
3 月 5 日 ,OpenAI 的最大竞争对手 Anthropic 刚刚发布了新一代 AI 大模型系列 —— Claude 3。该系列包含三个模型,按能力由弱到强排列分别是:Claude 3 Haiku、Claude 3 Sonnet、Claude 3 Opus。
比 GPT-4 更强?
Anthropic 表示,Claude 3 Haiku 是最快的模型,适用于需要即时响应的场景。它可以在不到三秒的时间内阅读 arXiv 上包含图表和图形的信息和数据密集的研究论文(约 10k tokens)。
Claude 3 Sonnet 在智能和速度之间提供平衡,适合企业工作负载,如知识检索或销售自动化。
而 Claude 3 Opus 则是能力最强的模型,实现了接近人类的理解能力,适用于高度复杂的任务,在多项基准测试中得分都超过了 GPT-4 和 Gemini 1.0 Ultra,在数学、编程、多语言理解、视觉等多个维度树立了新的行业基准。
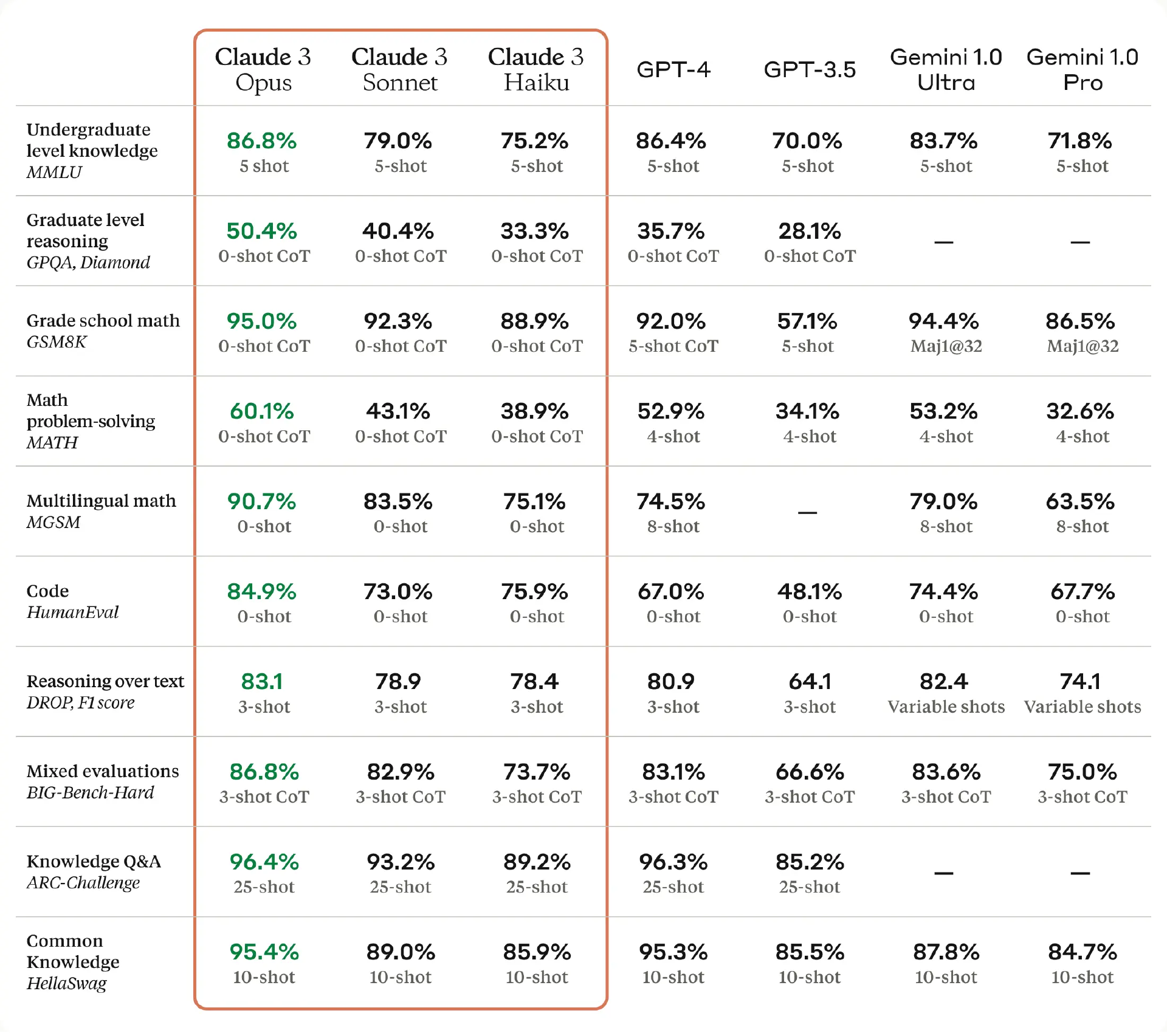
从 Anthropic 给出的 benchmark 测试数据来看,Opus 在多个指标上超过了 GPT-4。
在此之前,GPT-4 的综合性能全球绝对领先,能实测到的模型中只有这次 Claude 3 的上一代 Claude 2 超过了 GPT-3.5。
这次的 Claude 3,除了速度、理解、效率等综合性能之外,这次在长文本上有亮点,可以支持 200K Tokens 的上下文长度,另外也可以支持图像和文件输入了。

