1. 背景
1.1. Netty 3.X 系列版本现状
根据对 Netty 社区部分用户的调查,结合 Netty 在其它开源项目中的使用情况,我们可以看出目前 Netty 商用的主流版本集中在 3.X 和 4.X 上,其中以 Netty 3.X 系列版本使用最为广泛。
Netty 社区非常活跃,3.X 系列版本从 2011 年 2 月 7 日发布的 netty-3.2.4 Final 版本到 2014 年 12 月 17 日发布的 netty-3.10.0 Final 版本,版本跨度达 3 年多,期间共推出了 61 个 Final 版本。
1.2. 升级还是坚守老版本
相比于其它开源项目,Netty 用户的版本升级之路更加艰辛,最根本的原因就是 Netty 4 对 Netty 3 没有做到很好的前向兼容。
由于版本不兼容,大多数老版本使用者的想法就是既然升级这么麻烦,我暂时又不需要使用到 Netty 4 的新特性,当前版本还挺稳定,就暂时先不升级,以后看看再说。
坚守老版本还有很多其它的理由,例如考虑到线上系统的稳定性、对新版本的熟悉程度等。无论如何升级 Netty 都是一件大事,特别是对 Netty 有直接强依赖的产品。
从上面的分析可以看出,坚守老版本似乎是个不错的选择;但是,“理想是美好的, 现实却是残酷的”,坚守老版本并非总是那么容易,下面我们就看下被迫升级的案例。
1.3. “被迫”升级到 Netty 4.X
除了为了使用新特性而主动进行的版本升级,大多数升级都是“被迫的”。下面我们对这些升级原因进行分析。
- 公司的开源软件管理策略:对于那些大厂,不同部门和产品线依赖的开源软件版本经常不同,为了对开源依赖进行统一管理,降低安全、维护和管理成本,往往会指定优选的软件版本。由于 Netty 4.X 系列版本已经非常成熟,因为,很多公司都优选 Netty 4.X 版本。
- 维护成本:无论是依赖 Netty 3.X,还是 Netty4.X,往往需要在原框架之上做定制。例如,客户端的短连重连、心跳检测、流控等。分别对 Netty 4.X 和 3.X 版本实现两套定制框架,开发和维护成本都非常高。根据开源软件的使用策略,当存在版本冲突的时候,往往会选择升级到更高的版本。对于 Netty,依然遵循这个规则。
- 新特性:Netty 4.X 相比于 Netty 3.X, 提供了很多新的特性,例如优化的内存管理池、对 MQTT 协议的支持等。如果用户需要使用这些新特性,最简便的做法就是升级 Netty 到 4.X 系列版本。
- 更优异的性能:Netty 4.X 版本相比于 3.X 老版本,优化了内存池,减少了 GC 的频率、降低了内存消耗;通过优化 Rector 线程池模型,用户的开发更加简单,线程调度也更加高效。
1.4. 升级不当付出的代价
表面上看,类库包路径的修改、API 的重构等似乎是升级的重头戏,大家往往把注意力放到这些“明枪”上,但真正隐藏和致命的却是“暗箭”。如果对 Netty 底层的事件调度机制和线程模型不熟悉,往往就会“中枪”。
本文以几个比较典型的真实案例为例,通过问题描述、问题定位和问题总结,让这些隐藏的“暗箭”不再伤人。
由于 Netty 4 线程模型改变导致的升级事故还有很多,限于篇幅,本文不一一枚举,这些问题万变不离其宗,只要抓住线程模型这个关键点,所谓的疑难杂症都将迎刃而解。
2. Netty 升级之后遭遇内存泄露
2.1. 问题描述
随着 JVM 虚拟机和 JIT 即时编译技术的发展,对象的分配和回收是个非常轻量级的工作。但是对于缓冲区 Buffer,情况却稍有不同,特别是对于堆外直接内存的分配和回收,是一件耗时的操作。为了尽量重用缓冲区,Netty4.X 提供了基于内存池的缓冲区重用机制。性能测试表明,采用内存池的 ByteBuf 相比于朝生夕灭的 ByteBuf,性能高 23 倍左右(性能数据与使用场景强相关)。
业务应用的特点是高并发、短流程,大多数对象都是朝生夕灭的短生命周期对象。为了减少内存的拷贝,用户期望在序列化的时候直接将对象编码到 PooledByteBuf 里,这样就不需要为每个业务消息都重新申请和释放内存。
业务的相关代码示例如下:
// 在业务线程中初始化内存池分配器,分配非堆内存
ByteBufAllocator allocator = new PooledByteBufAllocator(true);
ByteBuf buffer = allocator.ioBuffer(1024);
// 构造订购请求消息并赋值,业务逻辑省略
