
Meta 发布了 Llama 3.3,这是一款多语言大语言模型,旨在支持研究和行业中的一系列人工智能应用。该模型具有 128k 个 token 上下文窗口,并对架构进行了改进以提高效率,在推理、编码和多语言任务的基准测试中表现出色。该模型在 Hugging Face 上以社区许可的形式提供。
Llama 3.3 对之前版本进行了改进,具有更长的上下文窗口,长达 128k 个 token,并使用分组查询注意力(Grouped-Query Attention,GQA)优化了 Transformer 架构,以实现更好的可扩展性和效率。它通过将监督学习和基于人类反馈的强化学习相结合来进行微调,确保在各种任务中的出色表现,同时保持有用性和安全性。
该模型在关键基准测试中表现出色。这个拥有 700 亿个参数的模型在多语言对话、推理、编码和安全评估方面的表现优于开源和专有替代方案:
推理和知识:Llama 3.3 在具有挑战性的 GPQA 推理基准上,准确率达到了 50.5%,与其前身相比,有所改进。
代码生成:该模型在 HumanEval 编码基准上,pass@1 达到了 88.4%,为人工智能辅助编程设定了高标准。
多语言能力:在多语言推理基准 MGSM 上,Llama 3.3 的精确匹配(EM)得分为 91.1%。
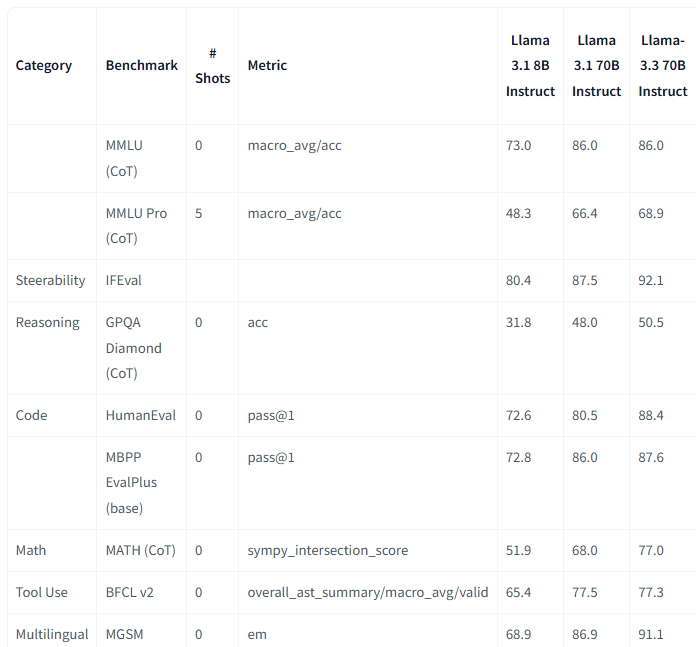
来源:Hugging Face 博客
该模型的多语言流畅性和文本生成能力使其适用于构建人工智能助手、开发软件和生成内容。它对工具集成的支持使其能够与三方应用程序协同工作,以执行数据检索、计算和合成数据生成等任务。
Meta 在模型开发过程中也将安全性放在了首位。Llama 3.3 采用了强有力的拒绝策略来应对潜在的有害提示,并在响应中保持了平衡的语气。鼓励开发人员将其部署在包含了安全保障措施的人工智能系统中,例如 Meta 的 Prompt Guard 和 Code Shield 等,以增强安全性。
该版本在社区中引发了关于其实际潜力的深刻讨论。Bulcode 首席执行官 Mihail Shahov 强调了 Llama 3.3 等紧凑型机型在企业应用中日益重要的作用:
像 Llama 3.3 这样较小的模型在企业级应用程序中无疑是越来越受欢迎了,特别是对于那些需要效率、成本效益和快速部署的任务来说。它们的适应性使其非常适用于客户服务、个性化和轻量级分析等用例——在这些场景中,速度和可负担性往往比对极端深度的需求更重要。
从长远来看,我认为混合方法将会成为常态:紧凑型模型处理大多数日常工作负载,而较大的模型则用于应对小众、高复杂性的挑战。归根结底,这是关于将工具与任务相匹配的问题——紧凑型模型用于可扩展性和可访问性,大模型用于突破性创新。
同样,CloudAngles 的首席执行官 Revathipathi Namballa 分享 了他们组织采用 Llama 3.3 的计划:
这是个好消息。在 CloudAngles,我们已经成功地将我们的 mlangles AI 平台与 Llama 3.2 集成在了一起。随着 3.3 版本的发布,我们已经为部署此升级做好了充分的准备来使我们的客户受益。
非常感谢整个 Meta 团队,感谢他们在推动人工智能创新方面所做出的卓越努力,并使这些进步变得触手可及,以便我们能够探索新的可能性。
该模型可在 Llama 3.3 社区许可证 下访问,检查点托管在 Hugging Face 上。开发人员可以使用诸如 Transformers 之类的流行框架来运行该模型,并利用量化版本来降低硬件需求。Meta 邀请社区提供反馈,以完善未来的迭代并推进人工智能安全标准。
更多详细信息可以在 Llama 3.3 的存储库中找到。
作者介绍
Robert Krzaczyński 是一名专门研究微软技术的软件工程师。他每天主要使用.NET 开发软件,但他的兴趣远不止于此。除了核心专业知识外,Robert 还对机器学习和人工智能有着浓厚的兴趣,不断扩展他自己在这些前沿领域的知识。他拥有控制工程和机器人工程学士学位和计算机科学硕士学位。
原文链接:




