
本文要点
随着企业的自动化程度越来越高,它们的业务流程也越来越自动化,最终得到的是许多需要彼此通信的应用程序。这在系统设计方面会带来巨大的转变,因为这关系到完全由机器自动完成相关工作。
在传统的数据库中,数据是被动的,查询是主动的:数据被动地等待某个东西运行查询。而在流处理器中,数据是主动的,查询是被动的:触发器就是数据本身。交互模型有根本的不同。
在现代应用程序中,我们需要能够查询被动数据集获取用户动作的响应,但我们也需要通过数据进行主动交互,将数据作为事件流被推送到不同的订阅服务。
我们需要重新思考数据库是什么,它对我们而言意味着什么,以及我们如何与它包含的数据以及将它们连接在一起的事件流交互。
在 2020 年 3 月举行的伦敦 QCon 大会上,我发表了关于“为什么仍有必要从技术角度来看流处理器和数据库”的演讲,并探讨了未来可能将它们进行整合的行业趋势。这些趋势可以映射到从主动数据库(如 MongoDB)到流处理解决方案(如 Flink、Kafka Streams 或 ksqlDB)的常用方法上。
我就职于 Confluent,这家公司是由 Apache Kafka 的创建者创建的。这几天,我在 CTO 的办公室里办公。我们去年做的一件事就是仔细研究流处理器和数据库之间的差异。这就产生了一个名为 ksqlDB 的新产品。随着事件流系统的流行,以及它们与数据库之间存在的显而易见的关系,比较不同的模型如何处理移动数据和静止数据是很有用的。也许更重要的是,这些领域之间存在着明显的整合迹象。数据库正变得越来越主动,在写入数据时发出事件,流处理器越来越被动,在它们积累的数据集上提供历史查询。
你可能会认为,这种技术层面上的整合是一种求知欲,但如果你稍微退一步看,它确实表明我们的构建软件方式有一个根本的转变。Marc Andreessen现在是硅谷的一名风险投资家,他有一个很好的说法:“软件正在吞噬世界”。投资软件公司是有意义的,因为随着时间的推移,不管是个人还是公司,使用的软件都会越来越多。我们购买更多的手机应用,我们购买更多的互联网服务,企业购买更多的商业软件,等等。软件使我们的世界更高效。这是趋势。
但是,认为我们作为一个行业仅仅是消费更多软件,这种想法很肤浅。一个更深刻的观点是,我们的业务变得更加自动化。这与其说是因为购买了更多的软件,不如说是使用软件来自动化我们的业务流程,所以整个事情都是自动运行的——从某种意义上说,企业正在“变成软件”。以 Netflix 为例:他们开始时通过邮政邮件向客户发送 DVD,客户也是通过邮政归还物理介质。到 2020 年,Netflix 已经成为一个纯粹的软件平台,用户只需点击一个按钮就可以立即观看任何电影。让我们通过另一个例子看看企业“变成软件”意味着什么。