SubInfoReq infoReq = new SubInfoReq ();
infoReq.setXXX(......);
// 将对象编码到 ByteBuf 中
codec.encode(buffer, info);
// 调用 ChannelHandlerContext 进行消息发送
ctx.writeAndFlush(buffer);
业务代码升级 Netty 版本并重构之后,运行一段时间,Java 进程就会宕机,查看系统运行日志发现系统发生了内存泄露(示例堆栈):
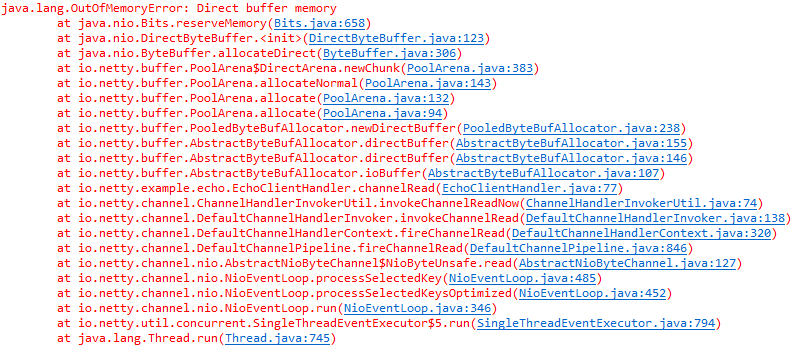
图 2-1 OOM 内存溢出堆栈
对内存进行监控(切换使用堆内存池,方便对内存进行监控),发现堆内存一直飙升,如下所示(示例堆内存监控):
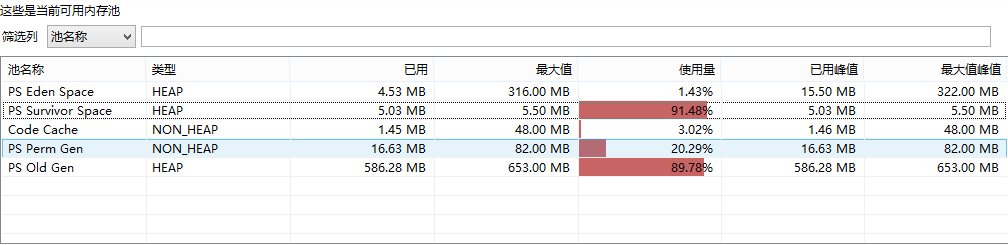
图 2-2 堆内存监控
2.2. 问题定位
使用 jmap -dump:format=b,file=netty.bin PID 将堆内存 dump 出来,通过 IBM 的 HeapAnalyzer 工具进行分析,发现 ByteBuf 发生了泄露。
因为使用了内存池,所以首先怀疑是不是申请的 ByteBuf 没有被释放导致?查看代码,发现消息发送完成之后,Netty 底层已经调用 ReferenceCountUtil.release(message) 对内存进行了释放。这是怎么回事呢?难道 Netty 4.X 的内存池有 Bug,调用 release 操作释放内存失败?
考虑到 Netty 内存池自身 Bug 的可能性不大,首先从业务的使用方式入手分析:
- 内存的分配是在业务代码中进行,由于使用到了业务线程池做 I/O 操作和业务操作的隔离,实际上内存是在业务线程中分配的;
- 内存的释放操作是在 outbound 中进行,按照 Netty 3 的线程模型,downstream(对应 Netty 4 的 outbound,Netty 4 取消了 upstream 和 downstream)的 handler 也是由业务调用者线程执行的,也就是说释放跟分配在同一个业务线程中进行。
初次排查并没有发现导致内存泄露的根因,一筹莫展之际开始查看 Netty 的内存池分配器 PooledByteBufAllocator 的 Doc 和源码实现,发现内存池实际是基于线程上下文实现的,相关代码如下:
final ThreadLocal<PoolThreadCache> threadCache = new ThreadLocal<PoolThreadCache>() {
private final AtomicInteger index = new AtomicInteger();
@Override
protected PoolThreadCache initialValue() {
final int idx = index.getAndIncrement();
final PoolArena<byte[]> heapArena;
final PoolArena<ByteBuffer> directArena;
if (heapArenas != null) {
heapArena = heapArenas[Math.abs(idx % heapArenas.length)];
} else {
heapArena = null;
}
if (directArenas != null) {
directArena = directArenas[Math.abs(idx % directArenas.length)];
} else {
directArena = null;
}
return new PoolThreadCache(heapArena, directArena);
}
也就是说内存的申请和释放必须在同一线程上下文中,不能跨线程。跨线程之后实际操作的就不是同一块内存区域,这会导致很多严重的问题,内存泄露便是其中之一。内存在 A 线程申请,切换到 B 线程释放,实际是无法正确回收的。
通过对 Netty 内存池的源码分析,问题基本锁定。保险起见进行简单验证,通过对单条业务消息进行 Debug,发现执行释放的果然不是业务线程,而是 Netty 的 NioEventLoop 线程:当某个消息被完全发送成功之后,会通过 ReferenceCountUtil.release(message) 方法释放已经发送成功的 ByteBuf。
