
本月,YashanDB 举办了 2023 新品发布会。作为国产数据库行业的一颗新星,崖山数据库 YashanDB 从“出道”之初便凭借着“自研技术”成为了信创领域的一匹黑马。此次发布会则再一次引发了行业的讨论。
在这次新品发布会上,YashanDB 宣布 V23.1 版本正式发布,并且首次集中推出共享集群、分布式实时数仓以及空间数据库三款新产品,至此,具备自主内核的企业级完整产品体系全面面世。据悉,此次发布会 YashanDB 还推出了个人版,并且面向所有用户和行业免费开放,目前该版本已在官网同步上线。
关于崖山数据库的故事,早前 InfoQ 在「卓越技术团队访谈录」中有做过深访:《中国的“贝尔实验室”:我们的数据库从内核的第一行代码写起》。这一次,我们同样有幸与 YashanDB 核心团队一起,探讨 YashanDB 的新品发布和背后的技术演进。
理论 + 技术 + 落地,三驾马车驱动 YashanDB 快速迭代
“基础软件产业的发展,始终遵循这样的一条路径——从基础研究到技术领先再到产业强大。”YashanDB 产品总监王南在发布会上表示,YashanDB 在五年时间里通过算法理论、关键技术、应用场景三驾马车驱动产品快速成熟。
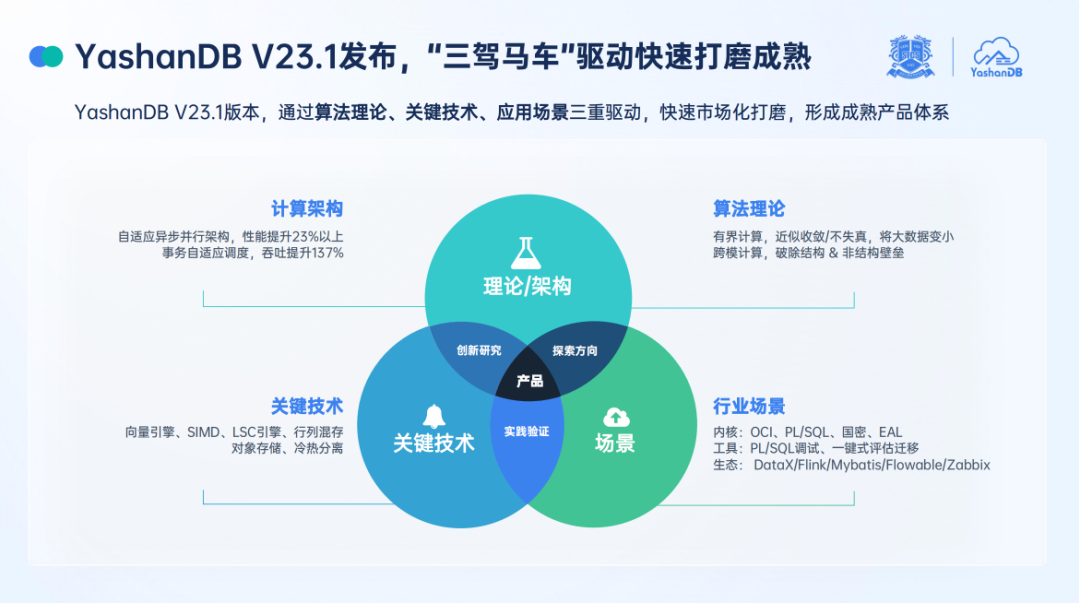
一方面,随着全行业数字化的提速,加之大模型与 AIGC 的爆火,数据的规模、形态以及应用场景越来越多样化,由此也对数据存储、计算、分析、管理等提出了更高的要求,传统的数据库在能效比、多模态数据管理等方面面临挑战。
针对这一问题,YashanDB 将原创的有界计算理论和跨模计算理论融入到计算框架中,以应对数十亿级数据量以及关系、图、文档等多模态的分析查询需求;同时 YashanDB 采用了自适应的异步并行框架和事务调度机制来提高任务调度效率,经测试系统性能提升约 20% 至 30%,事务吞吐量提升了 137%,达成算法级别的创新。
另一方面,从业务需求来看,TP(事务处理)业务和 AP(分析处理)业务的融合是未来的趋势之一,对于企业提高资源利用率和业务处理速度、简化数据管理、促进业务创新等方面有着不小的价值。
