
10 月 16 日,继上半年千亿参数模型 Yi-Large 之后,零一万物正式对外发布最新旗舰模型 Yi-Lightning。与 Yi-Large 相比,Yi-Lightning 在模型性能更进一步的前提下,推理速度方面也迎来极大提升。
零一万物内部评测数据显示,在 8xH100 算力基础下,以同样的任务规模进行测试,Yi-Lightning 的首包时间(从接收到任务请求到系统开始输出响应结果之间的时间)仅为 Yi-Large 的一半,最高生成速度也提升了近四成,大幅实现了旗舰模型的性能升级。
外部模型中,零一万物选择与 GPT-4o 做对比:
据零一万物介绍,Yi-Lightning 推理速度的提升,一方面得益于其自身的 AI Infra 能力,另一方面,Yi-Lightning 选择采用 Mixture of Experts(MoE)混合专家模型架构,并在模型训练过程中做了新的尝试。
MoE 模型由多个专家网络(Experts)构成,这种模型设计使其能够根据任务难度,动态选择激活哪些专家网络,这种动态选择机制旨在平衡推理成本和模型性能,确保模型在处理不同难度任务时既高效又准确。在训练过程中,MoE 模型会激活所有专家网络,以确保模型能够学习到所有专家的知识;而在推理阶段,根据任务的难度,模型只会选择性地激活更匹配的专家网络。
激活参数的规模和模型总参数的规模是 MoE 模型的两个关键概念。通常来说,激活参数与模型总参数的比例越大,模型的稀疏度就越高。虽然稀疏度的增加会极大程度上降低训练和推理成本,但是也会导致模型性能下降,显著加大训练难度。因此,如何在保持模型性能接近最优的同时,尽可能减少激活参数的数量以降低训推成本、提升推理速度,是 MoE 模型训练的重点目标。
具体到 Yi-Lightning 模型的训练,零一万物的模型团队进行了如下尝试,并取得了正向反馈:
独特的混合注意力机制(Hybrid Attention)。与 Mistral AI 采用的 Sliding Window Attention(滑动窗口注意力机制)不同,零一万物采用了混合注意力机制(Hybrid Attention),只在模型的部分层次中将传统的全注意力(Full Attention)替换为滑动窗口注意力(Sliding Window Attention),以平衡模型在处理长序列数据时的性能和计算资源消耗。此外,零一万物还引入了跨层注意力(Cross-Layer Attention, CLA)的设计,允许模型在不同的层次之间共享键(Key)和值(Value)头,从而减少对存储资源的需求。通过应用跨层注意力, Yi-Lightning 能够在不同层次之间更有效地共享信息,进一步提高了模型的推理效率。据悉,通过结合这两项技术,Yi-Lightning 在面对长序列数据时,KV 缓存大小实现了 2 倍至 4 倍的减少;某些层次的计算复杂度也由序列长度的平方级降低到线性级。
动态 Top-P 路由。动态 Top-P 路由就像是 MoE 模型中做出选择的“把关人”,可以根据任务的难度动态自动选择最合适的专家网络组合,而无需人工干预。与传统的 Top-K 路由机制相比,动态 Top-P 路由能够更灵活地根据任务的难度调整激活的专家网络数量,从而更好地平衡推理成本和模型性能。动态 Top-P 路由机制的引入也是 Yi-Lightning 能够实现“极速推理”的一大原因。
多阶段训练(Multi-stage Training)。在 Yi-Lightning 的训练规划中,零一万物还改进了单阶段训练,使用了多阶段的训练模式。训练前期,零一万物模型团队更加注重数据的多样性,让模型尽可能广泛吸收不同的知识;而在训练后期则会更加侧重内容更丰富、知识性更强的数据。通过各有侧重的方式, Yi-Lightning 得以在不同阶段吸收不同的知识,既便于模型团队进行数据配比的调试工作,同时在不同阶段采用不同的 batch size 和 LR schedule 来保证训练速度和稳定性。在有较多新增数据、或者想要对模型进行专有化时,零一万物也可以基于 Yi-Lightning 进行快速、低成本的重新训练。
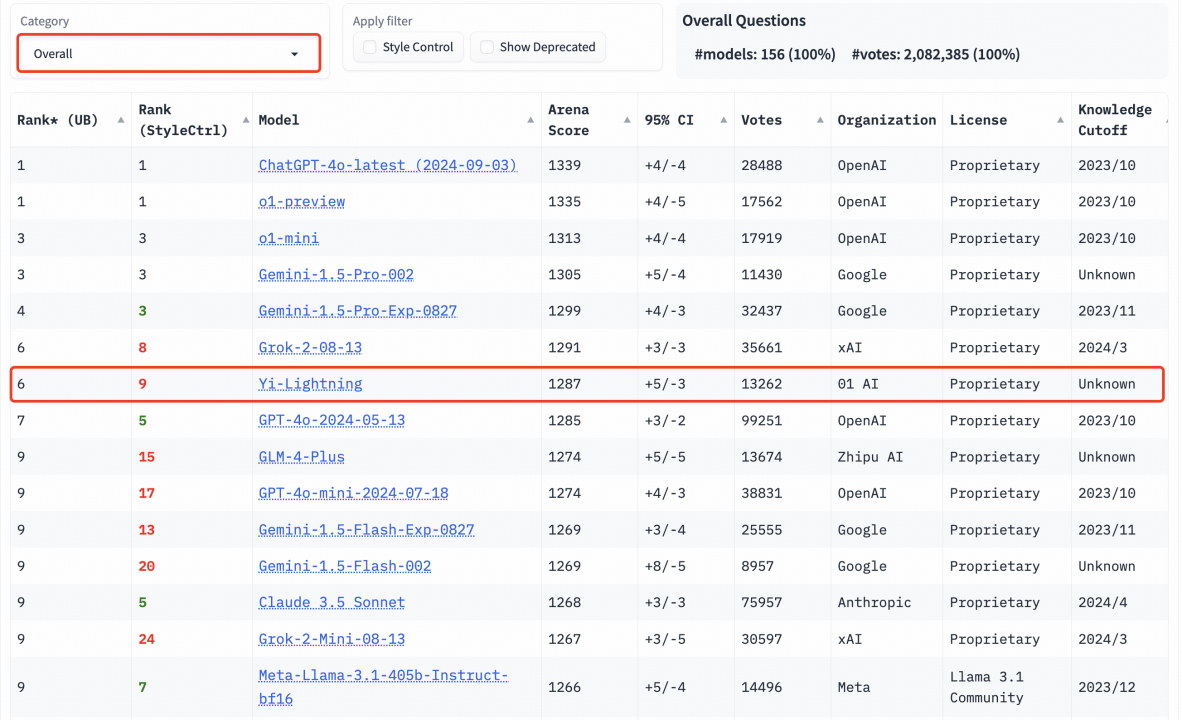
