
采访嘉宾 | 袁小栋、杜恒
编辑 | Tina
8 月 13 日,RocketMQ 迎来了 5.0 版本,这是继 2017 年发布 4.0 版本之后时隔 5 年的一次重大更新。5.0 版本进行了架构重塑,新增或者修改了超过 60% 的代码,但是对 4.0 的所有功能以及整体架构进行了无缝兼容,且没有引入任何外部依赖。而且其中非常重要的一点是,RocketMQ 兼容了开源 Flink 生态。与 Kafka 只是作为 Flink 的上下游数据不同,RocketMQ 直接实现了 Flink 的基础功能或者算子,并首创性地兼容了 Flink/Blink SQL 标准以及 UDF/UDAF/UDTF。为什么 RocketMQ 会选择将 Flink 融合到一起?这样带来哪些好处?适合哪些应用场景?为解答这些问题,InfoQ 采访了 RocketMQ 开源负责人杜恒和 rocketmq-streams cofunder 袁小栋。
InfoQ:RocketMQ 5.0 版本中,您认为的最重大的三个变化是什么?
袁小栋、杜恒:RocketMQ 5.0 的建设,是社区与云上逐渐演进的结果,每个特性都不是一蹴而就的,如果非要总结三个最大的变化,我认为就是云原生下的场景化弹性架构、事务分析一体的支持 以及 轻量级实时计算引擎 的出现。
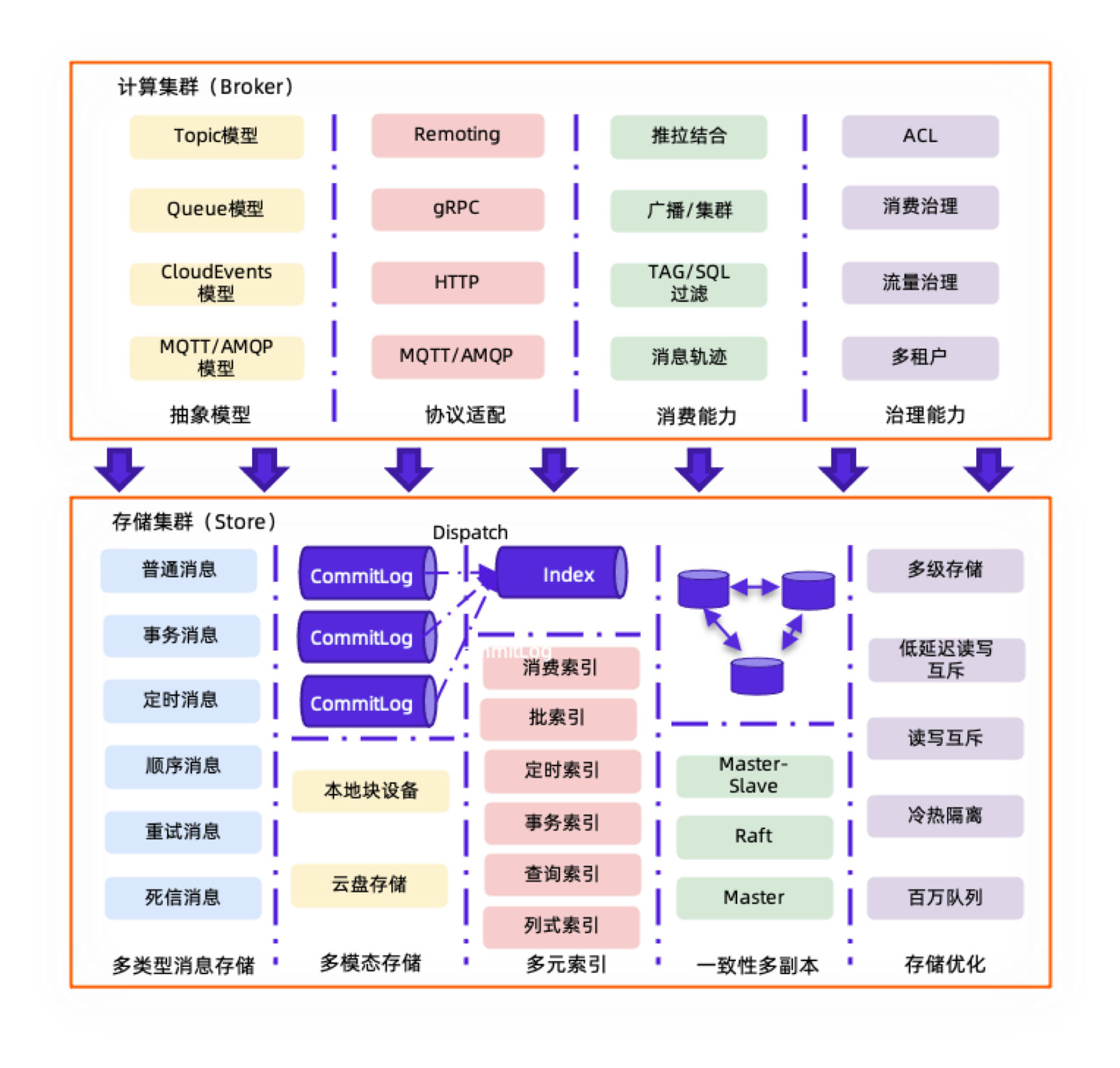
场景化弹性架构具体来说,就是能够在不同场景下能够以资源使用率最高、运维成本最低的方式进行部署、交付,比如在公有云上基于云盘,RocketMQ 可以非常方便的以单副本的方式运行;在私有化部署的场景下,可以使用两副本的方式进行交付;在两地三中心、异地容灾场景下,又可以以三副本+Preferred Leader 方式进行部署。