考虑下类似房屋抵押贷款申请处理这样的事情。这是一个百年不变的业务流程。有一名信用专员,一名风险专员,还有一名信贷专员。每个人在这个过程中都有一个特定的角色,公司编写或购买软件来提高这个过程的效率。购买的软件可以帮助信用或风险专员更好地完成工作。这是个弱式类比:我们购买更多的软件来帮助这些人更好地完成工作。
如今,现代数字公司构建软件不是为了帮助人们更好地完成工作:它们构建的软件将人类完全带离了原先的关键路径。继续这个示例。今天,我们可以在几秒钟内批准一个贷款申请(传统的抵押贷款可能需要几周时间,因为它遵循旧有的手动流程)。这个过程使用了软件,但使用的方式不同。许多不同的软件被链接在一起,形成一个完全自动化的过程。软件之间相互通信,贷款在几秒钟内审批完成。
所以,软件使我们的业务更高效,但是想一下,对那些系统的架构而言,这意味着什么。以前,我们可能会构建一个应用程序帮助信贷人员更好地完成工作,比如使用三层架构。信贷专员操作用户界面,然后后台运行着某种后端服务器应用,还有一个数据库,帮助用户更有效地进行风险分析,或者其他类似的工作。
随着企业的自动化程度越来越高,它们的业务流程也越来越自动化,我们最终会看到,许多应用程序相互通信:软件与软件通信。这是系统设计的巨大转变,因为它不再是帮助人类用户,而是以完全自动化的方式工作。
软件架构的演变:从单体到事件驱动的微服务
在软件架构的演变中,我们看到了同样的情况:从单体到分布式单体再到微服务,参见图 1。不过,事件驱动的微服务有一些特殊。事件驱动的微服务不直接与用户界面通信。它们将业务流程自动化,而不是响应用户单击按钮及等着事情发生。因此,在这些架构中,既有以用户为中心的一面,也有以软件为中心的一面。随着架构从左向右发展,如图 1 所示。一个软件的“用户”有可能是另一个软件,而不是一个人,所以软件的演进也与 Marc Andreessen 的观察一致。
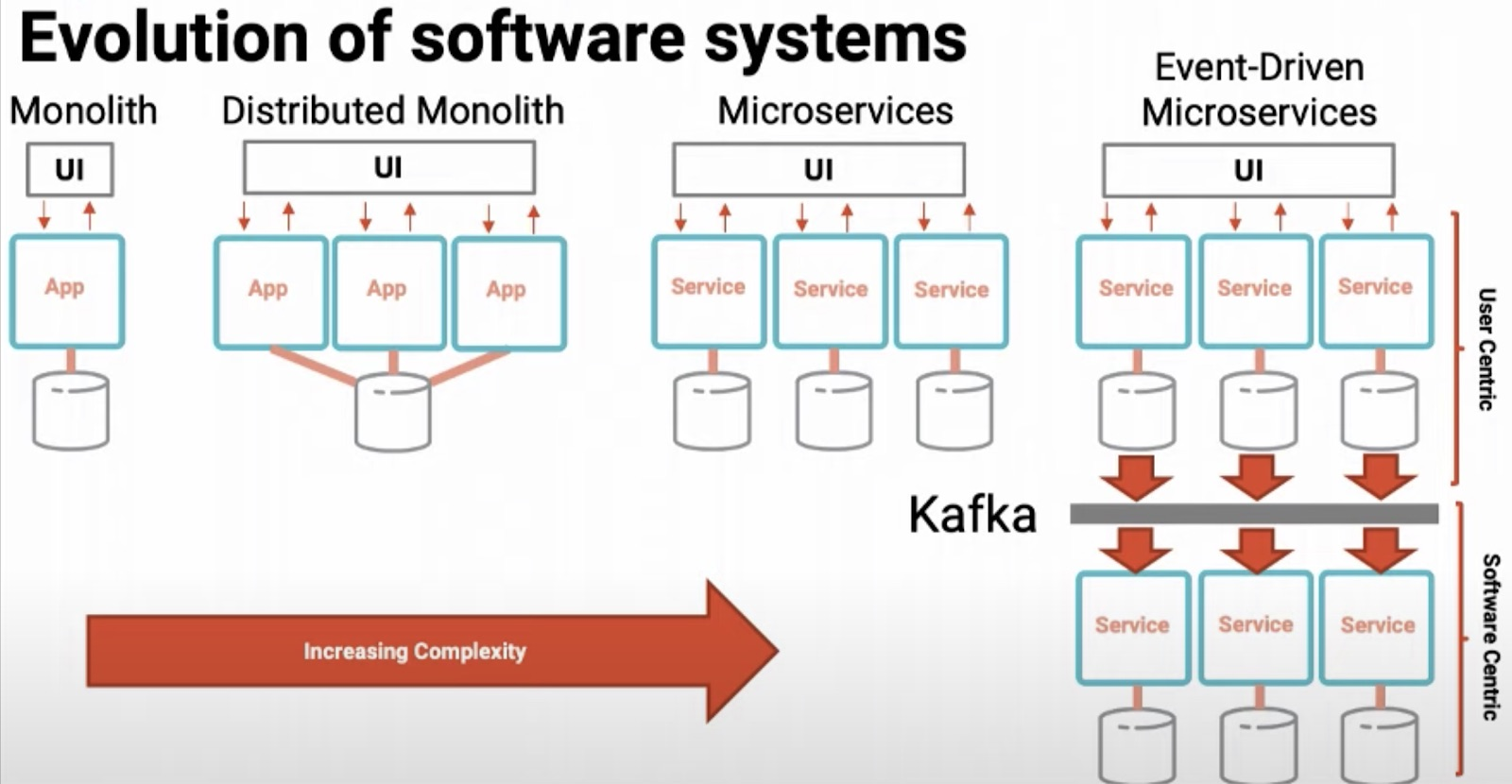
图 1:软件系统的演进
现代架构和传统数据库的影响
我们都用过数据库。我们编写一个查询,然后把它发送给某台保存着大量数据的服务器。数据库会回答我们的问题。单靠我们自己是无法回答这些以数据为中心的问题的。对于我们的大脑来说,要分析的数据实在太多了。但在数据库中,我们只需发送一个问题,就能得到答案。这很美妙,也很强大。