对此,在关键技术上 YashanDB 具备了三个核心能力:一是通过向量引擎以及 SIMD 的技术为大规模数据计算提供底层并行和并发计算的基础;二是通过 LSC 引擎(Large-scale Storage Columnar Table)和 TAC 引擎 (Transaction Analytics Columnar Table) 解决实时数据与海量历史数据的融合计算问题;三是通过对象存储实现冷热数据的自动转换以优化成本,多方面助力企业降本增效。
简单理解,上述两个方面主要解决的是数据库的性能与成本等问题,但当产品落地到应用端时,有没有与之匹配的工具能力、完备的生态支持则是影响用户体验的第三大核心要素。
面对这一问题,王南表示新版本的 YashanDB 在兼容性、工具以及生态方面表现亮眼。内核层面,V23.1 支持 OCI (Oracle Call Intedace),能够提供数据库高速访问的驱动性能,此外还全面兼容存量系统中大量的 PL/SQL(Procedural Language/SQL)等高级特性,以满足金融、政府以及企业核心系统的关键诉求;工具层面,一方面新版本调试能力增强,另一方面还提供了完整的迁移评估与工具体系,来确保数据迁移的快、稳、准;此外,在生态层面 YashanDB 也更加深入地联动上下游厂商做产品适配,为客户提供更完备的生态支持。
至此,一个高性能、高兼容、更开放的 YashanDB V23.1 正式诞生。
当然,除了全方位的能力迭代之外,本次发布会最受期待的便是向金融核心场景的 YashanDB 共享集群。
首次推出面向金融关键行业核心系统的共享集群
随着信创的持续走深,金融行业的国产化改造同样进入深水区,是否能够实现金融行业核心数据库系统的国产化替代,已然成为了国产数据库能力评估的一次大考。
由于金融行业的核心数据库系统需要处理复杂业务的账务信息,且对这些数据的准确性、安全性至关重要,所以银行核心系统对数据库的时延、数据一致性、安全性、高可用性等方面都有着极其严苛的要求。在此之前,大多数金融机构倾向于采用国外厂商提供的主机和数据库解决方案来构建其系统。其中,Oracle RAC(Oracle Real Application Clusters)一直是高端市场的佼佼者。Oracle 前后花了十年才正式推出,又经过了多次版本迭代才趋于稳定,其背后之艰,可想而知。
一般情况下,对于基于主备复制的高可用数据库来说,异步复制是常见策略,优点是性能友好,并且不会因为数据复制而带来过多的性能开销,然而异步复制有可能会造成数据丢失,在金融领域,这是不能接受的;对于分布式数据库来说,其架构决定了它天然具备一致性复制能力,但是它的价格相对高昂,并且节点数量增加,系统的运维复杂度会数量级提升。