在国际权威盲测榜单 LMSYS 上,Yi-Lightning 超越 GPT-4o-2024-05-13、Claude 3.5 Sonnet,排名世界第六,中国第一。
目前,Yi-Lightning 已上线 Yi 大模型开放平台(https://platform.lingyiwanwu.com/),每百万 token 仅需 0.99 元,直逼行业最低价。
李开复明确表示,零一万物在 Yi-Lightning 的定价上并没有亏本。“零一万物也在做 App,我们知道做 App 需要控制成本,所以我们不会赔钱卖模型,但也不会赚很多钱,而是在成本线上加一点点小小的利润,就得到了今天 0.99 元/百万 token 的价格。”
李开复表示,“从成立的第一天起,零一万物就同时启动了模型训练、AI Infra、AI 应用三大团队,当三个团队都成熟了以后再对接到一起。零一万物将这一模式总结为模基共建、模应一体两大战略——AI Infra 能力助力模型训练和推理,以更低的训练成本训练出性能领先的模型,以更低的推理成本支撑应用层的探索。”
发布会上,李开复也再次回应了关于此前有称大模型公司放弃预训练的传闻。“据我所知,这六家公司融资额度都是够的,我们做预训练的 production run,训练一次三、四百万美金,这个钱头部公司都付得起,我觉得中国的六家大模型公司只要有够好的人才,想做预训练的决心,融资额跟芯片都不会是问题的。”
首度发布 AI 2.0 数字人
此外,零一万物也首度对媒体公布了全新 ToB 战略下的首发行业应用产品 AI 2.0 数字人,聚焦零售和电商等场景,将最新版旗舰模型 Yi Lightning 实践于具体行业解决方案。
基于以 Yi Lightning 模型为代表的 Yi 模型,零一万物搭建起了包含角色大模型、直播声音大模型、电商话术大模型在内的一整套专用模型基座,形成了与 AI 1.0 时代完全不同的数字人解决方案。角色大模型为零一万物 AI 2.0 数字人提供了动作训练、表情生成等能力,直播声音大模型使得数字人迈过了多国语言和情感表达的门槛,电商话术大模型则成为了数字人主播的“AI 大脑”,负责链接知识库,完成智能对话。
零一万物表示,AI 2.0 数字人配备了“AI 大脑”——在电商话术大模型加持下,数字人能够基于模型自有知识库与外接数据库,自主生成直播话术,也能够快速、精准地识别直播弹幕的互动意图,给出对应解答。
Yi-Lightning 模型接入后,零一万物 AI 2.0 数字人对弹幕意图的识别更加精准、生成话术更自然、能够一步到位完成促单。随着与客户合作进程的不断深入,基于模型本身强大的函数调用能力,零一万物 AI 2.0 数字人还能够丝滑地与客户原有营销、物流系统互动,实现从引流到下单的全流程陪护。
据介绍,零一万物的 AI 2.0 数字人解决方案涵盖了 AI 伴侣、IP 形象、电商直播、办公会议等多个应用场景,合作案例包括全国某著名餐饮连锁、某头部酒旅类客户、全国某知名水果连锁店等,均取得了显著的 GMV 提升。其中某头部酒旅企业在接入 Yi-Lightning 全新加持的数字人直播后,GMV 较此前上升 170%。
“这样的 to B 工作只能在中国做,因为要触达美国的用户或国外的用户不太可能,所以全世界的范畴来说,to B 供应商基本都是当地的,即便在中国要买 SAP 的产品也是 SAP 中国卖给你,所以跨国设立分公司做 to B 绝对不是我们或其他创业公司能做的,所以 to B 的国外就放弃了,做 to B 就做国内,做 to B 就做有利润的解决方案,而不只是卖模型,不只是做项目制,这是我们 to B 的做法。”李开复表示。
而零一万物的 to C 布局主要在海外。首先,当团队开始做零一万物时国内还没有合适的中文模型,只有在国外先尝试,尝试了一段时间后就有了心得,迭代出了一些比较好的产品。其次,to C 产品在中国国内走流量有一个很大的问题,流量的成本越来越高但用户可能还有相当的流失,在这样的环境里就要非常谨慎。“现在当下最大的理由还是国外做 to C 产品,我们变现能力和消耗用户增长的成本算账可以算得过来,以后再关注国内有什么机会可以推出。”李开复表示。




