
目的
人类文明的许多领域都能找到某种贯穿历史长河的“物种”。 它们古老而年轻——时光荏苒,不断进化,逐渐积累下最顽强、最富生命力的基因片段,并在更广袤的生态中繁衍,最终造就该领域令人叹为观止的多样性。 编译器就是计算机世界的这样一个物种,它将不同时代大师们的匠心融入自己的基因,并逐渐传递到数据库、分布式计算、自然语言应用、人脸 / 语音驱动等现代物种中,比如抽象语法树、中间代码、语义优化和版本化等等。
LLVM 将编译器的许多优秀机制模块化,人们可以根据自己的语言、处理器、运行平台等需要,为自身应用定制编译器,在恰当的时机,快速地获得高性能的编译结果(Bitcode),然后链接其他编译结果或库,获得性能、资源使用效率、兼容性兼备的可执行代码。
许多对 LLVM 的介绍偏重“使用”,比如 JIT 或如何编译控制 GPU 等虚机。但功能只是起步,匠心更显价值。用厂家或社区提供的 LLVM 编译器( Lua、Swift、CUDA 等等)实现产品后,如果进一步了解和改善内部优化分析机制,对代码效率精益求精,则更能体现软件人员的追求,追随大师们的脚步继续传承和创新。本文希望介绍一种对 LLVM 编译器 IR 和分析优化部分的改造,希望对从事这方面工作的朋友有所启发。例如对 LLVM 前端、分析和优化器可以进行哪些修改,需要考虑哪些问题?有哪些分析手段?如何在中间代码 IR 和控制流程图(Control Flow Graph) 层面进行修改?这里面的许多分析优化原理在《编译原理》(英文名 Compilers: Principles, techniques and tools)里有更详尽的描述。
并行编程
随着处理器从单核向多核进化,并行编程是加速数据处理和提升吞吐量的。如何在现有的非并行代码上快速修改,将计算负载高效地分布到多颗 CPU,充分利用多核,又能避免花费大量精力重写和维护不同平台的不同代码?
分叉- 合并(Fork-Join) 是主流编译器采用的一种并行化方法,通常用语言扩展(language extension) 支持,比如 Cilk Plus 、 OpenMP 等。一个程序可以分解成一系列小任务块,每个小任务块包括各自的一系列指令。互相不依赖的一组小任务块,即可考虑并行执行(分叉出一组并行的线程),然后通过合并(Join)同步,等所有进程结束后再往下运行。
具体如何实现呢?举个例子来讲:
#pragma omp for
for (int i = 0; i < N; ++i) {
dest[i] = a[i] + b[i] * c[i];
}
这个 for 循环里的 N 次加乘可以并行进行,由 N 个计算单元一次性完成。 而且不管谁先谁后,最终结果都是一样的。
实现起来非常简单:开发者可以通过 Cilk Plus 或 OpenMP 等的语言扩展,比如加上“#pragma omp for”,来表示这部分代码可以并行执行,主流的编译器 GCC、ICC、LLVM 等则会将这样的循环编译成并行执行。开发者无需关心执行细节,更无需将代码拆成可并行的任务以适应 TBB 之类的并行计算库。
同时,去掉#pragma omp for 后,程序将退化为串行执行,执行结果不会变化。因此,当测试和 Debug,或底层不支持并行,或编译器不支持时,可以忽略这些语言扩展关键字,程序仍会安全地编译,执行结果和并行一样,只是没有多线程多核的并行加速而已。这也叫“串行语义”(serial semantics)——确保程序必须能退化到串行执行,是 Cilk、OpenMP 等并行计算语言拓展的基本准则。
但这一编译和优化过程处理并行指令时,不甚完善。2017 年 2 月,麻省理工学院的计算机科学与人工智能实验室发表的对LLVM 编译器做的一系列改进,值得关注。
LLVM 编译器编译并行指令的缺陷
比如优化循环时,能看到 LLVM 并行化的一些缺陷。请看下面这个归一化函数:
__attribute__((const)) double norm(const double *A, int n);
void normalize(double *restrict out,
const double *restrict in, int n) {
for (int i = 0; i < n; ++i)
out[i] = in[i] / norm(in, n);
}
该函数将 in 数组归一化。比如,in 数组可以是各地的销售额,通过该函数转化成销售额的百分占比。(norm 函数可以看成计算销售额的总和)。
因为每次对 norm 的调用,都会产生同样的结果,不随 for 循环变化,所以在不考虑并行计算的情况下,编译器通常会将该结果的计算从 for 循环里搬到循环之前,仅需计算一次。这能将计算复杂度从) 降为, 这种优化也叫做循环无变化的代码移动 (LICM, “Loop Invariant Code Motion”),一种常见的编译器优化。
现在,考虑一下在多核处理器的情况下,能否通过并行执行加速?如果将第 06 行并行执行——将相应的 i 值和 norm 函数一起交给 n 个计算单元同时算,就可以将串行的 n 个周期缩短为并行的 1 个周期,速度应该大大提升。
实现起来也很容易,如前所述,只需要将 for 前面加上#pragma omp parallel for,或者将 for 换成 cilk_for。 支持 OpenMP 或 Cilk 的主流编译器,都可以轻松编译,实现并行计算。 这种并行循环的场景非常典型。
编译器同样应该进行“代码移动”优化,把 norm 函数搬到循环外先计算,以降低计算复杂度。但 GCC5.3.0、ICC16.0.3 和 Cilk Plus/LLVM3.9.0 都没有这么做。编译成并行运行,速度有时候比串行还差。在 AWS c4.8xLarge, 18 核,n=64M(循环 64M 次)上的运行结果如下:
- 未做并行处理:原程序运行时间:0.312 秒;
- 并行处理,18 核:将 for 换成 cilk_for,用 Cilk Plus/LLVM 版,运行 180.657 秒;
- 并行处理,1 核:运行 2600 秒!