问题定位出来之后,继续溯源,发现 Netty 4 修改了 Netty 3 的线程模型:在 Netty 3 的时候,upstream 是在 I/O 线程里执行的,而 downstream 是在业务线程里执行。当 Netty 从网络读取一个数据报投递给业务 handler 的时候,handler 是在 I/O 线程里执行;而当我们在业务线程中调用 write 和 writeAndFlush 向网络发送消息的时候,handler 是在业务线程里执行,直到最后一个 Header handler 将消息写入到发送队列中,业务线程才返回。
Netty4 修改了这一模型,在 Netty 4 里 inbound(对应 Netty 3 的 upstream) 和 outbound(对应 Netty 3 的 downstream) 都是在 NioEventLoop(I/O 线程) 中执行。当我们在业务线程里通过 ChannelHandlerContext.write 发送消息的时候,Netty 4 在将消息发送事件调度到 ChannelPipeline 的时候,首先将待发送的消息封装成一个 Task,然后放到 NioEventLoop 的任务队列中,由 NioEventLoop 线程异步执行。后续所有 handler 的调度和执行,包括消息的发送、I/O 事件的通知,都由 NioEventLoop 线程负责处理。
下面我们分别通过对比 Netty 3 和 Netty 4 的消息接收和发送流程,来理解两个版本线程模型的差异:
Netty 3 的 I/O 事件处理流程:
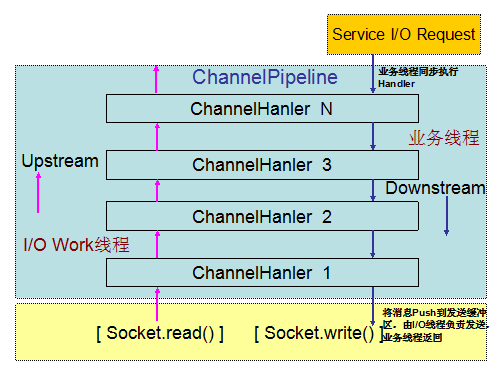
图 2-3 Netty 3 I/O 事件处理线程模型
Netty 4 的 I/O 消息处理流程:
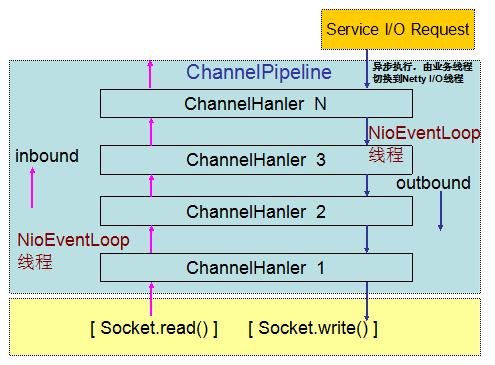
图 2-4 Netty 4 I/O 事件处理线程模型
2.3. 问题总结
Netty 4.X 版本新增的内存池确实非常高效,但是如果使用不当则会导致各种严重的问题。诸如内存泄露这类问题,功能测试并没有异常,如果相关接口没有进行压测或者稳定性测试而直接上线,则会导致严重的线上问题。
内存池 PooledByteBuf 的使用建议:
- 申请之后一定要记得释放,Netty 自身 Socket 读取和发送的 ByteBuf 系统会自动释放,用户不需要做二次释放;如果用户使用 Netty 的内存池在应用中做 ByteBuf 的对象池使用,则需要自己主动释放;
- 避免错误的释放:跨线程释放、重复释放等都是非法操作,要避免。特别是跨线程申请和释放,往往具有隐蔽性,问题定位难度较大;
- 防止隐式的申请和分配:之前曾经发生过一个案例,为了解决内存池跨线程申请和释放问题,有用户对内存池做了二次包装,以实现多线程操作时,内存始终由包装的管理线程申请和释放,这样可以屏蔽用户业务线程模型和访问方式的差异。谁知运行一段时间之后再次发生了内存泄露,最后发现原来调用 ByteBuf 的 write 操作时,如果内存容量不足,会自动进行容量扩展。扩展操作由业务线程执行,这就绕过了内存池管理线程,发生了“引用逃逸”。该 Bug 只有在 ByteBuf 容量动态扩展的时候才发生,因此,上线很长一段时间没有发生,直到某一天…因此,大家在使用 Netty 4.X 的内存池时要格外当心,特别是做二次封装时,一定要对内存池的实现细节有深刻的理解。
3. Netty 升级之后遭遇数据被篡改
3.1. 问题描述
某业务产品,Netty3.X 升级到 4.X 之后,系统运行过程中,偶现服务端发送给客户端的应答数据被莫名“篡改”。
业务服务端的处理流程如下:
- 将解码后的业务消息封装成 Task,投递到后端的业务线程池中执行;
- 业务线程处理业务逻辑,完成之后构造应答消息发送给客户端;
- 业务应答消息的编码通过继承 Netty 的 CodeC 框架实现,即 Encoder ChannelHandler;
- 调用 Netty 的消息发送接口之后,流程继续,根据业务场景,可能会继续操作原发送的业务对象。
业务相关代码示例如下:
// 构造订购应答消息
SubInfoResp infoResp = new SubInfoResp();
// 根据业务逻辑,对应答消息赋值
infoResp.setResultCode(0);
infoResp.setXXX();
后续赋值操作省略......