因此,国产共享集群已然成为数据库国产化替代的一大关键,攻克了共享集群技术的国产化,才能真正实现金融核心系统快速、低成本、安全的平滑替换。对此,YashanDB 共享集群首席架构师孟凡彬在采访中表示,共享集群产品架构的复杂度极高,团队也遇到了几个关键的挑战:一是如何快速地继承和复制 YashanDB 集中式如此复杂的功能,如何解决集群间 DDL 同步和一致性的问题;二是如何进行并发控制,性能达到最优;三是如何达到秒级故障透明切换的能力。
“为了应对这些挑战,团队在研发过程中采取了多种措施。例如,通过深度定制和优化,系统化地列出故障模式库并梳理所有 DDL、DML、DCL 的流程,同时引入了故障注入打点的工程方法,对代码全覆盖,做到“故障定位精确到每一行代码”,极大提升了稳定性;另外,为了达到秒级故障透明切换的能力,我们搭建了多场景的故障测试框架,来全面验证 YashanDB 的高可用能力等等。”孟凡彬补充道。
最终在经历了多重技术突破与验证之后,YashanDB 正式推出了基于磁盘阵列的共享集群数据库系统——YashanDB for Cluster。据介绍,该数据库系统采用单数据库多实例架构,所有计算节点提供对等的多活计算能力,节点之间以强一致性方式实现并发读写,从而为用户提供透明多写、高可用、高性能的数据库能力。
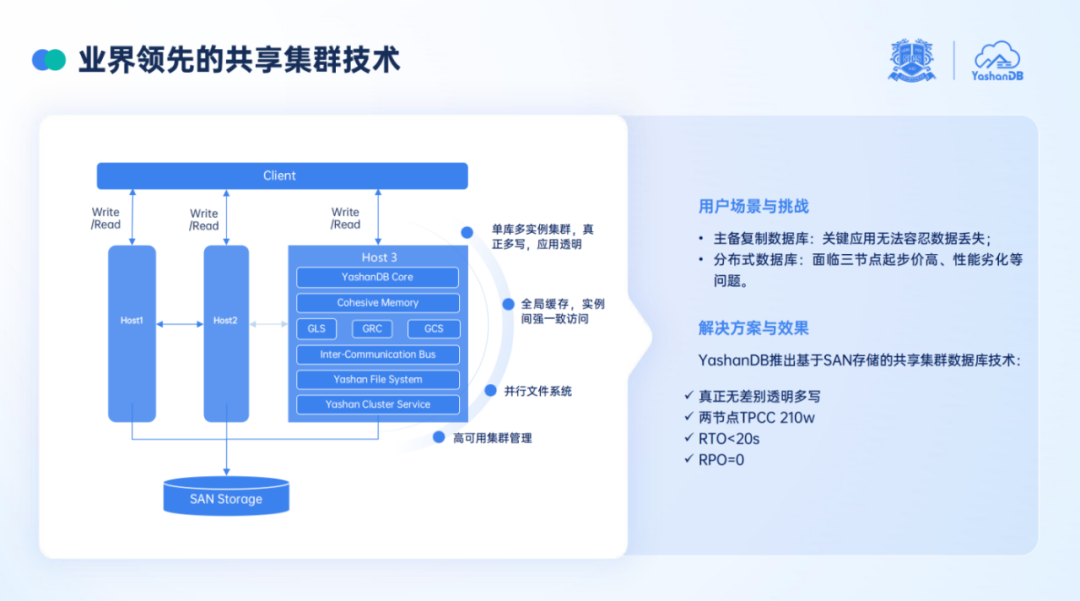
对于崖山共享集群的技术优势,YashanDB 技术总监欧伟杰在会上称:“崖山共享集群能够为客户提供真正无差别、透明的读写能力,无论客户连接到哪个实例,都能使用全量功能特性,并且可以像使用集中式数据库一样使用集群数据库;性能方面,崖山共享集群两节点 TPCC 超过 210w,且线性扩展比>0.8,能够为客户提供强大的性能。
据孟凡彬介绍,在早期进行内核设计时,YashanDB 充分考虑了向共享集群形态的演进,事务管理、MVCC 机制等内核技术天然适合共享集群,为后续的扩展打下坚实基础。此外,崖山共享集群的极致性能表现还离不开其背后的两项关键技术——Cohesive Memory 和 In memory FAT 技术。