这种灵活的存储架构,使得 RocketMQ 能够充分利用云上的 IaaS 层资源,这也是从 Cloud Hosting 到 Cloud Native 的一个巨大转变。除此之外,RocketMQ 在不同的场景下也会有不同的分层架构,比如在大数据场景下,RocketMQ 可以以单体架构降低成本、提供就近计算的能力,在公有云多租场景下,会提供存储计算分离的分层架构满足不同用户的接入诉求,而且 RocketMQ 的计算层是彻底消除状态的,用户可以任意节点接入进行消息的发送接收。
事务分析一体或者说双引擎是消息、事件、流融合处理平台的一个具体体现,RocketMQ 在保留原来业务消息领域首选偏重于事务场景的前提下,着重对分析进行了提升,包括多索引能力的增强、批的优化、KV 语义点查能力的支持等,都是希望能够用一套架构同时满足业务消息,也能够对大数据计算分析场景进行更好的支持。
rocketmq-streams 也就是今天的主题,解决了用户轻量级实时计算场景下资源占用过高、运维负担较重的困扰,也满足了对 RocketMQ 之上流转的宝贵业务数据进行深度计算分析后处理的诉求。
InfoQ:rocketmq-streams 是将 Flink 的哪些功能融合进了 RocketMQ?这样做带来了哪些好处?
袁小栋、杜恒:功能上 Flink 的基础功能或者算子如 Source、Sink、map、flatmap、split、select、window、union rocketmq-streams 都做了实现,当然也包括一些基础的核心特点:Exactly-once,灵活窗口(滚动,滑动,会话),双流 Join,高吞吐、低延迟、高性能等。
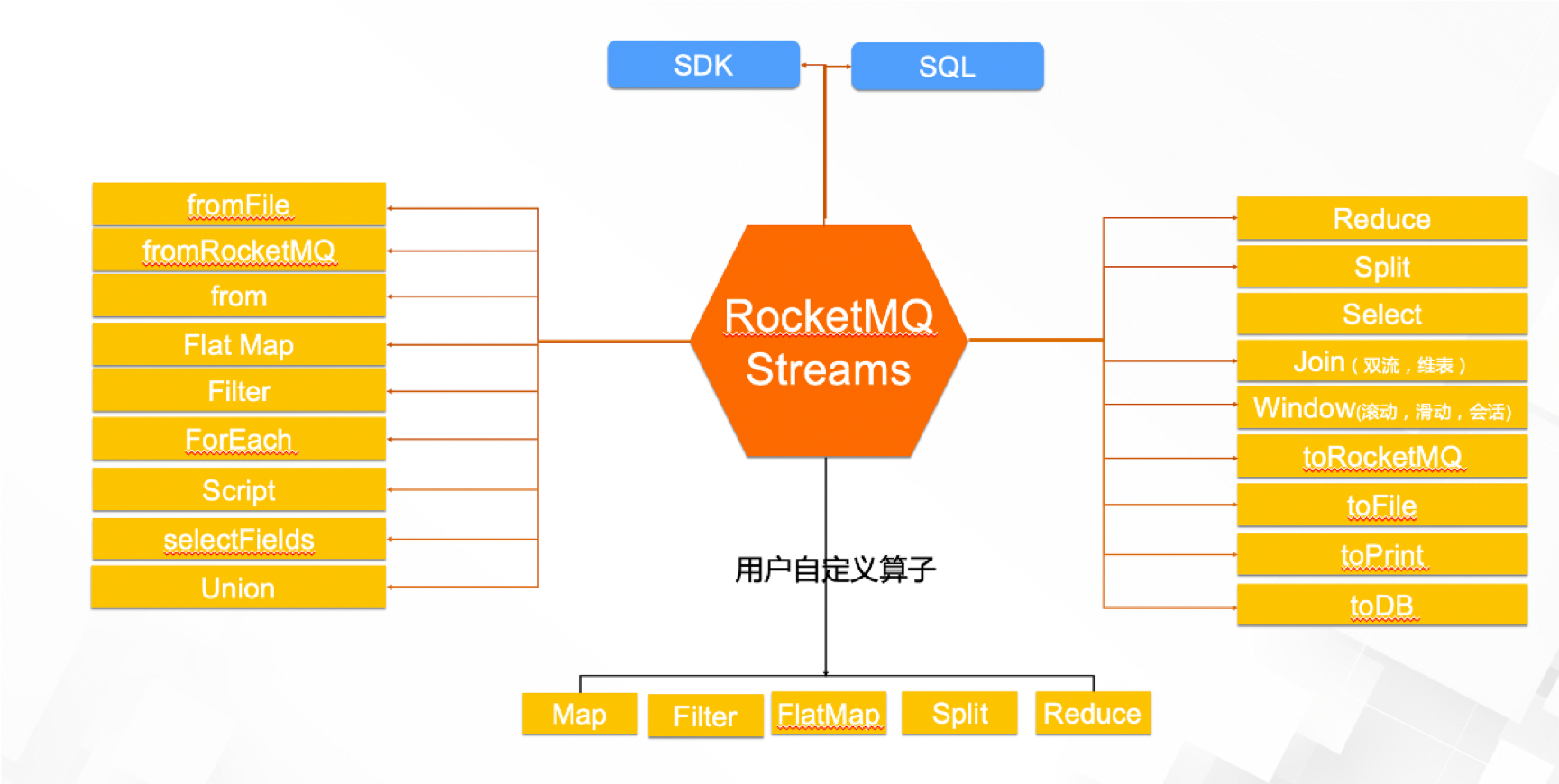