现在,有非常多的数据库系统可供我们使用。像Cassandra这样的数据库让我们可以在分配给数据库的内存中存储大量的数据;Elasticsearch则不同,它提供了一个丰富的交互式查询模型;Neo4j让我们可以查询实体之间的关系,而不仅仅是实体本身;像Oracle或PostgreSQL这样的数据库非常重要,它们可以适用于不同类型的用例。这些平台中的每一个在功能上都略有不同,这使得它们更适合于特定的用例,但在较高的层次上,它们都是相似的。在所有情况下,我们都是问一个问题然后等待答案。
这表明,所有数据库都做了一个重要的假设:数据是被动的。它就在数据库中,等着我们做点什么。这很有意义:数据库,作为一种软件,是一种用来帮助我们人与数据进行交互的工具——无论是你是我,还是信用专员,或其他任何人。
但如果没有用户界面在等待,如果没有人点击按钮并期待事情的发生,那么它还必须是同步的吗?在一个软件与软件通信越来越多的世界里,答案是:也许不必。
一种选择是使用事件流。流处理器允许我们操作事件流,就像数据库操作文件中保存的数据一样。也就是说:流处理器是为活动数据即动态数据而构建的,是为异步而构建的。但是,任何使用过流处理器的人可能都知道,它们感觉上不太像传统数据库。
在传统的数据库交互中,查询是主动的,数据是被动的。事情的发生是因为单击一个按钮并运行查询。数据被动地等待我们运行该查询。如果我们去泡一杯茶,则数据库什么也不会做。我们必须自己触发操作。
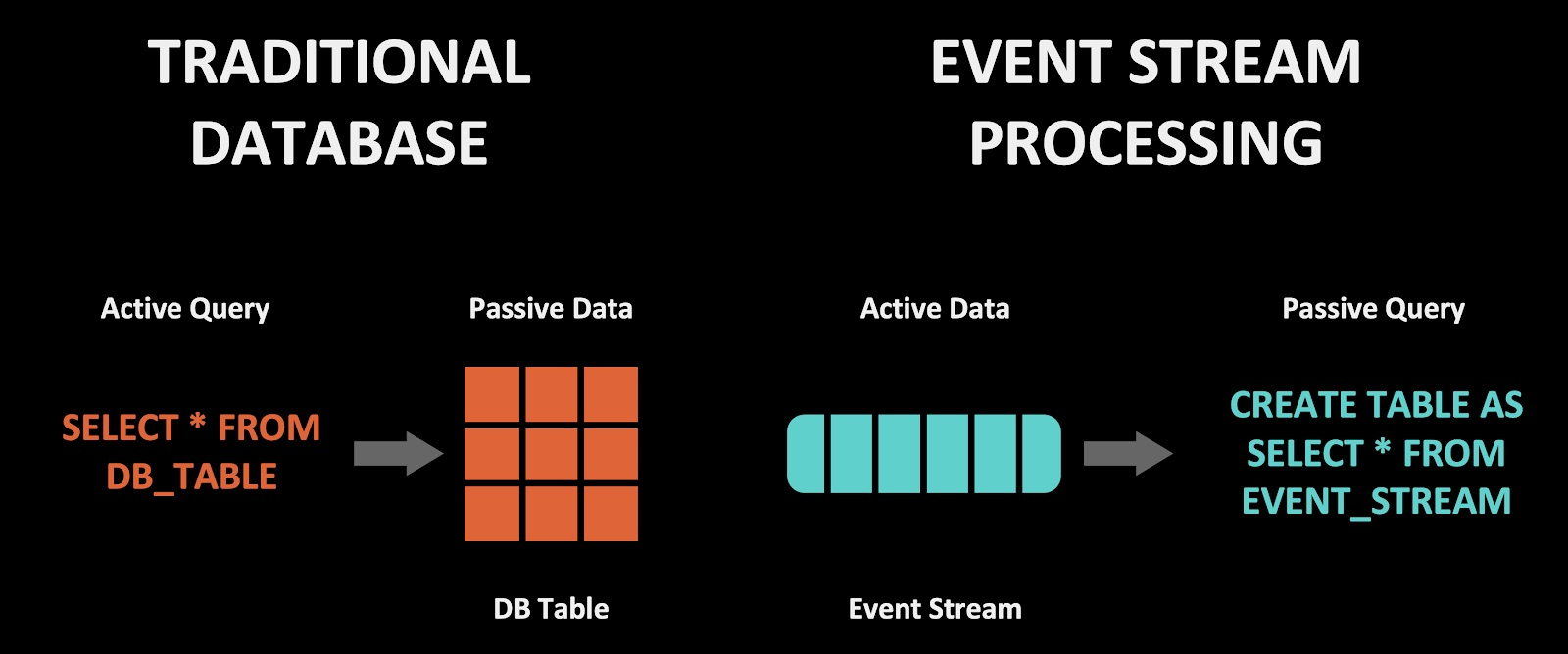
图 2:数据库 vs 流处理
在流处理器中,情况正好相反。查询是被动的。它在那里运行着,等待事件的到来。触发器并不是某人点击一个按钮并运行查询,而是数据本身——其他系统发出的事件或其它的什么东西。交互模型存在根本的不同。如果我们把它们组合在一起呢?
事件流是解决现代分布式架构数据问题的关键
考虑到这一点,我想深入挖掘下流处理器使用的一部分基本数据结构,并比较它们与数据库的关系。这里最基本的关系可能是事件、流和表之间的关系。
事件是构建块,从概念上讲,这是一个简单的想法:简单记录世界上某一特定时间点发生的事情。因此,事件可以是某人下订单,付一条裤子钱,或者在象棋比赛中移动车。它可以是你手机的位置,也可以是另一种连续事件流。
单个的事件形成流,情况一步步变化。事件流表示某个变量的变化:开车时手机的位置、订单的进度或象棋游戏中的走法。所有关于世界变化的精确记录。相比之下,数据库表是某个时间点上当前状态的快照。你不知道之前发生了什么!
