限于编程技术领域。Stack Exchange 网络包含了大量的问答站,通过观察哪些社区倾向拥有同类活跃的用户,我们同样可以建立起网站内部相互关联的网络。
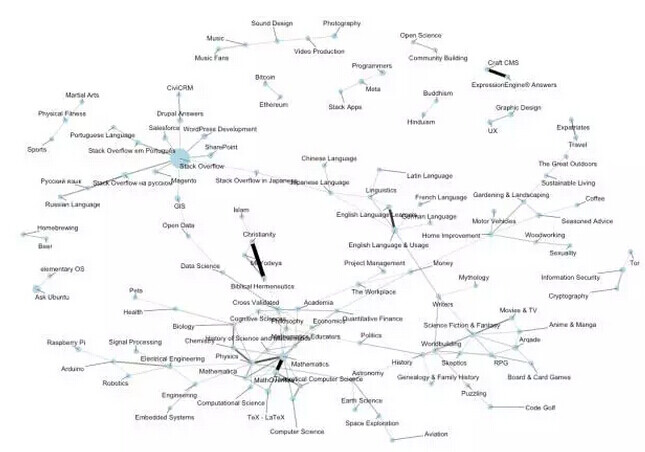
(并不是说我做的事情全都是网络相关,只是这些例子初看起来比较有趣。)
为什么要花时间来分析这些呢?因为有时候它们真的能直接影响产品功能。举例来说,在数量上掌握技术集群,能让我们改进开发者类型的模型,而这个模型会驱动 Providence 的目标。从商业的角度来说,不同角度的洞见也非常有价值。我曾和销售部、市场部以及社区团队一起工作,帮助他们解读数据、做出决策。
但本质上来说,我还是尤其对学习并“视觉化”这类信息感兴趣,这是这份工作的乐趣之一。我在这里的第二年,我的一个计划就是公开分享更多这类分析。在之前的一篇博文里,我分享了“哪些技术是最两极分化的”,我期待着很快能做更多这样的分享。
开发数据科学的体系框架(R 语言内部数据包)
我喜欢用 R 语言来学习数据中有趣的东西,但长期目标是让任何一个工程师都能轻易做到这件事。我刚进 Stack Overflow 的时候,是公司里第一个用 R 语言的人,但随后的一年它就传开了。R 语言的确是一个很棒的直接处理数据和回答有趣问题的工具。(当聪明的软件工程师们打开 Excel 做线形图的时候,我真是伤感啊!)
为了达到这个目标,我就专注于构建可靠的工具和框架,好让人们能应用到各种各样的问题上,而不是做个“一次性”的分析脚本。(这里是 StitchFix 的 Jeff Magnusson 发表的一篇很棒的博文,讲述了一些普遍意义上的难题。)
我的办法是建立 R 语言内部数据包,就像 AirBnb 的策略那样(虽然我们的数据团队比他们的团队年轻一些,体量也小些)。这些内部的数据包能查询数据库,并从句法上分析内部的 API,包括向用户隐藏各种安全和基础设施方面的问题。
这就牵涉到了建立一门 R 语言辅导课和撰写“入门”的材料。举例来讲,我开过一门公开课,介绍查询数据库的内部 sqlstackr 包。这门课变本加厉成了一个总体的 dplyr/tidyr/ggplot2 介绍,我发觉它比连接开发者与 dplyr 的总览辅导更有用处(因为它肯定是我同事们更感兴趣的东西)。
我的愿望是,随着数据团队的成长和更多工程师掌握了 R 语言,这个囊括了数据包和指南的生态系统能成长为真正的内部数据科学平台。
学术和行业
下面是一个流行的“数据科学家”的定义:
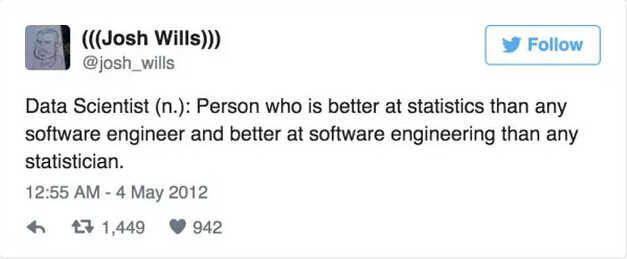
(Josh Wills:数据科学家,是那些比软件工程师更擅长统计学,并且比统计学家更擅长软件工程的人。)
这个版本的解释表述得很让人信服,但值得指出的是,它的反面也是正确的:在读研究生的时候,关于统计学,我比我们实验室里的其他人知道得更少;而在我的新工作中,关于软件工程,我比我的同事们知道得更少。所以,到底是怎么变成这样的?