Cohesive memory 系列技术主要实现了集群多实例之间的数据和锁的同步。在功能设计上,它不仅注重高性能的流程设计,还充分考虑了各类异常和故障场景下的高可用性。这种技术架构的挑战相当大,也是其被誉为“塔尖”技术的关键原因。
YashanDB 创新性地采用了本地化空间管理,有效避免了实例间的争用。此外,全局资源细粒度并发控制有效减少实例间的冲突,脏页快传技术有效减少脏页传递时的等待,实时事务状态广播几乎实时地在实例间同步状态,避免等待。
除此之外,文件系统对性能也至关重要,YashanDB 采取了 In memory FAT 专利技术,数据库通过崖山文件系统读写文件几乎零开销,文件系统元数据常住内存,数据库直连访问。

值得一提的是,在发布会现场进行了“拔网线、掐电源”极端情况下的故障模拟,崖山共享集群的 RPO(数据丢失量)为 0,能够确保故障切换不丢数据,故障恢复时间 RTO 小于 20 秒。针对高可用性,孟凡彬在发布会上表示:“YashanDB 的共享集群全面考虑了各种故障模式,包括网络故障、进程挂起、磁盘 IO 超时等,对所有业务流程进行了故障容错的设计,最终实现了端到端完备的应用连续性。”
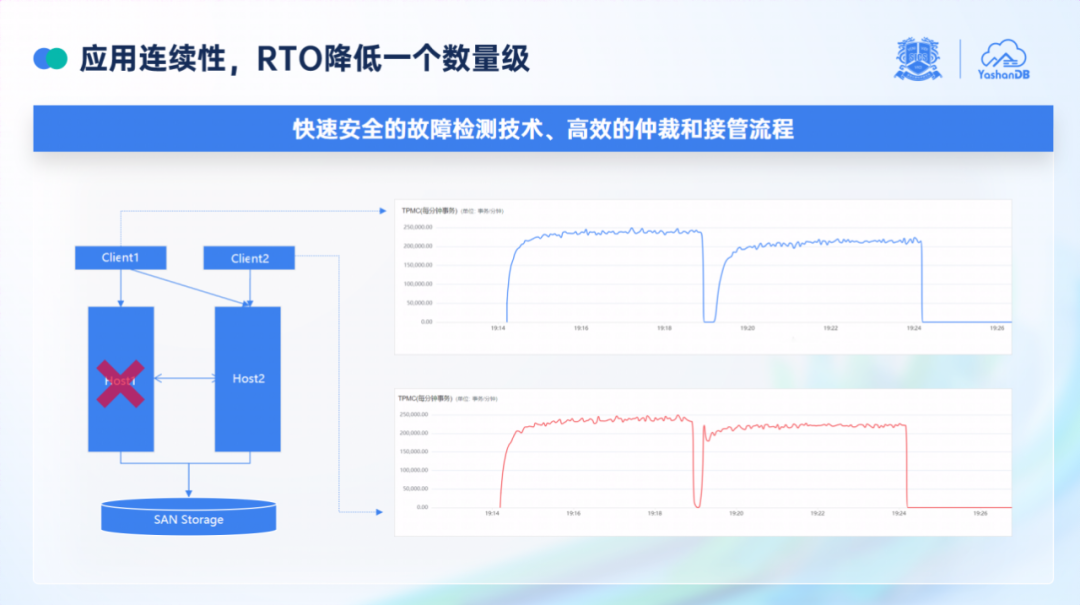
孟凡彬举例称,若上图的主机 Host1 故障,系统将会发生以下恢复动作:首先集群软件探测到节点故障,在共享存储上发起投票仲裁,将故障节点踢出集群列表;然后由幸存节点的数据库实例接管故障节点,包括全局资源的重建,重演日志将故障节点的脏页恢复,托管其事务区信息等;最后之前连接到故障节点数据库实例的客户端 Client1,将通过透明切换的能力自动连接到 Host2 的数据库实例上,恢复业务运行。
“通过右图的曲线可以直观看到效果,上面的曲线代表 Client1,在故障前连接到 Host1,故障后自动连接到 Host2 继续运行,从故障到端到端恢复正常,用时小于 20s;下面的曲线 Client2, 在故障前连接到 Host2,其业务运行会短暂受到集群冻结影响,小于 10s。”孟凡彬补充道,”故障发生后,故障自动恢复,业务是无感知的。”
分布式实时数仓发布,七大能力全面曝光
除了面向金融核心场景的数据库系统,分布式实时数仓——YashanDB for Data Warehouse 同样是本次发布会的一大亮点。