事实上,流与事件源的思想密切相关,作为一种编程范式,事件源将数据作为事件存储在数据库中,目的是保留所有这些信息。如果我们想获取当前状态,比如一个表,我们可以通过重放事件流来实现。

图 3:我们可以将国际象棋看作是一连串的事件或位置记录
国际象棋就是一个很好的类比。可以将数据库表想象为描述每个棋子位置的表。每个棋子的位置可以告诉我游戏的当前状态。我可以把它存储在某个地方,如果我想的话,可以重新加载它。但这并不是唯一的选择,用事件来表示一场国际象棋比赛会得到完全不同的结果。我们存储开局之后所有的事件序列。棋盘在游戏中任何时刻的状态,都可以通过从开局位置重放所有后续移动来生成。
注意,关于实际发生的事情,基于事件的方法包含的信息更多。我们不仅知道游戏中某一点的位置,还知道游戏的过程。例如,我们可以确定某种棋局的形成是源于某一棋手的妙招,还是对手的严重失误。
现在,我们可以把事件流看作是一种特殊类型的表。它是大多数数据库中不存在的一种特殊类型的表。它是不可变的。我们不能修改,只能追加,我们只能插入新记录。相比之下,传统数据库表允许我们更新和删除以及插入。它们是可变的。
如果我向流中写入一个值,则它将永远存在,而且是自动的。我不能回到过去,任意改变一些事件,所以它更像是一个使用复式簿记的会计分类账。所发生的一切都记录在分类帐上。但当我们考虑动态数据时,使用这种方法还另有一个很好的理由。通常,事件被发布到系统或公司的其他部分,因此,当你想要修改时,它可能已经被其他人使用了。因此,与在数据库中可以更新有关行不同,在移动数据时,你实际上需要创建一个补偿事件,将更改传播到所有侦听器。总而言之,在分布式架构中,事件是更好的表示方式。
流和表:一枚硬币的两面?
因此,事件提供了一种不同的数据模型——但与直觉相反,在内部,流处理器实际上使用了表,很像数据库。这些内部表类似于传统数据库中用于保存中间结果的临时表,但与数据库中的临时表不同,它们不会在查询完成时被丢弃。这是因为流查询会不定期地运行,没有理由丢弃它们。