// 调用 ChannelHandlerContext 进行消息发送
ctx.writeAndFlush(infoResp);
// 消息发送完成之后,后续根据业务流程进行分支处理,修改 infoResp 对象
infoResp.setXXX();
后续代码省略......
3.2. 问题定位
首先对应答消息被非法“篡改”的原因进行分析,经过定位发现当发生问题时,被“篡改”的内容是调用 **writeAndFlush接口之后,由后续业务分支代码修改应答消息导致的。由于修改操作发生在writeAndFlush** 操作之后,按照 Netty 3.X 的线程模型不应该出现该问题。
在 Netty3 中,downstream 是在业务线程里执行的,也就是说对 _SubInfoResp_ 的编码操作是在业务线程中执行的,当编码后的 ByteBuf 对象被投递到消息发送队列之后,业务线程才会返回并继续执行后续的业务逻辑,此时修改应答消息是不会改变已完成编码的 ByteBuf 对象的,所以肯定不会出现应答消息被篡改的问题。
初步分析应该是由于线程模型发生变更导致的问题,随后查验了 Netty 4 的线程模型,果然发生了变化:当调用 outbound 向外发送消息的时候,Netty 会将发送事件封装成 Task,投递到 NioEventLoop 的任务队列中异步执行,相关代码如下:
@Override
public void invokeWrite(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) {
if (msg == null) {
throw new NullPointerException("msg");
}
validatePromise(ctx, promise, true);
if (executor.inEventLoop()) {
invokeWriteNow(ctx, msg, promise);
} else {
AbstractChannel channel = (AbstractChannel) ctx.channel();
int size = channel.estimatorHandle().size(msg);
if (size > 0) {
ChannelOutboundBuffer buffer = channel.unsafe().outboundBuffer();
// Check for null as it may be set to null if the channel is closed already
if (buffer != null) {
buffer.incrementPendingOutboundBytes(size);
}
}
safeExecuteOutbound(WriteTask.newInstance(ctx, msg, size, promise), promise, msg);
}
}
通过上述代码可以看出,Netty 首先对当前的操作的线程进行判断,如果操作本身就是由 NioEventLoop 线程执行,则调用写操作;否则,执行线程安全的写操作,即将写事件封装成 Task,放入到任务队列中由 Netty 的 I/O 线程执行,业务调用返回,流程继续执行。
通过源码分析,问题根源已经很清楚:系统升级到 Netty 4 之后,线程模型发生变化,响应消息的编码由 NioEventLoop 线程异步执行,业务线程返回。这时存在两种可能:
- 如果编码操作先于修改应答消息的业务逻辑执行,则运行结果正确;
- 如果编码操作在修改应答消息的业务逻辑之后执行,则运行结果错误。
由于线程的执行先后顺序无法预测,因此该问题隐藏的相当深。如果对 Netty 4 和 Netty3 的线程模型不了解,就会掉入陷阱。
Netty 3 版本业务逻辑没有问题,流程如下:
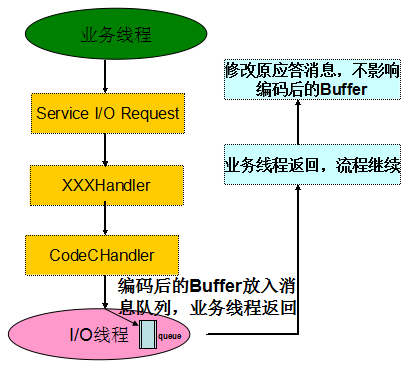
图 3-1 升级之前的业务流程线程模型
升级到 Netty 4 版本之后,业务流程由于 Netty 线程模型的变更而发生改变,导致业务逻辑发生问题:
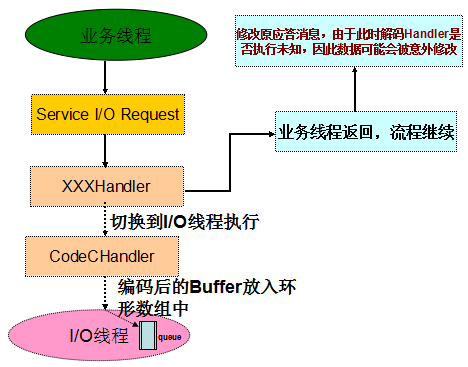
图 3-2 升级之后的业务处理流程发生改变
3.3. 问题总结
很多读者在进行 Netty 版本升级的时候,只关注到了包路径、类和 API 的变更,并没有注意到隐藏在背后的“暗箭”- 线程模型变更。
升级到 Netty 4 的用户需要根据新的线程模型对已有的系统进行评估,重点需要关注 outbound 的 ChannelHandler,如果它的正确性依赖于 Netty 3 的线程模型,则很可能在新的线程模型中出问题,可能是功能问题或者其它问题。
4. Netty 升级之后性能严重下降
4.1. 问题描述
相信很多 Netty 用户都看过如下相关报告:
在 Twitter,Netty 4 GC 开销降为五分之一:Netty 3 使用 Java 对象表示 I/O 事件,这样简单,但会产生大量的垃圾,尤其是在我们这样的规模下。Netty 4 在新版本中对此做出了更改,取代生存周期短的事件对象,而以定义在生存周期长的通道对象上的方法处理I/O 事件。它还有一个使用池的专用缓冲区分配器。
每当收到新信息或者用户发送信息到远程端,Netty 3 均会创建一个新的堆缓冲区。这意味着,对应每一个新的缓冲区,都会有一个‘new byte[capacity]’。这些缓冲区会导致GC 压力,并消耗内存带宽:为了安全起见,新的字节数组分配时会用零填充,这会消耗内存带宽。然而,用零填充的数组很可能会再次用实际的数据填充,这又会消耗同样的内存带宽。如果Java 虚拟机(JVM)提供了创建新字节数组而又无需用零填充的方式,那么我们本来就可以将内存带宽消耗减少50%,但是目前没有那样一种方式。
在Netty 4 中,代码定义了粒度更细的API,用来处理不同的事件类型,而不是创建事件对象。它还实现了一个新缓冲池,那是一个纯Java 版本的 jemalloc (Facebook 也在用)。现在,Netty 不会再因为用零填充缓冲区而浪费内存带宽了。
我们比较了两个分别建立在 Netty 3 和 4 基础上 echo 协议服务器。(Echo 非常简单,这样,任何垃圾的产生都是 Netty 的原因,而不是协议的原因)。我使它们服务于相同的分布式 echo 协议客户端,来自这些客户端的 16384 个并发连接重复发送 256 字节的随机负载,几乎使千兆以太网饱和。
根据测试结果,Netty 4:
- GC 中断频率是原来的 1/5: 45.5 vs. 9.2 次 / 分钟
- 垃圾生成速度是原来的 1/5: 207.11 vs 41.81 MiB/ 秒
正是看到了相关的 Netty 4 性能提升报告,很多用户选择了升级。事后一些用户反馈 Netty 4 并没有跟产品带来预期的性能提升,有些甚至还发生了非常严重的性能下降,下面我们就以某业务产品的失败升级经历为案例,详细分析下导致性能下降的原因。
4.2. 问题定位
首先通过 JMC 等性能分析工具对性能热点进行分析,示例如下(信息安全等原因,只给出分析过程示例截图):
图 4-1 JMC 性能监控分析
通过对热点方法的分析,发现在消息发送过程中,有两处热点:
- 消息发送性能统计相关 Handler;
- 编码 Handler。
对使用 Netty 3 版本的业务产品进行性能对比测试,发现上述两个 Handler 也是热点方法。既然都是热点,为啥切换到 Netty4 之后性能下降这么厉害呢?