事实上,近几年随着国产化替代的如火如荼,有很多厂商已经推出了国产化的实时数仓产品,并且也经历了初步的市场验证,YashanDB 选择在这个节点发布实时数仓,势必要拿出一些更有市场说服力的价值点来。
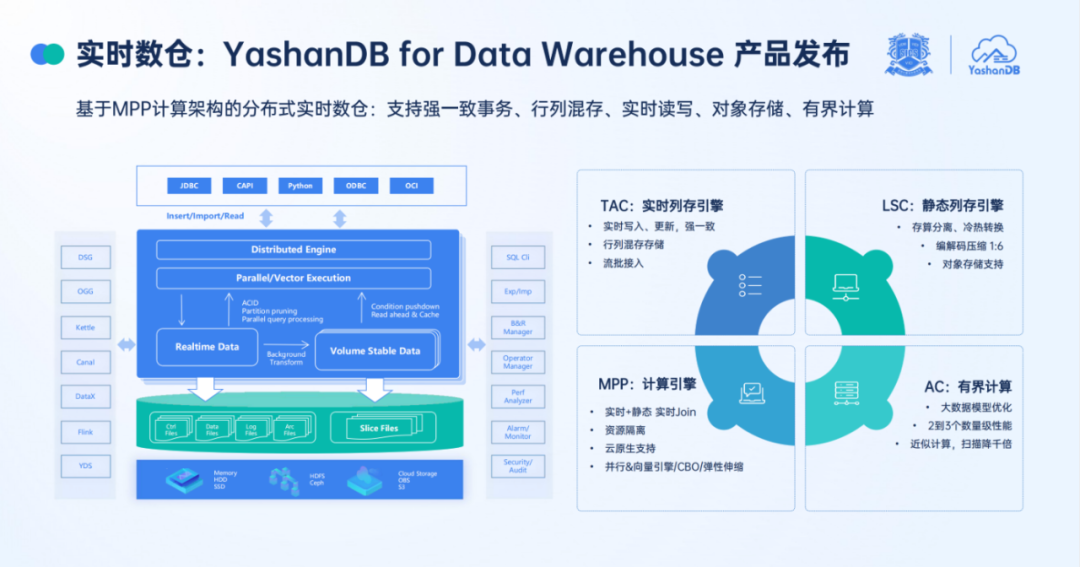
对此,王南表示:YashanDB for Data Warehouse 是一款基于 MPP 计算架构的分布式实时数仓,跟传统的 OLAP 数仓在内核上有很大的不同。
首先是在原有的 MPP 并行计算的基础上,增加了冷 / 热数据、静态 / 动态数据的跨模融合计算能力,为用户提供一致的 SQL 能力,并且用户可以访问全量数据;同时也能实现大规模负载和计算场景资源的完整隔离,包括计算资源、内存资源、存储资源的隔离,来保证所有的任务调度互不干扰。
其次是 TAC 实时列存引擎,它专注于实时场景,基于 In-place Update 原位更新技术,能够提供强一致的事务支持,保证数据的实时写入、更新和强一致性,同时利用行列混存技术,满足实时数据写入和查询的需求。再次,YashanDB for Data Warehouse 引入了 LSC 静态列存引擎,具备存算分离和冷热转换的能力,同时能够提供 6 倍到 10 倍的数据压缩比,从而大大降低数据存储成本,并且支持对象存储。
最后还融入了原创的有界计算 AC 能力,通过近似计算能够将几十亿级的数据扫描规模缩减近千倍,由此可以带来 2-3 个数量级的性能提升,从而大幅提升行业数据模型查询、分析、处理等能力。

值得一提的是,23.1 版本的 YashanDB 通过自研优化器、向量化执行、并行计算以及分布式计算能力全场景覆盖,使得 AP 并行分析查询能力进一步突破,TPC-H 性能是开源数据库的 10 倍以上,单节点导入性能达到 300MB/s。
由此,一个具备大容量、高压缩、强一致、高性能入库、强分析查询能力的实时数仓产品 YashanDB for Data Warehouse 正式诞生。
谈及崖山分布式实时数仓极致性能背后的关键技术优化,欧伟杰在会上表示,首先在 23.1 版本中 YashanDB 实现了面向行列算子的自适应 Cost 模型,结合算子计算模式,运行时动态调整模型参数,避免在不同环境下数据库性能表达差距大的痛点问题,最终通过对复杂查询场景下 Cost 模型的优化,实现了整体性能较上个版本最高 85% 的提升,并且也大大降低了性能调整的复杂性。