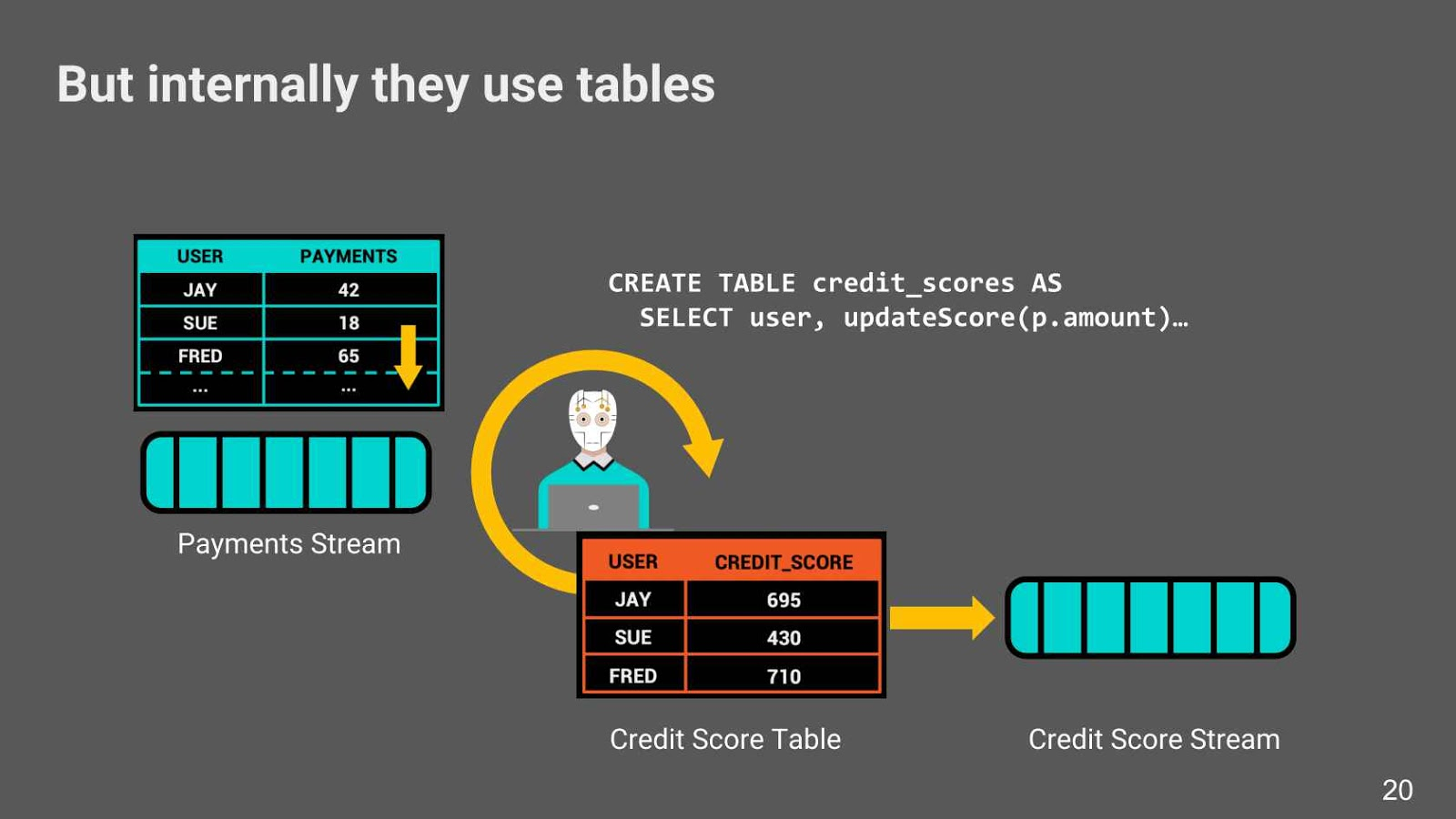
图 4:流处理器内部使用表来保存中间结果,但是输入和输出的数据都用流表示。
图 4 描述了流处理器可能如何执行信用评分。左边有一个账户的支付流。信用评分函数计算每个用户的信用评分,并将结果保存在一个表中。这个表位于流处理器内部,比输入流小得多。流处理器继续监听传入的支付,在此过程中更新内部表中的信用评分,并通过另一个事件流输出结果。需要注意的是,当我们使用流处理器时,我们会创建表,只是不展示给任何人。这是实现细节。所有交互都是通过事件流进行的。
这就导致了所谓的流/表二元性,其中流表示历史,系统中发生的每一个事件或每一次状态更改。可以通过一些函数(可以是简单的“group by key”,也可以是复杂的机器学习例程)将其转换为一个表。通过“监听”该表,可以将其转换回事件流。注意,大多数时候,输出流和输入流不一样,因为通常,这个处理过程是有损的,但是,如果我们在 Kafka 中保留了原始的输入流,我们就总是可以回放并重新生成。
因此,我们有这种二元性:流可以变成表,表可以变回流。在像 ksqlDB 这样的技术中,这两种思想被融合在一起:你可以从一个流转换到另一个流,你也可以创建表,或者“物化视图”,因为有时会像常规数据库一样引用和查询。一些数据库技术,如 MongoDB 和 RethinkDB,也融合了这些概念,但它们是从相反的方向处理问题。
流处理器和数据库的差别
流处理器可以像数据库一样执行一些操作。例如,在算法上,流表连接(参见图 5)和数据库中的等值连接非常类似。当事件到达时,通过主键在表中查找相应的值。
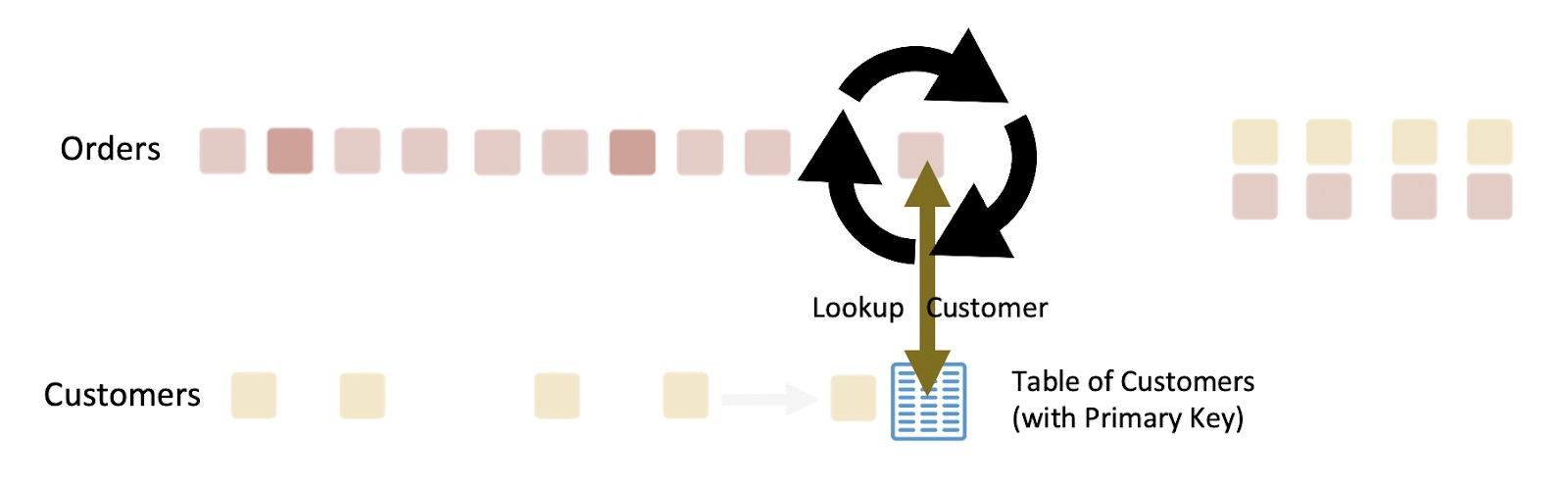
