一个故事
距离伦敦 150 英里的地方有一座农庄,笨笨的农夫养着一大群动物。农场中的动物们虽然打打闹闹,但是每当农夫出现,这群聪明的动物马上就会乖起来。
“为什么呢?爸爸”我女儿每次听到这里都会问这个问题,“因为如果农夫能看见他们干坏事,就会不给他们东西吃”。
而在伦敦,农夫的儿子经营着一家十几个人的小电商网站。虽然他比他老爸聪明多了,但软件公司的秩序比农场要混乱百倍。客户的订单经常无法正常流转,而所有人花了两周时间也不知道问题出在哪里。
“这个就更奇怪了,他可比他老爸聪明多了?”女儿貌似陷入了更深的疑惑,“如果他看不出来谁在干坏事,再聪明的人也没有办法!”
当然第二个故事是我编的,我女儿根本不知道什么是电商。但聪明的读者,你们会理解这个故事的。
观察
农夫的儿子不会想到,目前一个新的理念悄然来临,或许可以解决他现实的问题。
今年,“可观察性”(Observability)被引入到了 IT 领域,其首先表现为 CNCF-Landscape 出现了 Observability 分组。

从该分组的内容看包含了监控,日志,Tracing 等领域的项目。同时 o11y 大会等该领域的专业会议也已经排上了日程表。
仿佛一夜之间这个概念已经沸沸扬扬,但一个尴尬的现象却摆在眼前,目前没有一个人能清楚的解释这个概念,并定义它的边界。对于一个全新的概念,人们倾向于从之前的认知来定义它。而在可观察性之前,我们常常使用“监控”这个概念。
可观察性与监控有什么不同?简单说来,后者是前者的一个子集。监控关注系统的失败因素,从而定义出系统的失败模型。它的核心是运维,是监控设施。他们站在局外人的角度,去审视系统的运行情况。而可观察性除了关注失败之外,其核心是研发,是应用,是对系统的一种自我审视。是站在创造者的角度去探究系统应如何恰当的展现自身的状态。一个由外向内,一个由内向外。所以可观察性并不是新生物,而是一种观念创新。
一个可观察的系统应包含三个关键词,应用,主动,关联。应用表明我们关注的不是机器,不是网络这些间接证据,而是关注应用本身的状态。我们关注应用真实的吞吐,延迟,而不是从网关上去推测这些指标。而主动是观测的一个核心,它相对于被动更能暴露出问题的实质,后者只能回答 What,而前者可以回答 Why。现如今,微服务大行其道,工程师仅仅关注“点”的问题已经不够了。点线面,甚至与点线面体的结合才能应对当今的挑战。
观察之源
一个新物种,肯定有它的起源。从原点出发,我们可以知道它为什么是如今的模样。
可观察性进入人们的视野是来自于 Apple 的工程师 Cindy Sridharan 的博文“监控与观察”(Monitoring and Oberservability)。其中重点阐述了监控与观察的关系,观察的特点等重要的理念。随后 Zipkin 的 PL Adrain Cole 也从 Zipkin 的角度谈了可观察性的实践方法。
但我认为,Google 著名的 SRE 体系在以上大佬之前已经奠定了可观察性的理论基础。该体系中在监控领域 (是的,当时还没有可观察性这个概念),特别强调白盒监控的重要性,而将当时技术圈常用的黑盒监控放在了相对次要的位置。而白盒监控正是应和了可观察性中“主动”的概念。
正因为 SRE 在整个云原生运动中的突出地位,越来越多的团队意识到,应该从系统建设之初去主动的规划监控指标。特别在一些强调自己云原生特性的项目,如 linkerd,traefik 等, 会主动设计可观测系统内部状况的入口。这些入口包括但不限于,Promethues 的 endpoint,Zipkin 协议的支持等。
观察之法
相信大家对可观察性已经了初步的认识,现在我来进一步解释如何在你的团队中应用它。
可观察性是一套理念系统。
其重点是团队要融入可观察性的理念,特别是要求研发写出的应用是可观察的。将可观察性包含在你的需求之中,它是与扩展性,可用性同等重要的非业务性需求。
这让我想起了 TDD 和极限编程流行的年代,重要的不是单元测试本身,而是对研发流程的治理。而将可观察性纳入到需求也是对产品的挑战,因为这项需求并不是业务需求,产品经理会非常轻视它。而我认为架构师和资深工程师应该肩负起将可观察性融入团队则责任,因为只有他们才会清醒的认识到它对系统的重要意义。
打造可观察性系统可以通过以下三个手段:
- Logging,展现的是应用运行而产生的事件,可以详细解释系统的运行状态,但是存储和查询需要消耗大量的资源。所以往往使用过滤器减少数据量。