其次,V23.1 版本还设计并实现了多级内存管理能力,能够针对数据库内部不同使用场景采用动态的内存管理策略,降低直接从操作系统分配内存的频率,并在不同算子 / 会话间实现计算内存的重用。实测显示该方法能够有效提高复杂查询下计算内存的利用率,提升数据库整体处理能力。
当然,对于 CPU 和 I/O 资源的管控,YashanDB 也给出了它的优化思路,即面向混合负载场景设计提出细粒度资源管理诉求,设计并实现了资源管理器适配不同底层资源模块,有效降低了资源紧张场景下的 CPU 使用率。
最后则是支持基于对象存储的静态数据管理能力,虽然数据保存在远端,但利用静态数据的大颗粒度 I/O 特征和优化本地 DiskCache 能力,能够最小化远程访问的性能损耗,经 SSB 测试,YashanDB for Data Warehouse 的对象存储和本地存储的查询时延均小于 5%。与此同时还可以利用云基础设施实现海量数据的低成本和弹性管理。
面向未来,欧伟杰表示:“得益于 YashanDB 研发团队在技术上的不断深入打磨,崖山分布式数据库对比开源分析型数据库已经体现出了巨大优势,即便是 Q2 的单表查询也有数十倍的优势,我们相信崖山数据库仍有很大的提升空间。”
空间数据管理能力进化!YashanDB for GIS 重磅发布
除了金融场景和实时数仓,空间数据库同样也是国产化替代的一个核心场景,在地理信息系统、位置服务和导航、城市规划与管理等方面发挥着重要作用,尤其是随着“智慧城市”等概念的提出,空间数据库将会发挥出更大的价值。
面向空间数据管理这一场景,本次发布会同样给行业带来了一个新的选择——YashanDB for GIS。
据悉,YashanDB 空间数据库支持“原生 GIS 数据库引擎和中间件 + 关系型数据库”两种模式,具备 GIS 引擎与 SDE 双形态空间能力,支持矢量地图、激光云点、栅格、轨迹、遥感影像等空间数据的管理。
此外,YashanDB 23.1 版本还对地理空间数据管理模型进行了扩展,增加了矢量数据、标准函数、空间索引等功能,使得 YashanDB 成为具备高性能地理空间矢量数据管理能力的企业级自主研发数据库。
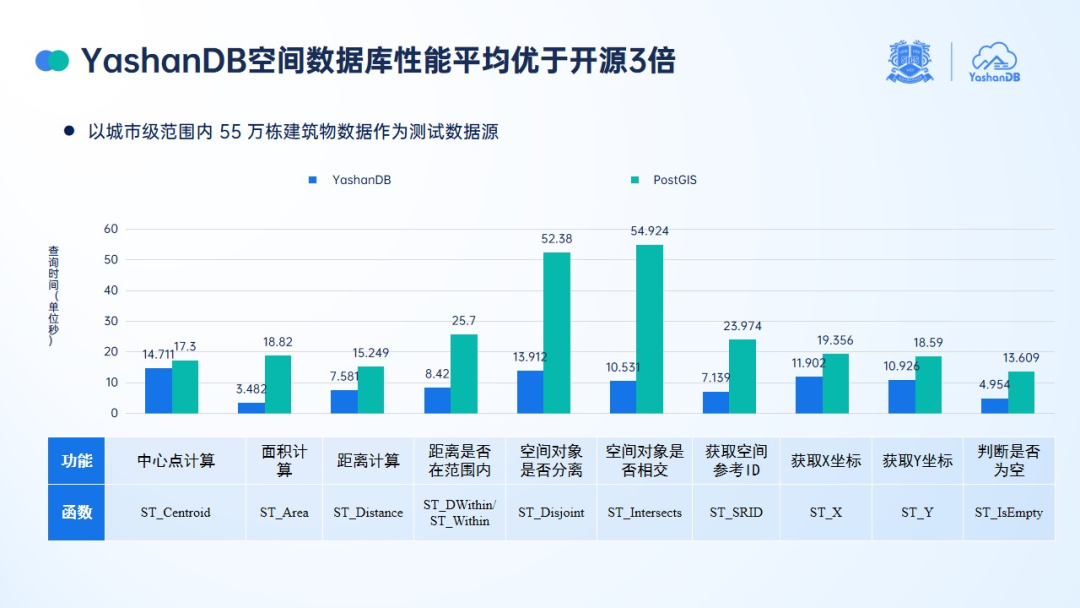