图 5:将流和表连接
但是,使用流-流连接将两个流连接在一起则大不相同,因为我们需要在事件到达时连接它们,如下图 6 所示。
当事件进入流处理器时,它们会在索引中缓冲,流处理器会在另一个流中查找相应的事件。它还使用事件的时间戳来确定处理顺序,因此,哪个事件先出现并不重要。这与传统数据库有很大的不同。
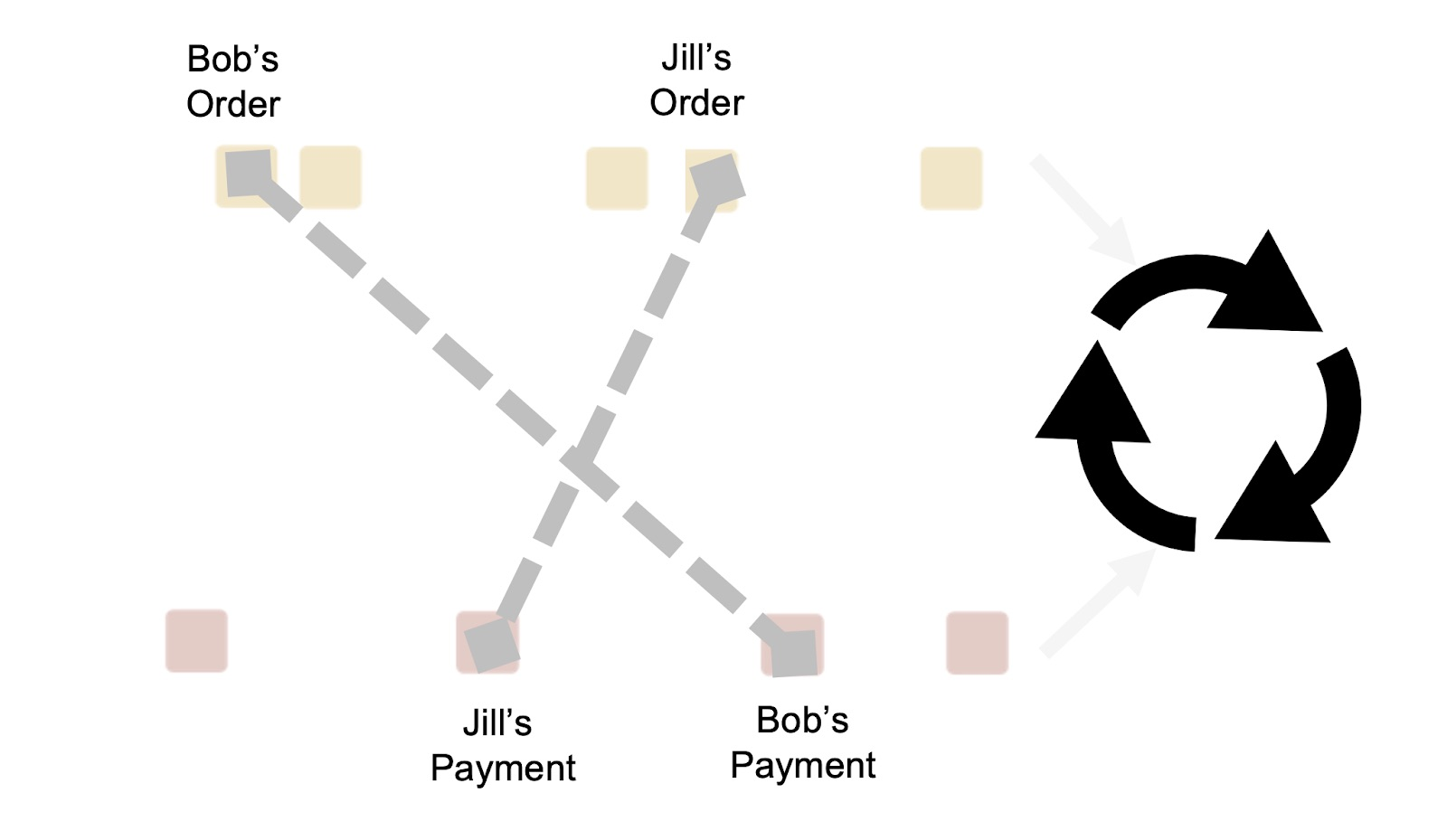
图 6:连接两个流
流处理器还有其他数据库不具备的特性。使用窗口的概念,它们可以适时关联事件。例如,我们可以使用一个时间窗口来限制哪些消息参与连接操作。假设我们希望使用跨度为 5 分钟的窗口聚合温度测量流,计算 5 分钟内的平均温度。在传统的数据库中,要实时地做到这一点很难。
流处理器还可以进行更高级的关联。例如,在数据库中很难实现会话窗口。会话没有预定义的时长;它持续一段时间,并在一段时间不活动后动态结束。Bob 正在我们的网站上找裤子,也许他买了一些,然后就走了,这就是会话。会话窗口允许我们检测和隔离不规则周期。
流处理器的另一个特性是能够处理延迟、无序数据。例如,它们保留了旧窗口,如果延迟或无序数据到达,就回溯更新这些窗口。传统数据库可以通过编程来执行相似类型的查询,但不能精确或高效的产生实时结果。
面向流的混合型数据库的优点
到目前为止,很明显,我们有两种不同类型的查询。在流处理中,我们有 push 查询的概念:将数据推出系统的查询。传统数据库有 pull 查询的概念:提出一个问题并获得返回的答案。我感兴趣的是介于两者之间的东西,结合了两种方法。我们可以发送 select 语句并获得响应。与此同时,我们还可以监听表的变化。我们可以同时拥有这两种交互模型。
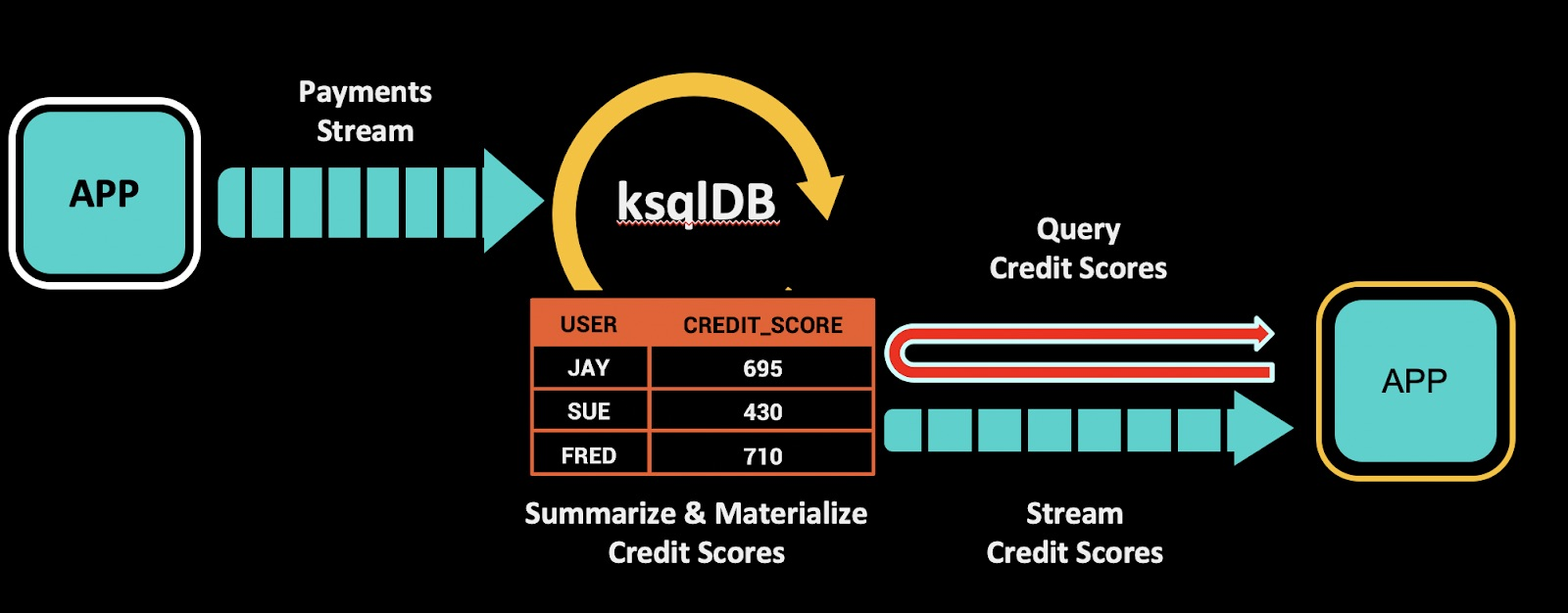
图 7:由流处理器定义的物化视图,第二个应用通过查询或流与之交互