通过方法的调用树分析发现了两个版本的差异:在 Netty 3 中,上述两个热点方法都是由业务线程负责执行;而在 Netty 4 中,则是由 NioEventLoop(I/O) 线程执行。对于某个链路,业务是拥有多个线程的线程池,而 NioEventLoop 只有一个,所以执行效率更低,返回给客户端的应答时延就大。时延增大之后,自然导致系统并发量降低,性能下降。
找出问题根因之后,针对 Netty 4 的线程模型对业务进行专项优化,性能达到预期,远超过了 Netty 3 老版本的性能。
Netty 3 的业务线程调度模型图如下所示:充分利用了业务多线程并行编码和 Handler 处理的优势,周期 T 内可以处理 N 条业务消息。
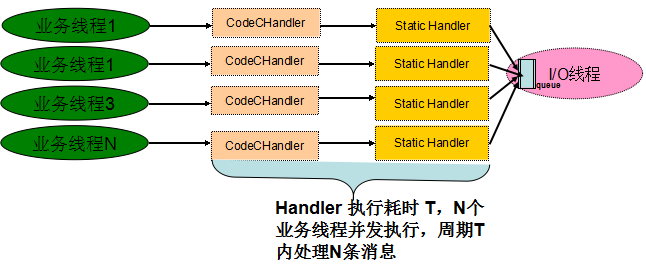
图 4-2 Netty 3 业务调度性能模型
切换到 Netty 4 之后,业务耗时 Handler 被 I/O 线程串行执行,因此性能发生比较大的下降:
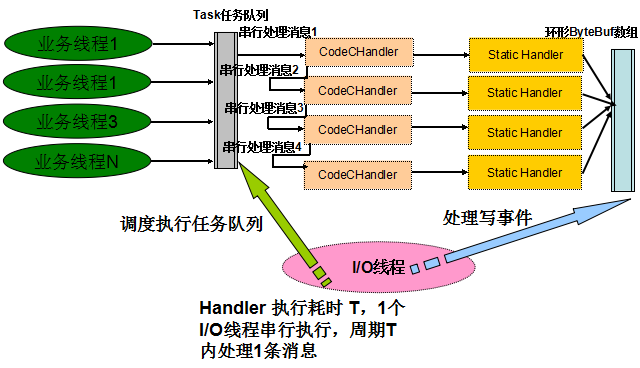
图 4-3 Netty 4 业务调度性能模型
4.3. 问题总结
该问题的根因还是由于 Netty 4 的线程模型变更引起,线程模型变更之后,不仅影响业务的功能,甚至对性能也会造成很大的影响。
对 Netty 的升级需要从功能、兼容性和性能等多个角度进行综合考虑,切不可只盯着 API 变更这个芝麻,而丢掉了性能这个西瓜。API 的变更会导致编译错误,但是性能下降却隐藏于无形之中,稍不留意就会中招。
对于讲究快速交付、敏捷开发和灰度发布的互联网应用,升级的时候更应该要当心。
5. Netty 升级之后上下文丢失
5.1. 问题描述
为了提升业务的二次定制能力,降低对接口的侵入性,业务使用线程变量进行消息上下文的传递。例如消息发送源地址信息、消息 Id、会话 Id 等。
业务同时使用到了一些第三方开源容器,也提供了线程级变量上下文的能力。业务通过容器上下文获取第三方容器的系统变量信息。
升级到 Netty 4 之后,业务继承自 Netty 的 ChannelHandler 发生了空指针异常,无论是业务自定义的线程上下文、还是第三方容器的线程上下文,都获取不到传递的变量值。
5.2. 问题定位
首先检查代码,看业务是否传递了相关变量,确认业务传递之后怀疑跟 Netty 版本升级相关,调试发现,业务 ChannelHandler 获取的线程上下文对象和之前业务传递的上下文不是同一个。这就说明执行 ChannelHandler 的线程跟处理业务的线程不是同一个线程!
查看 Netty 4 线程模型的相关 Doc 发现,Netty 修改了 outbound 的线程模型,正好影响了业务消息发送时的线程上下文传递,最终导致线程变量丢失。
5.3. 问题总结
通常业务的线程模型有如下几种:
- 业务自定义线程池 / 线程组处理业务,例如使用 JDK 1.5 提供的 ExecutorService;
- 使用 J2EE Web 容器自带的线程模型,常见的如 JBoss 和 Tomcat 的 HTTP 接入线程等;
- 隐式的使用其它第三方框架的线程模型,例如使用 NIO 框架进行协议处理,业务代码隐式使用的就是 NIO 框架的线程模型,除非业务明确的实现自定义线程模型。
在实践中我们发现很多业务使用了第三方框架,但是只熟悉 API 和功能,对线程模型并不清楚。某个类库由哪个线程调用,糊里糊涂。为了方便变量传递,又随意的使用线程变量,实际对背后第三方类库的线程模型产生了强依赖。当容器或者第三方类库升级之后,如果线程模型发生了变更,则原有功能就会发生问题。
鉴于此,在实际工作中,尽量不要强依赖第三方类库的线程模型,如果确实无法避免,则必须对它的线程模型有深入和清晰的了解。当第三方类库升级之后,需要检查线程模型是否发生变更,如果发生变化,相关的代码也需要考虑同步升级。
6. Netty3.X VS Netty4.X 之线程模型
通过对三个具有典型性的升级失败案例进行分析和总结,我们发现有个共性:都是线程模型改变惹的祸!