王南表示:“我们和开源数据库也做了一个对比,我们的空间计算引擎在面向一个真实城市 55 万栋建筑数据和 10 类功能和应用场景的测试验证下,我们的性能表现是商业和开源的空间计算引擎的 3 倍以上。”
事实上,空间数据的高效访问主要依赖于空间索引,全新发布的 YashanDB 空间数据库实现了基于 R-tree 的空间索引能力,由此也带来了性能的大幅领先。
据介绍,崖山空间索引的实现基于外包框,采用了用户定义类型存储空间数据类型,在 UDT (User Defined Type)的属性中包含其外包框,能够通过自适应算法,对较大的空间对象提前计算其外包框,保证提取外包框的 I/O 消耗可控。
此外,崖山空间索引的物理存储还复用了崖山原有 B-tree 的存储组织,这使得并发分裂局部锁机制等优势在空间索引上被完美继承。
值得一提的是,崖山空间索引也实现了全节点 MVCC,支持细粒度多版本管理和空值优化等。
不难看出,YashanDB 空间数据库在确保性能的同时,也在积极拓展更多有业务需求、有场景价值的能力,而这些能力在开源的 PostGIS 中是不可见的。
除了持续优化原生空间数据计算性能外,YashanDB 也积极在和 GIS 平台进行合作,先后完成了与中地数码 MapGIS 以及超图 SuperMapGIS 的适配验证,共同打造出了全国产化解决方案。据悉,崖山空间数据库作为核心时空数字底座,已被应用于深圳龙华区数字孪生城市。
“为了支持更大规模的空间应用,空间数据的分布式并行计算、时空数据冷热分离存储都是崖山空间数据库规划探索的方向。”欧伟杰补充道。
总结
从共享集群技术的全面突破,到实时数仓和空间数据库的优势立显,YashanDB 给了行业不小惊喜的同时,也再一次展示了“理论 + 工程”双轨制的创新优势。
欧伟杰曾在采访中表示,正是基于“双轨制”的模式,在数据库系统研发过程中,崖山数据库系统团队会更关注研究成果如何转化,工程师不只“低头赶路”,也会“抬头看路”,互相交流。“同样,我们也欢迎有兴趣的同学和我们的技术团队交流碰撞,共同推进国产数据库行业发展。”欧伟杰在发布会总结时说道。
理论研究的专注与纯粹 + 商业版本的实践与验证,共同为 YashanDB 构筑出了持续创新的能力底座,V23.1 是 YashanDB 的一个里程碑式版本,未来我们期待 YashanDB 撬动更多的场景并广泛落地。