rocketmq-streams 的设计之初主要是为了解决用户在使用 RocketMQ 过程中面临的一些轻量级计算的问题,在实时计算领域,社区一直以来的目标都是积极的与 Flink、Spark 等实时计算引擎通过生态合作的方式满足用户诉求。因此,rocketmq-streams 并非要做一个和 Flink 同质的大数据计算引擎,这个引擎场景很明确,主要是满足大数据量->高过滤->轻窗口计算的场景,重点要打造轻量化、高性能和低成本等优势。
流能力的建设,主要是围绕场景需求来建设,当然时间关系还有部分能力未完善,从 Apache RocketMQ 自身来讲,为了更好的支撑 rocketmq-streams, RocketMQ 本身架构也会有调整, 其实主要还是做了存储能力,API 方面一些增强,比如在存储方面,在 queue 语义的基础上,增加了用于点查的 KV 语义用来更好的支持 Checkpoint 存储;逻辑队列更好的解耦 Broker 和分区,在批处理场景中,可以提高数据读取的并发度,彻底消除队列占位以及负载均衡带来的影响;为了提升吞吐量,社区也在紧锣密布的进行 batch 存储的优化;此外,社区还有意对 OpenSchema 开放标准进行支持,提升 RocketMQ 数据治理能力;这些改进不仅仅是对 rocketmq-streams 的支持,而且也会帮助 RocketMQ 成为最符合实时计算引擎 Flink 的消息系统。
所以总结来说,融合进来的这部分功能,相对 Flink 本身,有两大性能上的优化:
主要是针对当前要求较多的大数据量 -> 高过滤 -> 轻窗口的场景下,努力提升计算和过滤的性能;除此之外就是部署轻量化,只需要 1core、1g 即可部署,除此之外,能够较好的支持自动容错以及任务的热更新。
InfoQ:最开始,决定将 streams 的功能融合进来,是为了解决哪些场景的问题,有着什么样的思考路径?