- 并行处理,18 核:用 OpenMP,LLVM4.0,运行 0.205 秒,好一些,但不明显;
这些主流编译器都支持分叉 - 汇合的并行机制,但对并行部分的代码的优化,为什么反而不如对串行部分做得好?哪里出了问题?
LLVM 编译器
典型的 LLVM 编译器包括三大部分:前端(和实际编程语言相关),后端(和实际芯片或硬件平台相关)以及中间语言(Intermediate Representation)。下图分别是通用型、基于多核并行扩展 Cilk Plus 和基于 NVidia CUDA 的三种 C 语言编译器的 LLVM 结构。
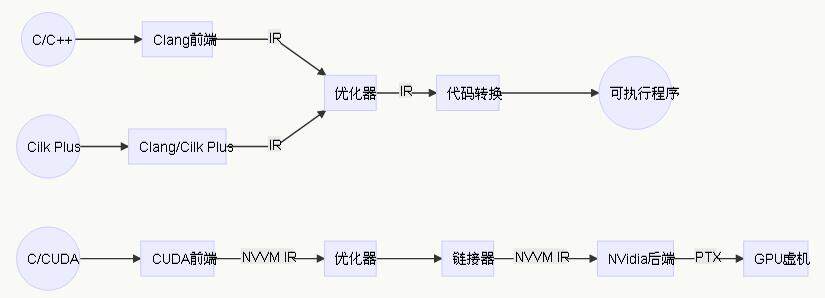
以第一种通用 C 编译器为例,前端负责类型检查和解析,将程序翻译成中间语言 IR(Intermediate Code),中间语言经过优化器,进行分析和优化的多次遍历,将 IR 转换得更高效。一般来说,这些优化不涉及最终执行的计算机指令集。最后,后端进行底层和机器相关的优化,将优化的 IR 转化为机器代码(在 CUDA 等架构下,最后转化为 PTX 这样的代码,用来控制底层虚机)。
问题
根据麻省理工学院 2017 年 2 月发表的一篇论文,问题可能出在这些编译器遇到可并行部分代码的标记时,是如何处理的。
比如,受前文提到的“串行语义”所限 ,要确保无论是串行或并行,执行结果都一样,GCC、ICC 和Cilk Plus/LLVM 都将并行部分的代码放在前端处理。让我们回到前面的归一化函数:前端看到cilk_for 的汇总- 分叉关键字,知道希望将这部分代码成并行执行,就会把第05-06 行的循环转换成两步:
1)第 06 行的循环执行内容被装进一个辅助函数。(Helper Function,把常用的计算或功能打包,以便多次调用);
2)第 05-06 行的循环本身,被替换成调用一个 Cilk Plus Runtime 库函数。循环的上下边界和辅助都作为这个 Runtime 库函数的参数。该函数负责把 n 次循环迭代转化为 n 个并行任务,同时执行。
问题是循环的内容被打包了,优化器针对循环优化的扫描看不到被打包的 norm 函数,也就无法采用代码移动(LICM)进行优化。通过对比归一化 PClang 可以看到:Cilk Plus 的并行化的编译,没做任何代码移动,所以执行速度比串行还慢。
OpenMP 采用的是同样的两步,不同的是,对辅助函数(Helper Function)内部进行了代码移动,即把 norm 函数放到循环之前计算。但并没有把 norm 函数搬到整个并行化之前,所以并行后每个核仍需要各自先算一遍 norm,仍然不是最佳优化方案。
所以,问题出在主流编译器“先解决并行化,再扫描和优化”的顺序不合理。遇到可并行处理部分的关键字时,就把他们作为语法糖( syntactic suger ) 过早地打包,等 Runtime 库函数调用执行。等优化器进行分析和优化时,要么看不到(Cilk Plus/LLVM),要么只能在语法糖的包内进行局部优化(OpenMP),都不够彻底。 这种语法糖的做法也可以看做 intrinsic funciton 。
该问题在 LLVM 开发社区 2017 年 1 月也有一个较受关注的讨论“ IR- 层面的注释”:
解决办法 -Tapir
麻省理工大学的计算机科学和人工智能实验室在 LLVM 开源编译器的基础上,进行修改,并开发了一个新的版本 Tapir 。 他们将并行部分的代码直接嵌入编译器的中间语言 IR 里,以便充分利用编译器后端对所有代码分析和优化,而不把并行代码作为语法糖那样下推到 Runtime 库函数。
这样做,编译器的代码转换处理并行部分可能出问题。之前也有开发者在现有的 IR 上拓展,但还没有获得成功,比如用内部函数(intrinsic functions)、或者建立一套完全不同的 IR 来描述带有并行的抽象语法树。
麻省理工学院的做法包括两大部分: 新增三个 IR 代码,并放弃全部并行,将程序流程转换成一种局部并行、总体串行的非对称结构。