因此,我相信我们正处于一个融合期,最终将形成一个涵盖流和表的统一模型,既可以异步处理,也可以同步处理,既为用户提供主动交互模型,也提供被动交互模型。
事实上,有一个统一的模型可以用来描述这种情况,我们可以使用类似 SQL 的东西来创建,不过需要一些扩展——用单个模型来控制。查询范围可以是从时间开始到现在、从现在到时间结束或从时间开始到时间结束。
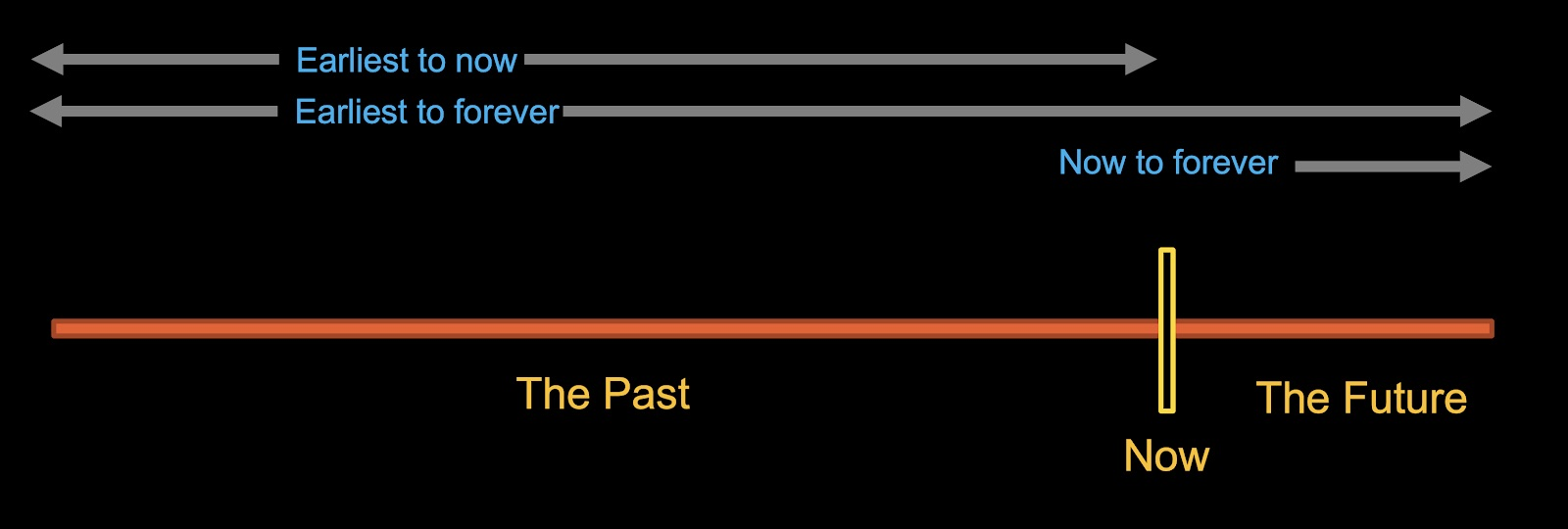
图 8:统一交互模型
“最早到现在”正是常规数据库所做的。查询针对数据库中的所有行,并在处理完所有行后终止。“从现在到永远”是流处理器现在所做的。查询从它接收到下一个事件开始,并且永久持续运行,在新数据到达时重新计算,并创建新的输出记录。“最早到永远”是一种探索较少的组合,但却是一个非常有用的组合。假设我们正在构建一个仪表板应用程序。通过“最早到永远”,我们可以运行一个查询,将正确的数据加载到仪表板中,然后持续保持更新。
还有最后一个细小但重要的点:历史查询是基于事件的(象棋游戏中的所有移动)还是基于快照的(棋子现在的位置)?这是统一模型必须包含的另一种可选项。
把这些放在一起,我们就得到了一个通用模型,它结合了流处理和数据库,以及两者的中间地带:可以保证数据最新的查询。在官方的 ANSI SQL 标准中添加流SQL扩展的工作正在进行当中,但是我们现在可以在像 ksqlDB 这样的技术中进行尝试。例如,下面是 push(“现在到永远”)和 pull(“最早到现在”)查询的 SQL。

图 9:统一交互模型中的推和拉查询
流处理器变得越来越像数据库,反之亦然。数据库也正变得越来越像流处理器。我们可以在主动数据库如 MongoDB、Couchbase 和 RethinkDB 中看到这一点。它们没有提供同样的原语用来处理事件流、异步性或时间与时域相关性,但它们允许我们从表创建流,而且与 ksqlDB 等工具相比,它们在执行拉取查询方面更好,因为它们是从那个方向处理问题的。