再值得参考的一点是价格:Opus 输入 15 刀/百万 tokens,输出 75 刀/百万 tokens;Sonnet 输入 3 刀/百万 tokens,输出 15 刀/百万 tokens;Haiku 输入 0.25 刀/百万 tokens,输出 1.25 刀/百万 tokens。
Anthropic 还放出了 42 页的技术报告《The Claude 3 Model Family: Opus, Sonnet, Haiku》。

报告地址:https://www-cdn.anthropic.com/de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_Card_Claude_3.pdf
在报告中,我们能看到 Claude 3 系列模型的训练数据、评估标准以及更详细的实验结果。

Anthropic 将 Claude 3 系列模型在推理、阅读理解、数学、科学和编程能力上,与竞品模型展开了比较,结果显示不仅超越了其他家模型,还在大多数情况下实现了新 SOTA。
效果好不好,还得看大家的测试结果
至于性能比较,虽然 Anthropic 表明自家模型比 GPT-4 更强,但很明显,大家对基准测试并不抱那么大的希望,“就像汽车厂商一样,他们肯定会说自家的车是最快最安全的。”
benchmark 已经不再那么具备参考意义,一是 Claude 3 比的是去年 3 月发出来的 GPT-4,二是选取指标上都会更“偏向”自己。

因此,不少网友用自己的方法进行了测试,来验证 Claude 3 是否有 Anthropic 宣传中的那么厉害。
其中一位网友说,第一眼感觉它比 GPT-4 好一点,比 Mistral 等好很多。比较特别的一件事情是,Claude 3 的回复似乎比之前的 LLM(大型语言模型)更人性化得多。

“我知道现在你可能感觉不到,但你肯定会度过难关的。I know it may not feel like it right now, but you ARE going to get through this.”这句话中的 “ARE” 非常人性化,GPT-4 不会在不经提示的情况下用大写字母来强调。
下面这幅图,大家能看懂讲的是什么吗?

这是一位网友别出心裁的用 ASCII 进行提问,Claude 3 也用了 ASCII 进行回复。

“Claude 3 (mid) 现在也可以读取 ASCII 码了。我用 ASCII 询问一些问题,并要求它以 ASCII 形式回答。该死的,他们做到了。这是 GPT-4++级别哇!”
另外,在代码能力上,也有一些网友进行了测试。有位网友要求 Claude 3 画一副 3D 自画像,再渲染成代码,效果非常令人惊叹:

有一位名为 Ruben 的网友,专门设置了了一个测试来对比 Claude 3 和 ChatGPT 的能力。
他给出了一个网站 UI 界面,要求 Claude 3 和 ChatGPT 将其转为代码。Claude 3 拒绝了,而 ChatGPT 成功的执行了。Claude 3 的道德标准太高了?!
还有一位企业家 Rishabh Srivastava,在 SQL-Eval 上对 Claude-3 进行了评估:https://github.com/defog-ai/sql-eval/tree/rishabh/claude-3,他得出的结论依然是 GPT-4 更好。

“比 Claude 2 好得多,但距离 GPT-4 还有一段路要走 对于 SQL 生成,Opus 具有 GPT-4 Turbo 级别的性能。Sonnet 具有与 3.5-turbo 类似的性能,但速度也慢大约 4 倍。GPT-4 仍然明显更好。”

这些测试结果,也许正如爱丁堡大学博士生符尧的分析:被评估的几个模型在 MMLU / GSM8K / HumanEval 等几项指标上基本没有区分度,真正能够把模型区分开的是 MATH 和 GPQA,“这些超级棘手的问题是 AI 模型下一步应该瞄准的目标”。
🔥Claude 3 极简试用方式必须安排!戳链接即可通过 Amazon Bedrock 访问 Claude 3 👉立即体验