三个 IR 更确切地表达分叉 - 汇合
这三个新增的 LLVM 中间代码 IR 是:detach, reattache 和 sync:
- detach 和 Cilk 的"spawn"类似,用来开始分叉,从串行转为并行;
- reattache 说明一个并行代码块里的语句执行完毕后,再执行哪一块代码。
- sync 用来同步本部分的并行部分,等本部分的并行任务执行完毕之后,再往下走。
编译时,Cilk plus 代码先通过修改过的前端 PClang,产生带有三个新 IR 的中间代码(Tapir),再通过优化器进行优化 (如 LICM,重复表达式替换等高层优化),之后将 Tapir 编译成通用的 LLVM 中间代码 IR(包括下推至 Runtime 函数调用等),然后像以前一样,再对 LLVM IR 进行分析和优化,最后转化成机器代码。

感兴趣的朋友可以去 Github 下载,本文所引用的论文附录里有使用说明。
对称和非对称型控制流程图(Control Flow Graph)
Tapir 的另一个重要思路,是放弃并行的最大化,仅在局部保证并行,而整体控制流保持串行。
让我们看一个典型的并行计算场景:计算菲波那切数列中的第 n 个元素的递归函数 fib。
int fib(int n) {
if (n < 2) return n;
int x, y;
x = cilk_spawn fib(n - 1);
y = fib(n - 2);
cilk_sync;
return x + y;
}
x=fib(n-1) 和 y=fib(n-2) 这两部分逻辑上可以并行执行,如 A 图,但 Tapir 采取的流程控制图如 B 图。
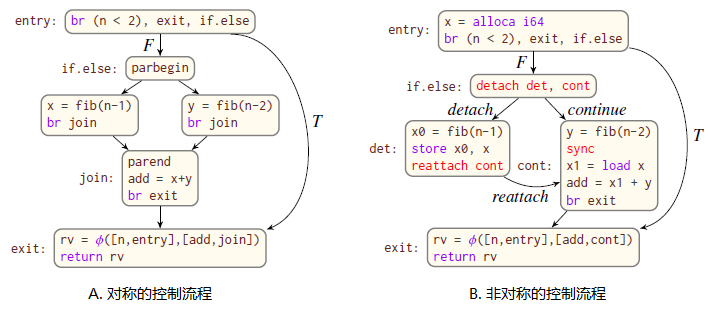
对称和非对称型控制流程图
非对称意味着两个方面: 一是通过 reattache 指令,将 det 和 cont 这两块程序用 reattach 这条边连接起来,使得本来可以并行执行的 det 和 cont 两个指令块,先后串行,先跑 det,再跑 cont。
二是确保在并行程序块里的变量,不能被并行块之外的程序访问。 比如 cont 里的指令无法直接访问并行的 det 里的 x0, 而要通过外部的虚拟寄存器 x 传递: x1=load x;
为什么这样做呢? 原因之一是为了尽可能少地修改优化器里的 80 多个分析和优化扫描代码。这些长期积累的机制,是为非并行代码设计的。所以 LLVM 采用语法糖的办法先将并行代码按语法糖下推,可以方便地沿用串行的分析和优化器。而现在如果在 IR 里保留并行代码,不下推,必须保证新 IR(Tapir) 经过分析、优化以及代码转换后,每个代码块的执行结果不改变,且不带来额外的并行读写竞争 (determinacy race)。
那么,一个很自然的想法,就是尽量保持程序的大块的串行顺序不变,仅将可以并行的部分,转化为局部并行。并行部分的数据放在局部寄存器里,外部串行指令不可以直接访问,而只能从内部传递给共享内存,以避免优化和代码转换带来额外的并行读写竞争。
对 LLVM 优化器的修改
即使这样,用于串行程序的分析、优化部分也需要少量修改,增加一些限制。比如,优化器可能将某些指令的执行前后顺序改变。如果将本来应该串行的变量赋值,移到并行部分,就有可能由于并行访问时间不同,产生该变量不确定(determinacy races)。
因此,Tapir 对 LLVM 的分析部分进行了相应修改,在变量别名分析(alias analysis) 部分,将 detach/sync 对应的指令块,作为函数处理,以免优化器错误地将串行部分的变量赋值移到并行部分里。而将 reattach 作为前后代码的分割边界,不允许优化器将后面的代码移到 reatache 之前,反之亦然。