因此,无论你是从流处理端还是从数据库端走到这一步,目标都很明确,都是朝着这个中间地带推进。我想我们会看到更多这样的情况。
数据库:该反思了吗?
回想下本文开头介绍的内容:Andreessen 对一个被软件吞噬的世界的观察,这是一个软件与软件交互的世界。用户界面,这个为你我提供帮助的软件,只是整个系统的一小部分。今天,我们在拼车、金融、汽车等各行各业都能看到这种现象,它已无处不在。
这对数据来说意味着两件事。首先,我们需要可以同时进行异步和同步处理的数据工具。其次,我们还需要不同的交互模型。这些模型可以将结果推送给我们,并将自动进行数据处理的步骤链接一起。
对于数据库,这意味着能够查询被动数据集并获得用户问题的答案。但它也意味着主动交互,将数据推送到不同的订阅服务。这一演变的一边是主动数据库:MongoDB、Couchbase、RethinkDB 等。另一边是流处理器:ksqlDB、Flink、Hazelcast Jet。无论哪种方式胜出,有一件事是肯定的:我们需要重新思考什么是数据库,它对我们意味着什么,以及我们如何与它包含的数据和将现代企业连接在一起的事件流进行交互。
作者简介:
Ben Stopford 是 Confluent(一家以 Apache Kafka 为基础创立的公司)CTO 办公室的首席技术专家。他参与的项目非常广泛,从实施 Kafka 复制协议的最新版本到评估和制定 Confluent 的战略。他是《设计事件驱动系统》一书的作者(O 'Reilly2018 年出版)。
原文链接:
Beyond the Database, and Beyond the Stream Processor: What's the Next Step for Data Management?