多了解统计学
有相当多激动人心的文章,讲述“程序员需要学习统计学”。我的确比我的同事们拥有更多统计学上的经验和训练(也是他们当中第一个拥有博士学位的人)。但它并不是我工作中的障碍。
首先,我注意到这个差距在很多重要的领域正在缩小。我认识的那些进行 A/B 测试的开发者,已经意识到“P 值操纵”的入侵和多种假说测试的危险了,他们同样意识到了影响力大小和置信区间的重要性。数据团队尤其做了很多努力。差距缩小更多的是花时间习惯这样一些台词,“使用泊松分布,不要用线性回归”,或者“知道什么时候用对数尺度”。
更重要的是,我发现当我提出统计学问题的时候,开发者们非常乐意倾听和学习,我感觉目前为止,已经建立起了相互信任的工作关系。下面是我经历的一个案例,它确实没有反映出“程序员需要学习统计学”那篇文章的观点,那篇文章把开发者描述得就像一群盲目自大狂。考虑到有可能我们团队是个不同寻常地有效率的工程部门(我听说过其他公司有很差劲的事儿!),但也有可能在过去的六年里,软件开发行业的态度已经改变了,而统计学的重要性被更广泛地得到认可。
我怀念研究院时光的一个方面,就是从他人身上学习统计学。我那时被一些比自己渊博得多的人围绕,在实验室会议或者研讨会上,我接触到了大量有用的统计学理论和方法。如果我犯了错,还能指望着其他人帮忙指出。而目前,我大部分的统计学教育必须是自我驱动的了,我必须对工作非常谨慎。如果我在一个报告里使用了不恰当的统计学假设,其他人就不太可能指出。
不要畏惧软件工程
在很长一段时间里,我都非常在意编程工作,常年用 GitHub 为开源 Python 和 R 语言项目做贡献,但为一个科技公司工作,的确代表了某种转变。我是个终生的 Mac 用户,并且在过去的几年里完全用 R 语言工作。
Stack Overflow 建立在微软的技术基础上,尤其是 C#、ASP.NET 和 SQL Server,在我入职前没有人用过 R 语言。我并非坚持要挑起一场使用某种语言的战争,但说到这些改变对我意味着什么,我当然会感到紧张。
事实上这也不是什么障碍,尤其是当我发现自己能在 Mac 上用 R 语言为公司做不少贡献的时候。我把很多贡献归功于 RSQLServer 和 jTDSdriver 的开发者,多亏了他们我才能轻松地通过 RStudio 查询数据库。我有一个 Parallels 虚拟机窗口,上面的 Visual Studio 永远打开着,但我发现大多数时间我都不再需要用它了。
我现在有时候会直接把代码推到产品上(通常是和广告定向体验相关的),但那也没造成什么矛盾。和我的同事们相比,我对很多软件工程领域所知甚少,包括前端网页设计和网站可靠性工程,但就像在其他任何一个公司一样,我最终还是免去了这些担忧。
其他的一些心得
离开生物学研究。这可能是最让我紧张的一个变动。整整八年(包括了大部分我本科学位的时间),我的研究一直聚焦在生物学。但仅仅花了几个月去做其他事,我就意识到了,坦承地说,我对生物学问题从来就没那么有热情。
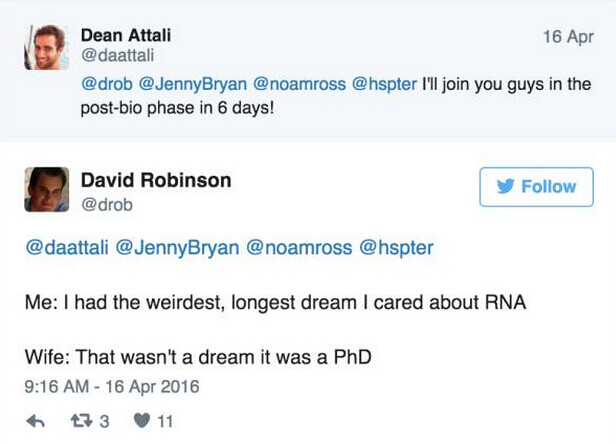
(Dean Attali:我还有六天就跟你们一样,进入“后生物学”阶段了!