另外,程序里占用时间最多的是循环,如何将一大堆指令流转简化为一两个嵌套的循环? 支配分析(Dominator analysis)是必需的一步–逐一确定程序里每个节点的状态,由之前的哪些节点决定? 对于每个指令而言,哪些变量的值是确定的?由于并行部分的不确定性,并行部分的寄存器值不可以作为确定值放在支配树里。
而 Tapir 的控制流程图里因为有了 Continue 这条边,可以完全沿用现在的算法,无需修改。 因为 Continue 将 detach 和 reattach 的指令块连起来,自然而然地形成两条通向 reattache 代码块的路径。 因此计算 reattache 代码块的支配节点可以完全沿用 LLVM 的串行分析器,像 If 语句分叉那样处理,而不会把并行部分误认为一定是支配树的一部分。
对于本文最开始举的归一化例子,因为将归一化的计算代码直接嵌入 IR 代码中,优化器中已有的 LICM 扫描能发现,并将 Norm 函数计算移到循环之外,从而缩短计算用时。不过,需要对 LICM 优化器做一个小小的修改。 LICM 需要对循环结束之前的所有支配节点进行扫描。
但是如前文的“支配分析”里描述的,Continue 这条边让并行部分的代码不属于支配节点,因此,对 LICM 优化的代码需要进行以下修改: 进行 LICM 扫描时,对并行循环按串行模式优化,也就是说,在寻找循环结束之前的支配节点时,忽略 Continue 这条边,这仅仅需要修改 25 行代码。
结论
同样用前文的 AWS 18 核平台,Intel Cilk Plus Runtime,重复试验,用 Tapir 代替 Cilk Plus/LLVM 进行编译:
- 未做并行处理:原程序运行时间:0.312 秒;
- 并行处理,18 核:将 for 换成 cilk_for,用 LLVM/Tapir 编译,运行 0.081 秒;
- 并行处理,1 核:运行 0.321 秒。
之所以这个并不复杂的想法一直没人去做,主要是人们担心需要对编译器的分析 / 优化部分做大量修改–LLVM 里,有 80 多种不同的优化分析扫描,有多少需要修改? 据 Leiserson 博士团队里的博士后 Tao B. Schardl 和计算机 / 物理双学位本科生 William S. Moses 说,“这证明了传统的想法完全错了。出乎意料的是,分析和优化的80 多种扫描,并不需要全部改写。T.B. 和Billy 仅仅修改了4 百多万行代码里的6 千行。” 其中,900 行用来定义这三个新IR,三千多行修改了Runtime 的函数调用,而对中间阶段的分析和优化,仅仅改动了2 千行左右。比如前文提到的归一化循环LICM 优化,仅仅需要修改25 行LLVM 的代码。
后记
本文不是为了对比Tapir、OpenMP 或Cilk Plus 在并行开发上的孰优孰劣,而是介绍Tapir 这样一个通过语言拓展和改造LLVM 编译器来方便并行开发的做法。这篇《Embedding Fork-Join Parallelism into LLVM’s Intermediate Representation》论文对许多大型、复杂的软件系统开发者也许有所启发,比如在LLVM 框架下如何考虑竞争、一致、安全、扩展、维护等方面。
当然,每个软件产品的开发背景不同,设计思路也大不一样。比如用某种GPU 框架有针对性地加速时,考虑更多的可能是如何通过厂商提供的LLVM 获得高效的PTX,来实现某些计算函数,以及高效的任务并行和数据交换。而一开始就构建在并行计算平台的业务开发,就无需过多考虑退化到单核和优化器的扩展性。
虽然Tapir 还是个非常早期的尝试,只对80 多种优化扫描中的一部分进行了深入的评估和修改,不过麻省理工电子工程和计算机科学系教授Charles E. Leiserson 认为, 这种编译器“能比其他商用或开源的编译器,更好地对并行代码优化,而且能编译一些编译器无法编译的内容”。似乎只需要对已有优化和分析机制做少量修改,并可以方便地对并行代码进行更多优化,值得继续关注。
感谢麦克周对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