袁小栋、杜恒:首先,前面提到过,RocketMQ 相比于 Kafka,长期以来是作为业务消息领域的首选出现在开发者面前,而在业务消息领域,大量的交易、订单、物流等核心数据通过 RocketMQ 进行流转,于是自然而然的就产生了基于这些珍贵的业务数据进行计算的需求,这是 rocketmq-streams 出现的源动力。
其次,在一些资源紧张、运维压力大或者计算场景相对简单的场景下,传统的做法是,用户部署一套庞大的实时计算引擎如 Spark 再把 RocketMQ 中的数据导入进去进行计算,这无疑会极大的增加用户成本以及背负沉重的运维压力,rocketmq-streams 的出现解决了这个问题,rocketmq-streams 只需要 1core、1G 即可运行,极大的降低了用户的成本以及运维压力,因此在轻量级需求、大数据的场景驱动下,rocketmq-streams 应运而生。
最后,从 RocketMQ 发展历史来看,RocketMQ 相比于其他消息产品一直坚持在计算方向进行探索,从 3.x 版本的 Filter server,即用户上传一段过滤逻辑到服务端加载运行(这应该也是 Function 的雏形),到 4.x 版本更加强大易用的 Tag,SQL 服务端计算过滤能力的支持,都很大程度上降低了业务服务的处理压力,如今 5.x 版本蓄势待发,在数据已经成为企业的核心价值的今天,一个更加强大的 rocketmq-streams 成为大势所趋, 这也与 RocketMQ 架构发展是一脉相承的。
当然幸运的是,随着 RocketMQ 生态的不断发展,不管是在社区,还是在阿里内部,一大批熟悉实时计算的开发者带着问题与思考,逐渐走进 RocketMQ 社区,共同完善 rocketmq-streams。
InfoQ:目前 rocketmq-streams 适合哪些场景?是否在阿里内部业务上有落地?
袁小栋、杜恒:rocketmq-streams 适合大数据量->高过滤->轻窗口计算的场景,如安全检测,风控,边缘计算,ETL 等场景; 不适合直接用来做窗口计算的场景,因为窗口计算会通过 RocketMQ 做 shuffle,直接做窗口计算,框架的核心过滤优势和轻量优势发挥不出来。
rocketmq-streams 现在是在专有云上被广泛用于入侵检测,是云盾的核心组件,在入侵检测场景中,由于所有的规则基本上都会做前置过滤且具有较高的过滤率,然后才会做较重的统计、window、join 等操作,因此在这个场景中,相比于采用其他大规模实时计算引擎,rocketmq-streams 资源占用是其他引擎的 1/70,性能有 3-5 倍的提升。当然在不同场景下,rocketmq-streams 的性能以及资源占用都会有不同的表现,欢迎大家试用并在社区积极反馈。
InfoQ:一些计算场景如果 rocketmq-streams 不满足,而需要同时部署 Flink,该如何权衡两套系统的计算资源和运维成本?
袁小栋、杜恒:rocketmq-streams 会积极融入 Flink 生态,就当前阶段来说,rocketmq-streams 可以独立部署,部署 rocketmq-streams 不会带来额外的软件开销,除此之外,现在我们正在做一个能力,rocketmq-streams 可以发布成 Flink 任务,部署在 Flink 集群上,发挥资源和性能优化的优势,使整体任务资源大幅下降,运维和资源复用一套。最后前面也提到, rocketmq-streams 的另外一个项目 rsqlDB 会对 Flink/Blink SQL、UDF/UDAF/UDTF 进行支持,当使用 rocketmq-streams 不能满足当前的计算需求时,可以将 rocketmq-streams 计算任务迁移到 Flink。
InfoQ:您们对流处理这部分有哪些未来规划?