- Metrics,是一种聚合数值,存储空间很小,可以观察系统的状态和趋势,但对于问题定位缺乏细节展示。这个时候使用等高线指标等多维数据结构来增强对于细节的表现力。
- Tracing,面向的是请求,可以轻松分析出请求中异常点,但与 logging 有相同的问题就是资源消耗较大。通常也需要通过采样的方式减少数据量。
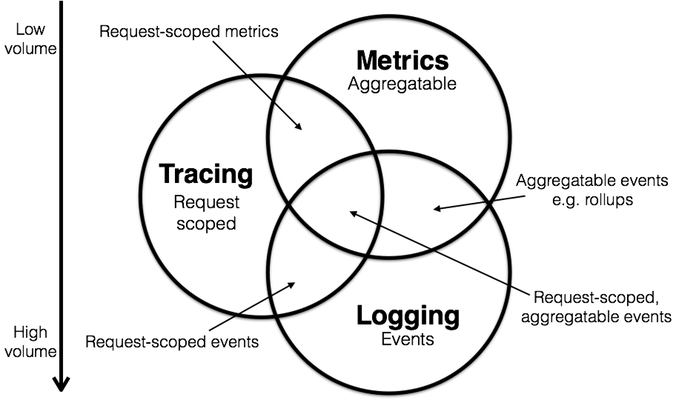
三种形式的组合使用将会产生丰富的观察数据。
其次可视化也是可观察性中比较强调的一点,这是由人类大脑倾向于形象思维所决定的。一行一行的系统指标数据根本不会比一张系统拓扑图更直观。直观的图形将帮助人们跟容易理解系统,发现问题。同时图形的大量引入也会减少人的疲劳感,增强趣味性。想象一下使用系统如同在玩一款即时战略游戏,那该是多每秒的一种体验。而大屏幕最近变得越来越流行,这也是对可视化有了更高的要求。对于相关观察数据来说,Tracing 和服务关系的可视化是观察系统的设计重点与难点。
最后是报警,报警在监控的体系是用于提示系统异常。而在观察的体系下,更多了一层过滤繁杂信息的作用。设想一下在一个超过1000 个节点的环境中存在大量的观察指标,究竟人们需要关注什么?而通过对报警规则的设置,从而提示出需要注意的一些特殊的事件,而这些事件往往成为影响系统稳定的关键因素。
接下来是具体工具的介绍,Zipkin,Jaeger 等关注与Tracing 领域。fluentd,elk 等等是logging 领域的典型代表。而promethues,grafana,influxdb 则是Metrics 领域的前去。而我所在的Apache Skywalking 则是融合了Tracing 和Metrics,目标是最大限度的实践可观察性的理念。
观察之道
“道”的理念是强调事物的本源,如果我们仅仅被“可观察性”带来的外部工具这个表象所吸引,而没有认识到其内在的驱动动力,就很容易在实践“可观察性”时犯错误。
首先可观察性带来了团队文化的转变,让我以DevOps 做一个类比。DevOps 中一个重要的概念是强调研发与运维的无缝配合,从而形成一个整体。而可观察性的语境下,研发是主体,他首先需要主动考虑如何将应用的那些关键指标以什么形式暴露出去。而之前大部分研发只有在应用出现故障的时候,才会考虑在什么位置加个日志看看。这是巨大的进步,将研发与运维的关系从Tom 和Jerry 转换为了海尔兄弟。你看,这是一幅多么美妙的情景啊!
其次,可观察性有利于系统的生长,工程师之间流传这样一句名言:系统不是设计出来的,而是长出来的。而掌握了观察之法,人们会了解到系统目前的实际情况,系统不再是一张静态的架构图,而是一个鲜活的生命体。从现在的位置出发,大家会有无限的灵感来打造系统的生长方向。甚至基于大数据与人工智能可以模拟采用哪种方向会带来更好的结果。这种交互设计方式将给整个IT 产业带来革命性的变化。
最后,观察会带来外部的关注。有这样一个故事,有一家互联网公司使用Skywalking 的一大目的就是利用其应用拓扑图的功能,向投资人解释该公司的技术实力。这非常震撼,可观察性降低了人们理解系统的门槛,从而获得更多的关注,而关注本身就是一种稀缺资源。同时如果各方都能对系统有一些理解,那么产品与研发,运营与研发的关系我觉得可以更加和谐。
故事的结局
回到最开始的故事,农夫的儿子需要一双观察之眼好好的审视系统的情况。希望他也能如他父亲一样,可以容易的管理他自己的Cat 和Cattle 们。

最后,我所在的Apache Skywalking( https://github.com/apache/incubator-skywalking ) 项目致力于在分布式追踪和 APM 领域提供全面的解决方案。目前项目正在实践可观察性的相关理论。本月 22 日,Skywalking 与 Zipkin 强强联合举办一场别开生面的沙龙。届时项目 PMC 彭勇升将详细给您带来 Skywalking 对于观察这个理念的深入思考。欢迎大家积极报名参加。活动链接: https://skywalking.hdh.im/
本文作者
高洪涛,Bitmain 资深工程师。原华为技术专家,目前为 Apache SkyWalking (incubating) PMC。开源达人,曾参与 Sharding-JDBC,Elastic-Job 等知名开源项目。对区块链,分布式数据库,容器调度,微服务,ServicMesh 等技术有深入的了解。