下面小节我们就详细得对 Netty3 和 Netty4 版本的 I/O 线程模型进行对比,以方便大家掌握两者的差异,在升级和使用中尽量少踩雷。
6.1 Netty 3.X 版本线程模型
Netty 3.X 的 I/O 操作线程模型比较复杂,它的处理模型包括两部分:
- Inbound:主要包括链路建立事件、链路激活事件、读事件、I/O 异常事件、链路关闭事件等;
- Outbound:主要包括写事件、连接事件、监听绑定事件、刷新事件等。
我们首先分析下 Inbound 操作的线程模型:
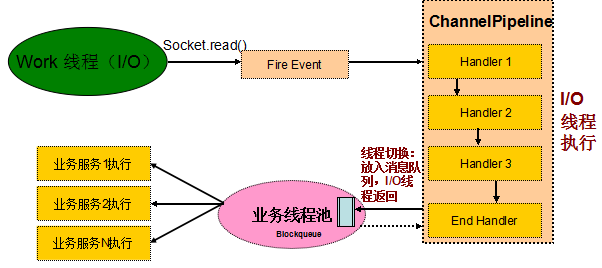
图 6-1 Netty 3 Inbound 操作线程模型
从上图可以看出,Inbound 操作的主要处理流程如下:
- I/O 线程(Work 线程)将消息从 TCP 缓冲区读取到 SocketChannel 的接收缓冲区中;
- 由 I/O 线程负责生成相应的事件,触发事件向上执行,调度到 ChannelPipeline 中;
- I/O 线程调度执行 ChannelPipeline 中 Handler 链的对应方法,直到业务实现的 Last Handler;
- Last Handler 将消息封装成 Runnable,放入到业务线程池中执行,I/O 线程返回,继续读 / 写等 I/O 操作;
- 业务线程池从任务队列中弹出消息,并发执行业务逻辑。
通过对 Netty 3 的 Inbound 操作进行分析我们可以看出,Inbound 的 Handler 都是由 Netty 的 I/O Work 线程负责执行。
下面我们继续分析 Outbound 操作的线程模型:
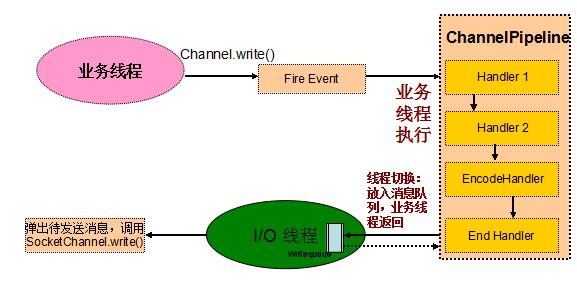
图 6-2 Netty 3 Outbound 操作线程模型
从上图可以看出,Outbound 操作的主要处理流程如下:
业务线程发起 Channel Write 操作,发送消息;
- Netty 将写操作封装成写事件,触发事件向下传播;
- 写事件被调度到 ChannelPipeline 中,由业务线程按照 Handler Chain 串行调用支持 Downstream 事件的 Channel Handler;
- 执行到系统最后一个 ChannelHandler,将编码后的消息 Push 到发送队列中,业务线程返回;
- Netty 的 I/O 线程从发送消息队列中取出消息,调用 SocketChannel 的 write 方法进行消息发送。
6.2 Netty 4.X 版本线程模型
相比于 Netty 3.X 系列版本,Netty 4.X 的 I/O 操作线程模型比较简答,它的原理图如下所示:
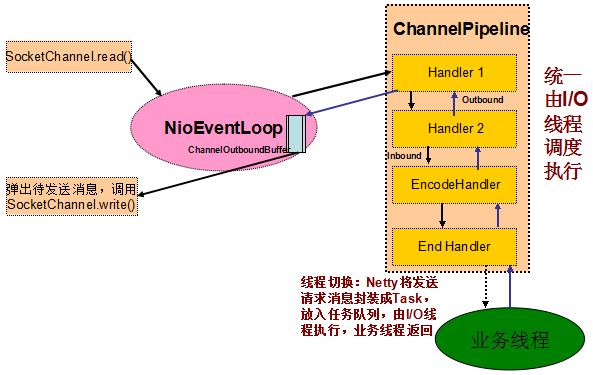
图 6-3 Netty 4 Inbound 和 Outbound 操作线程模型
从上图可以看出,Outbound 操作的主要处理流程如下:
- I/O 线程 NioEventLoop 从 SocketChannel 中读取数据报,将 ByteBuf 投递到 ChannelPipeline,触发 ChannelRead 事件;
- I/O 线程 NioEventLoop 调用 ChannelHandler 链,直到将消息投递到业务线程,然后 I/O 线程返回,继续后续的读写操作;
- 业务线程调用 ChannelHandlerContext.write(Object msg) 方法进行消息发送;
- 如果是由业务线程发起的写操作,ChannelHandlerInvoker 将发送消息封装成 Task,放入到 I/O 线程 NioEventLoop 的任务队列中,由 NioEventLoop 在循环中统一调度和执行。放入任务队列之后,业务线程返回;
- I/O 线程 NioEventLoop 调用 ChannelHandler 链,进行消息发送,处理 Outbound 事件,直到将消息放入发送队列,然后唤醒 Selector,进而执行写操作。
通过流程分析,我们发现 Netty 4 修改了线程模型,无论是 Inbound 还是 Outbound 操作,统一由 I/O 线程 NioEventLoop 调度执行。
6.3. 线程模型对比
在进行新老版本线程模型 PK 之前,首先还是要熟悉下串行化设计的理念:
我们知道当系统在运行过程中,如果频繁的进行线程上下文切换,会带来额外的性能损耗。多线程并发执行某个业务流程,业务开发者还需要时刻对线程安全保持警惕,哪些数据可能会被并发修改,如何保护?这不仅降低了开发效率,也会带来额外的性能损耗。