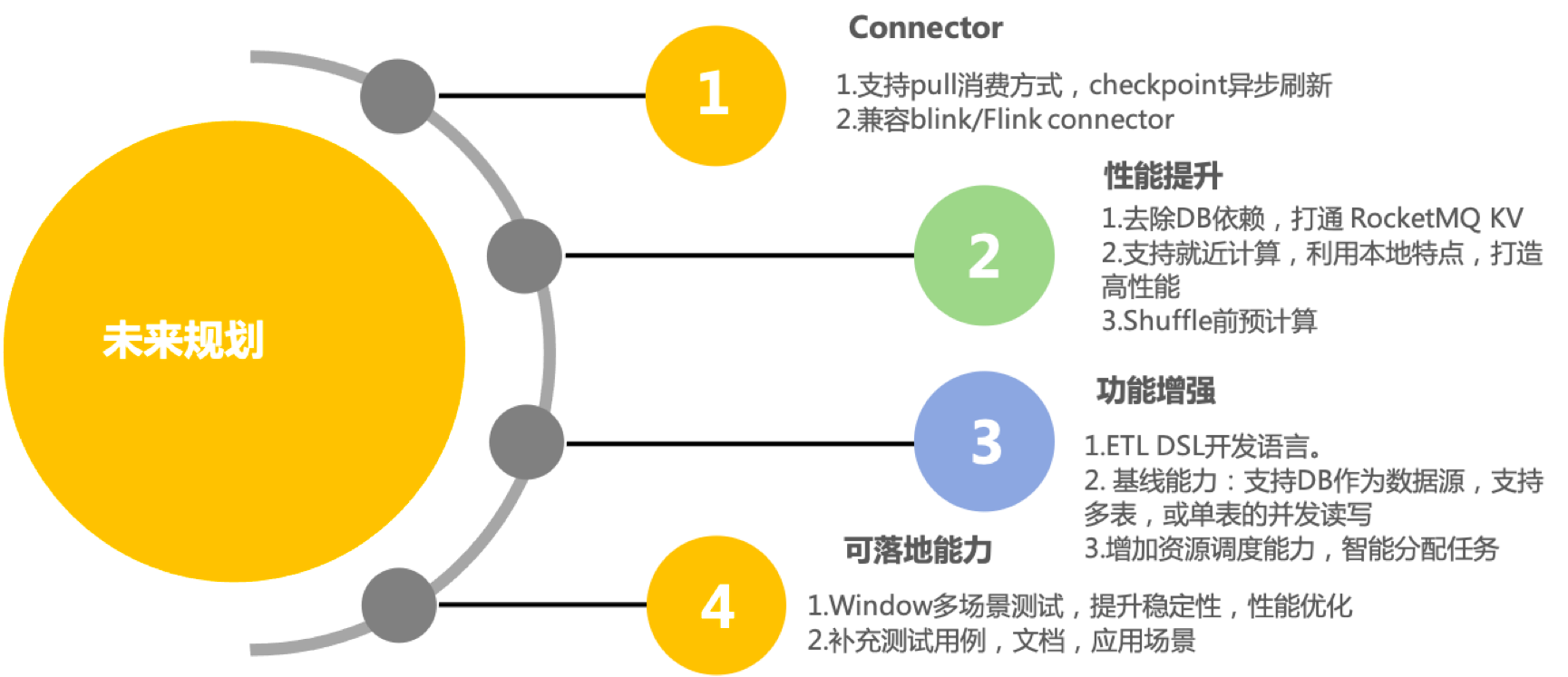
袁小栋、杜恒:目标还是打造最快的轻量计算引擎,需要把轻和快做到极致。如利用 RocketMQ 架构的优势做本地计算、KV 作为远程存储等; ETL 也会是我们将来拓展的一种场景,开发 DSL,支持热更新的 ETL 也是我们将来的一个重点方向;除此之外,会积极的融入 Flink 生态,取长补短,支持更广的计算场景。
嘉宾简介:
袁小栋:Apache RocketMQ Committer, rocketmq-streams cofunder,阿里云安全智能计算引擎负责人
杜恒:Aapache RocketMQ PMC member, OpenMessaging TSC member, 阿里云消息专有云及开源生态负责人
延伸阅读:
终于!RocketMQ 迎来第五个大版本,深度解读“消息、事件、流”超融合处理平台