David Robinson:
我:我有一个最狂野的、最长久的梦想——我真的在乎 RNA。
我妻子:那不是个梦想,那是个博士学位。)
生物学展现了很多有趣的计算和统计学问题,生物信息学里也有很多让人兴奋的工作。但当我完成一份生物分析的时候,我其实最终得到了一个我自己都没有学问或兴趣去阐释的结果。(过了那么多年,研究整体的酵母菌基因组,我能叫得上名字的基因还是屈指可数。)
相反,我是 Stack Overflow 的长期用户,而且对软件开发生态有普遍的兴趣,所以我把上述那些网络看做一个结果,我能分辨出它是否会立即发生作用。研究我确实感兴趣的数据,这感觉还是不一样的。
写作:这是一个被我低估了的优势。我在取得学位的过程中写了不少东西,大部分是期刊文章和学位论文,事实上,那种正式的语言是非常生硬的。而在过去的一年里,我大部分的写作都是用于内部的报告、记录或者博客文章,我得写得不那么正式和书面化。(来对比一下我写学位论文的语言和写博客的语言吧。)我现在尝试发表一些以前遗留的学术研究,但由于上述原因,让我转换回那种期刊文章的语言模式就很难。
跟我一起工作的同事
我笑点很奇怪,在大部分的推文里,我都会虚构一个叫“Dev”的角色作为搞笑的拍档,我们或者拿工程师文化开玩笑,或者拿我自己没经验开玩笑。

为了避免笑点不明显,每一条笑话推文都是纯粹瞎编的。首先,这些对话必须从未发生过。但更重要的是,他们不是跟我一起工作的开发者们的映射。公司里那些聪明的、有能力又细心的同事,是我在这儿工作最大的乐趣之一。
有非常多值得列出来讲的人(当然是全体数据和广告服务部成员),但我还是举几个例子吧。Jason Punyon 是最开始发现了我关于贝塔分布博文的那个开发者。Jason 是个优秀的工程师,在这儿工作了六年,他做出了大量有用的产品。让我印象很深的一个地方,就是他把关注数据和关注用户这两件事结合在了一起。
几个月前我做了个实验,实验表明,在工作广告中展示薪酬范围是有显著益处的,然后我把这个结果分享给公司内部。我只是很开心能分享些我得到的结论,而 Jason 拿到结果,并把它们转变成了行动,推送给所有员工(包括我们自己),要大家登记各自的薪酬信息。
他这样做是因为他很看重数据,把数据当做他决策的指南,而这个决策也为公司决策指明方向。他同样看重开发者们,把开发者当做我们产品的用户,当做普通人,并且认为他们值得预先获知薪酬信息。跟他一起工作我感到很自豪。
还有很多工程部以外的同事让我非常钦佩,我尤其高兴能和社区团队一起工作。举例来说,Taryn Pratt(外号蓝脚)比我早几个月加入团队。我在入职前曾为 Stack Overflow 社区做过点贡献,但跟 Taryn 比起来就不算什么了。她是个多年的活跃用户和主持者,答题数超过 3 500,编辑过 22 000 多条有用的信息!
虽然 Taryn 在公司不是开发者,但她却拥有出色的技术经验和技能(好多社区运营都是这样)。她把自己这些技能(尤其是 SQL)也运用到了 Stack Overflow 社区里。
在这个背景下,她最近还开始学 R 语言了,所以她能运用统计学的、数据驱动的方法,去分析和理解问答行为中的模式。在她和其他团队成员的帮助下,我非常兴奋地看到了数据科学为社区做出贡献。
给大家的建议:创造公开的作品,让别人知道你
在受雇于 Stack Overflow 后不久,我得知了 Jason 的推文背后的故事,那次决定去联系我的内部会议,最开始是个突发奇想。

我真的感到非常幸运能得到现在这份工作,看到上面这条推文后我更觉得幸运了。我受雇的经历可能太离奇了,不能从中提取出什么建议来。但如果我尝试给还没毕业的人一些建议,这就是我的想法:面向公众的工作并不是浪费时间。
当我还在研究生院的时候,我最在意的事情就是发表论文。在我的认知里,那才是成功取得学位的明证,也是唯一关乎我职业生涯的事情。我最终取得博士学位,仅仅发表了中等水平数量的论文。我很高兴我那么做了,但说实话,如果当时没发表那么多论文,或者根本没发论文,也很难说我的生活会有什么不同。
然而我明确地知道,我要是没发那篇贝塔分布的博客文章,我的生活会多么不一样,甚至如果我根本就没在 Stack Overflow 回答那个问题,又会是怎样。
发表期刊文章是创造社会价值的一个方式,但离下面这件事远得多:它们预估起来很缓慢,而且在提交之前,它们必须是“完美的”。我觉得有一种态度很危险,就是认为发期刊文章是唯一的公开自己研究的办法。因此很多学术领域很棒的研究,就会被忽略好几年或者就此销声匿迹,仅仅因为它不是篇真正的论文(当然我那些博客文章都不够资格提交为期刊论文)。
所以我想说,如果你有些特别有趣但又不像论文的东西,就把它当做博文发出来,或者当做 Stack Overflow 的回答写出来,再或者当成在 GitHub 上的开源项目。总之就是把它呈现出来!
就像我一开始说的那样,我很高兴自己回答了贝塔分布的问题。它给了我一个机会,用我编程方面的知识和产出去做一个产品。我最终得以跟这个产品的建造者们一起工作,而正是这些人至今仍持续让我感到钦佩。来到这里一年了,这是我所能期待的最棒的工作。
本文编译自: One year as a Data Scientist at Stack Overflow ,作者是 Stack Overflow 的数据科学家,主要使用 R 和 Python。InfoQ 获授权翻译,翻译编辑:张英洁。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