为了解决上述问题,Netty 4 采用了串行化设计理念,从消息的读取、编码以及后续 Handler 的执行,始终都由 I/O 线程 NioEventLoop 负责,这就意外着整个流程不会进行线程上下文的切换,数据也不会面临被并发修改的风险,对于用户而言,甚至不需要了解 Netty 的线程细节,这确实是个非常好的设计理念,它的工作原理图如下:
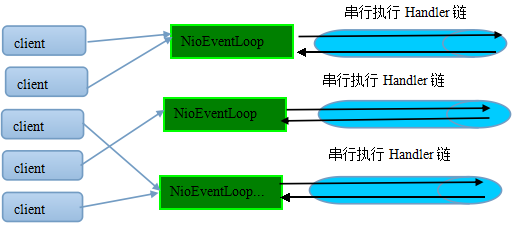
图 6-4 Netty 4 的串行化设计理念
一个 NioEventLoop 聚合了一个多路复用器 Selector,因此可以处理成百上千的客户端连接,Netty 的处理策略是每当有一个新的客户端接入,则从 NioEventLoop 线程组中顺序获取一个可用的 NioEventLoop,当到达数组上限之后,重新返回到 0,通过这种方式,可以基本保证各个 NioEventLoop 的负载均衡。一个客户端连接只注册到一个 NioEventLoop 上,这样就避免了多个 I/O 线程去并发操作它。
Netty 通过串行化设计理念降低了用户的开发难度,提升了处理性能。利用线程组实现了多个串行化线程水平并行执行,线程之间并没有交集,这样既可以充分利用多核提升并行处理能力,同时避免了线程上下文的切换和并发保护带来的额外性能损耗。
了解完了 Netty 4 的串行化设计理念之后,我们继续看 Netty 3 线程模型存在的问题,总结起来,它的主要问题如下:
- Inbound 和 Outbound 实质都是 I/O 相关的操作,它们的线程模型竟然不统一,这给用户带来了更多的学习和使用成本;
- Outbound 操作由业务线程执行,通常业务会使用线程池并行处理业务消息,这就意味着在某一个时刻会有多个业务线程同时操作 ChannelHandler,我们需要对 ChannelHandler 进行并发保护,通常需要加锁。如果同步块的范围不当,可能会导致严重的性能瓶颈,这对开发者的技能要求非常高,降低了开发效率;
- Outbound 操作过程中,例如消息编码异常,会产生 Exception,它会被转换成 Inbound 的 Exception 并通知到 ChannelPipeline,这就意味着业务线程发起了 Inbound 操作!它打破了 Inbound 操作由 I/O 线程操作的模型,如果开发者按照 Inbound 操作只会由一个 I/O 线程执行的约束进行设计,则会发生线程并发访问安全问题。由于该场景只在特定异常时发生,因此错误非常隐蔽!一旦在生产环境中发生此类线程并发问题,定位难度和成本都非常大。
讲了这么多,似乎 Netty 4 完胜 Netty 3 的线程模型,其实并不尽然。在特定的场景下,Netty 3 的性能可能更高,就如本文第 4 章节所讲,如果编码和其它 Outbound 操作非常耗时,由多个业务线程并发执行,性能肯定高于单个 NioEventLoop 线程。
但是,这种性能优势不是不可逆转的,如果我们修改业务代码,将耗时的 Handler 操作前置,Outbound 操作不做复杂业务逻辑处理,性能同样不输于 Netty 3,但是考虑内存池优化、不会反复创建 Event、不需要对 Handler 加锁等 Netty 4 的优化,整体性能 Netty 4 版本肯定会更高。
总而言之,如果用户真正熟悉并掌握了 Netty 4 的线程模型和功能类库,相信不仅仅开发会更加简单,性能也会更优!
6.4. 思考
就 Netty 而言,掌握线程模型的重要性不亚于熟悉它的 API 和功能。很多时候我遇到的功能、性能等问题,都是由于缺乏对它线程模型和原理的理解导致的,结果我们就以讹传讹,认为 Netty 4 版本不如 3 好用等。
不能说所有开源软件的版本升级一定都胜过老版本,就 Netty 而言,我认为 Netty 4 版本相比于老的 Netty 3,确实是历史的一大进步。
7. 作者简介
李林锋,2007 年毕业于东北大学,2008 年进入华为公司从事高性能通信软件的设计和开发工作,有 7 年 NIO 设计和开发经验,精通 Netty、Mina 等 NIO 框架和平台中间件,现任华为软件平台架构部架构师,《Netty 权威指南》作者。
联系方式:新浪微博 Nettying 微信:Nettying 微信公众号:Netty 之家
感谢郭蕾对本文的策划和审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。




